Redis
《Redis开发与运维》笔记
-
为什么单线程还能那么快
- 纯内存访问,Redis将所有数据放在内存中,内存的响应时长大 约为100纳秒,这是Redis达到每秒万级别访问的重要基础。
- 非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上 Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不 在网络I/O上浪费过多的时间。
-
对于字符串类型键,执行set命令会去掉过期时间,这个问题很容易 在开发中被忽视。
-
设置过期时间为负值,则会立刻删除key。使用persist指令移除过期时间
-
可以使用migrate指令将源redis中的key迁移到目标redis(两个redis实例)。其本质是 dump(源redis执行)、restore(目标redis执行)、del(源redis执行)三个命令的组合,不过是原子操作
-
scan命令
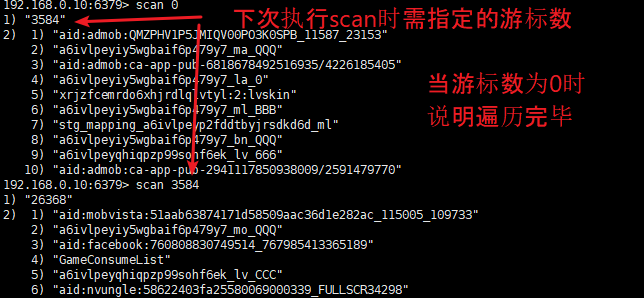
scan命令用于增量遍历keys,类似于keys命令,但是scan命令可以指定分页以达到增量遍历的目的,时间复杂度为O1 但是如果在scan过程中key数量发生了变化,则获取的结果将和实际有偏差
- flushdb/flushall指令用于清空数据库,flushall会清空所有1-16个数据库。可以使用rename指令将其重命名为一个随机字符串避免滥用
除了五种数据结构的存储,redis还提供了其他的功能
慢查询分析、pipeline、事务于Lua、Bitmaps、HyperLoglog、发布订阅、GEO 
慢查询
每次执行命令分4步:
- 客户端向redis服务端发送命令
- 命令排队
- 执行命令
- 返回结果 其中,慢查询分析只到前3步
-
慢查询阈值 在配置文件中加入以下配置
slowlog-log-slower-than=1000000 // 记录大于1秒的命令,如果设为0,则记录所有命令 slowlog-max-len=1000 // 最多记录多少条记录
-
慢查询记录放在哪 慢查询日志是存放在内存中的,可以通过命令进行查询
slowlog get 3 // 获取3条慢查询记录,先进先出队列
Pipeline
批处理命令(如mget、mset)有效地节约了多命令执行时间,但大部分命令不支持批量操作,pipeline就是将多条命令打包一起发送,然后一起返回,降低了命令执行时间
- 原生批处理命令与pipeline对比
- 原生批处理是原子的,pipeline不是
- 原生批处理命令是一个命令对应多个key,pipeline支持多个不同命令
- 原生批命令是redis服务端支持实现的,而pipeline需服务端和客户端共同实现
事务
redis提供了简单的事务功能,将多个命令放在 multi 和 exec 之间即可,事务过程中的命令并没有真正执行 
注:
- redis中事务不支持回滚,如果事务中某个命令出错,其前面的命令仍会执行。
- 如果在事务中某个事务中用到的key被其他客户端修改了,则不会执行该事务,类似于乐观锁 但是这些问题可以使用Lua脚本解决,即使用一段脚本来控制redis,且是原子操作
Bitmaps
Bitmaps可以实现对位操作 其本质就是一个字符串,例如 a 的二进制为1001,虽然Bitmaps存储的是 a,但可以对其二进制进行操作
setbit key 20 1 // 设置key的第20位的值为1(只能是01) getbit key 20 // 获取key的第20位的值