Pytorch使用tensorboard
基本使用
首先需要安装tensorboard
# -U 表示如果存在则升级
pip3 install -U tensorboard
接着就可以直接在代码中使用
from torch.utils.tensorboard import SummaryWriter
...
# 默认会在项目路径下创建 runs 文件夹
dashboard = SummaryWriter()
...
dashboard.add_scalar('Loss/train', loss.item(), i)
...
dashboard.close()
查看图表
tensorboard --logdir=./runs
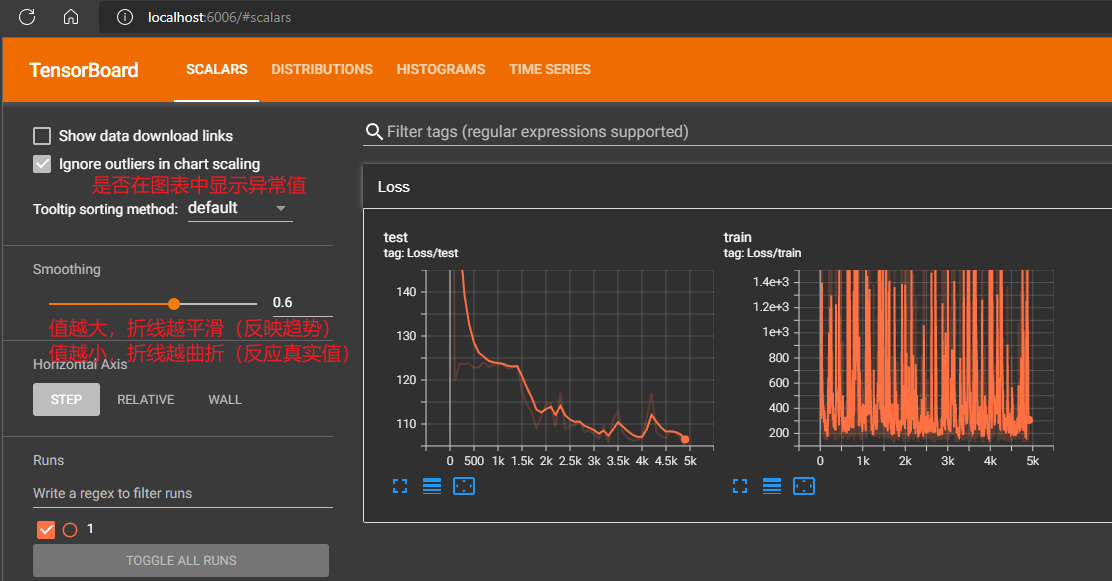
显示模型学习量变化
for idx, (x, y) in enumerate(test_data_loader):
...
# 显示所有学习量变化
for name, parm in model.named_parameters():
dashboard.add_histogram('Weight/'+name, parm, i)
# 仅显示指定学习量
dashboard.add_histogram('Weight/myweigth', model.fc.weight, i)
...
Histogram
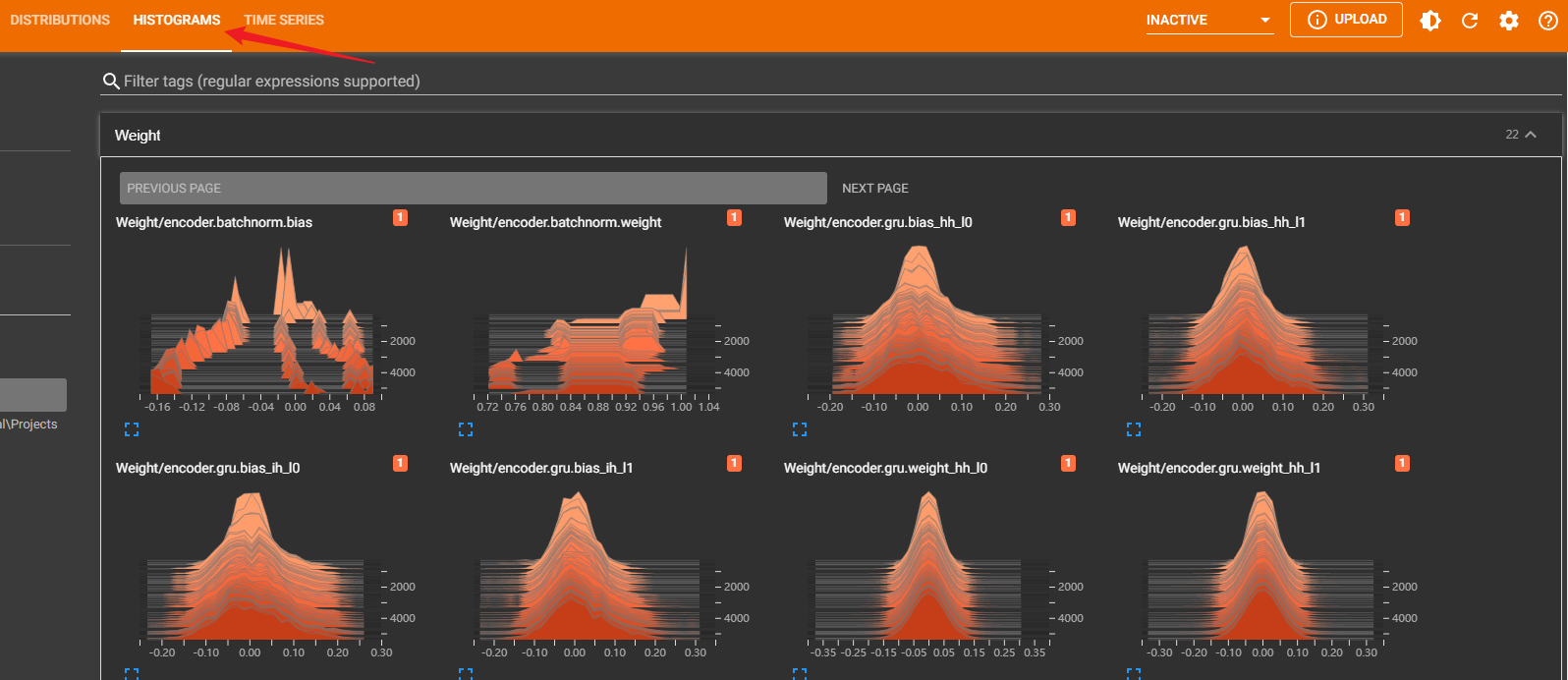
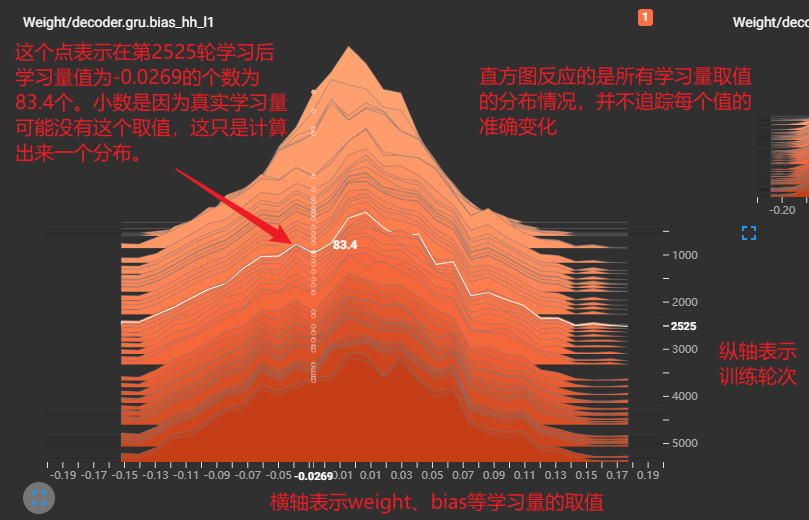
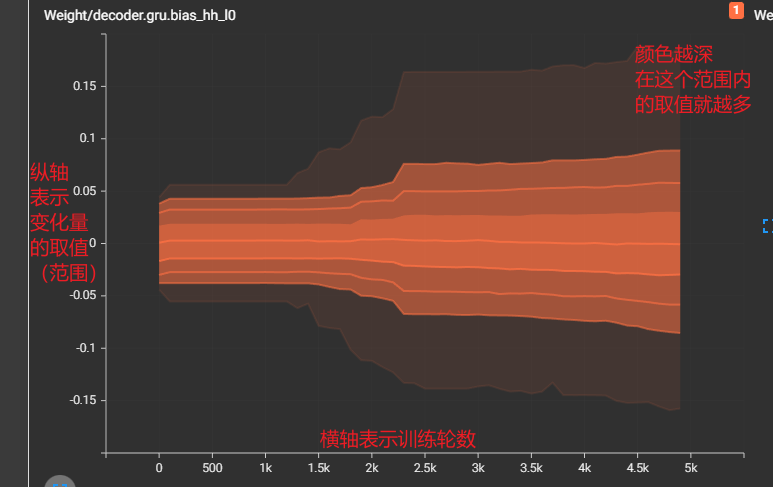
需要知道的是,上图中,虽然只是 gru.bias_hh_l1 的取值变化,但这个bias并不只是代表一个值,而是一堆值(想象一个线性方程组中的参数),故它只是反应这一堆值的分布变化,而不是追踪其中一个值的变化
事实上,并不能单纯地直接将横轴理解为学习量的取值,它仅表示一个范围。具体地,例如你不能直接从图中看出取值为0的学习量有多少(-0.0269同理),你只能通过计算 (-0.01, +0.01) 这个区间内的积分,大致估算出取值为0的有多少。
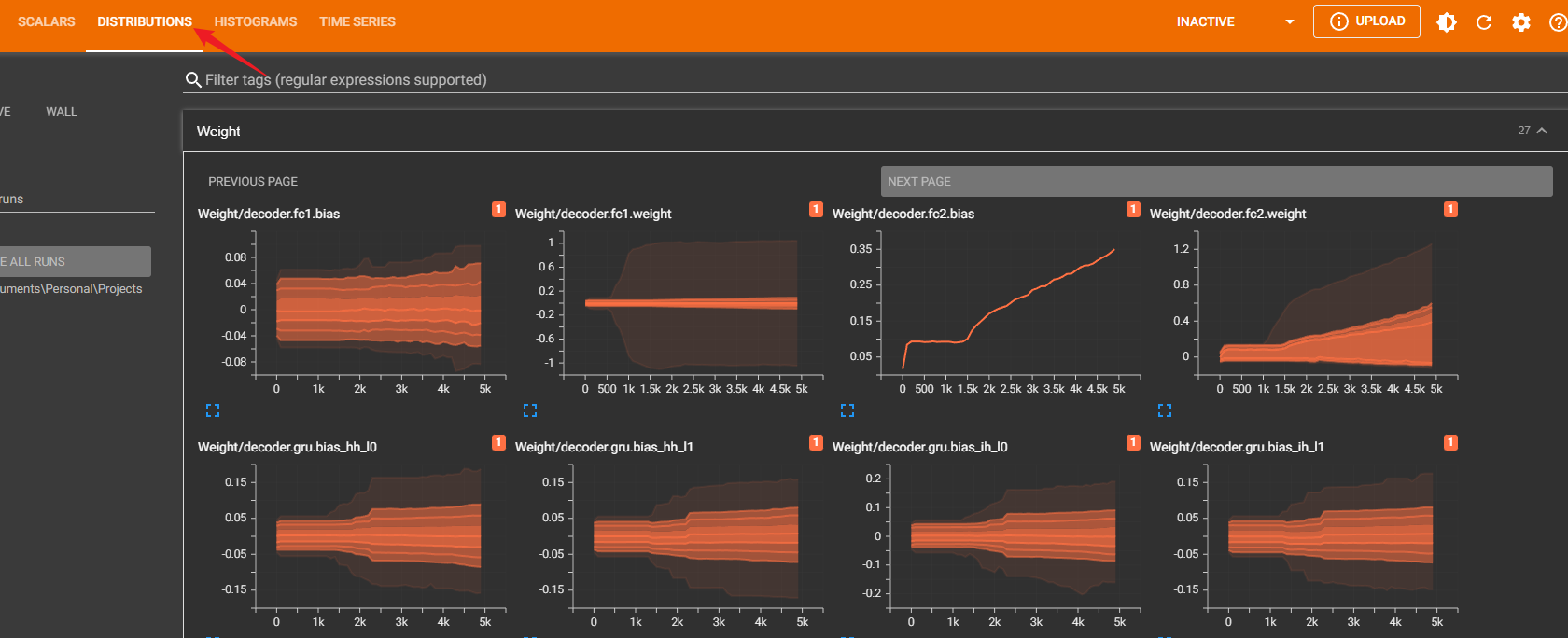
DISTRIBUTIONS
Distributions图和Histogram图是同源的,也就是说他俩是同一数据的不同展示形式。他们都展示的是某学习量的分布情况,相较而言,我认为Distributions更直观
初始化权重
def init_weight(m):
if isinstance(m, torch.nn.GRU):
m.weight_ih_l0.data.fill_(1)
m.weight_hh_l0.data.fill_(1)
m.bias_ih_l0.data.fill_(0)
m.bias_hh_l0.data.fill_(0)
...
model.apply(init_weight)
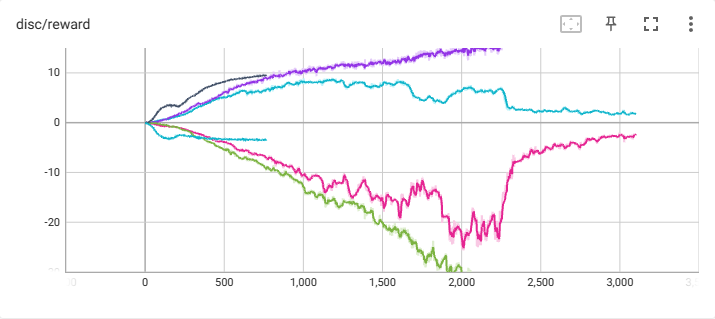
在一个图中显示多条曲线
方法一(推荐):除了 add_scalar,tensorboard还提供了 add_scalars(tag, dict_data, step) 的方法
dashboard1 = SummaryWriter('./logs')board.add_scalars('disc/reward', {"exp": scalar1, "noob": scalar2})
这种方法会自动在 logs 目录下创建两个日志文件,分别是 disc_reward_exp 和 disc_reward_noob,其本质和下面的方法二一样,只不过不用维护多个dashboard了
方法二:创建多个SummaryWriter对象并指定不同的目录,添加数据项时指定相同的名称即可
dashboard1 = SummaryWriter('./runs/1')
dashboard2 = SummaryWriter('./runs/2')
for i in range(100):
dashboard1.add_scalar('mychart', i, i)
dashboard2.add_scalar('mychart', i*2, i)
在其 公共父目录 启动
tensorboard --logdir=./runs
将生成的两个日志目录都勾上即可
step/relative/wall
它们三者是可选的图表横坐标
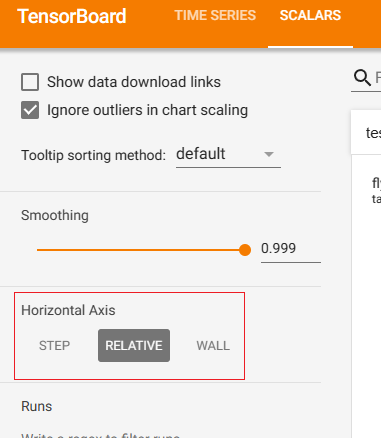
step:就是添加数据时填写的step
relative:相对时间,它不管程序是从什么时候开始的,例如横坐标的1就表示,所有程序运行一个小时时添加的数据,用于横向对比各个模型的性能
wall:绝对时间,表示在某个具体时间下,程序添加的数据
每个chart都要维护一个 global_step 很麻烦?
我查了一下,网上貌似有说将global_step设置为None,就能实现自增而不用单独维护一个变量,但我试了下貌似没用,而且我看官网也没相应描述
我的一个解决方法是自己创建一个class,内部组合一个 SummaryWriter,然后由它来维护 step 的自增:
from torch.utils.tensorboard import SummaryWriterimport collectionsclass Board: def __init__(self, path): self.board = SummaryWriter(path) self.global_steps = collections.defaultdict(int) def add_scalar(self, tag, scalar): self.board.add_scalar(tag, scalar, self.global_steps[tag]) self.global_steps[tag] += 1 def add_scalars(self, tag, scalar): self.board.add_scalars(tag, scalar, self.global_steps[tag]) self.global_steps[tag] += 1 def add_scalar_map(self, m: dict, prefix=""): for k, v in m.items(): self.add_scalar(f'{prefix}/{k}' if prefix else k, v)# 用起来也很简单,除了不用再传step,其他的操作都一样board = Board(r'./logs')board.add_scalar('test/loss', scalar)
如此一来,就不用再为step自增发愁了。