Mysql
《MySQL是怎样运行的》笔记
https://book-how-mysql-runs.netlify.app/#/
结构
-
MySQL是 C/S 架构,一个服务端负责真正与储存的数据打交道,多个客户端连接服务端用于发送指令(例如SQL)
-
mysql客户端连接服务端:mysql -h localhost -u root -p12345(注:-p后面不能有空格)
服务端处理客户端请求的过程:
-
处理连接:客户端与服务器的连接方式有多种,例如TCP/IP连接、管道或共享内存、Unix域套接字
-
解析与优化:查询缓存(查询系统表时不会走缓存,8.0后不使用缓存,避免太大开销) -> 语法解析 -> 语法优化
-
存储引擎:InnoDB、MyISAM、Memory…,用于封装数据的存储和提取操作
通过上述内容可看出,mysql的架构也可以分为三层:客户端 -> MySQL server(负责管理客户端连接、缓存、语法解析和优化等操作) -> 存储引擎
查看MySQLServer支持的存储引擎:`show engines;`
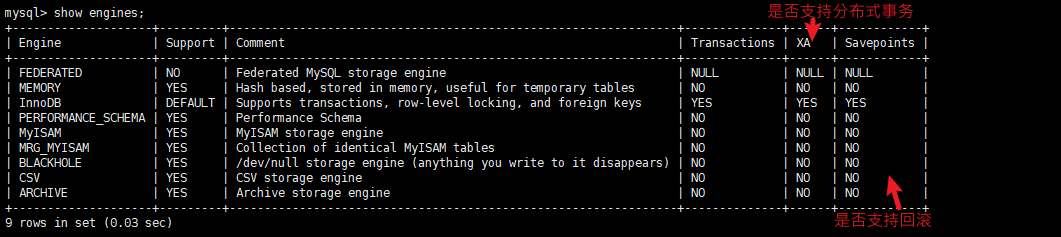
存储引擎是针对表的,可以在表创建时指定,也能在创建后使用alter命令修改。
配置
在启动mysql服务端或客户端时,可以在命令后面跟上一些参数用于控制mysql的默认行为。
例如,启动mysql 服务端可以通过 mysqld -P3307 或 mysqld --port 3307 来指定端口
也可以通过修改配置文件的方式,配置文件的查找路径为:`/etc/my.cnf、/etc/mysql/my.cnf、SYSCONFDIR/my.cnf、$MYSQL_HOME/my.cnf …`
配置文件内容
类似于 .ini 文件的配置
[server]
option1 = value1
(具体启动选项。。。)
[client]
(具体启动选项。。。)
[mysqld]
(具体启动选项。。。)
。。。
不同的启动命令所能读取的配置组是不同的,例如使用mysqld启动服务端就会读取 [ mysqld]、
\[server\]两个组,使用mysql 启动客户端就会读取
\[mysql\]、[client ] 两个配置组
配置优先级
配置文件可以有多个,会一个一个加载,就像springboot一样,如果有多个配置文件都配置了同一个选项,则以最后一个为准
同一个配置文件在不同配置组中出现了相同的配置,则也以最后一个组为准
如果启动命令中有相应的配置参数,则以命令中的为准
环境变量
可以使用以下命令查看:
MySQL笔记
存储引擎
MySQL的结构:连接层 -> 服务层 -> 引擎层 -> 存储层
各存储引擎的特点:
InnoDB
支持 事务、外键、行级锁
MySQL中,数据库对应文件系统中的一个文件夹,每个InnoDB表都对应该文件夹下的一个 .ibd 表空间文件,该文件用于存储表结构、索引、数据
表空间文件存储的逻辑结构为:
-
一个表空间下存放多个段
-
一个段下存放多个区,一个区大小为1M
-
一个区下存放多个页,一页大小为16K
-
一个页下存放多个行
-
一行就表示表中一行数据,需要注意的是,除了本身就有的字段外,还额外有 事务id 和 Roll指针
MyISAM
不支持事务、外键、行级锁,支持表锁
在文件系统中以三个文件表示:.sdi(表结构) .MYD(数据) .MYI(索引)
Memory
数据存放在内存中,支持hash索引
只保存一个 .sdi 文件,用于保存表结构数据
索引
索引能提高查询速度,但会拖慢增删改的速度
索引设计原则总结:

索引结构
B+树索引:三个存储引擎都支持
Hash索引:只有Memory支持,高效率,不支持范围搜索,不支持排序
B树和B+树的区别:B+树所有数据都存放在叶子节点中,并且叶子节点形成一个单向链表。MySQL中,将单向链表修改为双向链表
为什么MySQL使用B+树做索引?
不管是用B树还是红黑树还是B+树,每个节点都需要保存在页中,而一页的大小是固定的(16K),如果在里面存放数据,则一页就存不了多少索引,而B+树只存放索引,故可以存放更多索引,层级更低,且将叶子节点连接可以用于顺序搜索
索引分类
索引类型:
-
主键索引:只能有一个
-
唯一索引:可以有多个
-
常规索引
-
全文索引
根据存储形式,又分为:
-
聚集索引:必须有且只有一个,叶子节点存放行数据。默认是主键索引,如果没有主键,则使用第一个唯一索引,否则自动生成一个rowid作为隐藏列当作聚集索引
-
二级索引:可以有多个,例如对任意列手动创建的一个普通索引。叶子节点存放主键,此时需要回表查询(根据主键再去查聚集索引)
索引操作
# 创建索引,加上 UNIQUE 表示创建唯一索引,索引可以指定多列,及为联合索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON TABLE_NAME (col1, col2...)
# 查看索引
SHOW INDEX FROM TABLE_NAME
# 删除索引
DROP INDEX FROM TABLE_NAME
SQL性能分析方式
慢查询日志
Ubuntu22安装MySQL8
安装
首先更新一下源
sudo apt updatesudo apt upgrade
比较慢或者常报网络错误可以使用国内镜像,使用方法和镜像地址见:https://mirror.tuna.tsinghua.edu.cn/help/ubuntu/
安装很简单,一条命令即可
sudo apt install mysql-server
启动MySQL
sudo service mysql start
至此,有些教程会说 执行 sudo mysql_secure_installation 命令,但其实在测试环境中,这个命令不是必要的,并且它默认使用 auth_socket 这个密码插件,这个插件可以让你不需要密码登录MySQL,所以会让你觉得困惑,我怎么都不用设置root密码?所以我建议先跳过这一步,待下面的步骤都走完了,再执行这个进行安全设置也不迟
注:auth_socket是一个密码校验的插件,它可以让你使用本机用户登录MySQL,另外还有 mysql_native_password 以及MySQL8中默认的 caching_sha2_password,这俩就需要设定密码。参见:https://kohasupport.com/what-is-the-difference-between-mysql-plugins-mysql_native_password-caching_sha2_password-and-auth_socket-plugins/
修改配置使得其可以远程访问
这点很重要,默认只能本机访问,我一开始觉得很纳闷,明明我创建了可以远程访问的账户,但依旧是无法访问,后来发现这里没改
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
将原本的

修改为

其中 0.0.0.0 表示任何主机都可以访问,也可以将其改为指定的主机
初始安装MySQL后,root不需要密码,可以直接使用下面的命令进入MySQL-CLI
sudo mysql
修改root密码
alter user 'root'@'localhost' IDENTIFIED WITH mysql_native_password by 'yourpassword';
修改完成后,退出MySQL-CLI,再进入的话就需要root密码了,使用以下命令进入
mysql -u root -pyourpassword
注意,仅在做实验测试的话可以直接将密码写出来,-p后面直接跟密码,不需要空格
创建用户
此时还不能远程访问,因为目前的root用户为 ‘root’@’localhost’,即仅为本机可以访问,最佳实践是创建一个新的管理员账户
create user 'hunt'@'%' identified with mysql_native_password by 'yourpassword';
主机部分使用 % 即表示该用户可以从任何主机访问
其中 with mysql_native_password 表示使用 mysql_native_password 这个授权插件进行密码校验,可以不要该部分,在MySQL8.0环境下,默认使用的是 caching_sha2_password 这个密码插件,它更安全但是较慢。
MySQL学习笔记
概述
索引的数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
- 每个索引都可以选择不同的数据结构
使用红黑树保存索引数据,仍然会因为树的高度增加带来的查询效率的衰减,解决方案是每个节点多放几个索引数据,即B树,为了更高的查询效率,在B树的基础上衍生出B+树
B和B+树的区别
- 非叶子节点不保存数据,只保存树索引
- 叶子节点使用指针链接
B+树每个节点默认是16kb,每个索引14字节,所以一个节点可以存1170个索引元素
-
myISAM 和 InnoDB是形容表的,不是形容库的,所以每个表都能有不同的存储引擎
-
MyISAM中B+树索引的叶子节点的data元素保存的是数据库某一行的索引(在文件系统中索引和数据分两个文件存储),而InnoDB叶子节点中的data保存的就是某一行的数据(索引和文件保存在同一个文件中,即
聚集索引) -
InnoDB表必须要有主键,并且推荐使用整型自增 每个节点中保存了很多的索引数据,如果没有使用UUID作为主键则需要先转换成为acsii进行比较。并且整型更节约空间 使用自增的原因是因为查找可能是范围查找,就可以直接遍历叶子节点 方便插入和删除(树的插入和删除复习)
-
联合索引 按照联合索引顺序将多个索引统一保存在B+树的每一个节点中,查找时,如果节点中的第一个元素相同,则比较下一个,以此类推
-
每次查询的时候,文件系统最少会向内存中加载一页的数据(即一个节点16kb,类比操作系统的
局部性原理) -
表中的每一行都会有一种行格式,比如COMPACT、Dynamic、Compress等。每一种行格式所记录的每一行的数据格式不尽相同,例如COMPACT格式记录的一行数据为: 变长字段长度列表+NULL标志位+记录头信息+列1数据+列2数据。。。
- 变长字段长度列表: 按可变长字段顺序保存该字段长度,例如 name varchar(20) 是该列第3个元素,则在该变长字段长度列表的第三个位置保存实际存储的name的实际长度 注:innoDB每一行元素占用总内存不得超过65535字节,blobs类型字段除外。但是一页只有16k的数据,
故超过一页大小的数据就需要分页,不同的数据库引擎分页方式不同,例如InnoDB中,分页数据的第一页不存储数据,只存储下一页的地址,方便索引 - NULL标志位 表中的某些字段允许为空,则该字段中按照允许为空的字段顺序存储01,其中0代表该值为空,1代表不为空,例如00101
- 变长字段长度列表: 按可变长字段顺序保存该字段长度,例如 name varchar(20) 是该列第3个元素,则在该变长字段长度列表的第三个位置保存实际存储的name的实际长度 注:innoDB每一行元素占用总内存不得超过65535字节,blobs类型字段除外。但是一页只有16k的数据,
存储结构/索引
InnoDB
- InnoDB查询出来的数据会自动根据主键进行排序,原因是其主键默认也是索引。MySIAM查询出来的顺序是插入时的顺序
InnoDB数据存储格式

表中的数据以数据页为单位在磁盘中进行存储,每一页有16KB,每一页数据都会携带除用户数据以外的数据,例如下一页的数据,和该页的分组数据。例如:如果表中每一行元素只需要存很少数据,则一页数据就可以存很多行数据,所有的行数据形成一个链表,如果一页数据量过大,则查询效率会减小。 此时就会将这一页的数据分成n个组,例如(1-4)(5-9)…,每个组保存最小数据的指针,保存在页的头信息中,即分组数据。 这样的话,如果查询某一个数据则会先去分组数据里面找,然后直接在命中的分组中进行查找。 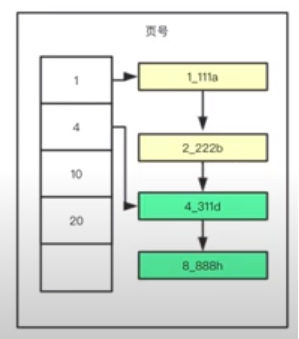
-
目录页 一张表中的数据会存储在多个页中,那么查找数据时如何知道在第几页? 在这些页之上又抽象出一种目录页的结果(即B+树中的非叶子节点),目录页中存储了每一页的最小索引的位置
-
如果建表时既没有定义主键,也没有定义唯一列,则InnoDB会自动创建一个名为 rowID的自增字段
-
MySql在创建表时会自动创建一个空页,当向表中存数据时就会向该页存,当该页存满时,
会复制当前页到新的一页,然后再创建一个新页存储新的数据,并将第一页数据清空,升级为这两个新页的目录页,这样做的好处是保持查找开始内存位置不变,将第一页常驻内存,加快查找速度 -
创建多个字段联合索引 会将这些字段拼接起来进行排序(建立索引的本质就是排序),
并在该索引的B+树的叶子节点只保存数据行的主键(即每创建一个索引都会创建一个B+树,但是除主键索引外,其他的都不保存行数据),然后根据该主键再去主键索引查找行数据 如果建立的索引列的数据都相似或者相同,则创建出的索引意义不大,Mysql会自动在这种索引中加上主键索引,保证索引唯一
可以使用 explain SQL 查看是否使用索引
注:
- mysql中的utf8格式其实只是真正的utf8的子集,它认为你不会存一些非常少见的字符,真正的utf8应该是utf8mb4
- 定义字段时也可以指定排序规则,比如对于字符串的比较,可以将其转换为ascii比较,也可以转换为二进制比较,使用以下方式设置
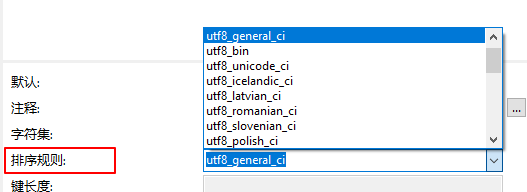 例如,以_bin结尾的就是转换为二进制比较
例如,以_bin结尾的就是转换为二进制比较
事务
使用begin/commit/rollback开启/提交/回滚事务,可以开启或关闭Mysql的自动提交(默认开启使用begin/commit/rollback开启/提交/回滚事务,可以开启或关闭Mysql的自动提交(默开)
-
隐式提交 使用ddl时会自动隐式提交数据
-
保存点 创建事务后,提交前,可以创建多个保存点。当需要回滚时可以指定回滚到某个保存点
四种事务隔离
- 读未提交(Read Uncommitted) 事务即使没有提交,其他地方也能读到该未提交的数据 会出现脏读
-
读已提交(Read Committed) 必须提交之后其他地方才能读到数据,但是其他地方的事务中,即使没有提交,但是表发生了变动,同一个事务中也会查出不同的结构 会出现幻读和不可重复读(两者本质相同)