Pytorch
pytorch 安装
报错:
OSError: [WinError 126] The specified module could not be found. Error loading "xxx\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.
安装 VC_redist.X64 没用(即Microsoft Visual C++ Redistributable,这是visual c++的一个运行环境,类比java的jre)
安装 Visual Studio 就可以了,https://visualstudio.microsoft.com/zh-hans/vs/features/cplusplus/

后面可能还会报没有 numpy,安装numpy后又报 _ARRAY_API not found 错误,检查一下是不是安装的 numpy 2.x,卸载重装
python -m pip uninstall numpy
# 安装 1.24.0 也会报错
python -m pip install numpy==1.26.4
pytorch多卡训练的一些问题
多卡训练时的batch_size设置
问:假设我有4张卡,我将batch_size设置为64,那么是每张卡上都有64的batch同时训练,还是每张卡batch为64/4=16?
答:不管是dp还是ddp模式,batch_size都是单张卡上的batch大小,即每张卡训练的都是batch=64
我觉得挺奇怪,如果我是因为显存不足而使用多卡训练,模型中又有大量batch_norm,那么是不是这里的多卡训练就达不到我想要的效果?因为,如果对batch_norm来说,batch越大效果越好,则我希望是多张卡能够合起来组成一个大的batch,但实际上它还是几个小的batch单独计算batch_norm
当然,有需求就会有市场,batch_norm也是有跨gpu版本的,名为 SyncBatchNorm
DP vs DDP
dp和ddp的区别在于梯度计算的过程
当使用dp模式时,多张卡计算的loss结果会concatenate到第一张卡上,然后由这张卡计算整个batch的梯度,然后累加起来再求平均
当使用ddp模式时,每张卡单独计算这张卡上的mini_batch的梯度,然后再将所有的卡上的梯度求和,再除以卡的数量,这样一来就让每张卡上的梯度一样了,然后每张卡单独backward,因为每张卡的超参数都一样,且梯度一样,所以更新后的梯度也是一样的
学习率
使用多卡训练时,不需要刻意对学习率进行调整

参考
https://discuss.pytorch.org/t/comparison-data-parallel-distributed-data-parallel/93271
为什么模型训练这么吃显存?
现象
我有一个pytorch深度学习模型,模型本身不大,经过计算发现其自身只有约40 million的待学习参数量,大约仅需要150m内存就够了,但是我在一块有24g显存的显卡上训练时,很容易OOM,即使将batch size调整到刚刚能训练且不爆显存的大小,在backward阶段仍然会OOM,问题在于为什么这么小的模型却需要这么大的显存?
排查
搜索一番发现显存占用主要存在于4个方面:
-
模型参数(parameters)
-
模型参数的梯度(gradients)
-
优化器状态(optimizer states)
-
中间激活值(intermediate activations)
问题是它们会在什么时候才开始占用显存?会占用多大显存?
模型参数
模型创建时就会占用,占用大小为模型的 weights 和 bias 的总数。例如,创建下面这个线性模型:
self.fc = torch.nn.Linear(in_features=3, out_features=2)
一共需要 (3+ 1) * 2 * 4 字节的显存,其中 (3 + 1) 是3个weight和1个bias,将这个模型展开其实就是下面这个方程组:
w11 * x1 + w12 * x2 + w13 * x3 = y1
w21 * x1 + w22 * x2 + w23 * x3 = y2
这个占用大小一般都是固定的,不会在训练过程中变化
模型参数的梯度
这个会在backward调用时占用,这也是为什么训练的时候没用OOM,一backward就出错,所以设置batch size的时候应适当留一些显存用于存储梯度。
它占用的大小和模型参数相同,一个学习参数对应一个梯度嘛。占用大小也是固定不变的
优化器状态
会在 optimizer.step() 的时候占用,但是占用大小和具体优化器实现有关,例如,如果使用的是SGD,则其不会占用额外空间,但如果使用的是Adam,则会再额外占用2倍模型参数那么多空间,因为它还需要为每个参数保存两个梯度更新状态。
训练过程中占用大小固定不变。
中间激活值
这就是为什么这么小的模型需要这么大显存训练的原因,它会占所有显存的大头,但会在backward过程中(求导之后)被gc。并且其占用的显存会随着batch size的增大而增大。
pytorch中的unfold
torch.nn.functional.unfold
如果将卷积看作 滑动窗口+求和 的话,那么这个方法就是只有 滑动窗口 这一步了。
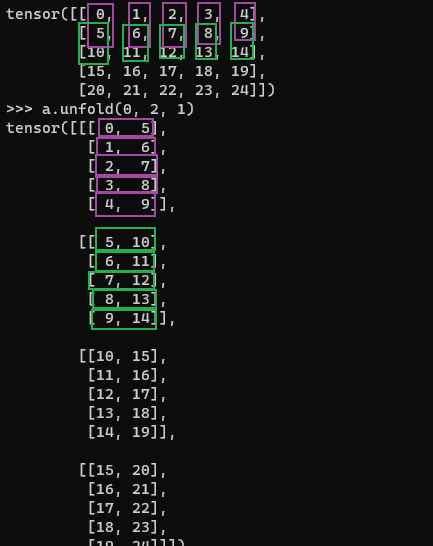
如图,a.unfold(0, 2, 1),表示在a的第0维以卷积核长度为2步长为1的方式开始取值。a的维度为(5,5),其第0维相当于行,所以图中是竖着取值的,最终得到维度为(4,5,2)的结果,因为a的0维只有5个数,而你要以步长为1两个两个地取,故只能取出4对,第二维中的5表示有5行,第三维中的2表示取出来的两个对。
假如要对二维图像进行卷积,卷积核要是二维的怎么做呢?则可以连续使用两次unfold(先对行卷,再对列卷)
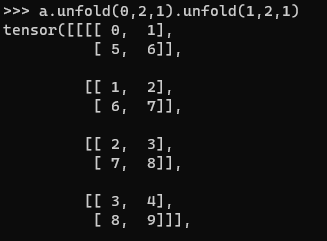
注意两次unfold所在的维度是不同的,得到的结果就是维度为(4,4,2,2)的结果。
torch.nn.Unfold
nn包中的Unfold有点不同,它可以指定一个多维的卷积核,直观感觉上,它应该是直接将特征图中的每个像素点扩展成卷积核的感受野部分,比如直接将(2,3,3)的图像升维成(2,2,2,2,2)这种(第二维为channel,使用2*2的卷积核),但实际上并不是这样。
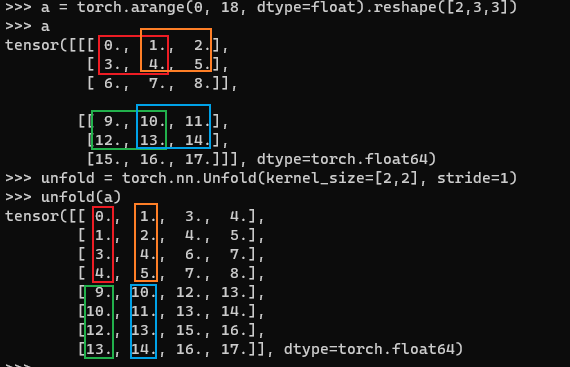
输入是(2,3,3)得到的却是一个(8,4)的矩阵。
其实这里除了滑动窗口外它还多做了两步
-
将滑动窗口得到的结果展平成1维数组
-
将多个channel得到的展平后结果进行拼接(想象n个channel上有n个窗口同时滑动,每次都将所有的滑动窗口拼接成一个长的一维数组)
所以结果维度中的8表示的是C * kernel_w * kernel_h(即文档中的 C*Π(kernel_size)),这是因为它表示的是将kernel得到的结果展平并拼接所有channel的结果,4则表示单个channel中可以卷4次。
要想得到预想的结果,可以直接再reshape成(2,2,2,2,2)就行。
另,Unfold的第二个参数 dilation 表示卷积空洞数量,想想空洞卷积是怎样的。
记一次模型训练速度优化的过程
优化之前每轮训练大概需要 3'10’’,优化之后大概只需要 35‘’
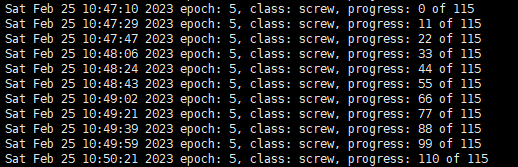
优化前
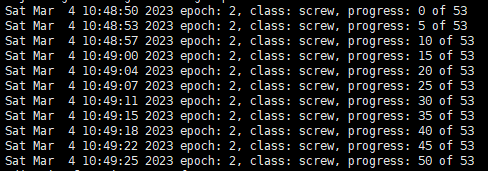
优化后
问题提出
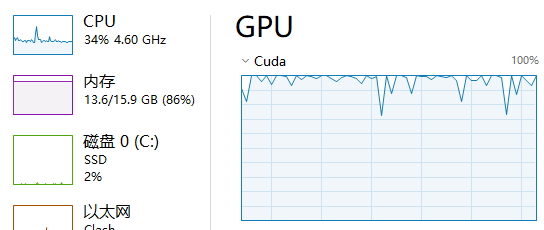
我有一个图像异常检测的模型,训练过程很慢,且在训练过程中GPU的使用率剧烈波动,一会100%一会又降到0。我使用的是GTX3090 24G显卡,在MVTec数据集上训练,该数据集有15个类别,单卡全部训练完大约需要4天。
寻找原因
python或pytorch本身提供了一些性能分析的工具,但我担心并行环境下,一些方法执行耗时并不能反应真实的代码性能,所以我采用一种较为简单粗暴的方法:控制变量法。不断注释或修改某些函数,或者在死循环中执行某些语句,查看执行的速度和GPU占用。
一旦找到出问题的语句就能对该代码进行优化,手段包括但不限于:避免对tensor元素的for循环、tensor直接创建到GPU上、修改pytorch中Dataloader的一些优化参数等
下面是一个具体的优化过程:
我发现代码在loss函数上执行的特别慢,为了验证,我在loss计算和backward这里使用了一个死循环

注意:pytorch的backward计算是基于计算图的,默认情况下,执行backward之后就会删掉计算图,如果尝试再次backward就会报错,解决办法就是如图所示,加上 retain_graph=True 参数即可保留特征图
代码执行过程中发现,GPU利用率剧烈上下波动,可以肯定loss函数是出了问题的,追踪代码进入到loss函数的实现,可以发现它是由三个loss相加得到的,故还是一个一个注释看效果,前两个loss计算时,GPU基本能处于满载,但是到第三个loss时,GPU使用率又开始上下翻动,再进去查看实现,发现代码并不多

依然是给可能出问题的语句使用死循环执行,发现第455行和457行执行得极慢,且当代码执行到这时,原本满载的GPU很快就降到0了,与此同时cpu使用率开始增大。问题一定出在这。
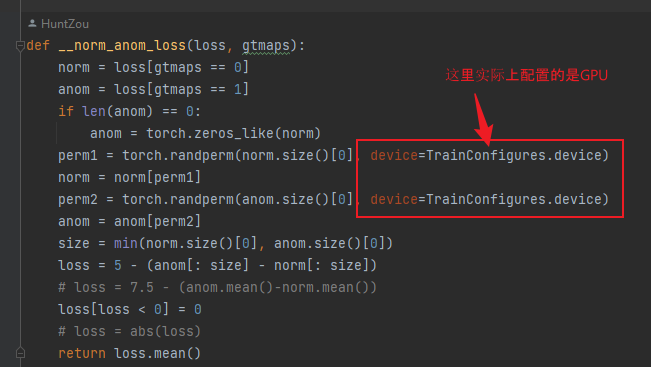
torch.randperm(num)函数的作用是随机打乱一个序列,例如这里为了增加模型的鲁棒性,会随机打乱norm和anom两个矩阵中元素的索引。通过pytorch文档查询到该函数会返回一个随机序列的tensor,问题就出在这,如果没有指定 device 参数,该tensor将在cpu上生成,由于我这里要打乱的序列长度较大(亿级别),故cpu执行时,需要1~2s,而GPU则可以瞬间完成,故指定device为目标训练设备即可(这里是GPU)
结合一些其他的代码优化,模型训练过程中可以看到GPU基本一直处于满载状态,训练速度大大提升。
优化建议
tensor直接创建到GPU
pytorch提供的很多创建tensor的方法都会有一个 device 参数用于指定tensor创建位置,可以直接指定创建到GPU。或者在cpu上创建tensor之后使用 .to(device) 函数复制到GPU上,显然直接指定device会好很多,免去了复制过程且避免使用cpu做计算,例如上面那个例子。
pytorch保存特征图
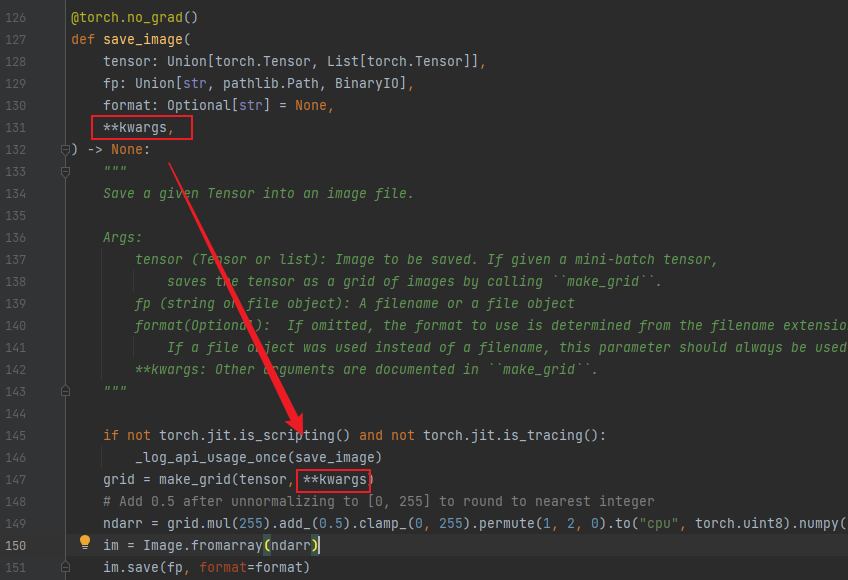
pytorch子项目torchvision提供了用于保存tensor为图片的方法 torchvision.utils.save_image
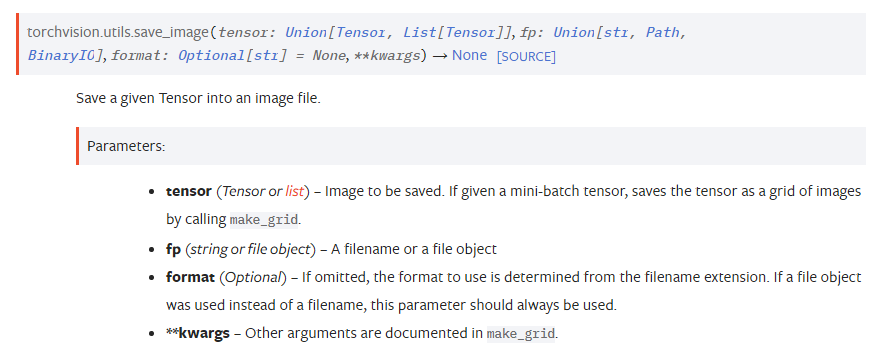
其中,参数tensor的维度为(batch_size, channel_size, H, W) 或者 (channel_size, H, W) 或者 (H, W),fp则为文件保存路径
注意:该处batch_size应该为同类图片的张数,而channel应该为单张图片的通道数(例如灰度图为1,rgb图为3),而不是你训练的batch size,也不是特征图的通道数
事实上,当输入tensor为minibatch时,其内部还会调用 torchvision.utils.make_grid 方法对所有的图片合成一张大图
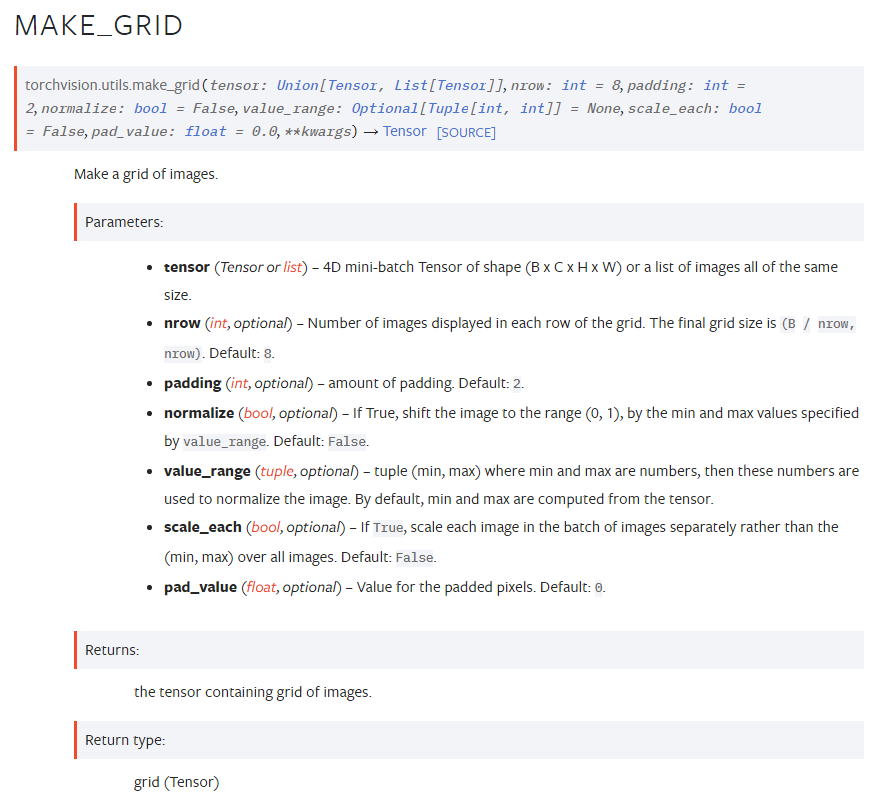
在torchvision.utils.save_image参数中,可以直接使用kv的形式传递torchvision.utils.make_grid的参数,通过save_image的源码可以看到,它是直接将后面的参数传递给了make_grid,由此你就可以在save_image方法中调整拼接图的间距(本该是make_grid的参数)
示例:
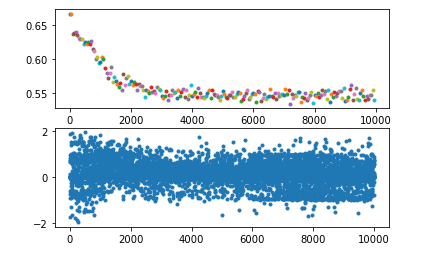
# 将上一个模型得到的特征图x保存下来
# x的第一维是train的batch size,每一个batch并不属于同一个物品,故将每个物品的特征图单独保存(单独取出每个train的batch)
# 每个物品的特征图有很多,每个特征图又是一张单独的灰度图,故将特征图的数量作为save_image的batch_size,而每张图是单通道的灰度图,故给每张图都增加一个维度用于表示其通道数为一维
# nrow 用于指定每一行并排拼接多少张图片,为了让整个大图看起来更方,这个就用特征图数量的开方
torchvision.utils.save_image(x[0].unsqueeze(1), r"D:\Tmp\feature.jpg", nrow=int(math.sqrt(x.shape[1])), padding=8)
结果就是本文最开头的那个图片
pytorch自定义激活函数
代码
自定义函数需要继承 torch.autograd.Function 类,并实现两个静态方法 forward 和 backward
import torch
# 自定义函数
class MyFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
"""
该自定义函数作用是将输入乘以2
使用以下方法将函数输入保存下来给backward中使用
ctx.save_for_backward(input)
"""
return input * 2
@staticmethod
def backward(ctx, grad_output):
"""
返回一个固定的梯度
这里结果必须乘上grad_output,下文有解释
使用以下方法获取forward过程中的输入
input, = ctx.saved_tensors
"""
return torch.tensor(3.) * grad_output
# 使用
x = torch.tensor(1., requires_grad=True)
y = MyFunc().apply(x) # 注意使用apply函数调用
y.backward()
print(f'grad: {x.grad}')
# 输出
# grad: 3.0
解释
两个函数的作用
forward 函数用于forward过程中,backward 函数用于backward过程中,两者并没有直接关系,所以上述代码其实是 \( y=w\*x \\quad where \\quad x=1, w=2\\) ,但 \(\frac {dy}{dw}=3\ )(本来应该等于2的)。这也是为什么backward中要想得到函数的输入就需要在forward中先保存
Pytorch dataloader加载数据很慢
现象
写了个模型,训练速度很慢,发现大部分时间都花在了加载数据的过程中,训练时间反而不多
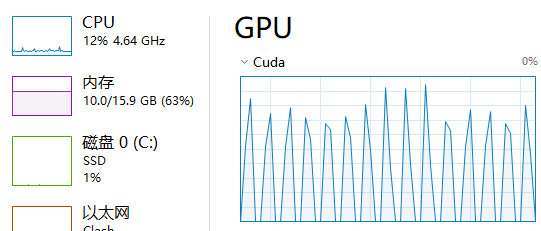
主机内存占用(已提交相当于总申请内存,其中包含交换分区的大小,其后面的数字为总可申请大小,其会根据申请情况动态扩容):

解决
num_workers
DataLoader中设置参数 num_workers=3 效果:
主机内存占用:

测试过程中貌似有一次内存申请越来越多,进而导致磁盘被占满(交换分区)
该参数默认情况下为0
该参数用于指定加载数据使用的线程数
当其为0时,其顺序执行以下步骤:
-
dataloader获取本轮训练需要的数据索引
-
主线程拿到索引后再调用 torch.utils.data.Dataset 的 getitem 方法逐个获取数据
-
获取完数据后,开始执行模型训练
-
一轮训练结束之后,再次返回到步骤1获取数据,如此往复,完成训练
当其>0时,真实的过程我还是不清楚,以下是我做的一个测试结果:
dataloader会在初次迭代时根据 batch_sampler 获取多个batch的索引(具体为 prefetch_factor*num_workers 个),并将他们传给workers。每个worker都将单独加载一个batch(例如batch size为16,则每个worker会加载16条数据)到主机内存。
真正训练时,会去主机内存中找到所需的batch(如果用到GPU,则会再次从主机内存复制到显存)。与此同时,也会再次调用workers去加载一批新的数据
若没找到,则会再次调用workers去加载(这一句来源于网络)
实测结果显示,貌似只有在首次迭代dataloader时会一次加载多批数据,后续每次都是只用一个worker加载一批数据。我想这样应该也是合理的,如果每次都加载多批数据,消耗速度小于加载速度,最终内存会爆掉
经测试:
在我的某个模型中,每增加一个worker(默认prefetch_factor=2)内存消耗增加5.8G(绝大部分为交换分区,所以一旦worker多了之后就会大量占用磁盘空间,得注意)
可能是因为数据集较小(765M的纯文本数据),修改batchsize并不增加内存消耗,修改prefetch_factor对内存影响貌似也不是很大
以下为我某次测试数据(仅供参考,实际得依照具体模型和数据规模来看)
4worker 20次训练耗时16s 平均耗时0.8s
3…………………………………18s………………0.9s
2…………………………………28s………………1.4s
1…………………………………50s………………2.5s
0…………………………………50s………………2.5s
参考:
https://pytorch.org/docs/master/data.html
看到一个简洁明了的:https://www.cnblogs.com/h694879357/p/16055835.html
加了该参数程序就不动了?
我在windows10下使用jupyter,加入该参数后程序就卡在那了。
解决方法,导出为python文件,并且:1. 将方法体放到 main 方法中, 2. 使用命令行或其他ide执行
原因是设置 num_workers>0 需要多线程支持,jupyter notebook在这方面有很大的问题,并且还需要在 if __name__ == '__main__' 代码块中运行
参考:https://github.com/pytorch/pytorch/issues/51344
pin_memory
dataloader参数,默认为false,该值设置为true的结果(貌似影响没那么大)
记录pytorch遇到的一些问题
Embedding层的num_embeddings设置过小
遇到了两个报错都是这个原因导致的:
报错一:
RuntimeError: CUDA error: device-side assert triggered
报错二:
RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERROR
nn.Embedding层的 num_embeddings 参数用于指定需要被embed字典的最大容量(被embed那个数能取得的做大值,和具体能取哪些值无关),若传入的某个字典索引大于该容量,则会出现越界错误。
例如我输入的vocab字典真实最大长度为3000,而Embedding层的 num_embeddings 仅设置为2000,则可能报错
PS:后边训练另一个Seq2Seq模型,也是随机报这两个错误,测试发现也是同样的问题引起的。
记一次模型训练时显存溢出的问题
出现的问题
写了一个Seq2Seq的中英翻译模型,使用Encoder-Decoder模式。训练时发现总是训练一段时间后就会报显存溢出的错误,训练终止。
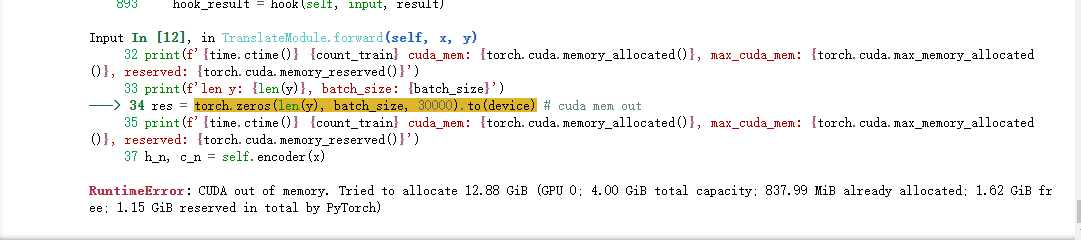
根据报错信息可知,pytorch欲分配12.88G的显存,但我的显存只有4G,显然是不够的
寻找原因
从异常栈来看,报错问题出在我创建一个大小为 len(y) * batch_size * 30000 的tensor上
将 len(y) 和 batch_size 打印出来,发现异常处 len(y)=1579 ,正常情况下应该为35左右

pytorch为每个float类型数据分配4字节内存,故上述tensor共需 1579 * 73 * 30000 *4 / (1024^3) = 12.88 G 的内存,这与错误信息相符。
len(y) 表示的是英语句子的分词长度(即把一个句子拆分成单词数组的长度),故去语料数据集中找到该条数据
找到出问题的语料(一个句子)发现是双引号导致的问题,句子中包含一个双引号,处理是误认为是字符串开始的标识符。关于这一点参见
https://blog.woyou.cool/post/2826
问题解决
通过代码追踪发现,这个tsv文件是我自己生成的,生成过程中忽略了引号的转义,故重新生成并加上转义即可(删掉 quoting=csv.QUOTE_NONE 即可)

其他
如果是训练一段实际后才出现溢出问题,很有可能是代码或数据问题
如果是一开始就有问题,则可能是由于batch size过大导致
pytorch显存使用
- pytorch会根据代码需要向GPU申请显存空间
- 使用完该空间后pytorch并不会立即将其返还给GPU,而是继续保留
- 当代码继续向pytorch申请空间时,pytorch会先分配预留的空间,不够的话再向GPU申请
_故GPU显示的显存占用 = 代码的真实占用( torch.cuda.memory_allocated() ) + pytorch的预留空间( torch.cuda.memory_reserved() )_
这也是为什么训练过程已经结束,但代码并未退出时,查看显存占用依然很大的原因(用jupyter时很明显,不手动重启或终止内核它就会一直占用着)
loss总是收敛到0.69左右
这种情况一般是在使用了交叉熵的二分类问题上容易出现,同样的,也可能出现loss收敛到1.0986、1.386等等,其实他们就是log(1/2)、log(1/3)、log(1/4)。。。
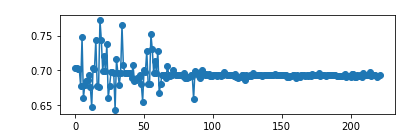
问题概述
根本原因:交叉熵
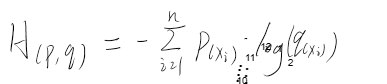
若q=0.5则对于01分布来说,H=log(0.5)=0.69,同理对于n分类问题来说,loss可能会收敛到log(1/n),这都是因为各个类别拟合概率相近导致的,再看看为什么会导致各类别拟合概率相似
常见原因之一:Sigmoid
使用交叉熵之前通常会使用sigmoid作为激活函数,sigmoid公式及图像为:
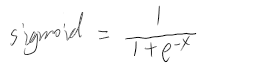
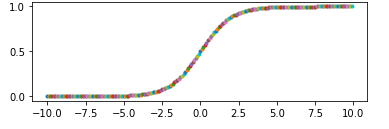
由此可知,有两种情况会使得sigmoid的输出都是相近的
1. 自变量x都是相近的,导致函数值也相近
2. 当自变量x大于或小于某个数之后(例如5和-5),其值基本就等于1或-1。那么如果上层神经元的输出都是一个较大或较小的数,则经过sigmoid之后得到数组元素就都是1或-1,则针对每个分类的概率就是相同的,这样的数据得到的交叉熵就是log(0.5)或者log(1/3)或者log(1/4)…
对于第一种情况,我们看看为什么自变量x会都相近。一般来说,线性函数的结果输入到sigmoid中,其公式为:wX=Y
由此可知,若要使得y中的元素相同,又有两种方式:
1. w中每一行都相同或相近
2. X趋近于0,则此时Y也会都趋近于0
再分析逐个分析
出现第一种情况一般来说可能是权重的初始值设置不合理,例如使用pytorch中的fill_函数使得所有的权重都相同,且后续训练也没有有效地更新权重导致的(为什么没更新权重后面会说),则可以选择一些更随机的初始化方法。
为什么权重没有更新:可能是学习率设置的过小或初始权重过大或情况二,一般来说,如果是学习率设置过小或初始权重过大,则在足够多的迭代次数之后,loss就会恢复正常
出现第二种情况则是数据源的问题(若全连接前还有其他层,则其他层的输出就已经很小了),此时可以通过normalize的方法对batch的数据进行处理或放大之后再输送到全连接层
对于第二种情况,较好的做法是在将数据送到sigmoid之前先进行normalize
以上只是两种特殊情况,下面将列举我目前能想到的五种情况
出现问题原因及解决方法
当输入与输出确实不相关时
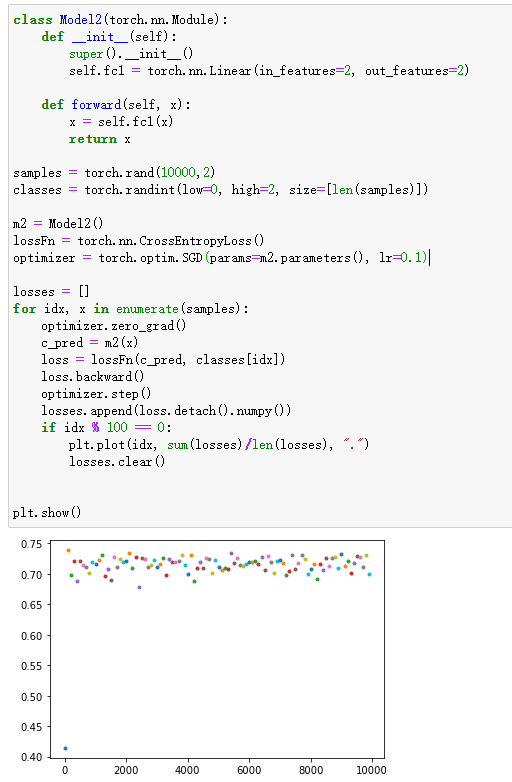
解释:这个很好理解,因为你的数据本身就不能拟合,所以不管是让人做分类还是让机器做分类都只能得到50%的正确率
解决办法:数据源上找原因
当模型初始权重相同且较大,且学习率较小时
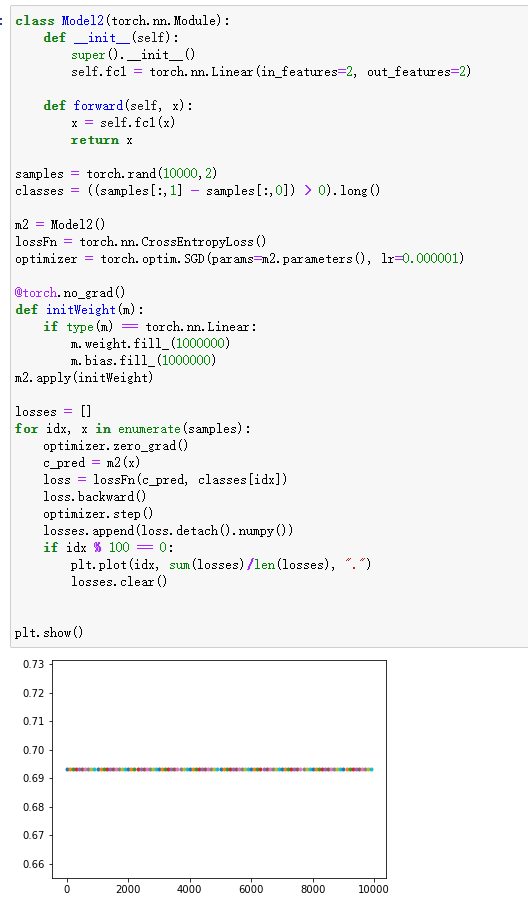
解释:权重相同则意味着模型预测每个分类的概率输出是一样的,学习率较小意味着权重更新幅度太小,导致即使经过了长时间的训练权重依然几乎相同——同初始值一样。
解决办法:理论上,出现这种情况,只要迭代的次数足够多,模型还是可以收敛的。也可以使用pytorch的norm_方法初始化权重,并增大学习率
当模型的输入本身就很小,或者模型初始化权重很小时
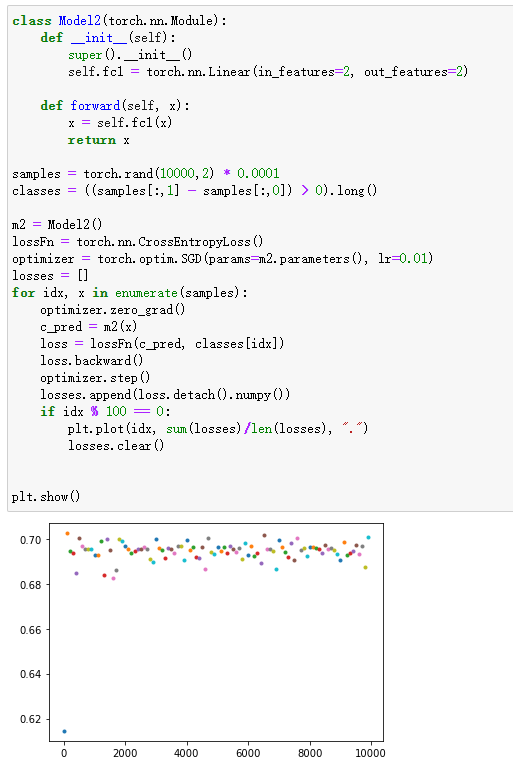
解释:两个原因,1. 由于预测输入是通过线性函数 w*x + b=y 得出的,如果此时x或w趋近于0,则得出的y也都是趋近于0或偏置b的,最终导致模型对各个类的概率相同。2. 同下方的将输入整体放大的情况
解决办法:对输入做normalization处理,合理初始化权重,比如使用N(0,0.001)分布初始化权重
特征不明显,导致长时间训练不拟合

解释:emmmm
解决办法:做一些特征工程,多迭代迭代应该也能跑出来,增加模型复杂度或许也有用
使用sigmoid或tanh这类函数时,将输入特征整体放大后使得收敛更困难

解释:从pytorch文档中可以看出,lstm使用了很多sigmoid和tanh激活函数
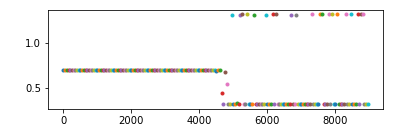
这两个函数都有一个特征,就是他们的导数在大于或小于某个范围时几乎等于0,这就导致backward时梯度越来越小,进而导致权重无法更新或极慢,如下图
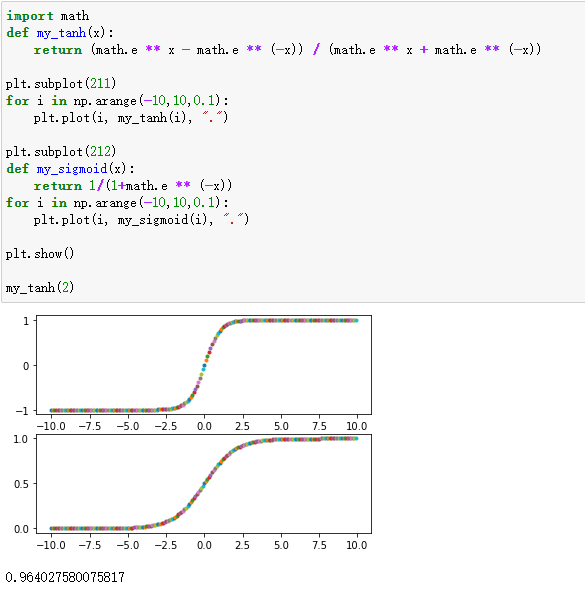
所以如果输入lstm的值都比较大或比较小,从官网给出的公式不难看出,其输出就容易只在0、1、-1三个数附近徘徊(如下图中的第二个图)
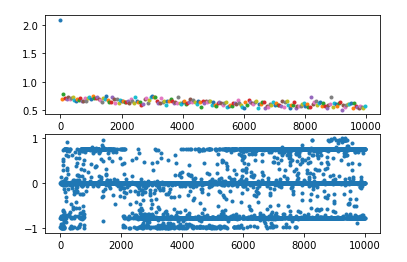
解决办法:解决办法很多,这里写三种
想要解决这个问题就得在lstm的输入端做一些处理,比如,我这里使用sin函数将值域固定在某个范围内,起到了一定的效果

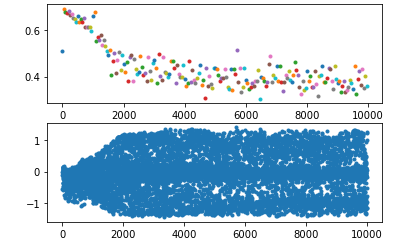
或者,直接使用pytorch提供的layerNorm
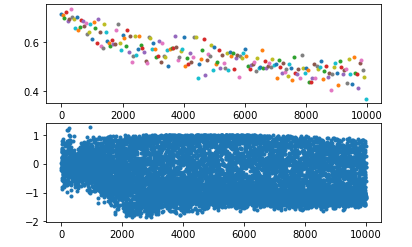
或者,当我不进行norm只使用batch输入的时候,批量化处理会排除个别元素干扰,对整个batch求均值能提高收敛速度减小训练时间