Juc
JUC笔记
管程:锁对象
守护线程:为其他线程服务的后台线程
JMM
该部分为 《深入理解java虚拟机》第二版 中关于java内存模型的描述
为了屏蔽各个平台的内存差异,jvm创建了java内存模型。其主要目标是定义程序中各个变量(线程共享变量)向内存读写的规则
JMM规定所有的变量都存储在主内存中,每个线程都有自己的工作内存,线程所使用的变量都是主内存到工作内存的拷贝。但它们和堆栈内存是两个概念。
主内存和工作内存间的交互通过8个java原语实现,例如如果要将变量从主内存拷贝到工作内存,则需要顺序执行 read、load 两个原语,反之,则顺序执行 store、write。
volatile
-
可见性
-
禁止指令重排序
线程读取被volatile修饰的变量会强制从主内存刷新工作线程的值,修改也将立即向主内存同步,故而保证其对所有线程的可见性
但需要注意的是可见性并不一定线程安全,因为对变量的操作并非原子操作
除了volatile外,synchronized 和 final 也能保证可见性,同步代码块的可见性是因为:变量在执行unlock之前,必须同步回主内存中。所谓可见性,实际上指的是修改后的可见性,final修饰的变量在分配内存阶段就已经赋值了,且都不允许被修改,天然保证了可见性
所谓指令重排序,当两行代码的执行没有依赖关系时,可能在执行时顺序被交换,例如:
doInitialize()
intialized = true
实际执行时,cpu并不知道两者存在逻辑关系,所以可能将 intialized=true 提前执行,如果其他线程要根据该变量做一些判断,则可能出现问题
其实现方法是,创建一个内存屏障,内存屏障之后的代码不会被重排序到之前执行
synchronized也能解决指令重排序带来的问题,但它并不是防止指令重排序。指令重排序带来的问题本质上是多线程下才会出现的问题,而synchronized能保证在加锁状态下,变量只能被一个线程访问
happend-before
先行发生原则描述的是,在几种特定的场景下,代码会有明确的先后执行顺序。例如:线程的start()方法一定会比该线程的其他方法先发生,在同一个线程中对某变量的操作,书写在前面的代码总是比后面的代码先发生。这些原则有什么用呢?
它们就好比是数学中的一些基本假设或基本条件,由这些基本条件可以推导出很多复杂的结论。
多线程环境下,可以由这些原则判断程序代码是否安全。
实现线程安全的方法
互斥同步
同步指多线程在访问某资源时同一时刻只能有一个线程来访问,互斥是实现同步的一种手段
synchronized是实现同步的一种手段,同时它也是一种可重入锁,即如果是当前线程已经获取了锁对象,则它下次仍然可以进入被锁的代码块中。与之类似的还有juc中的ReentrantLock,它们都是可重入锁,只是使用的语法上有所区别,ReentrantLock使用lock()和unlock()两个api实现加锁和释放锁,而synchronized使用字节码指令monitorenter和monitorexit来加锁和释放锁。另一个区别为,RenntrantLock实现了更多高级的功能,例如:
-
等待可中断:可以为线程设置等待超时时间
-
公平锁:多个线程按照先来后到顺序获得锁
-
Condition:Object的wait和notify的另一种实现,可以实现对其他线程的独立控制
jvm在后续改进中,synchronized的性能和ReentrantLock的性能也差不多
非阻塞同步
互斥同步本质上是悲观锁,代码进入同步区域会首先加锁,而非阻塞同步则是乐观锁,即先进行操作,如果没有其他线程争用共享数据,则操作成功,如果产生了冲突,则采取其他的补救措施
乐观锁减少的是在冲突较少的场景下,加锁解锁的开销,而在冲突较多的场景下,乐观锁比悲观锁性能更差
CAS是乐观锁的一种实现,它有三个属性:目标值地址,旧的目标值,新的目标值。只有当旧的目标值和地址中的值相等时,才会将地址中的值修改为新的目标值。但可能出现ABA问题,JUC中使用变量版本号来解决该问题。不过一般来说,这种问题并不会对程序造成影响。
无同步
如果没有共享数据,那就不用考虑同步问题。例如纯函数,或者栈上分配技术,或者ThreadLocal数据等
锁优化
自旋锁
使用忙循环来代替线程阻塞唤醒的内核态开销
但自旋只适用于短时间的共享资源占用,jdk6引入自适应自旋,当上次自旋成功获得锁后,则认为这次也可能成功获得锁而自旋,因此运行自旋更长时间,但如果很少有自旋成功的,则自动省略自旋进入阻塞
锁消除
如果经过逃逸分析发现共享变量不会被其他线程共享操作,则将锁消除
锁粗化
如果一段代码内频繁地加锁解锁,则可能优化为对整段代码一次性加锁
轻量级锁
对象内存布局为:对象头+数据部分+对齐填充
而对象头又分为:markword + 指向方法区Class的指针(数组的话还需要加上数组的长度)
markword在32位机下长度为32位(64位机下为64位),其中25位存储对象hash值,4位存储GC年龄,2位存储锁标志位,1位表示偏向锁是否可用。其中前25+4+1=30位内容会随着锁标志位的变化而变化,具体为:
| 锁标志位 | 前29位存储内容 | 对象状态 |
|---|---|---|
| 01 | 对象hash+GC年龄 | 未锁定 |
| 00 | 指向栈帧中 锁记录 对象的指针 | 轻量级锁 |
| 10 | 指向Monitor(管程)对象的指针 | 重量级锁 |
| 01 | 偏向线程ID、偏向时间戳、GC年龄 | 可偏向 |
| 11 | null | GC标记 |
轻量级锁加锁过程:
JUC学习笔记
volatile
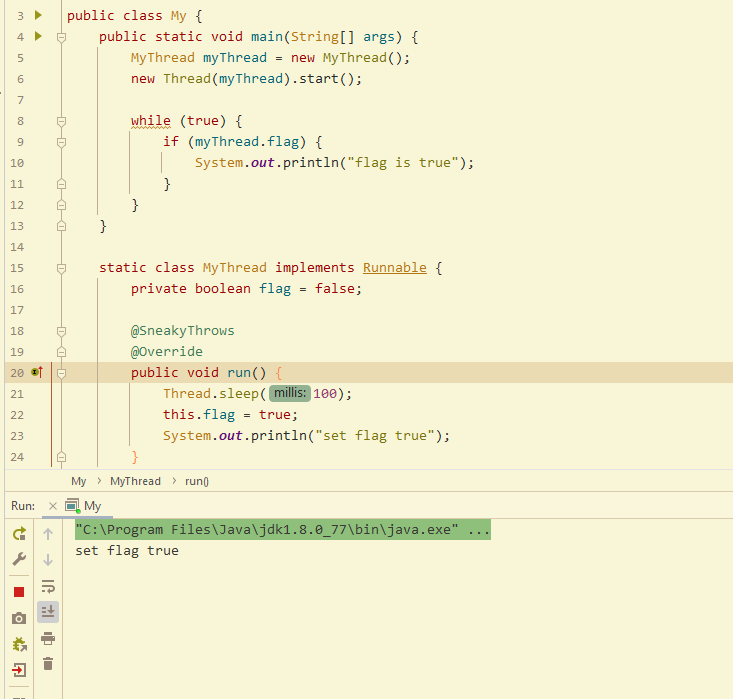
- 关于上述程序的说明: main方法中开启了两个线程,一个共享数据flag。myThread线程在100毫秒后将flag修改为true,主线程循环读取flag,如果为true则打印一句话。 但是执行结果发现,即使myThread将flag修改为true,主线程仍然没有打印任何值。
- 解释: 每个线程都会有自己的工作线程,且他们共享一块主内存。myThread线程从主内存读取数据后,在工作内存中修改数据并同步进主内存,但由于 while(true) 执行效率非常快,main线程从主内存获取数据之后根本来不及重新从主内存中读取数据,所以一直读取的是旧数据。解决方案:死循环中加入延时/加入同步锁/使用volatile修饰变量
volatile
使用内存栅栏技术(防止指令重排序),使得线程每次获取数据都是从主存中获取 相较于synchronized是一种更轻量级的同步策略
缺点
- 不具备互斥性,可以多线程同时读写
- 不保证操作原子性
原子变量
使用volatile能保证可见性,但是无法保证对变量修改的原子性(例如 i++ 问题),此时可以使用 java.util.concurrent.atomic 包下提供的常用原子变量
- 这些原子变量内部都使用了volatile保证可见先
- 对这些变量的修改都使用了 CAS 保证数据的原子性
private AtomicInteger num = new AtomicInteger();
num.getAndIncreasment(); // 自增
CAS
包含了三个操作数 内存值V,预估值A,更新值B。当且仅当 V== A 时,才会将B赋给V。这三步是同步的 会出现ABA问题
synchronized
synchronized 默认使用当前对象作为锁,如果是静态方法则使用当前class对象作为锁。 在某时刻内,只能有一个线程能够获取锁
ConcurrentHashMap/CountDownLatch
线程安全的Hash表
- HashMap 和 HashTable HashMap线程不安全 HashTable线程安全,但效率低,每个方法都使用同步锁,并且复合操作(例:如果存在即修改)也是线程不安全
ConcurrentHashMap 锁分段机制
并发级别(concurrentLevel)
默认分为16段(segment),每个段中又有一个16单位长度的数组,数组的每个元素下又挂着一个链表 这样的话每个段都有一个独立的锁,所以可以多线程同时访问多个不同的段 jdk1.8之后每个段也修改为使用cas操作
- 此包下还提供了很多其他的集合,例如 CopyOnWriteArrayList,该类也是一个集合,用法同 List,但是每次向其中添加元素时,它都会重新复制一个新的List并指向原集合。所以对集合有很多的添加操作时效率较低,开销大。通常可以用于多线程使用迭代器遍历,并在遍历过程中添加元素(注:普通的list即使在迭代器遍历过程中添加元素也会报错)
CountDownLatch 闭锁
在进行某些运算时,只有其他所有线程的运算全部完成,当前运算才继续执行
// 这里的 2 代表这个闭锁可以监控2个线程是否结束,内部维护一个整型变量=2,每次子线程结束就-1,直到为0
CountDownLatch latch = new CountDownLatch(2)
new Thread(new MyThread(latch)).start();
new Thread(new MyThread(latch)).start();
latch.wait(); // 会一直等到闭锁值为0
class MyThread implements Runable{
private CountDownLatch latch;
public void run() {
// do something
this.latch.countDown(); // 子线程结束后,需手动将闭锁减一
}
}
Callable接口
创建线程的方式有四种