Jvm
《深入理解java虚拟机》第三版笔记
- 第一款商用虚拟机ClassicVM使用的是基于句柄的对象查找方式。这样做的目的是当对象移动时不需要修改对象引用的位置。缺点是需要两次定位对象。
- GraalVM,是一个再HotSpot的基础上增强而来的跨语言全栈虚拟机,可以运行java、Scala、Kotlin等基于jvm的语言,还有C、C++、Rust等基于LLVM的语言,同时还支持JS、Ruby、Python等。GraalVM可以无额外开销地混用这些语言
- 自JDK10起,HotSpot加入了全新的Graal编译器,顾名思义,它源于GraalVM。它本身就是用java编写的,目的是替换C2编译器
- NIO引入基于Channel与Buffer的IO方式,直接分配堆外内存,避免java堆与Native堆来回复制数据
- 对象分配内存使用指针碰撞或者空闲列表的方式,具体使用哪个取决于垃圾回收器的实现。不管哪种方式都可能出现并发问题,jvm通过CAS和TLAB解决
- new对象过程:检查类有没有被加载,如果没有则先执行 加载链接初始化的过程 -> 堆内存中分配地址并赋0值 -> 设置对象头信息包括GC分代、锁状态等 -> 执行对象构造器方法
- 对象的内容包括 对象头、实例数据、对齐填充
- 对象头信息中包含markword、类型指针(非必须)、数组长度(数组类型才有)
- 实例数据中保存着对象中的各个字段内容,包括从父类继承下来的
- 不停添加栈帧是报栈溢出还是内存溢出异常?
当栈内存固定时报栈溢出(hotspot),如果是动态扩展的(classic),则是内存溢出
- 基于分区的垃圾回收器(G1、CMS等)可能出现待清理的分区中含有别的分区所引用的对象,为了避免整堆扫描,会给每个区分配一个 Remember Set 用于记录哪些对象被其他区引用,它也将加入GCroot中进行扫描。记忆集只是一个抽象接口,它的一个实现是卡表,卡表记录了分区之间是否存在对象依赖关系(只记录两个分区的依赖,并不记录分区内部具体哪个对象的依赖),卡表本质上只是一个标记数组
- 卡表是如何维护的?
如果其他区的对象引用了本区中的对象,则那个区的卡表就应该被修改,形成脏表。问题是如何实现这一过程,HotSpot是使用写屏障(和内存屏障不同)实现的,所谓写屏障,可以理解为是aop的过程,即在对象引用这个动作前后加上一段维护卡表的代码
- 进行GCroot扫描时,由于栈空间也很大,如果直接扫也很浪费时间,所以会将对象的引用专门存储到一个名为 OopMap 的数据结构中,扫描时只扫它就够了
- ParNew是Serial多线程版本,Parallel Scavenge与ParNew差不多,区别在于PS更关注吞吐量(用户线程时间/总时间),而CMS、ParNew等关注缩短单次STW的时间,两者是不一样的,缩短单次的时间意味着收集的次数变多,而每次收集都会有额外开销,所以反而使得吞吐量降低了。
- G1垃圾收集器中,为每一个region都设计了两个名为TAMS的指针,在并发标记过程中,如果有新的对象需要分配内存,就会分配到这两个指针内,这两个指针内区域的对象默认都是存活的,不会被垃圾回收
- 三色标记法如何解决并发标记过程中的动态引用变化?
CMS使用增量更新算法实现:已经标记为黑色(所有的引用它的对象都已经扫描过)对象再引用其他对象时就会被修改为灰色
G1使用原始快照算法实现:有新的引用关系建立时,就记录下这个关系,后续重新扫描这些记录
- Shenandoah是一款只有OpenJDK才有的垃圾收集器,它能实现再任何大小的堆内存中都将STW时间控制在十毫秒内,对比于G1和CMS,它不仅能进行并发标记,还能进行并发内存整理,并且其没有年轻代和老年代的区别,并将G1的每个region维护的记忆集修改为一个“连接矩阵”,便于统一管理维护。其他基本和G1差不多
- Shenandoah如何实现并发整理?
在原本的对象头前面增加一个指向该对象的指针,正常情况下,该指针指向本身这个对象,但在并发整理时,会将该对象复制到其他地方,该指针就会指向新的那个对象地址。缺点是每次对象访问都是两次定位,类似于句柄访问对象的方式。Shenandoah使用CAS的方式保证这一过程的安全
- ZGC的目标和Shenandoah相似,都是要实现不影响吞吐量的情况下,将任意堆的收集时间控制在10ms。它也是基于Region并且不设分代。区别在于ZGC的region可以动态变化,并且ZGC的并发整理要优秀很多(见下)
- ZGC的并发整理的原理?
实际上,GC过程中,很多步骤不需要知道对象的具体内容,而只需要知道对象的状态,例如在三色标记过程中,只需要知道对象之间的依赖关系,而不需要知道对象的内容。传统的做法是将一些与对象本身无关的信息记录在对象头,例如GC分代年龄、锁信息等,但如此一来,就是你只需要对象头中的某些信息,你也必须找到该对象的具体位置(因为对象头也是对象的一部分),这样会造成多余的消耗。而ZGC就是直接将一部分信息存放到对象的指针上,这样只要知道对象的指针就够了,而不用真正去访问对象的内容。这种方法称之为“染色指针”
为什么可以这样做?
因为实际上,在64位系统中,一个指针的范围非常大,而实际上现在的cpu架构也只会用到部分长度(AMD64只支持到52位长度),所以很大一分部都浪费掉了,ZGC就是利用指针的这部分空间存储相关数据
- 向 HashMap<Long, Long> 添加一个kv会额外占多大内存?
long类型占8字节,而包装称Long类型,则需要添加8字节的Markword,8字节的Klass指针,需要24字节,两个Long则需要48字节,然后这两个Long组成一个Map.Entry对象后,又需要16字节的对象头(markword和klass指针),并且Entry需要一个8字节的next字段和一个4字节的hash值(另外需要4字节填充),这一共又是32字节,然后HashMap需要有一个指向该Entry的8字节指针,所以一共占了 48 + 32 + 8 = 88 字节
java中的动态链接
以下为我个人的理解:
在java中,有两个地方会提到动态链接,一不小心弄混了就会非常困惑
一个过程
假设我写了两个方法:
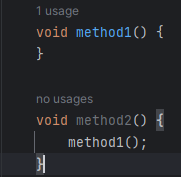
method2的字节码指令为:
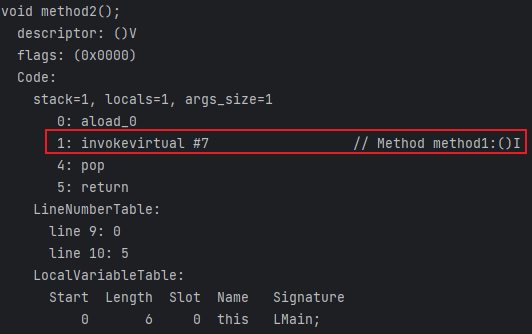
其中 invokevirtual 表示执行的是一个虚方法,所谓虚方法,就是只有代码在运行期间才知道真正调用的是哪个方法(final 修饰的方法除外),而不是在编译期间就确定的。
后面的 #7 指的是常量池中字符串常量的引用,将引用具体化可以得到 Method method1:()I,后面得到的这一串字符就是符号引用
为什么这里执行 method1 是一个虚方法?因为你不确定子类或者父类是否重写了该方法,所以编译期间你根本不知道它调用的到底是哪个方法。只有真正运行后,知道是哪个对象调用的该方法后才能确定应该调用谁的方法
所以在真正调用该方法前,这个被调用的方法仅仅是一个符号引用,每次只有真正调用该方法时,才会将该引用转换为所调用方法的直接引用,这个运行时才确定直接引用的过程,就称之为动态链接。
注意:这里的动态链接是一个过程,或者说是一种思想
一个引用
JVM会在调用每一个方法前,都在方法栈头创建一个栈帧,该栈帧是一种能够支持函数调用所有信息的数据结构,它是一个具体的存在。
而栈帧中会保存一个指向常量池的指针,该指针实际指向常量池中该方法的实际引用。这个指针就是动态链接。
注意:这里的动态链接是一个指针,它是一个有形的实体
方法在调用时不是已经确定了自己的引用吗,为什么还要保存自己的引用?
-
便于获取栈信息:例如我们在debug或者保存栈快照时,它能告诉我们栈中到底有哪些函数
-
函数结束执行后可以知道它的返回值是哪个方法返回的
-
另一种说法是方法在调用时并不会一次性加载所有的方法信息,例如异常表等,只有真正出现异常后才去方法区加载该方法的异常表,那么这个过程肯定得知道该方法到底属于方法区的哪个方法。
引自上文:Often, it is better to take a more abstract and high-level view of things. An Activation Record is a data structure that holds all the information needed to support one call of a function. It contains all the local variables of that function, and a reference (or pointer) to another activation record; that pointer is known as the Dynamic Link. Stack Frames are an implementation of Activation Records. The dynamic link corresponds to the “saved FP” entry; it tells you which activation record to return to when the current function is finished. The frame pointer itself is simply a way of indicating which activation record is currently in use. The dynamic links tie all the activation records for a program together in one long linked list, showing the order they would appear in a stack.
jvm学习笔记
基于栈和基于寄存器的指令集架构
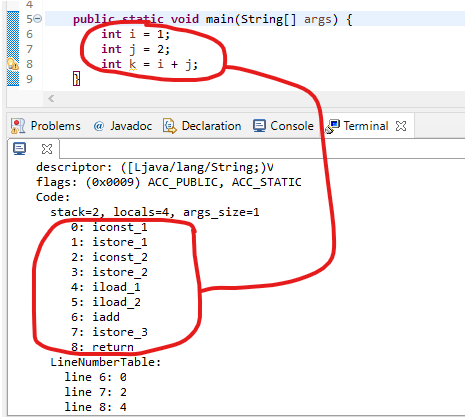
Jvm前端编译器架构=都是= 基于栈 的指令集架构,与之对应的还有 基于寄存器 的指令集架构。### 基于栈的指令集架构
* 跨平台性好、指令集小、指令多、性能相较于寄存器更差
* 例:
基于寄存器的指令集架构
* 直接使用cpu的指令集,故执行幸能更好,但是移植性较差
Hotspot/JRocket/J9
JRocket:号称最快的虚拟机,专注于服务端,牺牲程序启动速度,因此其内部不包含解析器的实现,全部代码都即时编译器编译后执行
J9:运行IBM自己的软件时速度较快,J9最厉害的地方是它高度模块化,不但可以部署在桌面或服务器上,还可以部署到嵌入式环境中,例如CLDC级别的环境;这些环境用的是同一个J9核心VM,搭配上适用于具体环境的GC和JIT编译器。
hotspot:运用最广泛的虚拟机
类加载子系统
graph LR
加载 ---> 验证
subgraph 链接
验证 ---> 准备 ---> 解析
end
解析 ---> 初始化
类的加载过程
- 加载 加载二进制流并产生对应的Class对象。
- 链接 2.1 验证
- 确保class文件的字节流满足当前虚拟机的要求,保证被加载类的正确性
- 主要包含四种验证:文件格式验证(例如是否以魔数开头),元数据验证,字节码验证,符号引用验证 2.2 准备
- 为类变量分配内存并且设置该类变量(static修饰的变量)的默认初始值,即零值。如 int i = 3,则在此阶段将i赋值为0。
- 注:这里不包含被final修饰的类变量,它在编译的时候就已经赋零值了,在准备阶段会显示初始化,即 i 赋值为3。
- 准备阶段不会为实例变量初始化,类变量会分配到方法区中,而示例变量则会随着对象一起分配到java堆中。 2.3 解析
- 将常量池内的符号引用转换为直接引用的过程。
- 初始化
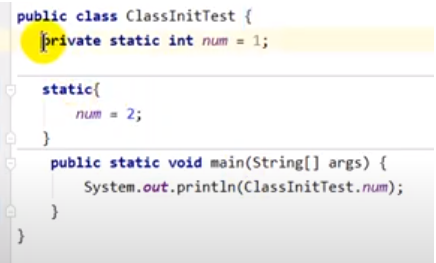
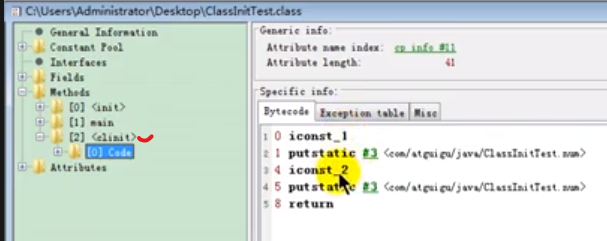
- 初始化阶段就是执行类构造器方法()的过程。
- 该方法不需要定义,由javac编译器自动生成(如果没有类变量或静态代码块就不会生成该方法)。不同于类的构造器,即()
- 构造器方法中的指令语句按照源文件出现的顺序执行。
- 若该类有父类,则一定要保证父类的()已经执行完毕了
- 虚拟机必须保证一个类的()方法在多线程下被同步加锁。
类加载器

-
虚拟机规范中规定类加载器只有两种,启动类加载器(bootstrap class loader)和用户自定义类加载器(凡是直接或间接继承自ClassLoader类的均为用户自定义类加载器)
-
Bootstrap class loader使用的是c/c++编写,其他类加载器使用java编写。