一些java面试题
对象创建过程?
首先根据字面量去常量区查找是否存在该class类,然后检查该class是否已经被加载过,如果没有则执行加载、链接、初始化的过程。然后去堆内存通过指针碰撞或者空闲列表的方式开辟内存,然后设置对象头信息(类指针、gc年龄、偏向锁等信息),最后执行 () 函数。
bool占几字节?
int占4字节,但boolean本身只占一个字节,但需要内部对齐,所以要补3个字节
为什么64位的机器下引用类型只占4字节?
本来应该是8字节,但jvm默认开启了类指针压缩,因为一个程序一般不会超过4G
Class对象是放在方法区还是堆中?
笼统地说是放在方法区,但实际上,由于jvm底层是使用c++实现的,所以每个class实际上不仅有java版的还有c++版的,c++版的是放在方法区,而java版的是放在堆中的,当创建一个对象时,它会先去堆中找class,如果找不到就去方法区找c++版的,找到的话就会在堆中创建一个java版的
双重校验锁创建单例对象是否要加volatile?
需要,因为创建对象至少由三部分组成,开辟空间赋0值 -> 执行init方法 -> 局部变量表赋值,假如后两步发生了指令重排序,那么多线程情况下可能出现使用未初始化的类,volatile可以防止指令重排序
arraylist VS linkedlist
序列化有一个很大的不同:arraylist由于存在动态扩容,所以它并不会直接将整个数组进行序列化(因为很有了可能有多的元素),而是只根据元素个数进行序列化。而linkedlist的序列化并不会存前后的指针,而是在序列化时按顺序存储,反序列化时再按照该顺序创建链表即可
插入效率也分情况:如果向最后插入数据,在涉及到数组扩容的情况下,arraylist要更慢
遍历的话:如果使用迭代器遍历linkedlist,两者效率差不多
CopyOnWriteArrayList
底层使用ReentrantLock和volatile来保证多线程安全。
copyOnWriteArrayList底层维护一个volatile修饰的数组,读时不加锁,增删改时添加可重入锁。
当修改数据时,会创建一个新的数组,并将原来的数组复制过来,再添加新元素。这个过程中,读取操作是不影响的,它还是会读取到旧值。只有修改完成后,才会将数组引用指向新修改的数组地址完成修改。并且由于有volatile存在,所以修改后立即可见。
分布式锁的实现方式有哪些?
redis的setnx、mysql的主键唯一性(不能重复添加id相同的数据)、zookeeper的临时顺序节点
redis做分布式锁需要注意什么?
加锁后要用 delete key 进行解锁、给锁设置超时时间,释放锁的过程使用lua脚本可以实现原子操作,Redisson的看门狗机制是自动给锁续期,可重入锁可能多次释放锁,故还需要一个重入计数器,集群环境下,需要对集群一半以上的设备加锁成功才算成功获取锁
base理论
不像CAP理论要么追求强一致性,要么追求高可用性。base追求在核心功能一致性的前提下尽可能使得周边功能也达到一致性
例如网络购物,一个东西是否支付成功,实际上有两个服务,第一个是真正支付的服务,第二个是给用户显示的界面。强一直性的情况下,如果支付成功了,则用户页面必须也显示支付成功,但在base理论下,核心功能是支付功能,支付成功了,但我允许页面上显示正在支付或者系统繁忙等信息,即通知页面服务不需要保证一致性
wait/notify VS await/signal VS LockSupport
wait/notify 可以认为与 Lock 的 await/signal 等价,它们的区别在于:
wait/notify 必须在同步代码块中执行,而await/signal必须在 Lock.lock() 代码块中执行
public static void main(String[] args) {
Object lock = new Object();
Thread thread1 = new Thread(() -> {
synchronized (lock) {
// ...
// 阻塞线程
try {
lock.wait(); // wait / notify 必须在 synchronized 代码块中执行,会释放锁
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread thread2 = new Thread(() -> {
synchronized (lock) {
// ...
// 唤醒阻塞线程
lock.notify(); // wait / notify 必须在 synchronized 代码块中执行,会释放锁
}
});
}
public void test() {
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
Thread thread1 = new Thread(() -> {
lock.lock(); // await / notify 必须在 lock() 代码中执行
// ...
// 阻塞线程
try {
condition.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
lock.unlock();
});
Thread thread2 = new Thread(() -> {
lock.lock();
// ...
// 唤醒阻塞线程
condition.notify();
lock.unlock();
});
}
而LockSupport的park() 和 unpark() 方法都是静态方法,直接调用即可,并且它是基于许可证机制(内部保存了一个变量,用0和1表示是否有许可证),允许先unpark() 在 park()
为什么wait方法需要放到同步代码块中?
synch底层实际是在markword上记录了一个管程对象的指针,而管程对象内部有一个waitset集合(保存等待获取锁的线程),调用wait方法的本质就是将线程加入到该集合中(释放锁后重新等待获取锁)。所以,如果没有同步代码块的加锁,则就没有这个管程,更别说waitset集合了
ConcurrentHashMap
链表长度大于8并且数组长度大于64时,链表会转换为红黑树
插入数据时,如果数组长度小于64会先尝试扩容
jdk1.8之前使用分段锁机制,1.8之后使用cas+synchronized,可以理解为将原来的分段锁粒度降低到数组的每个元素,当操作数组上的元素时使用CAS,当操作链表上的元素时使用sync
扩容流程:先判断是否需要扩容(转红黑树之前、addall()、add()检查),然后计算扩容标识戳(多线程协助扩容时用于判断线程是否满足协助条件),再由核心线程计算每个线程协助扩容的步长(类似于创建分布式主键的步骤),并创建出新的数组,然后多个线程开始复制元素,复制完毕后由最后一个完成的线程检查是否有遗漏数据等收尾工作。
读数据的时候是没有加锁操作的,假如读红黑树的时候正在写数据,元素总体结构虽然是红黑树,但其仍然维护了一个双向链表,所以即使是在写数据,读操作也是会继续进行的,只不过会以链表的方式去寻找数据
计数也是一个考点:以前是简单维护一个int值,添加一个数据就使用CAS +1,但是在高并发的情况下CAS就会造成很大的cpu浪费,1.8之后额外添加了一个CounterCell数组,可以简单理解为一个int数组,里面存放了很多int值,在高并发的情况下,当执行add操作后,该线程就可以任意从该数组中选择一个数+1,当要统计map的长度时,就将该数组元素求和再加上原本的那个数组长度值。解决了之前频繁对单个值做CAS的效率问题
并发编程的三大特性?
原子性(synch、CAS、Lock锁)、可见性(volatile、synch、Lock、final)、有序性
final
修饰类:不能被继承。修饰方法:不能被重写。修饰属性:不能被修改
内部类为什么只能访问final修饰的属性?
如果是类全局变量则不需要final也能被访问,创建内部类本质是创建了一个新的class,如果是外部类的全局属性变量(不需要加final),则会给内部类复制一个该属性。这样做是为了防止外部类被回收后导致内部类无法访问属性
而方法中的局部变量必须被final修饰才能被内部类访问,原因同上,只不过它从根本上禁止修改来保证访问数据的一致性
hashMap什么时候会进行rehash?
扩容的时候,如果新的容量大于某个阈值,则会进行rehash,该阈值默认是int的最大值,可以通过参数设置。rehash本质上是重新设置hash种子
redolog和double write buffer
首先需要明确一点的是:对mysql数据库的修改并不是之间对磁盘数据进行修改,而是对内存中的缓冲页(buffer pool)进行修改(脏页),再由内存持久化机制将缓冲页刷回磁盘。
redolog简单来说就算在每次修改数据前对该操作做一次记录,以防止数据写到内存缓冲页后,还没来得及刷回磁盘,数据库就挂掉了。当数据库重启后,就能重新执行redolog中的记录,达到redo的目的。
而double write buffer 则是保证数据的完整性的,假如内存中的缓冲页由于某些原因出现问题(例如向磁盘刷数据刷到一半数据库挂了,此时内存中的缓冲页可能只有一部分了)被破坏了,此时就算有redolog也是无法恢复的,例如redolog记录了一个 +1 的动作(实际上记录的确实是修改后的值, 而不是动作,这里需要考究一下),但是现在数据页都损坏了,知道+1但不知道在哪个数上面+1,所以只用redolog是无法恢复数据页的。
double write buffer就算用于解决该问题的,还没刷回磁盘的脏页在刷回磁盘之前需要先将页数据复制一份到 double write buffer,然后dwb先刷回磁盘,再将脏页刷回磁盘(向磁盘刷了两次数据,所以叫双写缓冲),假如此时刷一半出现故障,当mysql恢复时,它可以根据页数据校验和来判断是否刷成功,如果没有成功的话,则可以从 double write buffer 中恢复那些脏页重新刷回,由于dwb刷写磁盘是以顺序追加的方式写的,所以效率较高,对整个数据持久化性能影响不大
redolog 和 dwb 思路其实是一样的,都是在数据刷回磁盘前先copy一份用于故障恢复,不同点在于 redolog是对操作的恢复,而 dwb 是对整个缓冲页的恢复
脏页和log buffer刷盘时机
默认情况下(参数 innodb_flush_log_at_trx_commit=1),每次commit事务时都会调用 fsync 执行刷盘动作,但这也至少默认情况下多个刷盘时机的一个,其他的时机还有,每秒都刷一次(即使 innodb_flush_log_at_trx_commit=1),log buffer使用内存超一半时,有checkpoint时

注:mysql始终是用户进程,工作在用户态,所以log buffer想要刷盘需要先复制到内核态的 os buffer
explain中的type
按照唯一索引查找,并且找到了对应的记录,则其type为const,如果没找到,则会显示没有使用索引
而非唯一索引则不管找没找到,都是ref类型
如果使用or连接两个索引查询条件,则其type为 index_merge
不管是唯一索引还是非唯一索引,当条件为 is null 时,type为ref,如果为 is not null,则为 range
redis中的事务有什么用?
它可以保证事务中的语句在执行过程中不会插入其他语言,在exec之前只是将它们暂存起来,但不是原子性的,因为它不会回滚。事务一般搭配watch使用,相当于给事务创建了一个if条件,使用watch监控某些key,如果在执行到mutil被监控的key发生了变化,则不会执行multi的内容。将该过程循环就能实现一个乐观锁
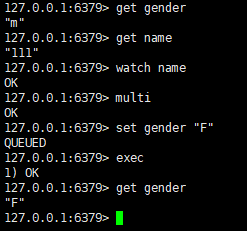
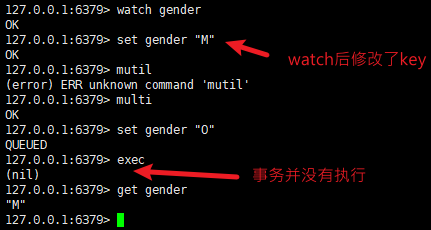
需要注意的是,如果在watch监控过程中,key过期了,则并不会影响事务的执行
java对象中的实例属性(无static)何时初始化?
如果在class中有对象属性,则其赋值语句在 () 中执行,并且不管字段在构造器前还是后,都是在 () 一开始就完成(但是在非静态代码块之后),所以 () 执行顺序是 非静态代码块 -> 属性赋值语句 -> 构造器本身代码
注:上述三个代码块都会被编译进 () 方法中
重写的返回值可以不同吗?
必须相同,但重载的可以不同
并且重写的可见修饰符必须更大,例如父类是protected,子类只能是 protected 或 public。需要明确的是,java中有四个访问修饰符,其访问权限分别是 public > protected > default > private,所以,如果父类的方法使用了default以上(不含)的修饰符,则子类必须指明修饰符而不能使用默认修饰符(即什么修饰符都不写)
重写的方法可以抛出比父类方法更少的异常,例如父类抛出异常A、B,则子类可以值抛出一个或一个也不抛。
为什么TIME_WAIT需要两个MSL?
https://segmentfault.com/a/1190000041875584?utm_source=sf-similar-article