clipped surrogate loss in PPO
PPO是一种off policy的强化学习算法,它的优势就是可以重复使用之前policy与环境交互得到的数据,它通过将一个分布中的采样数据转换为从另一个分布中的采样数据,即从old policy这个分布转换为new policy这个分布
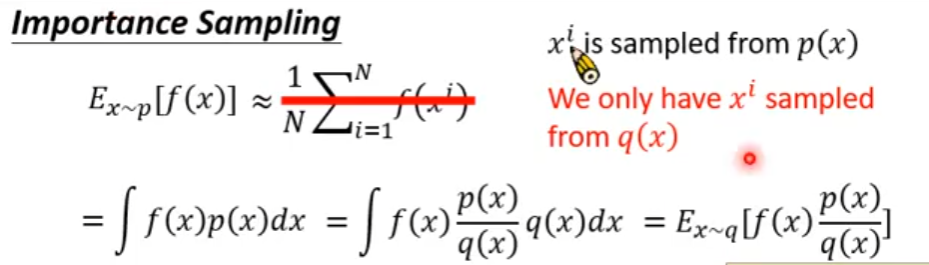
PPO就是在此基础上做了进一步优化使得其能适应强化学习的环境,其核心就是下面这个公式:
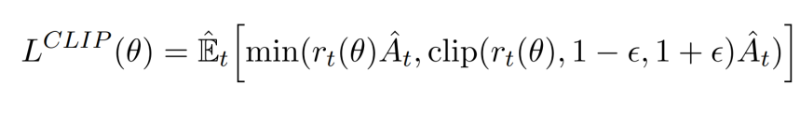
其中的 ( r_t(θ) \ ) 为:
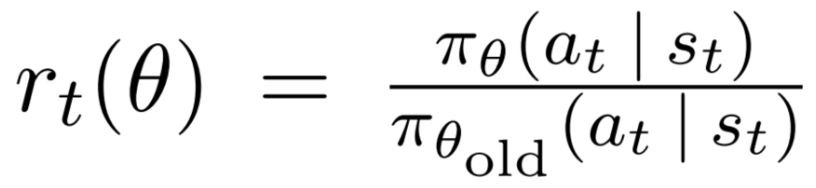
即新旧策略在状态St下得到at的概率比值,显然,如果该比值大于1,说明新的策略更倾向于选择该action
以下为 stable-baseline3 中该表达式的实现,其中,ratio就是上述的那个比值,clip_range取值为0.2
# clipped surrogate loss
policy_loss_1 = advantages * ratio
policy_loss_2 = advantages * th.clamp(ratio, 1 - clip_range, 1 + clip_range)
policy_loss = -th.min(policy_loss_1, policy_loss_2).mean()
现在就有两个问题,1)对clamp(clip)的理解,2)对min的理解
clamp
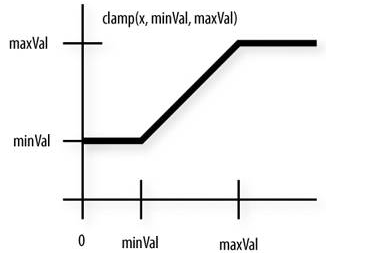
从公式中看出,clamp是对ratio的裁切,即避免它过大或过小,为什么要这么做呢?通过 Importance Sampling 的式子可以看出,将一个分布转换为另一个分布后,它的期望值是没变的,但是它们的方差是不同的,若仅采样有限数据,很容易出现误差

注意到上图中,两者方差的第一项是不同的,后者会多乘这个ratio。理论上来说,由于均值不受影响,所以只要采样的数据足够多,也不会对最终结果产生较大影响,但对于一个实际意义的马尔可夫奖励过程,几乎是不太可能采样足够多的
一个非常需要注意的点是,被clamp过的部分是没有梯度的,即梯度为0,根据链式求导法则,前面计算的梯度应该都是0
换句话说,我们并不希望new policy和old policy的差异过大,如果太大的话,干脆就不对模型做更新了
min
如果当前的Advantage是正值时,如果当前的new policy远小于(两者比值小于某个阈值)old policy得到该action的probability,我仍然希望模型能够学到东西(参数更新,增大policy取得该action的概率)。
相反,若此时,new policy的probability远大于old policy,因为此时advantage是正值,我们的目的就是要让new policy的probability更大,而它此时已经比old大了,所以我们就应该避免它更大,故此时反而应该将其clamp掉,使得其梯度为0,进而使其不做更新
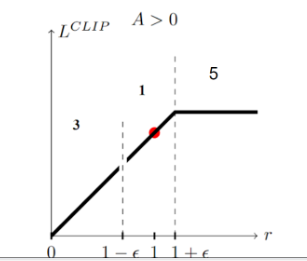
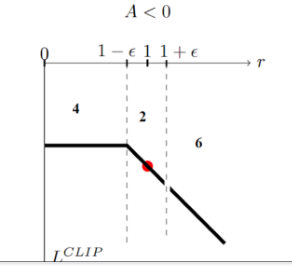
如果当前的advantage是负值时,若new policy的probability远大于old policy,则继续让其更新,因为我们要试图减小policy产生该action的概率,反之亦然
参考
https://huggingface.co/learn/deep-rl-course/unit8/clipped-surrogate-objective
https://huggingface.co/learn/deep-rl-course/unit8/visualize
https://www.bilibili.com/video/BV1XP4y1d7Bk/?p=5&vd_source=78951f3f7dcd752bebcfd9734a584537