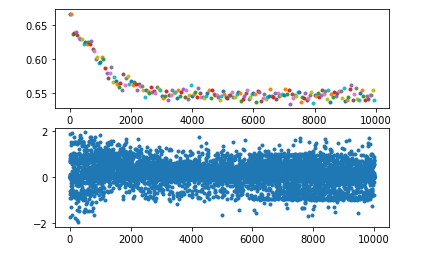
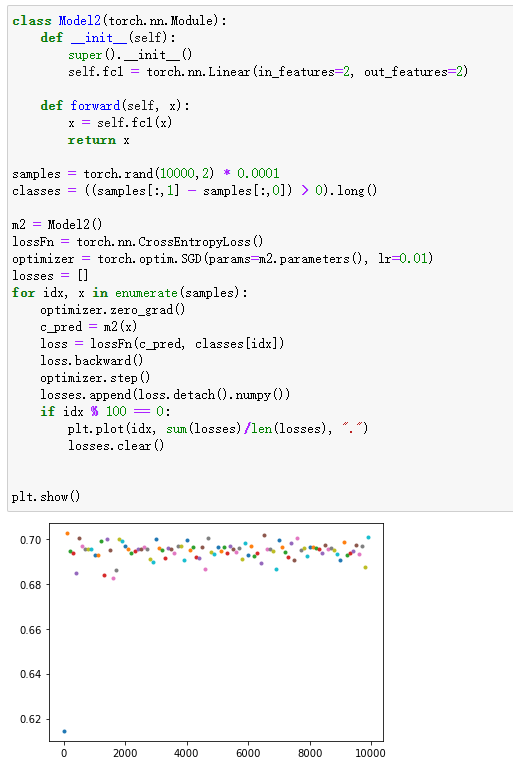
loss总是收敛到0.69左右
- pytorch
- 深度学习
这种情况一般是在使用了交叉熵的二分类问题上容易出现,同样的,也可能出现loss收敛到1.0986、1.386等等,其实他们就是log(1/2)、log(1/3)、log(1/4)。。。
问题概述
根本原因:交叉熵
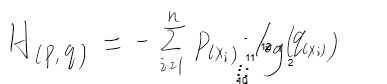
若 q=0.5
对于 01 分布来说,H=log(0.5)=0.69,同理对于 n 分类问题来说,loss 可能会收敛到 log(1/n),这都是因为各个类别拟合概率相近导致的,再看看为什么会导致各类别拟合概率相似。
常见原因之一:Sigmoid
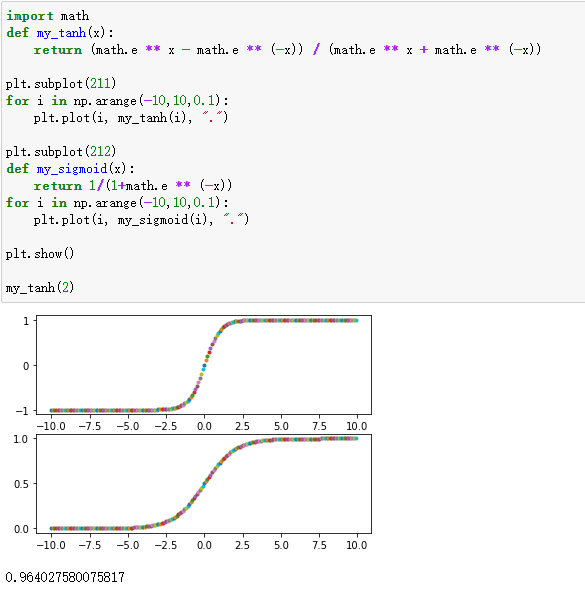
使用交叉熵之前通常会使用 sigmoid 作为激活函数,sigmoid 公式及图像为:
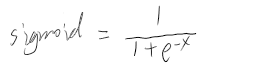
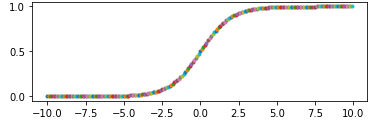
由此可知,有两种情况会使得 sigmoid 的输出都是相近的:
- 自变量 x 都是相近的,导致函数值也相近。
- 当自变量 x 大于或小于某个数之后(例如 5 和 -5),其值基本就等于 1 或 -1。那么如果上层神经元的输出都是一个较大或较小的数,则经过 sigmoid 之后得到数组元素就都是 1 或 -1,则针对每个分类的概率就是相同的,这样的数据得到的交叉熵就是 log(0.5) 或者 log(1/3) 或者 log(1/4)…
对于第一种情况,我们看看为什么自变量 x 会都相近。一般来说,线性函数的结果输入到 sigmoid 中,其公式为:wX = Y。
由此可知,若要使得 y 中的元素相同,又有两种方式:
- w 中每一行都相同或相近。
- X 趋近于 0,则此时 Y 也会都趋近于 0。
再逐个分析。
出现第一种情况一般来说可能是权重的初始值设置不合理,例如使用 pytorch 中的 fill_ 函数使得所有的权重都相同,且后续训练也没有有效地更新权重导致的(为什么没更新权重后面会说),则可以选择一些更随机的初始化方法。
为什么权重没有更新:可能是学习率设置的过小或初始权重过大或情况二,一般来说,如果是学习率设置过小或初始权重过大,则在足够多的迭代次数之后,loss 就会恢复正常。
出现第二种情况则是数据源的问题(若全连接前还有其他层,则其他层的输出就已经很小了),此时可以通过 normalize 的方法对 batch 的数据进行处理或放大之后再输送到全连接层。
对于第二种情况,较好的做法是在将数据送到 sigmoid 之前先进行 normalize。
以上只是两种特殊情况,下面将列举我目前能想到的五种情况
出现问题原因及解决方法
当输入与输出确实不相关时
解释:这个很好理解,因为你的数据本身就不能拟合,所以不管是让人做分类还是让机器做分类都只能得到50%的正确率
解决办法:数据源上找原因
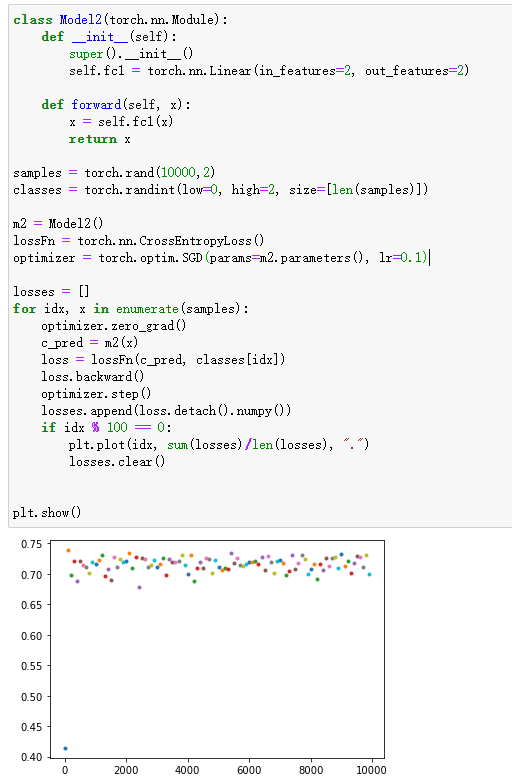
当模型初始权重相同且较大,且学习率较小时
解释:权重相同则意味着模型预测每个分类的概率输出是一样的,学习率较小意味着权重更新幅度太小,导致即使经过了长时间的训练权重依然几乎相同——同初始值一样。
解决办法:理论上,出现这种情况,只要迭代的次数足够多,模型还是可以收敛的。也可以使用 pytorch 的 norm_ 方法初始化权重,并增大学习率。
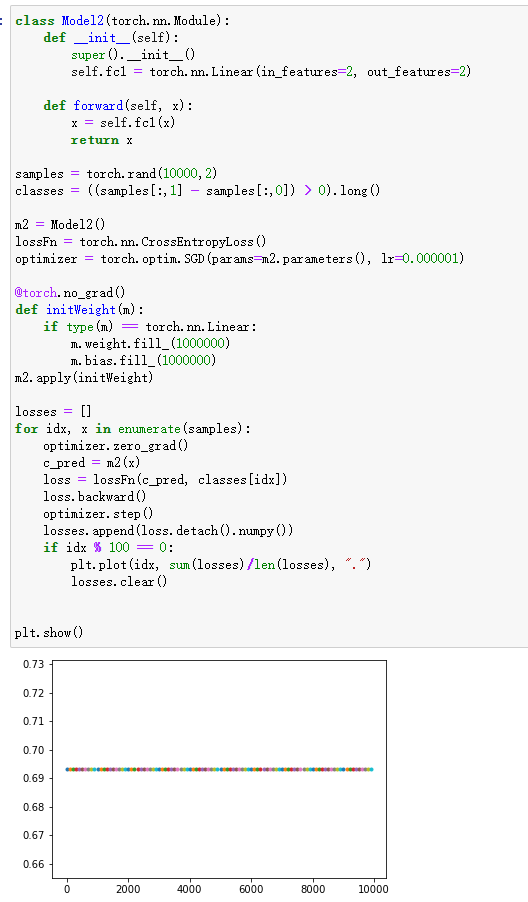
当模型的输入本身就很小,或者模型初始化权重很小时
解释:两个原因:
- 由于预测输入是通过线性函数
w * x + b = y得出的,如果此时 x 或 w 趋近于 0,则得出的 y 也都是趋近于 0 或偏置 b 的,最终导致模型对各个类的概率相同。 - 同下方的将输入整体放大的情况。
解决办法:对输入做 normalization 处理,合理初始化权重,比如使用 N(0, 0.001) 分布初始化权重。
特征不明显,导致长时间训练不拟合

解释:emmmm
解决办法:做一些特征工程,多迭代迭代应该也能跑出来,增加模型复杂度或许也有用
使用 sigmoid 或 tanh 这类函数时,将输入特征整体放大后使得收敛更困难

解释:从 pytorch 文档中可以看出,LSTM 使用了很多 sigmoid 和 tanh 激活函数。
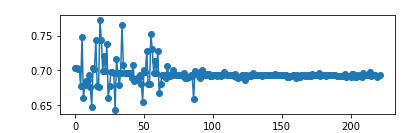
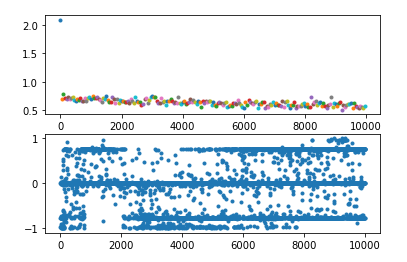
这两个函数都有一个特征,就是他们的导数在大于或小于某个范围时几乎等于 0,这就导致 backward 时梯度越来越小,进而导致权重无法更新或极慢,如下图:
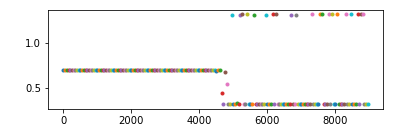
所以如果输入 LSTM 的值都比较大或比较小,从官网给出的公式不难看出,其输出就容易只在 0、1、-1 三个数附近徘徊(如下图中的第二个图)。
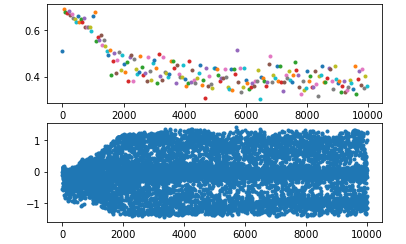
解决办法:解决办法很多,这里写三种
想要解决这个问题就得在 LSTM 的输入端做一些处理,比如,我这里使用 sin 函数将值域固定在某个范围内,起到了一定的效果。

或者,直接使用 pytorch 提供的 layerNorm。
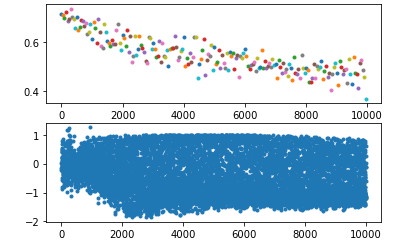
或者,当我不进行 norm 只使用 batch 输入的时候,批量化处理会排除个别元素干扰,对整个 batch 求均值能提高收敛速度减小训练时间。