Python
python孤儿进程示例和解决方法
子进程原本的父进程停了,它就会由系统的init进程接管,这个子线程就成了孤儿进程,另外还有个僵尸进程的概念,说的是进程已经结束了但是资源没有被父进程清理。
在python中很容易产生孤儿进程,例如以下代码:
import timeimport multiprocessingdef sub_task(): """子进程任务:循环打印时间和父进程状态""" while True: print(f"{time.asctime()}, {multiprocessing.parent_process().is_alive()}") time.sleep(1)def parent_task(): """父进程任务:开启一个循环打印的子进程,然后睡5秒""" sub_p = multiprocessing.Process(target=sub_task, daemon=True) sub_p.start() time.sleep(5) # 将这里的5s修改为2s试试if __name__ == "__main__": p = multiprocessing.Process(target=parent_task, daemon=False) p.start() # 创建“父进程”后主进程睡3秒然后停掉“父进程” time.sleep(3) p.terminate() p.join() p.close()
上述的代码执行起来就会有问题,你会发现,即使已经将子进程设置为守护进程(daemon=True),将其父进程结束后,该子进程仍然在在打印,但是父进程状态(is_alive())由原来的 True 变为了 False,该进程已经成为了孤儿进程
但是,如果你将上述父进程休眠时间从5秒修改为2秒,则子进程也会随着父进程的退出而退出。
上述代码运行后,通过实验或任务管理器你会发现,父进程确实是在3秒后直接终止了,而子进程却没有。问题就在于父进程是正常退出还是异常退出,当父进程在执行terminate()之前已经执行完了(设置2s的休眠时间),则为正常退出,此时父线程会自动清理其子进程。而如果在执行terminate()的时候父进程仍然在执行(sleep() 设置为5)则为异常退出,此时它还没来得及清理其子进程,故而其子进程成为了孤儿进程
一个比较好的解决方法是使用进程间通信,例如使用 multiprocessing.Event:
import timeimport multiprocessingdef sub_task(): """子进程任务:循环打印一个东西""" while True: print(f"{time.asctime()}, {multiprocessing.parent_process().is_alive()}") time.sleep(1)def parent_task(shutdown_flag): """父进程任务:开启一个循环打印的子进程,然后睡5秒""" sub_p = multiprocessing.Process(target=sub_task, daemon=True) sub_p.start() shutdown_flag.wait()if __name__ == "__main__": shutdown_flag = multiprocessing.Event() p = multiprocessing.Process(target=parent_task, args=(shutdown_flag,), daemon=False) p.start() # 创建“父进程”后睡3秒然后停掉“父进程” time.sleep(3) shutdown_flag.set() p.join() p.close() print("main done")
multiprocessing.Event() 可以理解为一个bool值,有四个方法:
%:取余 vs 取模
刚才发现,这个符号在python中表示取模,而在其他一些语言中,例如 Java、Javascript、Golang 等,表示的是取余。这两者有什么区别呢?
现象
计算下面这个式子:
-5 % 3
# 在 python 中,它等于 1
# 在 java 中,它等于 -2
计算


优势
python中经常会有切片操作,取模则可以简化这一操作,例如取一个长度为5的数组中倒数第3个元素,最直接的做法为 arr[ -3],当然也可以写 arr[2 ]。事实上,如果你使用python计算 -3 % 5 你就能得到 2,正方向index和负方向index可以很轻易地转化。但是使用 java计算得到的却是 -3。
python:多进程共享复杂的可写对象
本来想用该方法共享一个模型的,一个进程用于收集训练数据,一个进程用于训练,但是仍然不行。但基本的进程共享内存空间对象还是可以的:
from multiprocessing import Process
from multiprocessing.managers import BaseManager
# 第一步:定义需要共享的类
class Data:
"""
该对象处于共享内存中,其内部属性(即使是自定义对象)也是在共享内存中
"""
def __init__(self, n=0):
self.num = n
def add(self, i):
# 注:该操作进程不安全,需要加锁才能保证安全
self.num += i
def get_num(self):
return self.num
# 第二步:创建一个继承 BaseManager 的类,内容可以为空
class MyManger(BaseManager):
...
# 第三步:注册共享类
MyManger.register("Data", Data)
if __name__ == '__main__':
# 第四步:创建自定义Manager对象并启动
manager = MyManger()
manager.start()
# 第五步:获取共享对象的引用,该对象已经位于共享内存中,但它其实是一个代理对象,其类型为 AutoProxy[Data],所以你不能直接获取其 num 属性
d = manager.Data()
p1 = Process(target=d.add, args=(1,))
p2 = Process(target=d.add, args=(1,))
p1.start()
p2.start()
p1.join()
p2.join()
# 注:再次强调,由于 d 是一个代理对象,所以你不能直接通过 d.num 获取num的值
print(d.get_num()) # 2,两个进程各自加1
python中进程池要使用 Semaphore 时,需要使用 multiprocessing.Manager().Semaphore() 对象,而不是 multiprocessing.Semaphore() 对象,相应的 Lock、Value也是
python classmethod staticmethod
有两点不同
1. class method 会自动将当前class作为参数传入,但我觉得这并不能让它和 static method 产生差异,因为你完全可以这样写:
class F(): @staticmethod def sm(cls): print(cls) @classmethod def cm(cls): print(cls)F.sm(S) # <class '__main__.F'>F.cm() # <class '__main__.F'>
一般这里会说classmethod可以防止硬编码,我觉得比较牵强,因为你调用的时候实际上已经需要指定调用class了,这里无非是多传了一个参数,看起来不太优雅,不过也可以通过其他方式解决,这样一来,classmethod在某些场景下确实能一定程度使得代码更美观简洁
2. 继承的差别才是我觉得classmethod的优势所在
class F(): @staticmethod def sm(): print(F()) @classmethod def cm(cls): print(cls())class S(F): ...S.sm() # <__main__.F object at 0x00000290C6935120>S.cm() # <__main__.S object at 0x00000290C6935120>
注意到,static method 创建的是父类对象,而class method 创建的是子类对象,所以classmethod的一个典型的应用场景就是创建当前类的对象
class MyClass: @classmethod def create_instance(cls, *args, **kwargs): # do some check before instance be created return cls(*args, **kwargs)
如此一来,不管该类如何继承,都可以直接通过 XXX.create_instance() 来创建对应的对象
python multiprocessing Pipe Queue
两者功能类似,甚至可以说是相同,都是用于多进程通信。两者可以认为是Hibernate和JPA的关系,即Queue可以看作是对Pipe的进一步封装
Pipe的基本形式为:
pipe1, pipe2 = multiprocessing.Pipe()task1(p1, p2): p1.send("bingo") # 进程1向pipe1发送一条数据task2(p1, p2): p2.recv() # 进程2接收pipe中的数据,如果没有数据则会阻塞multiprocessing.Process(target=task1, args=(pipe1, pipe2)).start()multiprocessing.Process(target=task2, args=(pipe1, pipe2)).start()
上面代码为 Pipe 的默认用法,需要注意的是:
就像非对称加密中的公钥和私钥一样,使用公钥加密的数据必须用私钥才能解密,使用私钥加密的数据必须用公钥解密
这里也一样,pipe1 和 pipe2 互为一对,任意一个用来发送数据,就必须用另一个才能接收。
另外,你可以向pipe中send多个数据,但每次调用recv时只会获取一条数据
与Pipe类似的还有 Queue,不同点在于它只是一个实例 queue = multiprocessing.Queue()
事实上,可以认为Queue是对Pipe的封装,这种封装带来了两个好处:1)全双工通信,即一个Queue对象既可以发,也可以收。2)实际上Pipe是有send 限制的,即如果一直send数据但不recv,当占用一定大小内存后,send也会发生阻塞,而Queue就不会。但是,当设置 Pipe(duplex=True) 时,得到的两个pipe就都是全双工通信的了,相当于得到了两个Queue
但也正因为如此,Queue的效率往往更低
另一个不同在于:从设计思想上,Pipe应该被用于两个进程间通信,而Queue则可以应用于多进程间通信。但从实际使用上看,即使将Pipe用于多进程间通信也是没问题的。
参考:https://superfastpython.com/multiprocessing-pipe-in-python
python多继承的问题
__new__
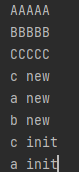
考虑以下代码的输出结果:
class A:
print("AAAAA")
def __init__(self):
print("a init")
...
def __new__(cls, *args, **kwargs):
print("a new")
return super(A, cls).__new__(cls)
a = A()
结果为:

__new__ 是object的一个静态方法,用于创建对象实例,__init__ 用于初始化对象。而上面的 “AAAAA” 则是在加载类的过程中就执行了
多继承下的实例化过程
考虑以下代码输出:
class A:
print("AAAAA")
a_attr = "a"
def __init__(self):
print("a init")
super(A, self).__init__() # 这里的super指的是谁?
...
def __new__(cls, *args, **kwargs):
print("a new")
return super(A, cls).__new__(cls)
class B:
print("BBBBB")
def __init__(self):
print("b init")
super(B, self).__init__() # 这里的super指的是谁?
...
def __new__(cls, *args, **kwargs):
print("b new")
return super(B, cls).__new__(cls)
def bm(self):
print("bbb")
class C(A, B):
print('CCCCC')
def __init__(self):
print('c init')
super(C, self).__init__() # 这里的super指的是谁?
def __new__(cls, *args, **kwargs):
print("c new")
return super(C, cls).__new__(cls)
...
c = C()
print(C.mro())
python:global vs nonlocal
这两者都只有在修改外部作用域变量时才需要,如果只是读取就不用
首先需要区分python中的全局变量和局部变量
全局变量是在函数外定义的变量,即所有定义在def中的变量都不是全局变量,即使是嵌套函数外层函数中定义的变量
相反,定义在函数内部的变量即为局部变量,即使闭包嵌套再多层,也都是局部变量。
如果要在函数中 修改 全局变量(即将原本的引用指向一个新的引用地址,最下面有举例说明),则需要先用 global 声明。
count = 0
def increment():
global count # 修改全局变量前应先声明这里的count是全局变量,否则下一行语句会报错
count += 1
print(count)
increment() # 输出1
increment() # 输出2
如果想要在闭包中修改上层函数中的变量,则需要使用 nonlocal 关键字先声明,它的作用和 global 类似,但是它只能关联嵌套函数中上层函数中的变量。
def outer():
count = 0
def increment():
nonlocal count # 使用nonlocal声明这里的count是上层函数中的count
count += 1
print(count)
increment() # 输出1
increment() # 输出2
outer()
注意:即使上层函数中没有引用的变量,但是上上层有,或者更上层有,也是可以的:
def outer():
count = 0
def inner():
def increment():
nonlocal count # 使用nonlocal声明这里的count是上上层函数中的count
count += 1
print(count)
increment() # 输出1
increment() # 输出2
inner()
outer()
但是nonlocal引用的变量必须是局部变量(定义在函数内部),如果将上述 count=0 定义在最上层(outer()函数外面),则报错。
python的闭包简介
LEGB法则
python变量的作用域遵从LEGB法则,即:
-
Local(L):定义在方法或类内部的变量,如 def 或 lambda 函数内部
-
Enclosed(E):闭包内部变量(仅限闭包)
-
Global(G):全局变量
-
Built-in(B):python内置的关键字
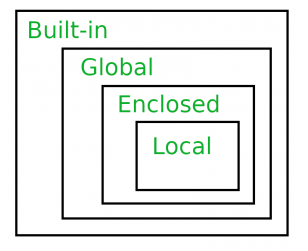
对任意一个变量,python会按照上述顺序依次查找
这意味着python中有且仅有这四个作用域,最小作用域范围就是方法,而没有其他语言中的块作用域,例如下述代码:
def func():
if True:
v = 'bingo'
print(v)
这段代码如果在java中执行就会无法编译,因为v的作用域局限在if的代码块中。而在python中就不会,因为python的最小作用域是func。同样,对于for、while这些代码块也是没有作用域的
闭包
英文名为 enclosing function,我更喜欢称之为“嵌套函数”,因为其本身就是“函数内部定义的函数”
def outlier():
def inner(): # 这个函数就是闭包
...
...
# 你可以在outlier函数内部直接调用inner函数,也可以直接将inner函数作为返回值
这样做的目的是什么呢?我觉得就是创建出一个作用域。如果不看python内置变量的话,在没有闭包的情况下,python仅仅只有两个作用域,对于一个变量,要么在func内部找,要么去全局里面找。这样做的话,对于func内部变量还好说,因为变量已经被func根据不同的功能隔离开了,但对于全局变量的管理就比较混乱了,各种不同功能的全局变量一股脑都在全局环境中。但引入闭包就不同了,它又将func视作一个全局变量环境(仅针对闭包来说),一层一层嵌套,就能更好地管理“全局变量”(并非真的全局变量,仅仅对闭包而言)
这就好比是:在以前,村民有什么问题都去找酋长。现在这种责任关系通过进一步的细分,村民有问题找村长,村长解决不了找县长,县长解决不了找市长。。。
一个综合一点的题目
为什么输出结果是这样?
arr = []
for i in range(3):
def inner(num):
return num * i
arr.append(inner)
for func in arr:
print(func(2))
# 输出结果:4 4 4
分析:
从作用域来说,由于for是没有作用域的,故代码其实等价于:
arr = []
i = 0 # 由于for没有定义域,故for内部定义的变量i等价于在外部定义
def inner(num): # 由于for没有定义域,故for内部定义的函数inner等价于在外部定义
return num * i
for counter in range(3): # for会先给外部变量i赋值,再将函数添加到arr中
i = counter
arr.append(inner)
for func in arr:
print(func(2))
看到没,对于函数inner来说,i就是全局变量,而对于main来说,它是局部变量。这个作用域太大了,而我们仅仅是希望将其限制在for和inner之间。所以,一个解决方法是使用闭包:
python -m
长话短说
简单来说,-m 参数的作用有两个:
-
简化运行方式,你可以直接运行在
sys.path下的模块而不需要指定具体路径(如果直接用python pkgpath则要指明具体路径) -
它会将当前执行的目录也加入到
sys.path,这样即使在代码中使用相对或绝对路径import package_path也是可以运行的(否则就只能引用sys.path中的package了)
具体的
模块
python中的模块分两种:
-
一般的python文件,例如
xxx.py,这个称之为“代码模块” -
一个包含其他模块的目录,这个称之为“包模块”,其目录下的模块既可以是代码模块,也可以是包模块。一般情况下,其目录下会存在一个名为__init__.py的文件
最初-m参数提出来就是为了简化模块的运行方式,例如对于 SimpleHTTPServer(python3中是 http.server),在没有该参数出来之前你需要指定该包的具体路径才能运行
python xxx/xxx/xxx.py
在此之后,因为该包在sys.path中,你只需要直接运行包名即可(注:包名不包含.py后缀)
python -m xxx
事实上,这两种方式运行的效果是一样的,使用-m参数后python解释器会自动帮你找到模块的绝对路径,这和直接在代码中 import module 本质上是一样的
如果某目录(模块)下存在“__main__.py”文件,则你可以直接运行该模块,例如你在 “testmodule” 目录下有两个文件
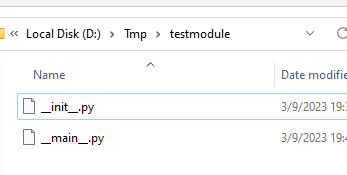
你可以运行
# 均在上述Tmp目录下
python .\testmodule\
# 或
python -m testmodule
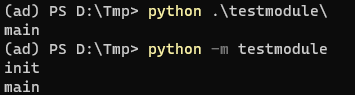
注1:如果是以模块方式运行,则其模块下的“__init__.py”会先运行
注2:import module时也会执行module下的“__init__.py”,如果module就是一个py文件时,它会先将该文件执行一遍
sys.path
sys.path是一个目录数组,你在import module时,python解释器就会遍历这些目录去寻找相应的module,如果没找到就报找不到module的错误,当在命令行中使用-m参数运行module时,它会自动将当前目录加入到sys.path中去,否则就不会,可以在代码中打印出来看看
添加
可以直接使用 sys.path.append(dir) 进行添加,这里需要注意的是,如果使用如下代码进行添加则可能会出问题:
# 以下为错误做法:这里实际上指的不是当前文件所在目录,而是你运行py文件时所在的目录
module_dir = os.path.abspath('./')
# 以下为正确做法,要获取文件所在位置,然后再根据该位置进行调整
module_dir = os.path.abspath(os.path.join(os.path.abspath(__file__), ".."))
sys.path.append(module_dir)

if __name__ == “__main__”:
__name__是个魔法属性,当你执行某module时,该module的 __name__就会等于"__main__",如果是import的module,则该module的__name__就等于该module的名称
import 代码模块时,python解释器会先从头到尾执行一遍该代码模块的代码,有些代码你不想这个时候运行,例如一些测试该模块的代码。此时你就可以将这部分代码放在“if __name__==“main””中,只有你主动执行该模块时,这段代码才会执行
参考
https://stackoverflow.com/questions/7610001/what-is-the-purpose-of-the-m-switch