Java
java多线程编程实战指南 笔记
线程简介
进程是程序的运行实例,是动态的,运行一个java程序实际上就是一个java虚拟机进程
进程是程序向操作系统申请资源(内存空间、文件句柄等)的基本单位,线程是cpu调度的最小单位
一个进程可以包含多个线程,这些线程贡献进程申请的资源
Thread的start方法是启动一个线程,但该方法的调用并不一定立即启动线程,得看系统的线程调度器决定。线程是一次性的,即该方法只能调用一次
run方法是线程的具体任务逻辑,它是由JVM自动调用的,该方法执行结束,则线程也就结束了。由于该方法是一个public的方法,当然可以手动调用,不过手动调用时它就是在当前线程下执行的普通方法了
java种,一个线程就是一个对象,但与普通对象不同的是,线程对象需要额外分配操作栈空间内存,并且可能绑定一个内核线程
Thread、Runnable创建线程的区别
// 方式一:通过匿名内部类的方式创建Thread的子类
new Thread(){
@Override
public void run() {
// ...
}
}.start();
// 方式二:通过传入一个Runnable接口的实现类来启动一个Thread
new Thread(new Runnable() {
@Override
public void run() {
// ...
}
}).start();
-
继承Thread对象本质上是基于继承的技术,而通过创建一个Thread对象并在构造器中传入Runnable实现则是基于组合的方式。从解耦的原则上来说,组合优于继承
-
可以只创建一个Runnable的实现并传入多个Thread中,使得它们可以共享Runnable中的变量,但可能引发并发问题
-
Thread对象就是继承了Runnable接口,但需要明确的是,Runnable接口和多线程运行并没有强制的关系,它只是一种可以运行的方法的抽象,很多接口并不需要使用多线程调用Runnable,这种情况下,创建Thread对象会更消耗资源,因为它会自动开辟栈空间并且绑定内核线程
可以将线程设置为守护线程,但是必须在start方法之前设置,否则会抛异常。守护线程和用户线程的区别在于,是否会影响JVM的停止,当用户线程执行结束后,不管是否存在守护线程,都会停止JVM
一个线程可以创建另一个线程,则它们就是父子关系。默认情况下一个线程是否是守护线程,取决于其父线程是否是守护线程,它们会保持一致。
线程状态
-
new:创建而未启动,该状态只会出现一次
-
runnable:包含ready和running两个状态,可能获取到cpu也可能没有,但处于可运行状态
-
blocked:IO阻塞或者等待锁时
-
waiting:一些特定方法触发线程等待,例如:Object.wait()、Thread.join()、LockSupport.park(Object)等
-
timed_waiting:带超时时间的等待
-
terminated:run()正常或异常结束,该状态只会出现一次
线程安全
什么是竞态?
竞态就是指多线程环境下,对某共享变量的操作可能出现不符合预期的情况,例如多线程下的 i++ 操作
线程安全的问题主要体现在3个方面:原子性、可见性、有序性
原子性
原子操作不可分割,意思是从其他线程的角度来看,对某共享变量的操作要么没执行要么执行完成,不存在执行到一半的状态
java中有两种方式实现原子操作,一个是锁,另一个是CAS
注:
-
java中的long和double的操作不具备原子性,即多线程环境下可能读写一半的值。
-
java中的volatile不具备原子性
-
但是两者结合就不一样了,jvm规范中特别指明了,使用volatile修饰的long或double的写操作具有原子性
可见性
一个变量更新后,其他线程可以立即读取到最新的值,即为可见性
JMM用于屏蔽物理机内存模型,因为每个cpu都会有自己的寄存器,但它们也有共同的内存空间,这就和JMM模型一致了。程序中的可见性是多线程衍生出的问题,它与实际用多少个cpu是无关的,这是因为线程的切换会导致寄存器的值出现上下文的切换,从宏观角度来看,其实就是在模拟多cpu
有序性
多处理器的情况下,从一个处理器视角看另一个处理器运行的程序是按照程序预期顺序执行的(这句话容易引发歧义,见下)。有些情况下,处理器并不会按照程序代码的顺序执行,例如发生了指令重排序或内存重排序(见下)。
所谓有序性,就是指避免重排序对多线程环境产生影响
注:对有序性的一个误解是从一个处理器看另一个处理器执行的指令是完全按照程序代码顺序来的,这是错误的,所谓有序性本意并非不允许重排序,而是说另一个处理器执行的代码,就算发生了重排序,对我这个处理器执行的代码结果是按照代码预期顺序的,例如下面的代码:
处理器1
A = 0
B = 1
S = 2
-------------------t1时刻
处理器2
java内部类
一般内部非静态类
class Outer {
public Integer data = 1;
class Inner{
void print() {
System.out.println(data);
}
}
}
public static void main(String[] args) {
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner(); // 注意内部类 new 的方式
inner.print(); // 1
outer.data = 2;
inner.print(); // 2
}
由此可见,一般内部类与外部类共享变量,并且可以对变量进行修改
方法内部类
class Outer {
public Integer data = 1;
public void fun(){
Integer funDate = 1;
class Inner{
void print() {
System.out.println(data);
System.out.println(funDate);
}
}
new Inner().print();
}
}
public static void main(String[] args) {
Outer outer = new Outer();
outer.fun(); // 输出 1 和 1
}
由此可见,方法内部类也是共享外部变量的,但是,对于方法内部的局部变量是不能做修改操作的,它可以不为final,但至少要保证不会修改它,否则编译就会报错
java中匿名内部类和lambda的区别
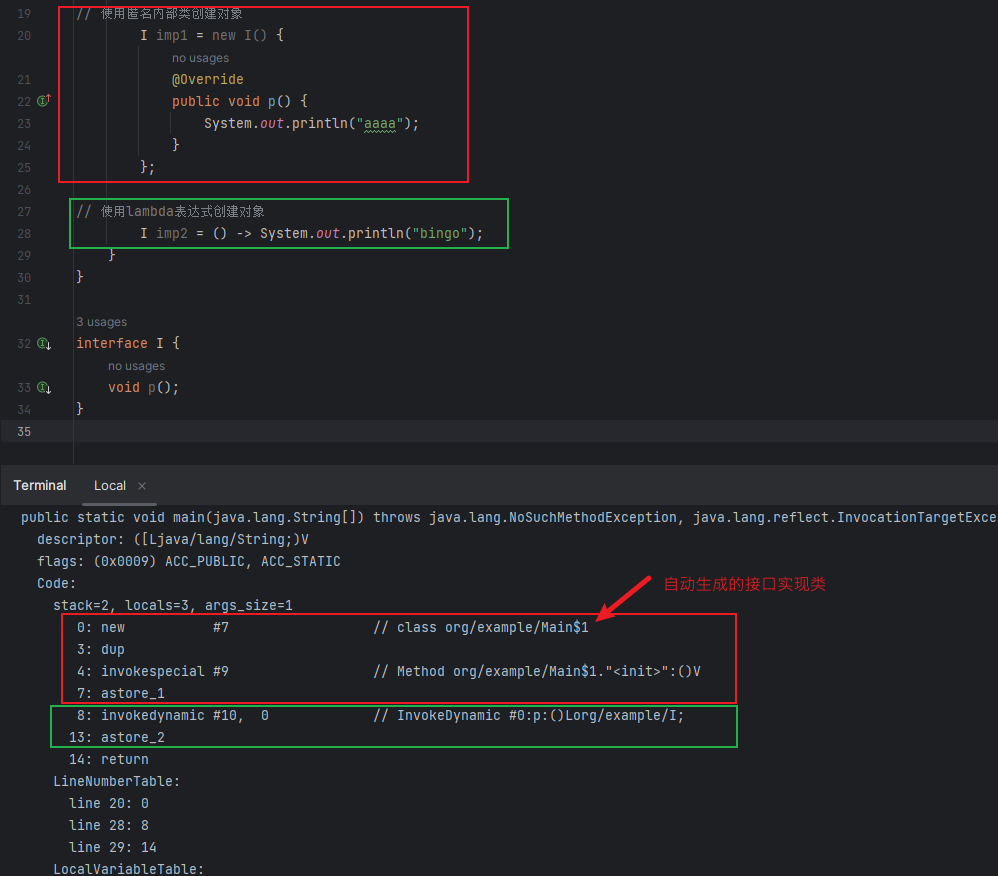
对于只有一个抽象方法的接口,可以使用匿名内部类创建引用对象,也能使用lambda表达式来创建对象:
interface I {
void p();
}
// 使用匿名内部类创建对象
I imp = new I() {
@Override
public void p() {
System.out.println("aaaa");
}
};
// 使用lambda表达式创建对象
I imp = () -> System.out.println("bingo");
两者的区别在于:前者是在字节码层面创建了一个接口的实现类然后进行初始化,后者则使用了动态语言的特性:
如何解释这个动态语言特性呢?
对于第一种方法,它的引用类型是固定的,即它只能是 I,不能替换成其他接口,而对于第二种,它的引用类型可以修改成任意其他只有一个抽象方法的接口
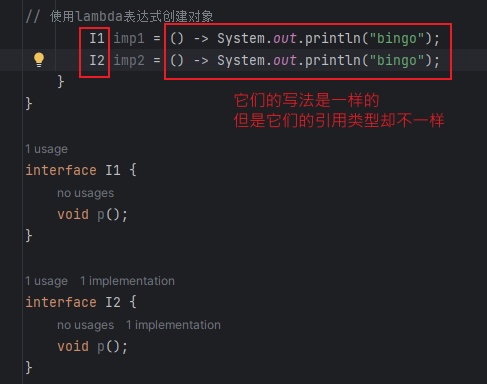
这是不是和java原本的强类型不太一样了,原本的强类型是指静态类型和实际类型一一对应,显然这里并不是这样。
为了使得java也具有动态类型的特性,jdk7引入了invokedynamic字节码指令,事实上,如果仅对于java语言来说,它早就可以通过反射实现动态语言的特性,之所以还要引入该指令,是因为反射是java语言的特性,而jvm不仅仅能运行java代码。
Spring笔记
什么是Spring?
应该从容器和生态方面作答
什么是开闭原则:
给系统做功能扩展时,不应该修改已经写好的代码。即对扩展开放,对修改关闭
为什么要使用容器?
容器的核心功能是用于统一规范,只要符合规范的对象都可以放在容器中统一管理
Autowired和Resource的区别?
两者类似于JDBC和JPA的关系,Autowired是spring提供的注解,默认按照类型注入。Resource是j2ee提供的,默认按照名称注入
Spring中有哪些核心模块?
Spring并不是一个模块,而是一堆模块的集合,例如 Spring Core(核心类库,提供IOC功能),AOP(提供aop功能),MVC(web应用支持)等
Spring AOP的理解
能够提供哪些与业务无关的功能,降低模块的耦合度,有利于代码的扩展和维护。SpringAOP是基于动态代理的,如果要代理的对象实现了某个接口,则会通过JDK的动态代理去创建代理对象,如果没有实现指定接口,则使用CGlib动态代理生成一个被代理对象的子类作为代理对象。当然,SpringAOP也继承了AspectJ
Spring AOP 和 AspectJ AOP 的区别?
AOP是一种思想,这两者就是它的实现。SpringAOP基于动态代理,属于运行时增强,而AspectAOP基于字节码操作,属于编译时增强。
对Spring IOC的理解
对象生命周期管理权的转移,用于解耦,它是整个Spring的基础核心
Bean的创建过程?
Bean的创建过程大致为:根据配置文件或注解生成BeanDefinition —> 执行 BeanFactory 的后置处理器(钩子,对BeanDefinition做修改或增强) —> 实例化对象 —> 填充属性(populate方法) —> 设置Aware接口 —>执行 Bean 创建的前置处理器 —> 执行 init-method 方法 —> 执行 Bean 创建的后置处理器 —> 创建完成
设置 Aware 接口有什么用?
Bean在创建时,有时可能需要知道一些关于容器的信息,例如可能需要知道BeanName,或者容器中其他的Bean,总之就是需要知道和容器相关的信息,但是Bean中并没有这些信息(这个Bean就是你需要交给Spring管理的类,你的类肯定没有容器相关的信息),此时就可以让该Bean实现某个 Aware 接口,例如实现 BeanNameAware 接口,该接口有一个 setBeanName(String name) 的方法,当Spring创建该Bean时,就会自动调用该接口并传入BeanName。这些Aware接口在业务开发中基本用不到,但如果要写一些BeanFactoryPostProcessor 或者 BeanPostProcessor 则很有可能需要实现Aware接口,因为这些PostProcessor其实也是Bean,也需要放到BeanFactory中才能生效。
Lambda表达式相关的Consumer、Function、Predicate与Supplier的区别
区别总览
名称 参数 返回值 实例 Consumer 有 无 Iterable上的forEach方法 Function 有 有 Optional的map方法 Predicate 有 有(bool) Optional的filter方法 Supplier 无 有 懒加载、惰性求值、Stream的generate(静态) 详细解释
Supplier
- 解释
在开发中,我们经常会遇到一些需要延迟计算的情形,比如某些运算非常消耗资源,如果提前算出来却没有用到,会得不偿失。在计算机科学中,有个专门的术语形容它:惰性求值。惰性求值是一种求值策略,也就是把求值延迟到真正需要的时候。在Java里,我们有一个专门的设计模式几乎就是为了处理这种情形而生的:Proxy。不过,现在我们有了新的选择:Supplier。
非常简单的一个定义,简而言之,得到一个对象。但它有什么用呢?我们可以把耗资源运算放到get方法里,在程序里,我们传递的是Supplier对象,直到调用get方法时,运算才会执行。这就是所谓的惰性求值。
- 举例
static void randomZero(Integer[] coins, Supplier<Integer> randomSupplier) { coins[randomSupplier.get()] = 0; } Integer[] coins = {10, 10, 10, 10, 10, 10, 10, 10, 10, 10}; randomZero(coins, () -> (int) (Math.random() * 10));
- 扩展
但是,通常实现 Proxy 模式,我们只会计算一次,反复计算是没有必要的。Guava给我们提供了一个函数:
memorizedUltimateAnswerSupplier = Suppliers.memoize(ultimateAnswerSupplier);memoize() 函数帮我打点了前面所说的那些事情:第一次 get() 的时候,它会调用真正Supplier,得到结果并保存下来,下次再访问就返回这个保存下来的值。