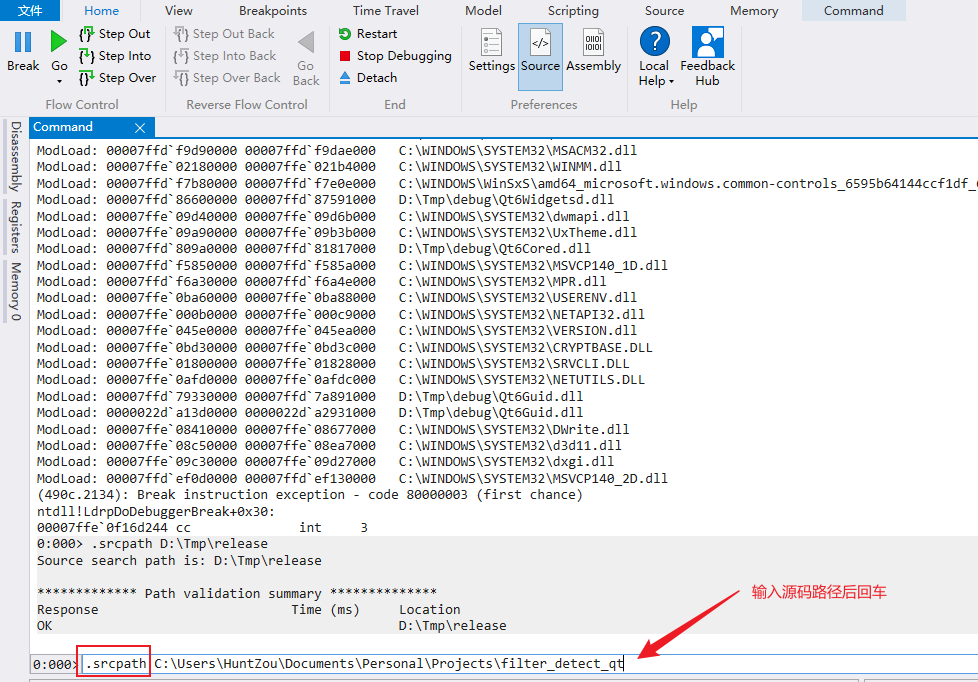
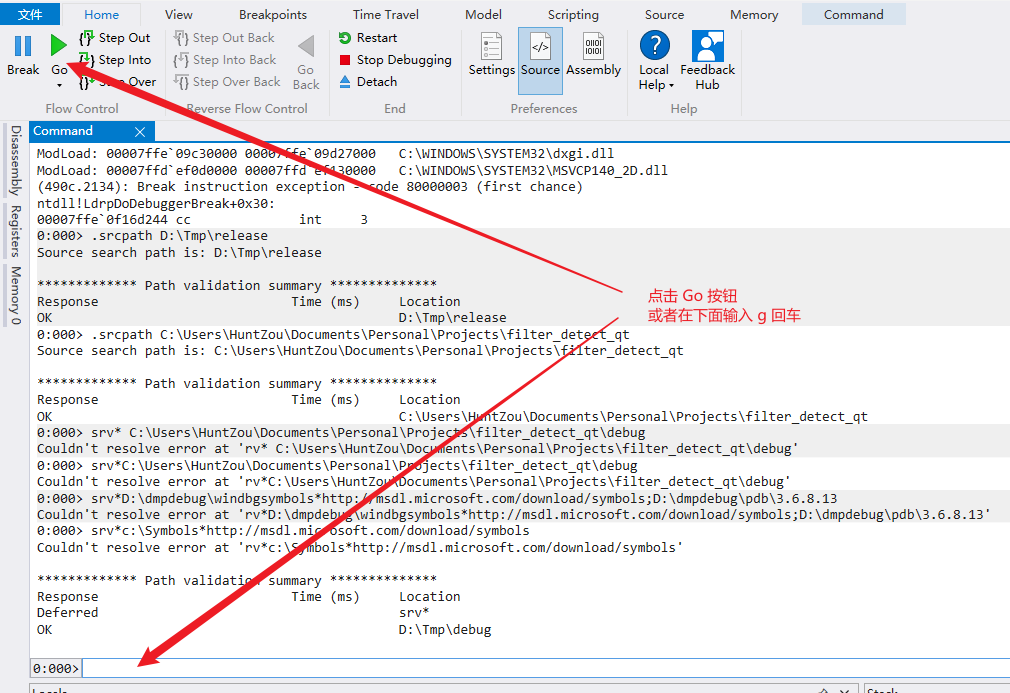
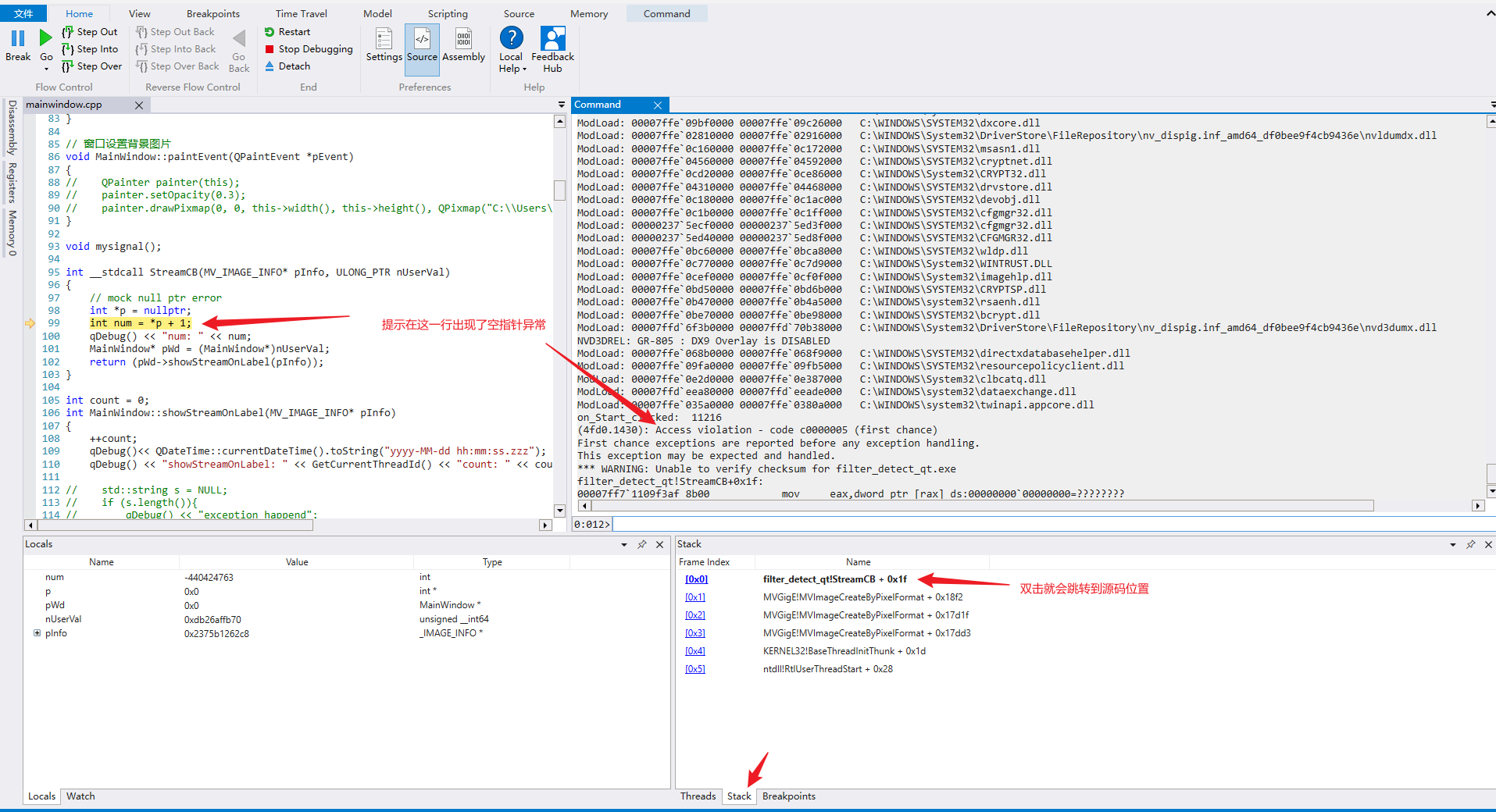
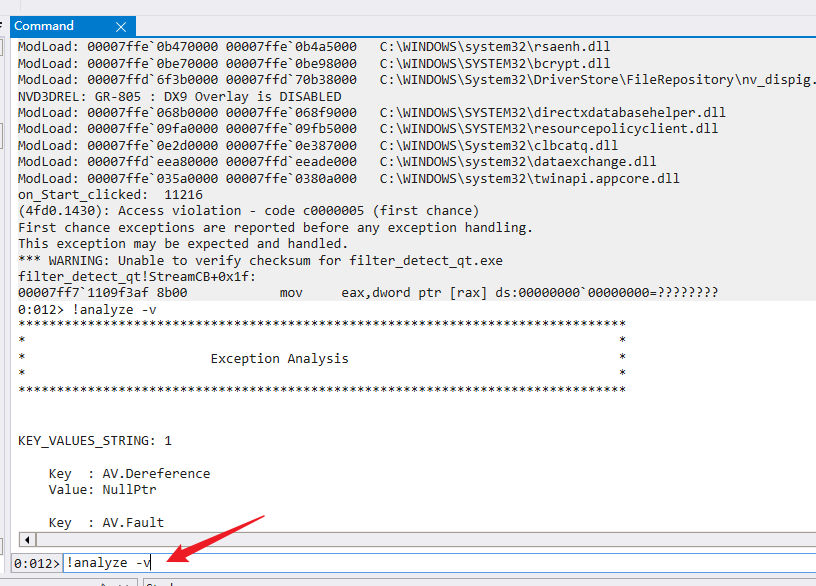
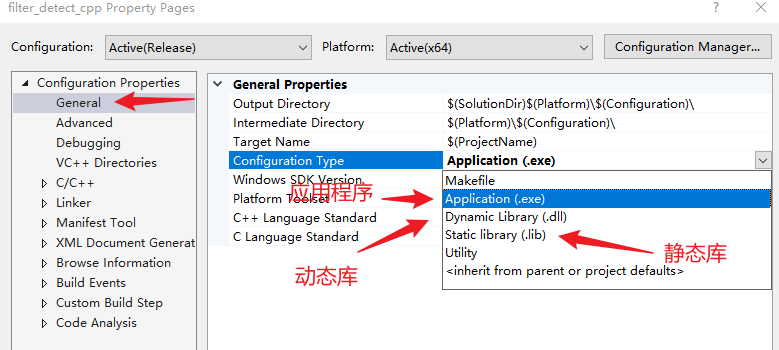
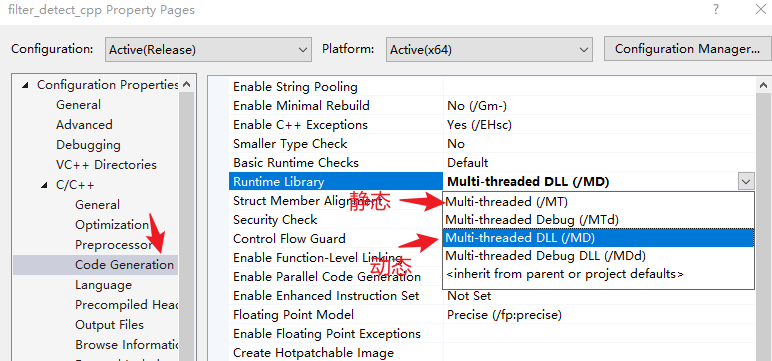
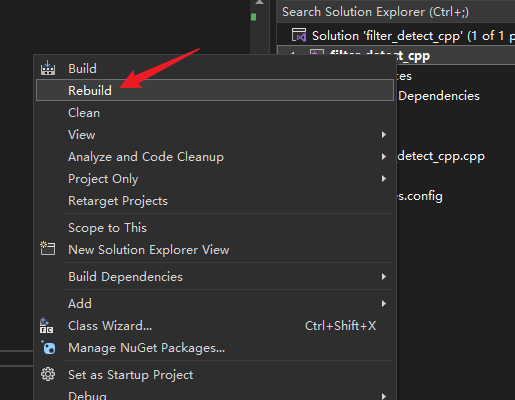
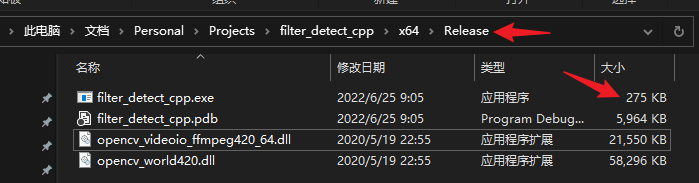
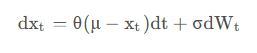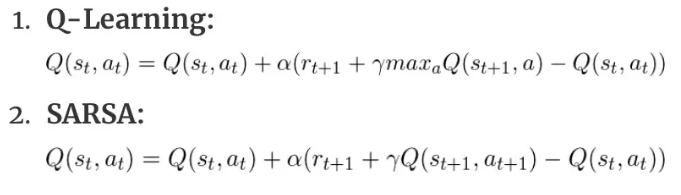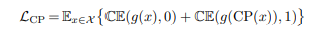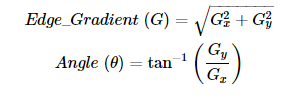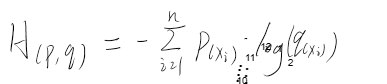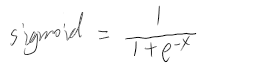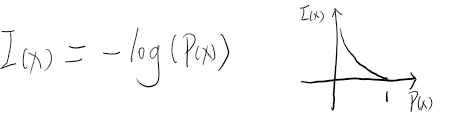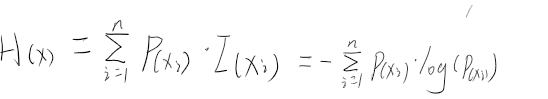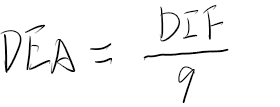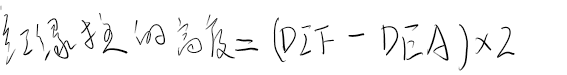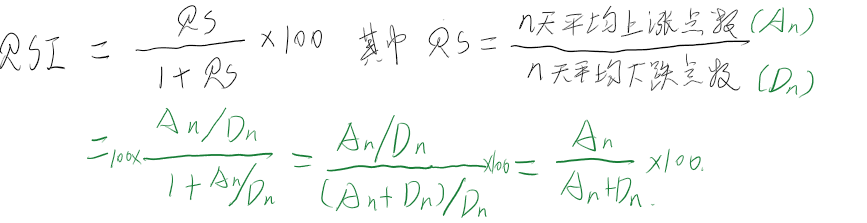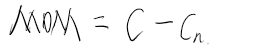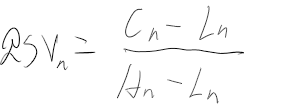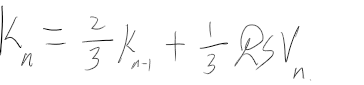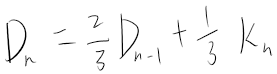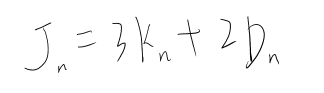Posts
Tempor est exercitation ad qui pariatur quis adipisicing aliquip nisi ea consequat ipsum occaecat. Nostrud consequat ullamco laboris fugiat esse esse adipisicing velit laborum ipsum incididunt ut enim. Dolor pariatur nulla quis fugiat dolore excepteur. Aliquip ad quis aliqua enim do consequat.
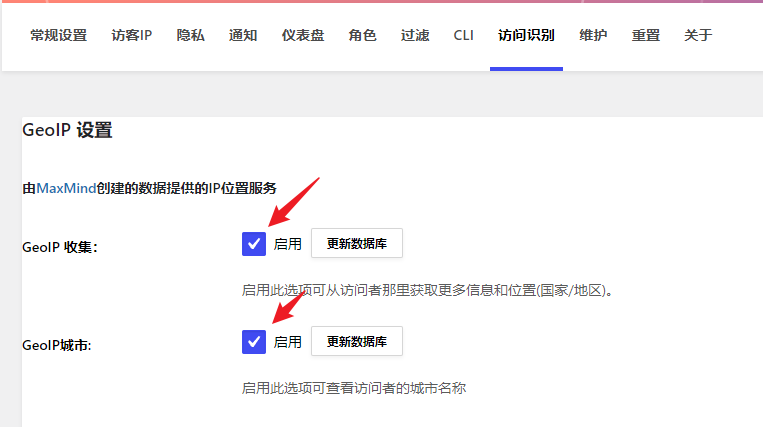
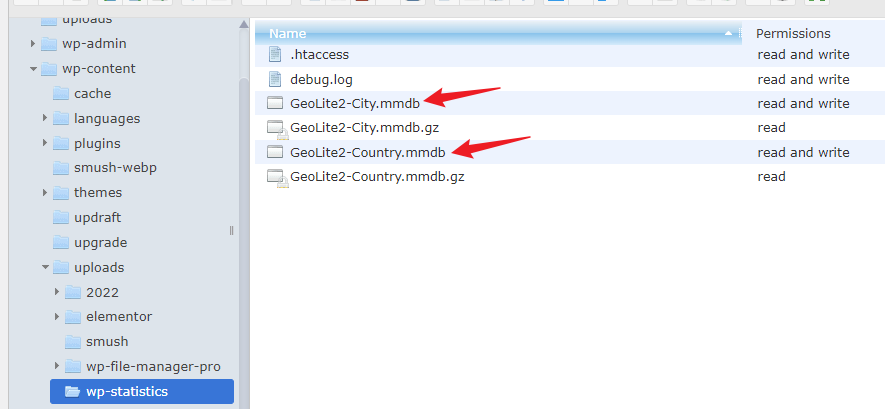
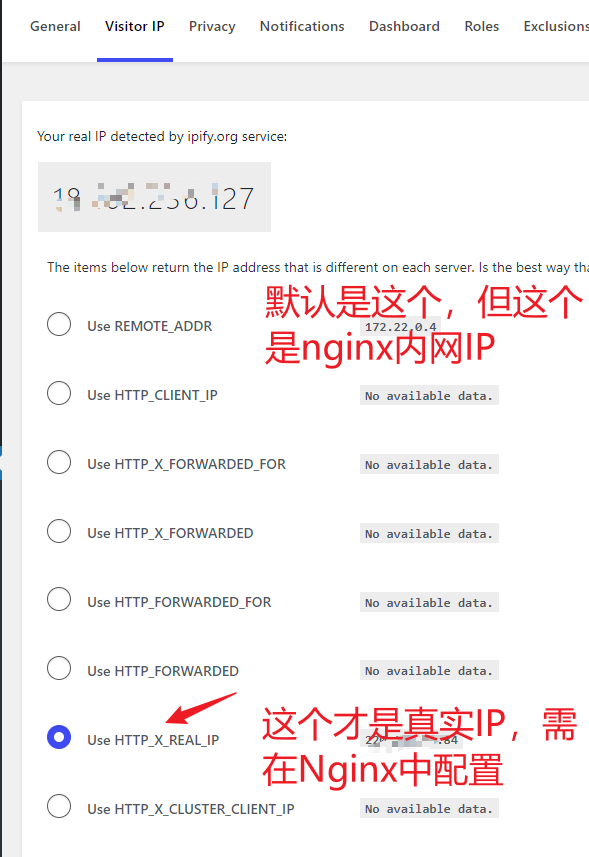
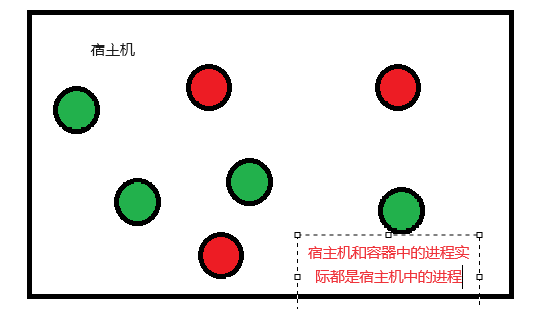
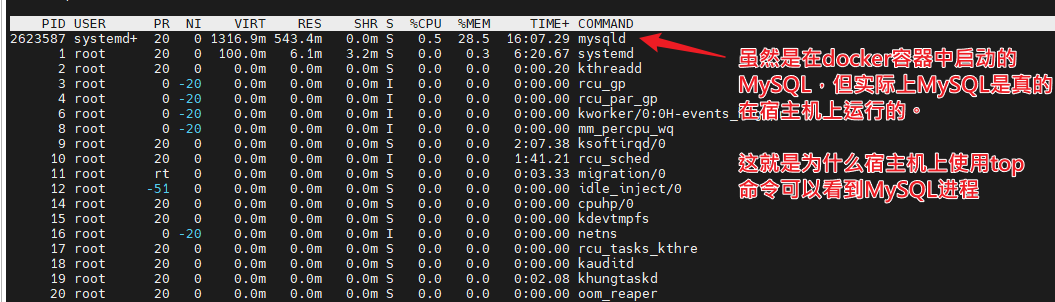
喜欢周末上班的感觉
相比weekday工作,我觉得weekend一个人来公司加班更舒服。
平时太多人找我了,想做个东西,时不时就会有人有事找,你不得不停下手上的工作去做其他事,周末工作就舒服多了,不用担心有人找,你就安安心心做自己的事就行,公司也太多其他人,也不吵,非常安静,非常舒服。
唯一不舒服的可能是义务加班,没加班费,但也还好,反正也没其他事,反正心也乱

今天上午改了一些代码,就想着要不出去转转,梁子湖不远不近,就去那吧,看了下三四十公里,骑小摩托大概五十分钟能到,反正心乱,去转转。
过去骑一路挺舒服,路平又宽,还没多少车,一路听着音乐很快就到了。
梁子湖比我想象的好看,也比我想的更开放,周边很多露营骑车钓鱼的,人多但干净,尤其是湖面水天相接让我很是震撼。绕着转了两圈,还专门修的环胡路,意犹未尽

我还说在地图上看梁子湖那么大,结果回来看了下手机记录,发现我就在它的一个稍小的子湖边上溜达了一下,甚至没有完整绕小湖转一圈,甚至离小湖转一圈还差的远,不过也骑了90公里
下次可以开着地图再绕,看能绕多久
还得学
AI 目前并不会减少你掌握新技能所需要付出的努力,只会让你产生不必学习就已经学会的错觉。
一切都还早
一切都还早,一切皆有可能,30了
乌合之众
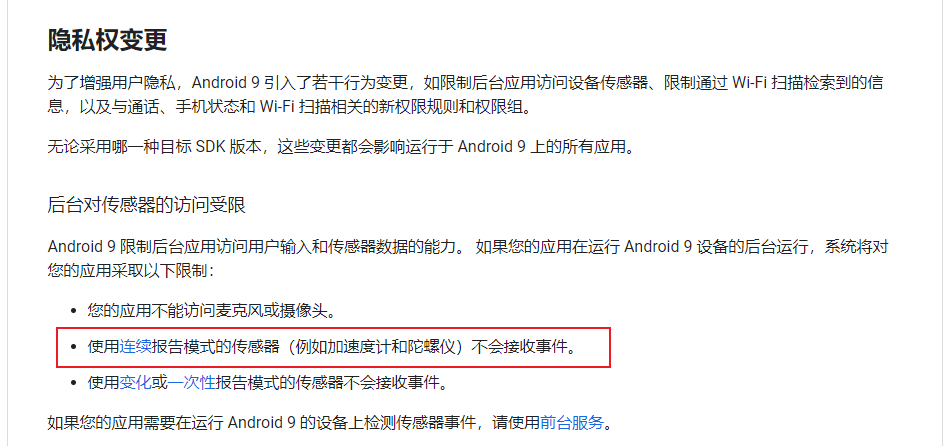
我担心,以后在重要的媒体中,实质性内容将逐渐衰落,30秒的片段会流行,节目只具有最低的共识,充斥着对伪科学和迷信的盲目介绍,尤其还有一种对无知的庆祝。
– 卡尔·萨根,美国著名科普作家,这段话写于1994年
哀其不幸怒其不争
每天不知道自己在做什么,脑子一堆想做的事,就是不去做。我的脑子里充满了悔恨、遗憾、焦虑、害怕,我以为上班了会好点,还是那么煎熬,我想让时间能快点,但是又怕时间过得太快。
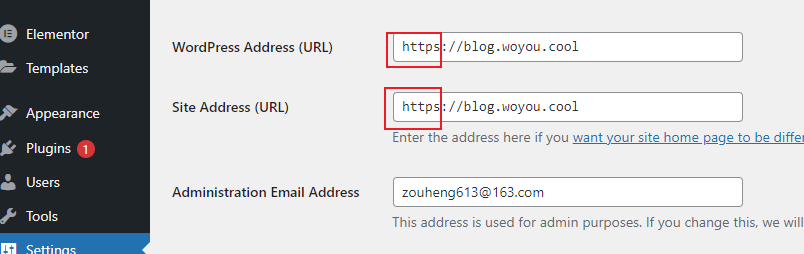
从worldpress迁移到hugo
blog平台从worldpress迁移到hugo了

仓鼠死了
去年五一买的仓鼠老公公昨晚回去发现死了,很愧疚,很内疚,可能是被我饿死的,也可能是又饿又冷死的,总之是我的问题。
年后好像就给了一勺粮,之前没收拾房间,想着这周收拾房间的时候给它打理打理,没想到就差这两天。我记得前天它还跑得欢,怪我,不应该那么随意。
买这个仓鼠的时候还有个老婆婆,不过第二天就死了,当时没喂养的设备,以为是渴死的,现在想想,应该不至于。
之前放房间味道太大,放到阳台了,阳台并不很开放,不过毕竟是寒冬腊月。
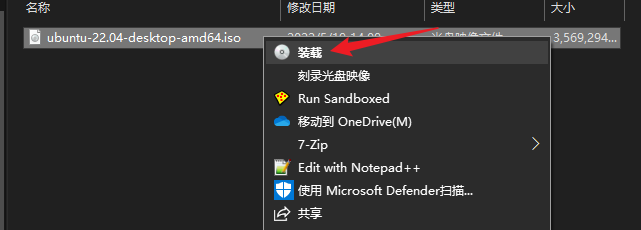
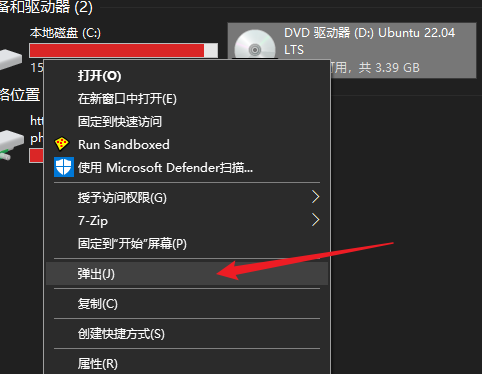
小米笔记本安装飞牛nas系统fnos
最近打算买个nas,先体验一下,正巧最近fnos到处推广,试一下
我先是在虚拟机上安装后试了下,觉得挺顺手的,功能也不复杂,也许是因为我没用过nas
小米笔记本安装过程也简单,我的笔记本是小米air13.3的那个。
准备一个U盘、fnos系统iso镜像,使用balenaEtcher或refus制作U盘启动盘,插入电脑
!!!同时将手机使用数据线连接上笔记本,并且打开手机的usb共享网络功能,因为fnos安装时使用不了该笔记本的无线网卡!!!
电脑启动时不停按f12,进入启动选项,选择U盘启动方式
然后按照fnos的指引安装即可。这里如果没有使用手机的usb共享网络,在选择网卡列表时就会为空。
安装完成后拔掉U盘,电脑重启,注意此时也要保持手机的usb共享网络开启状态,重启时可能会断,还得打开
直到系统启动,看到终端显示了访问的http地址,然后在手机上打开该地址,创建一个账户
账户创建完成后就可以断开手机的usb共享网络了
然后在终端登录刚才创建的账户,接着执行以下命令:
# 切换为 root 用户
sudo -i
# 查看wifi列表
nmcli device wifi list
# 连接某个wifi
nmcli device wifi connect "Wi-Fi名称" password "密码"
此时就可以用连接同一路由器的电脑的浏览器访问fnos的ip了。
但此时还有个问题就是当笔记本屏幕合上时,fnos就休眠无法访问了。解决方法是:
fnos终端登录你的用户,然后输入命令 sudo vim /etc/systemd/logind.conf,找到有一行为 HandleLidSwitch=suspend,将它的值修改为 ignore ,重启系统即可。
VMware启动虚拟机报错
症状
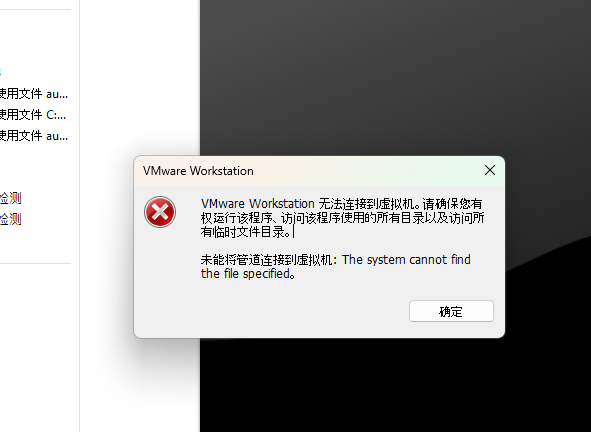
创建完虚拟机后,启动虚拟机报错:
VMware Workstation 无法连接到虚拟机。请确保您有权运行该程序、访问该程序使用的所有目录以及访问所有临时文件目录。
未能将管道连接到虚拟机: The system cannot find the file specified。
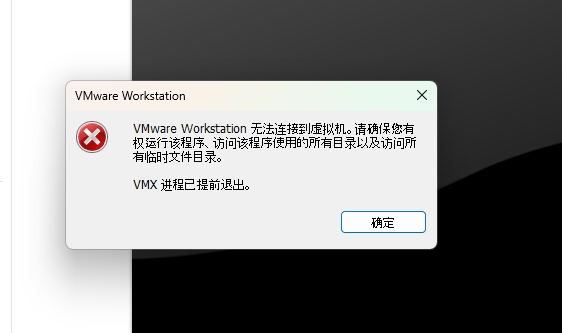
如果以管理员启动VMware,启动虚拟机会报错:The Code execution cannot proceed because ResampleDmo.DLL was not found.

点击 OK 后继续弹出错误:VMware Workstation 无法连接到虚拟机。
治标
根据提示,说缺少 ResampleDmo.DLL 动态库文件,所以去下载该文件:
进入网址:https://www.dll-files.com
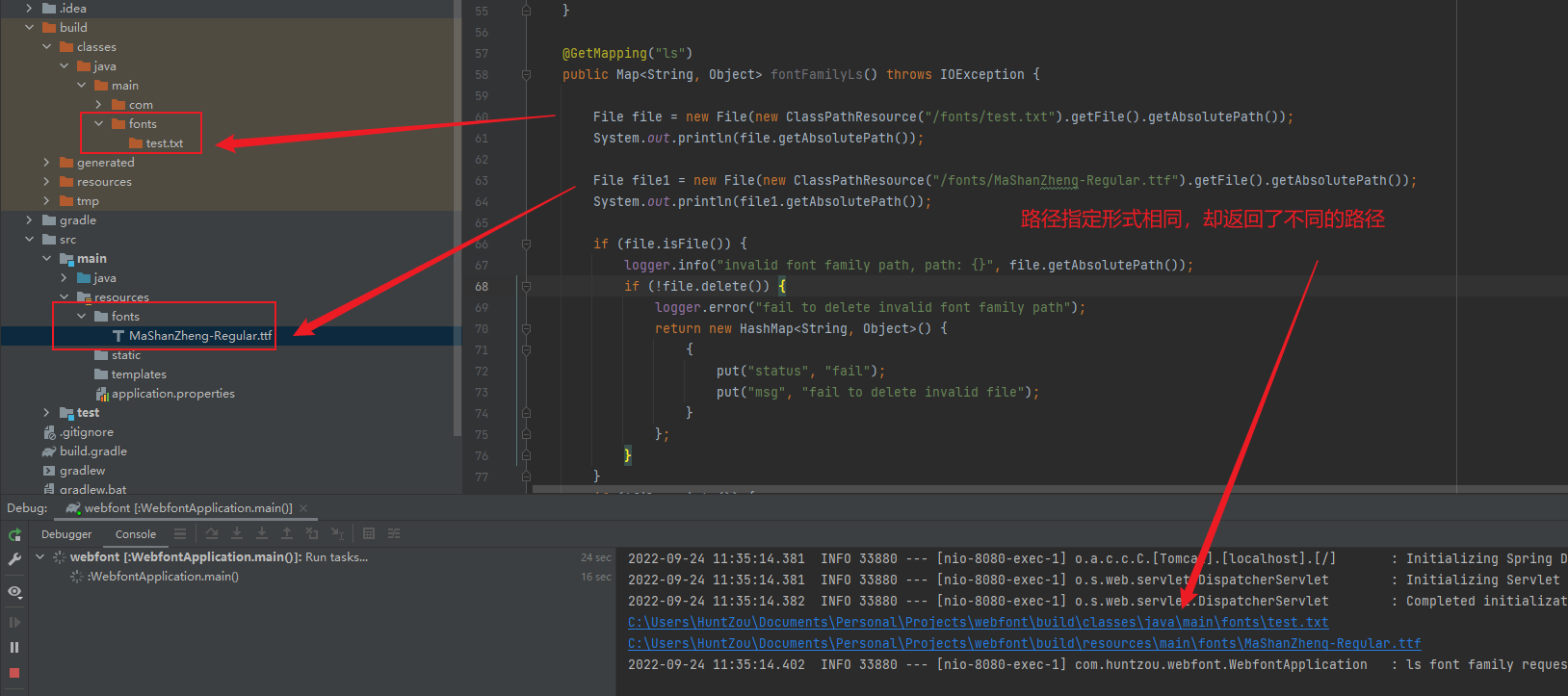
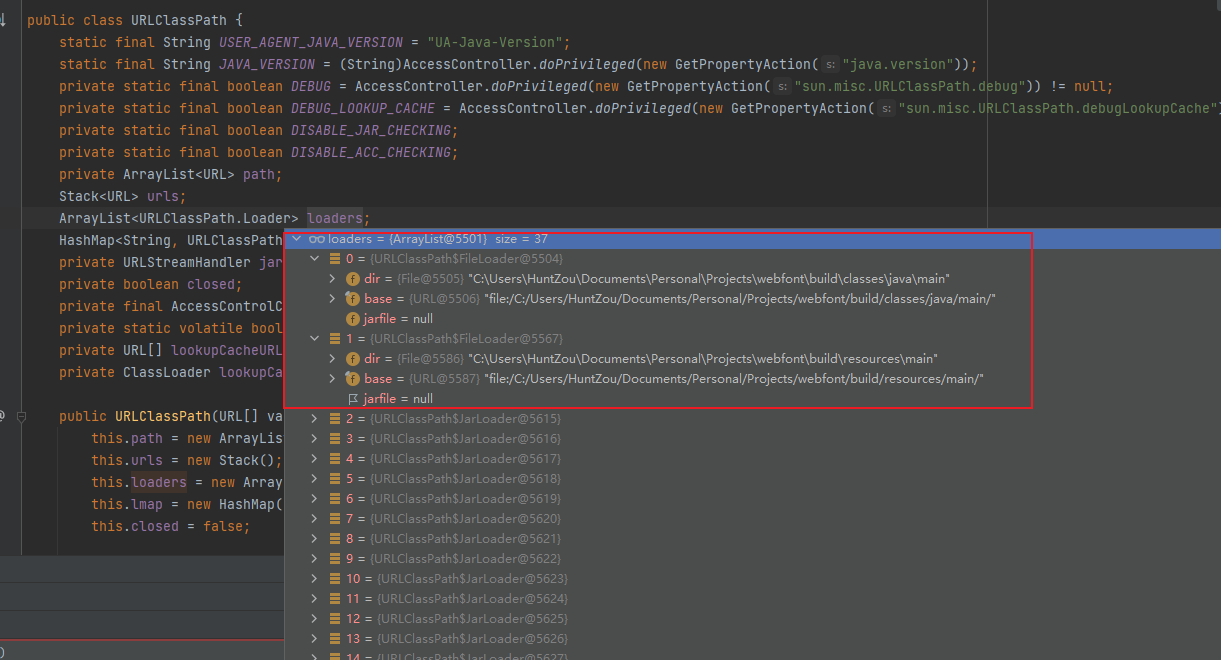
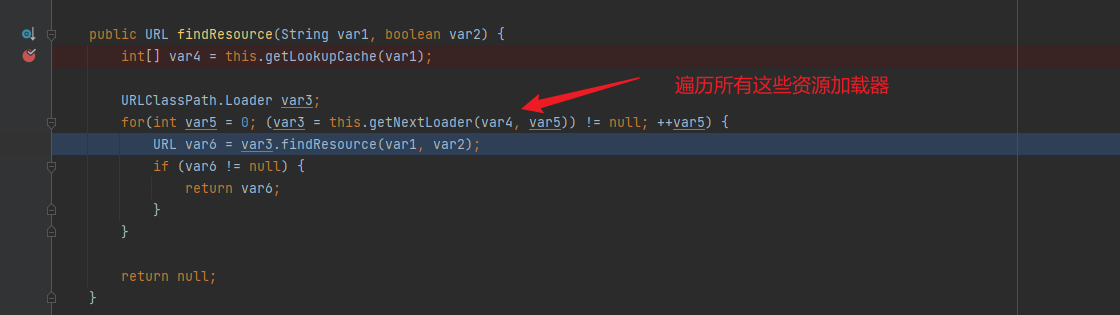
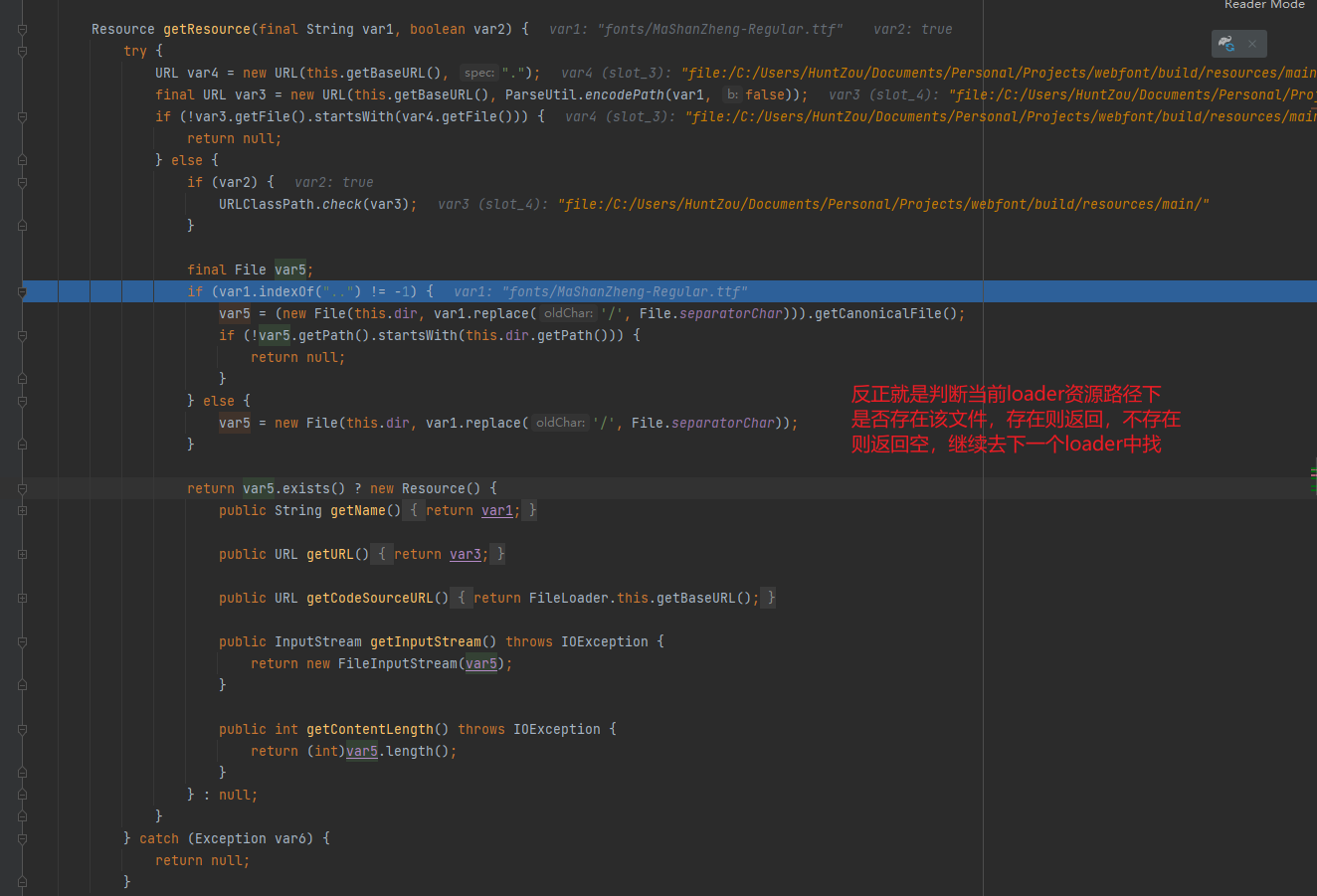
搜索 ResampleDmo
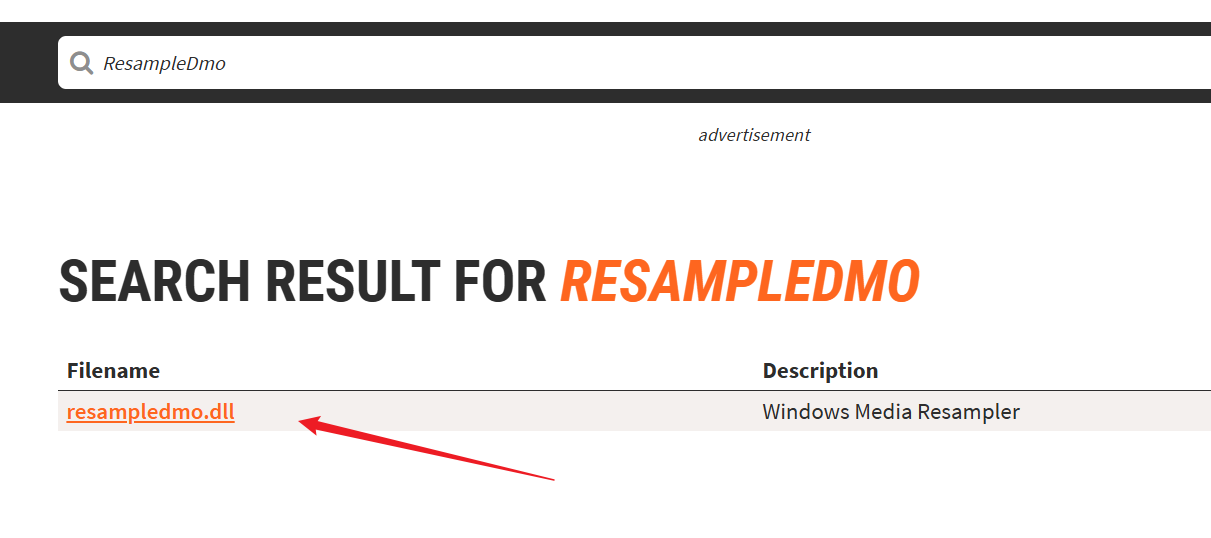
找到符合系统条件的包,点击下载
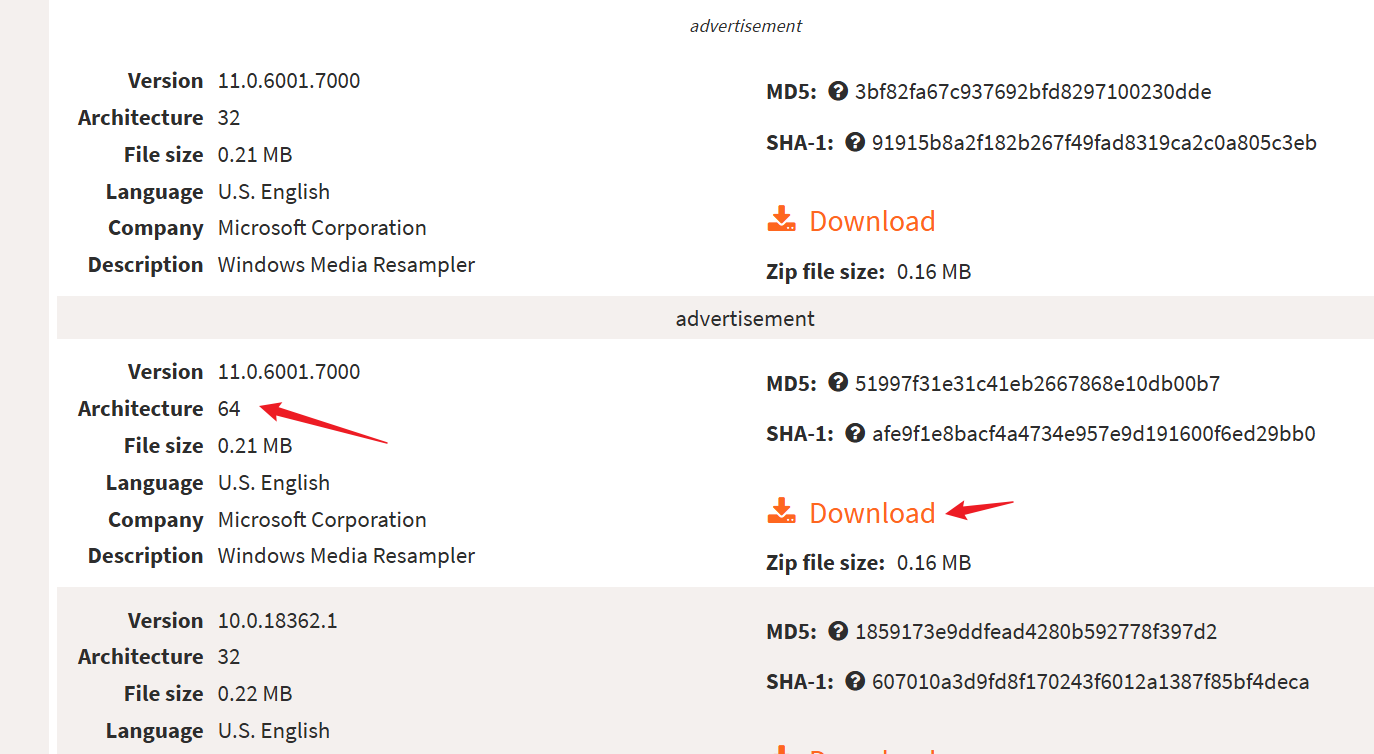
下载后解压,将得到的dll文件放到 C:\Windows\System32 目录下:
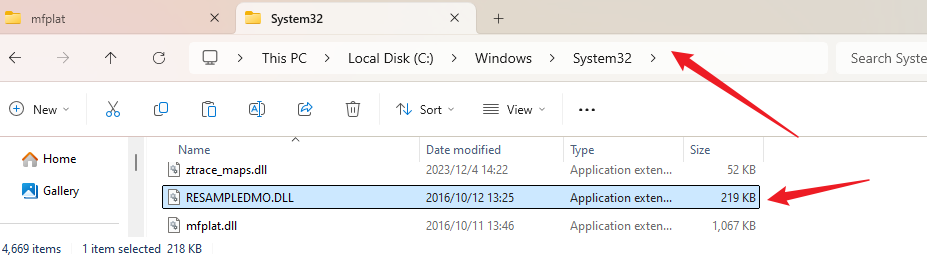
然后再次尝试启动VMware即可。我这里仍然是报错的,然后使用管理员方式启动后报缺少 mfplat.dll 文件,按照同样的方法下载安装后虚拟机就能正常启动了。
治本
我安装的是 Windows 11 Pro N,这个N是一个特殊的版本,它比正常的版本会少一些东西,其中就包含 Media Feature Pack 这个软件包,上面说的那两个dll就属于这个软件包的。
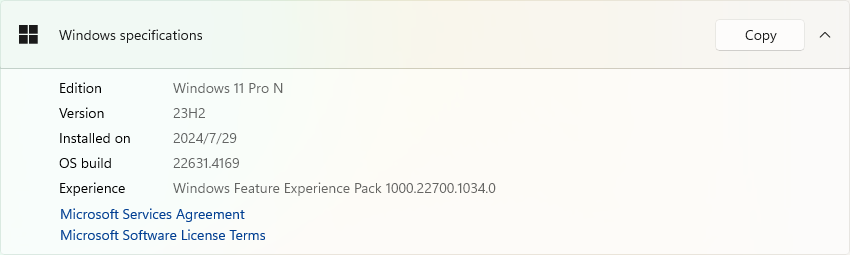
所以,另一种更优雅的解决方法是安装 Media Feature Pack
点击 setting -> System -> Optional features
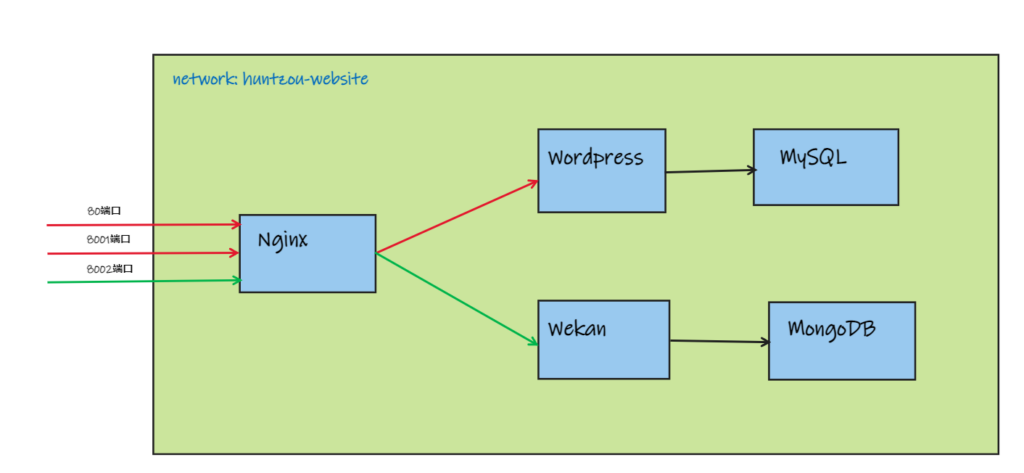
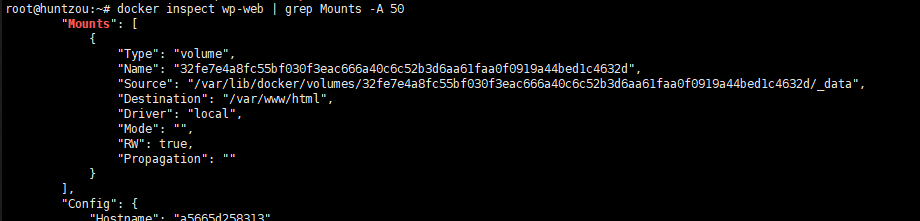
docker环境下wordpress迁移并更换域名
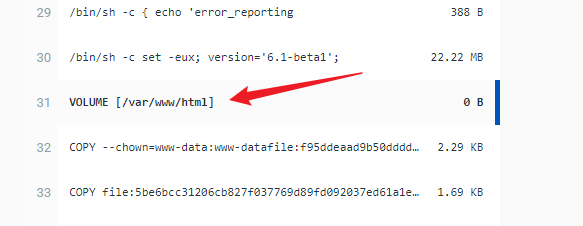
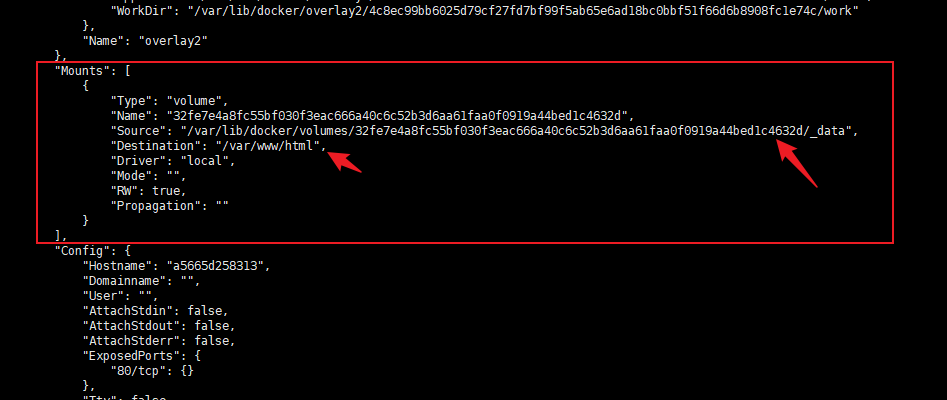
先执行docker inspect xxx找到 Mount 部分,将挂载的 /var/www/html 目录打包(或者直接使用docker cp命令将该目录复制出来再打包也一样)
mysql容器也是一样,将 /var/lib/mysql 目录进行打包
打包后的两个文件复制到新的机器上解压,分别重命名为 html 和 mysql(命名随便)
使用 docker run ... -v xxx:xxx -u "1000:1000" xxx 或者docker-compose的方式启动wordpress和mysql,docker-compose.yml如下:
version: '3.1'
services:
wordpress:
image: wordpress
container_name: wordpress-web
restart: unless-stopped
user: "1000:1000"
networks:
- huntzou_website
environment:
WORDPRESS_DB_HOST: wordpress-db
WORDPRESS_DB_USER: xxx
WORDPRESS_DB_PASSWORD: xxx
WORDPRESS_DB_NAME: wp_db
WORDPRESS_TABLE_PREFIX: wp
volumes:
- /home/hunt/Documents/docker_properties/wordpress/html:/var/www/html
- /etc/localtime:/etc/localtime
mysql:
image: mysql
container_name: wordpress-db
user: "1000:1000"
restart: unless-stopped
networks:
- huntzou_website
#command: --default-authentication-plugin=mysql_native_password
environment:
MYSQL_DATABASE: wp_db
MYSQL_ROOT_PASSWORD: zh613
volumes:
- /home/hunt/Documents/docker_properties/wordpress/mysql:/var/lib/mysql
- /etc/localtime:/etc/localtime
networks:
huntzou_website:
external: true
其中-v的挂载目录就是打包的那个目录,挂载点和原主机挂载点相同。
阿里云api实现ipv6的ddns
创建python的虚拟环境
# 创建一个虚拟环境python3 -m venv ipv6_py_env# 激活虚拟环境source ipv6_py_env/bin/activate
获取ipv6地址的脚本
ifconfig | grep -A 10 wlp2s0 | grep 'inet6' | awk '{print $2}' | sed '/fe80/ d'
将上述脚本使用python封装
res = sp.run("ifconfig | grep -A 10 wlp2s0 | grep 'inet6' | awk '{print $2}' | sed '/fe80/ d'", shell=True, capture_output=True, encoding="utf8")ipv6_addrs = res.stdout.split() # ipv6地址可能有多个,随便用一个即可
完整的python代码(修改自参考中的示例代码)
# -*- coding: utf-8 -*-import osimport sysimport timeimport subprocessfrom loguru import logger as loglog.add("auto_refresh.log")from typing import Listfrom alibabacloud_alidns20150109.client import Client as Alidns20150109Clientfrom alibabacloud_tea_openapi import models as open_api_modelsfrom alibabacloud_alidns20150109 import models as alidns_20150109_modelsfrom alibabacloud_tea_util import models as util_modelsfrom alibabacloud_tea_util.client import Client as UtilClientclass Refresh: def __init__(self): pass @staticmethod def create_client( access_key_id: str, access_key_secret: str, ) -> Alidns20150109Client: """ 使用AK&SK初始化账号Client @param access_key_id: @param access_key_secret: @return: Client @throws Exception """ config = open_api_models.Config( access_key_id=access_key_id, access_key_secret=access_key_secret ) # Endpoint 请参考 https://api.aliyun.com/product/Alidns config.endpoint = f'alidns.cn-hangzhou.aliyuncs.com' return Alidns20150109Client(config) @staticmethod def update_dns( new_ip: str ) -> bool: # 请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_ID 和 ALIBABA_CLOUD_ACCESS_KEY_SECRET。 # 工程代码泄露可能会导致 AccessKey 泄露,并威胁账号下所有资源的安全性。以下代码示例使用环境变量获取 AccessKey 的方式进行调用,仅供参考,建议使用更安全的 STS 方式,更多鉴权访问方式请参见:https://help.aliyun.com/document_detail/378659.html client = Refresh.create_client("your-ALIBABA_CLOUD_ACCESS_KEY_ID", "your-ALIBABA_CLOUD_ACCESS_KEY_SECRET") # record_id 可以通过 DescribeDomainRecords 接口拿到, 见 https://next.api.aliyun.com/api/Alidns/2015-01-09/DescribeDomainRecords update_domain_record_request = alidns_20150109_models.UpdateDomainRecordRequest( record_id='879766660467119104', rr='ipv6', type='AAAA', value=new_ip ) runtime = util_models.RuntimeOptions() try: # 复制代码运行请自行打印 API 的返回值 client.update_domain_record_with_options(update_domain_record_request, runtime) return True except Exception as error: if "The DNS record already exists" in error.message: # 说明该条记录已经存在,则无需更新 return True log.error(error.message) # 诊断地址 log.error(error.data.get("Recommend")) UtilClient.assert_as_string(error.message) return False return Falseif __name__ == '__main__': # 检测当前ip是否和上次更新的ip一直,如果不一致则更新dns pre_ip, cur_ip = None, None while True: try: res = subprocess.run("ifconfig | grep -A 10 wlp2s0 | grep 'inet6' | awk '{print $2}' | sed '/fe80/ d'", shell=True, capture_output=True, encoding="utf8") if not (res and res.stdout and res.stdout.split()): raise Exception(f"empty ipv6 address, {res and res.stdout}") except Exception as e: log.error(f"get ip error, {e}") time.sleep(30) continue ipv6_addrs = res.stdout.split() if pre_ip in ipv6_addrs: time.sleep(1) continue else: cur_ip = ipv6_addrs[-1] updated = Refresh.update_dns(cur_ip) if updated: log.info(f"updated dns, pre: {pre_ip}, new: {cur_ip}") pre_ip = cur_ip time.sleep(30) continue else: log.error("update dns fail") time.sleep(30) continue
最后执行该文件即可
深圳联通光猫改桥接访问ipv6
问题
深圳联通宽带,提供了ipv6地址,内外可以访问,外网仍然访问不了。经排查,问题可能出在联通光猫上,它带有ipv6的防火墙,会阻拦入站流量,没有找到关闭的方法。
遂想到是否可以将光猫修改为桥接模式,然后使用路由器进行PPPoE拨号上网,自己的路由器对ipv6应该更宽容。
想要修改光猫就得拥有光猫的管理员权限,问题在于,由于联通宽带光猫的管理员账号密码是动态变化的,问宽带师傅他还不一定给。说来也比较奇怪,一个月前我在网上搜了一下,广东的联通光猫账号密码都是 CUAdmin/cuadmin+光猫mac前6位(光猫后面贴的有),当时还能登录进去,现在又登录不了了,不知道是不是最近才改成动态密码的(每过一段时间宽带提供方会自动更新光猫的密码)。
网上有很多通过telnet和ftp的方式查看密码的方法,例如这个等等,但到我这都没用,我按照他们提供的配置页面地址进去,全都会跳到登录页面,即使我已经登录了普通账户(光猫后面都会贴上一个普通用户的账号和密码)
后来是通过重置光猫的方式解决管理员账户的问题的,注意,在重置之前有些必要信息需要提前保存,以下为详细过程
光猫改桥接
记录信息
首先进入光猫后台(一般是 192.168.1.1),登录普通用户(光猫后面有贴)
登录后选择 “认证注册” 选项,将LOID(逻辑id)复制并保存在本地,后面要用
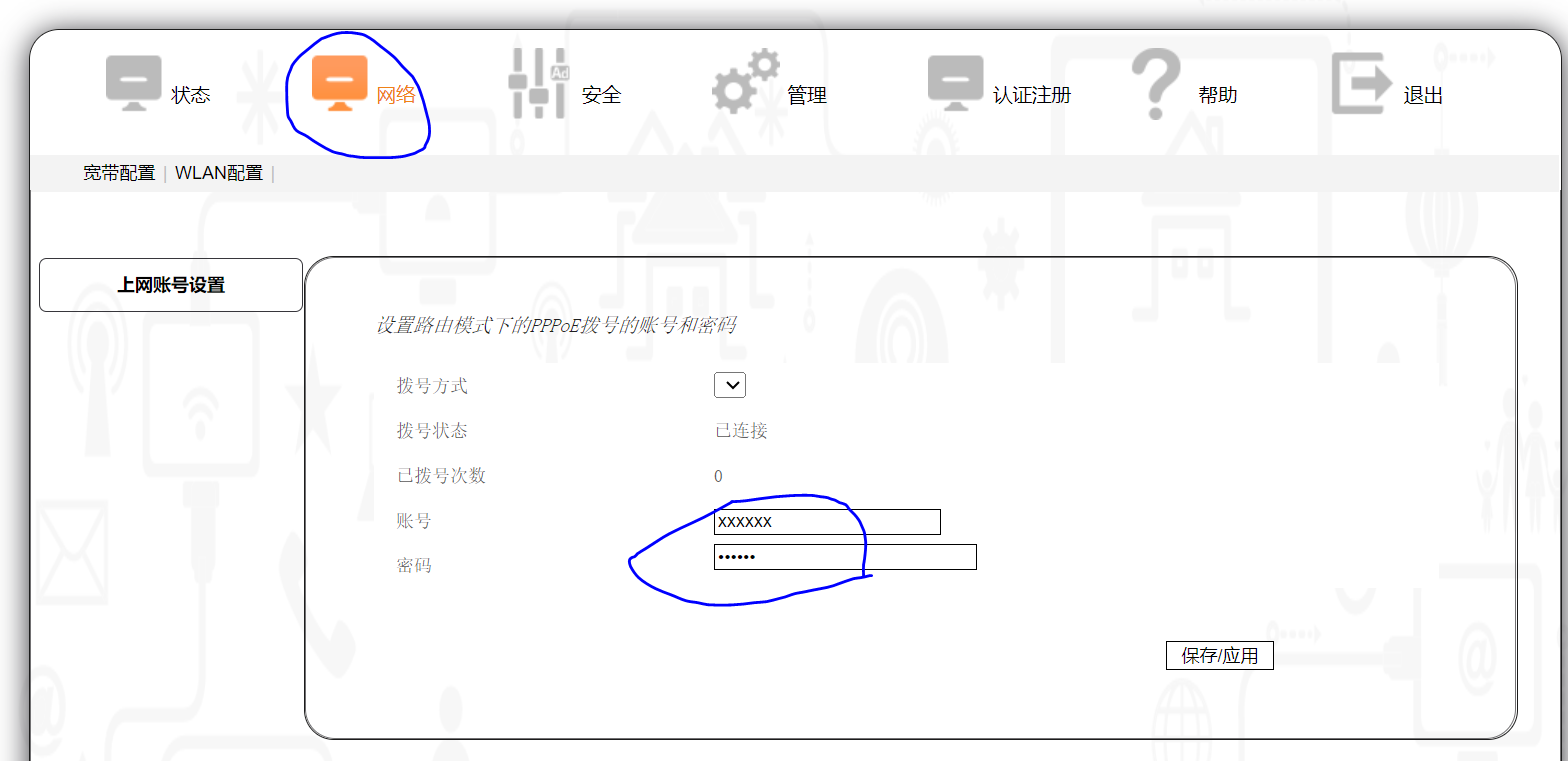
再进入 “网络” 选项,查看PPPoE拨号的账号和密码,账号一般明文显示,密码则是星号显示,要查看密码也很简单,打开浏览器的开发者模式,定位到密码框,将 input 标签的类型由 password 改为 text 即可。我这边查看到的密码就是账号的后6位。将账号和密码保持在本地
进入 “状态” 选项,记录一下vlanid,这一步对我来说没什么用,但是记录一下以防后续用到。vlanid就是后面的那几个数字
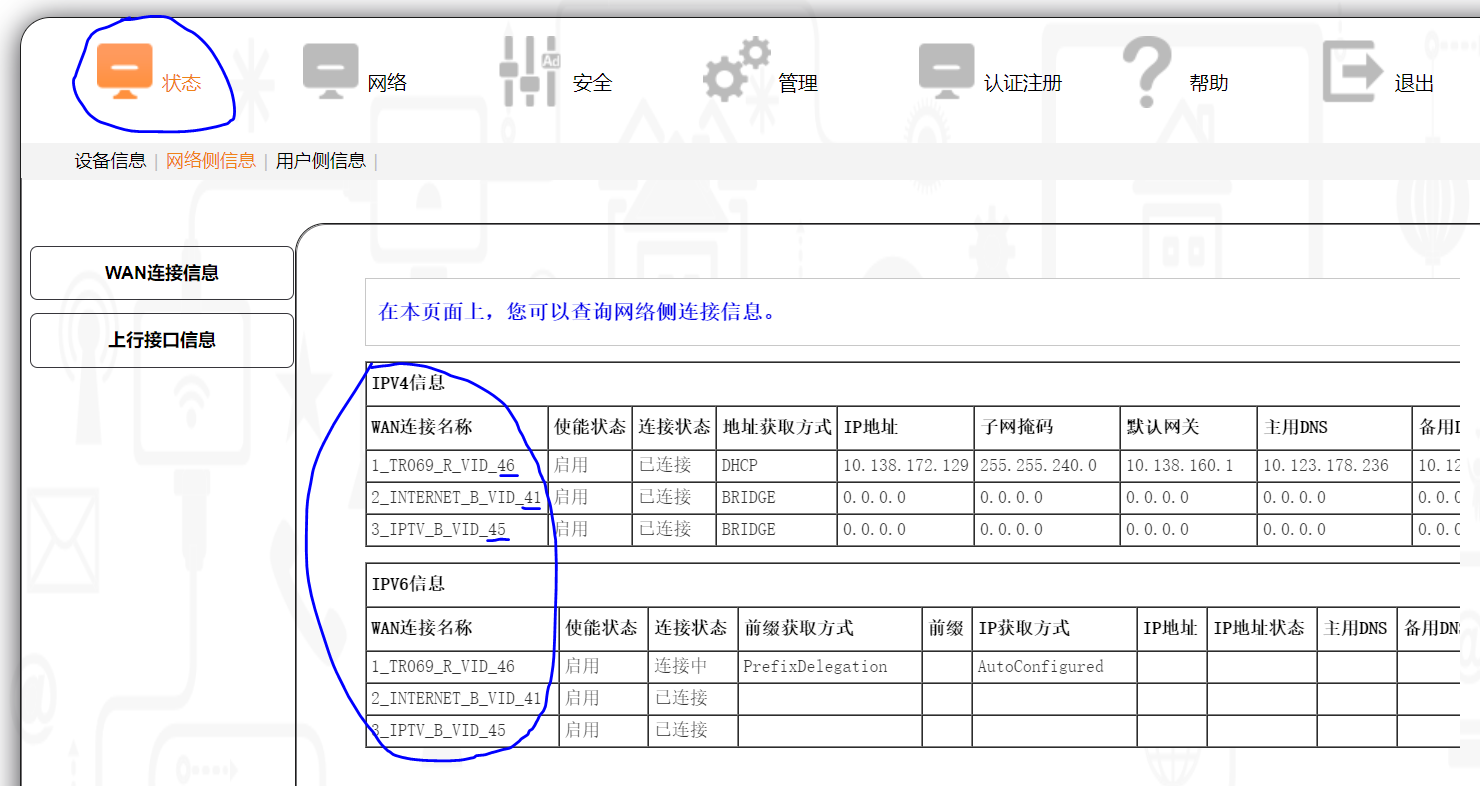
注:简单解释一下这三个东西是什么,可以直接理解成运营商会给你的光猫分配三条宽带,它们每一条宽带都是独立的,且拥有独立的ip地址:
-
TR069用于运营商远程管理你的光猫,例如远程修改光猫配置、更新光猫固件等,管理员动态密码就是运营商通过它远程下发的。网上有很多教程会说需要删掉该信道,但一般该信道的删除按钮会在前端置灰,真要删除的话只需要修改该button的dom属性即可点击
-
INTERNET 就是上网用的宽带,如果要将光猫网络改为桥接,则将它修改为桥接方式即可。
-
IPTV 就是用来看电视的
重置光猫
拿一根牙签一直按住光猫后面的复位按钮,直到前面板的等只剩一个电源灯在亮

设置光猫
再次进入光猫后台(192.168.1.1),选择管理员登录,此时直接使用 CUAdmin/CUAdmin 登录即可
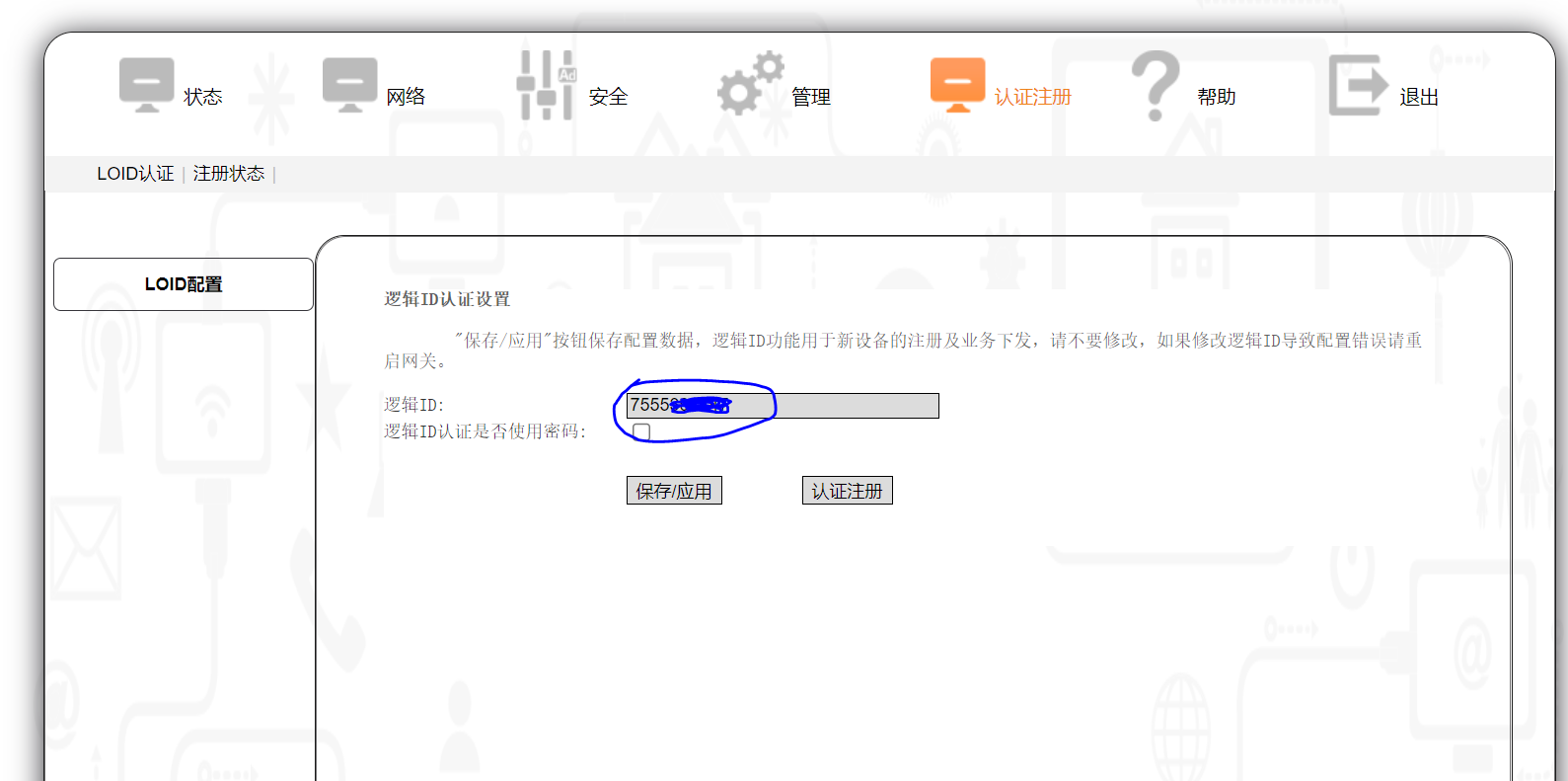
进入 “高级配置” 选项,选择 LOID配置,在 逻辑ID 处填入刚保存的LOID,点击保持按钮。
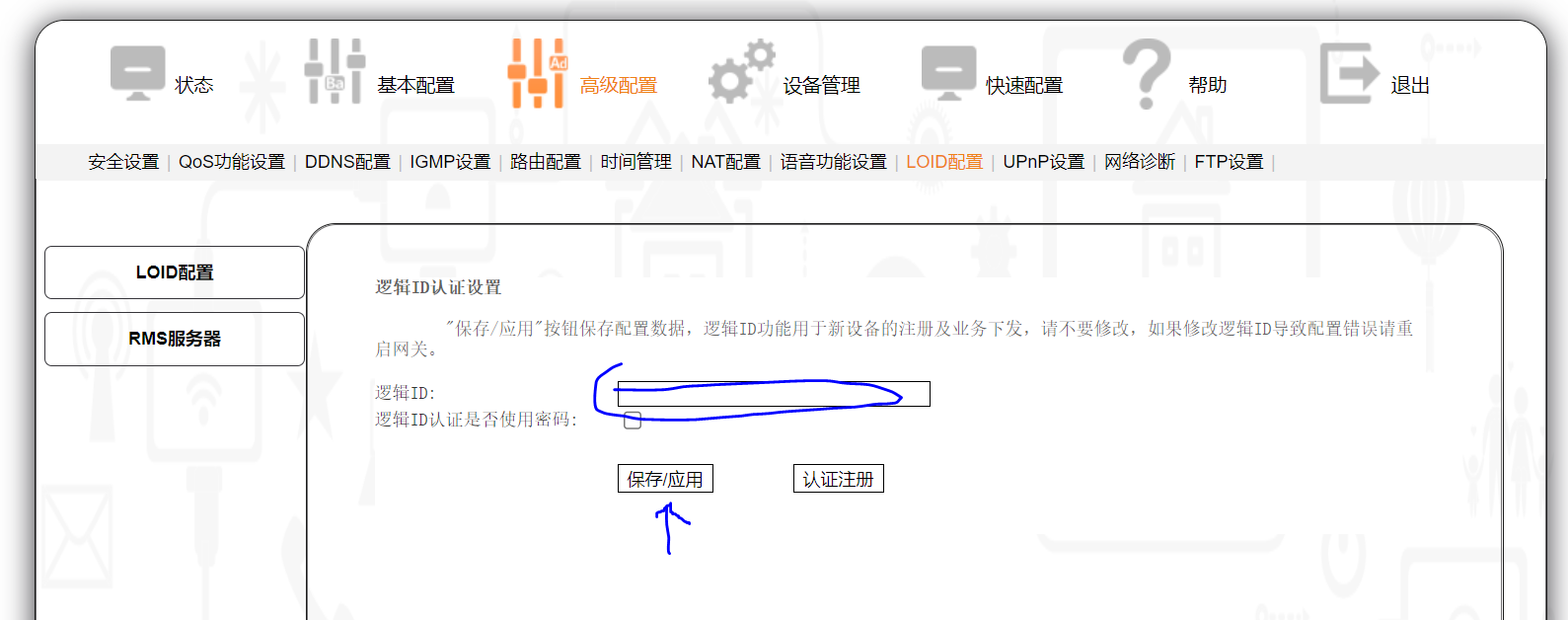
对我来说,到这一步之后,稍等一会我的光猫就会在路由模式下自动连上网,并且管理员密码已经被修改了,也就是说,光猫能不能上网貌似就认这个 LOID,至于拨号上网的PPPoE账号和密码则是自动下发的。
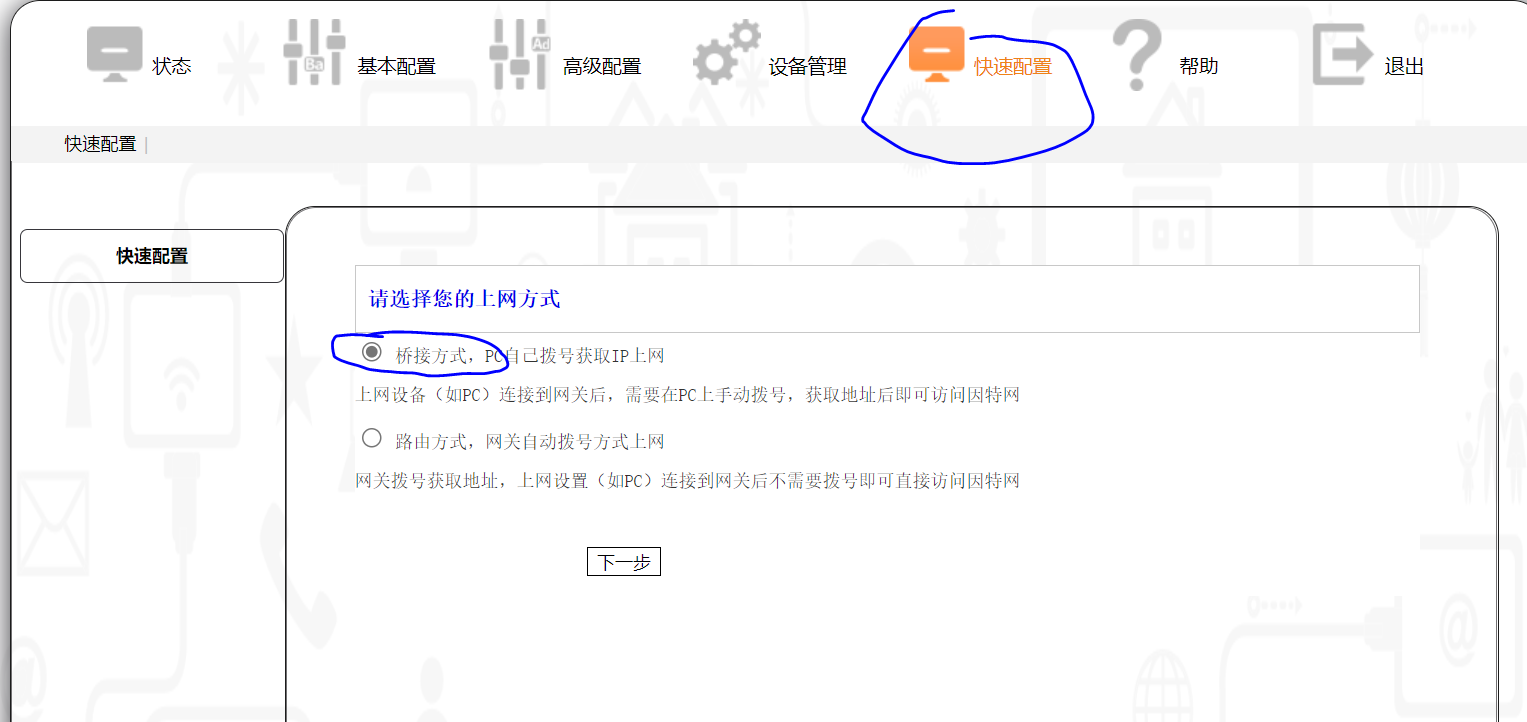
若想让其变为桥接,关键一步来了,你需要在点击保持上述LOID后,稍等一会(半分钟?一分钟?见下面的注)然后立即进入 “快速配置” 选项,选择第一个桥接方式,然后点击下一步,后面还会询问是否需要启用光猫的无线网,去掉勾勾即可,再点击完成
注:快速配置这里默认是勾选的桥接方式,当设置了 LOID 后,并且LOID生效后,它又会变成默认勾选路由方式,所以这里等待的关键就是要等它自动勾选为路由方式之后,再手动选择桥接方式
配置路由器
我这个路由器也是办宽带送的一个小米路由器,进入小米路由器后台(miwifi.com),在常用设置中找到上网设置,默认这里是DHCP方式,将其修改为PPPoE方式并输入刚才保存的宽带账号密码,点击应用按钮,等待一会即可
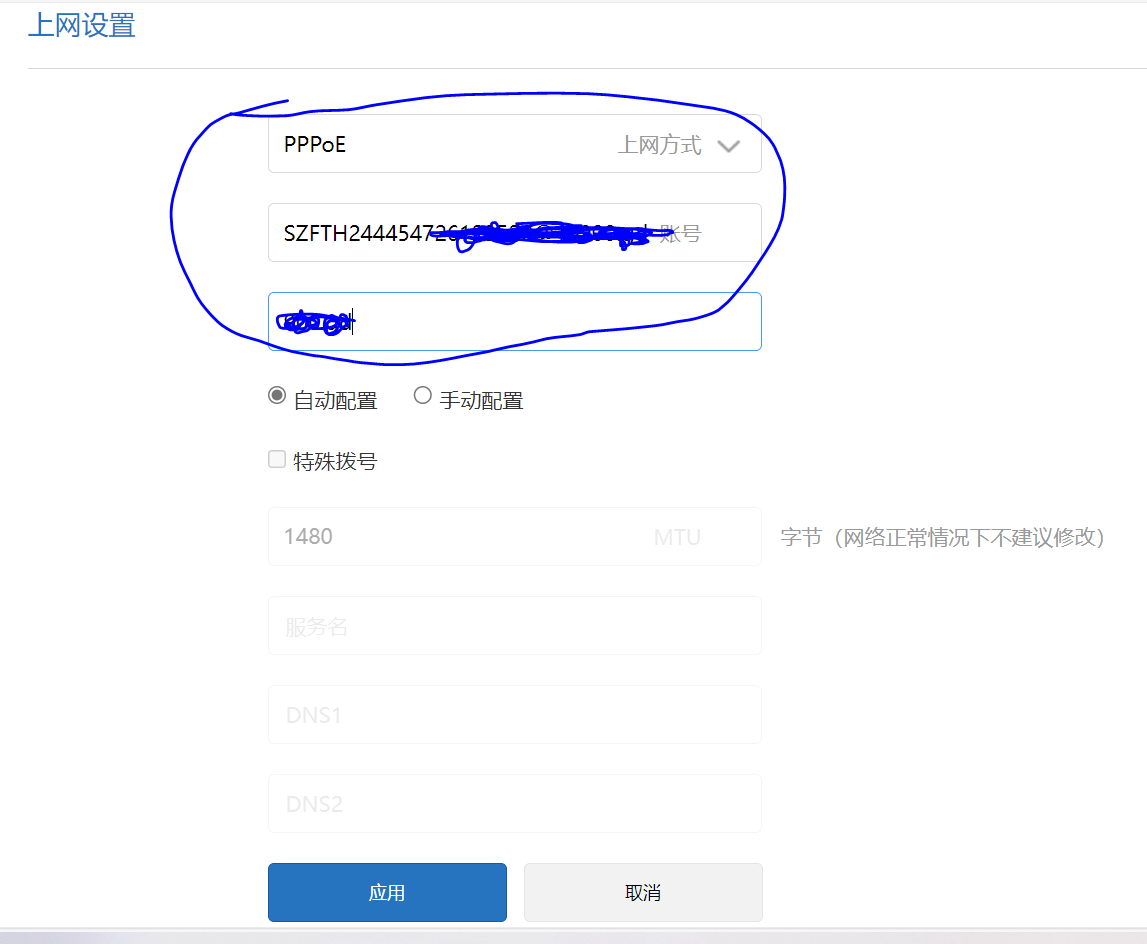
当在当前页面中的上网信息中能看到外网的ip地址时,说明已经可以了
注:路由器修改为PPPoE后就无法通过192.168.1.1进入光猫后台了
IPv6
路由器设置
在路由器后台的 上网设置 中找到 ipv6,将上网方式改为 Native
python孤儿进程示例和解决方法
子进程原本的父进程停了,它就会由系统的init进程接管,这个子线程就成了孤儿进程,另外还有个僵尸进程的概念,说的是进程已经结束了但是资源没有被父进程清理。
在python中很容易产生孤儿进程,例如以下代码:
import timeimport multiprocessingdef sub_task(): """子进程任务:循环打印时间和父进程状态""" while True: print(f"{time.asctime()}, {multiprocessing.parent_process().is_alive()}") time.sleep(1)def parent_task(): """父进程任务:开启一个循环打印的子进程,然后睡5秒""" sub_p = multiprocessing.Process(target=sub_task, daemon=True) sub_p.start() time.sleep(5) # 将这里的5s修改为2s试试if __name__ == "__main__": p = multiprocessing.Process(target=parent_task, daemon=False) p.start() # 创建“父进程”后主进程睡3秒然后停掉“父进程” time.sleep(3) p.terminate() p.join() p.close()
上述的代码执行起来就会有问题,你会发现,即使已经将子进程设置为守护进程(daemon=True),将其父进程结束后,该子进程仍然在在打印,但是父进程状态(is_alive())由原来的 True 变为了 False,该进程已经成为了孤儿进程
但是,如果你将上述父进程休眠时间从5秒修改为2秒,则子进程也会随着父进程的退出而退出。
上述代码运行后,通过实验或任务管理器你会发现,父进程确实是在3秒后直接终止了,而子进程却没有。问题就在于父进程是正常退出还是异常退出,当父进程在执行terminate()之前已经执行完了(设置2s的休眠时间),则为正常退出,此时父线程会自动清理其子进程。而如果在执行terminate()的时候父进程仍然在执行(sleep() 设置为5)则为异常退出,此时它还没来得及清理其子进程,故而其子进程成为了孤儿进程
一个比较好的解决方法是使用进程间通信,例如使用 multiprocessing.Event:
import timeimport multiprocessingdef sub_task(): """子进程任务:循环打印一个东西""" while True: print(f"{time.asctime()}, {multiprocessing.parent_process().is_alive()}") time.sleep(1)def parent_task(shutdown_flag): """父进程任务:开启一个循环打印的子进程,然后睡5秒""" sub_p = multiprocessing.Process(target=sub_task, daemon=True) sub_p.start() shutdown_flag.wait()if __name__ == "__main__": shutdown_flag = multiprocessing.Event() p = multiprocessing.Process(target=parent_task, args=(shutdown_flag,), daemon=False) p.start() # 创建“父进程”后睡3秒然后停掉“父进程” time.sleep(3) shutdown_flag.set() p.join() p.close() print("main done")
multiprocessing.Event() 可以理解为一个bool值,有四个方法:
有一种金鱼
很小的时候看的一篇鸡汤文,大意是说,有一种金鱼,其体型会随着鱼缸的大小而受到影响,鱼缸越大,它最终长得就越大,对这篇文章印象比较深。我也比较推崇“环境主导论”。
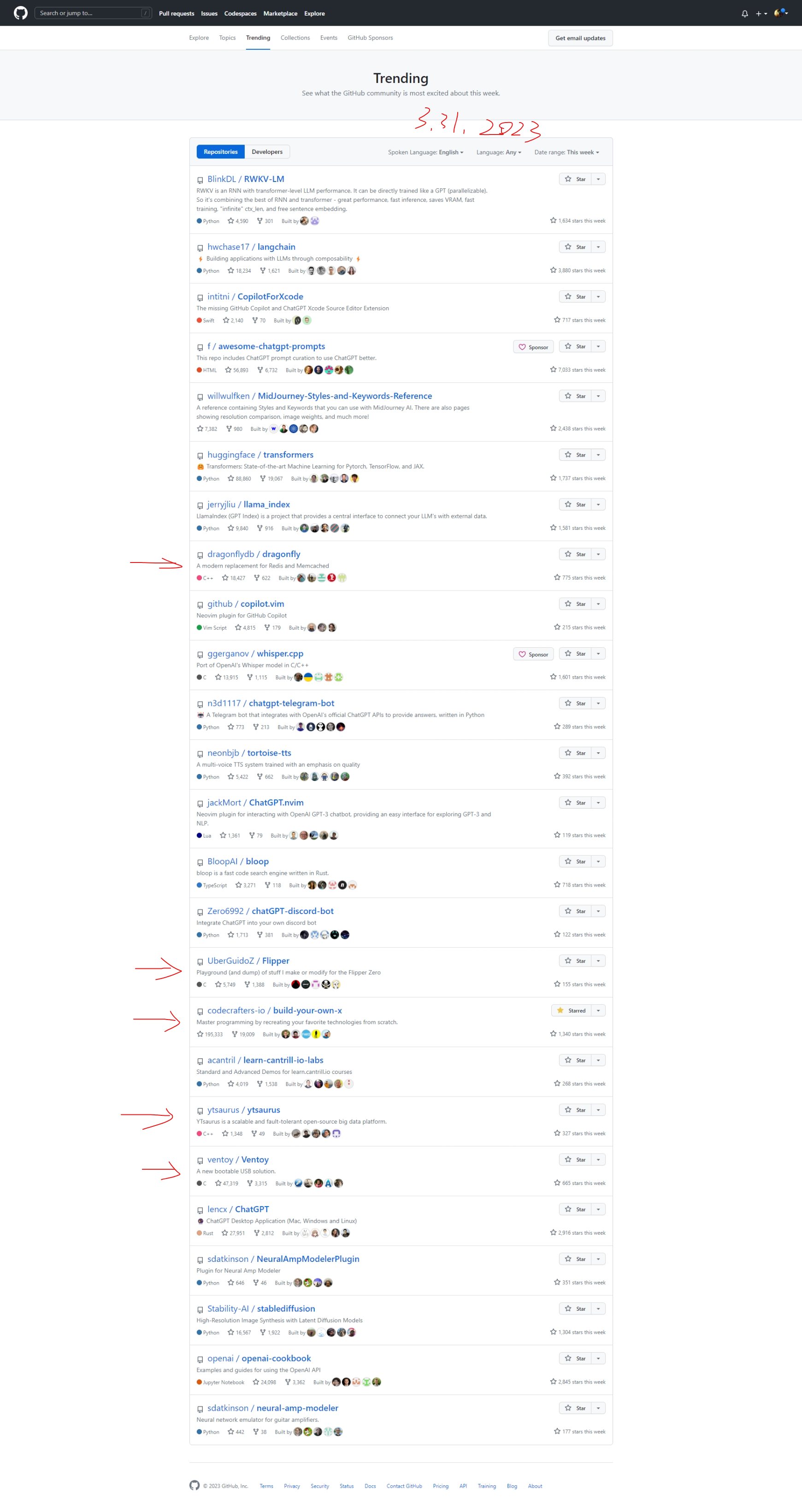
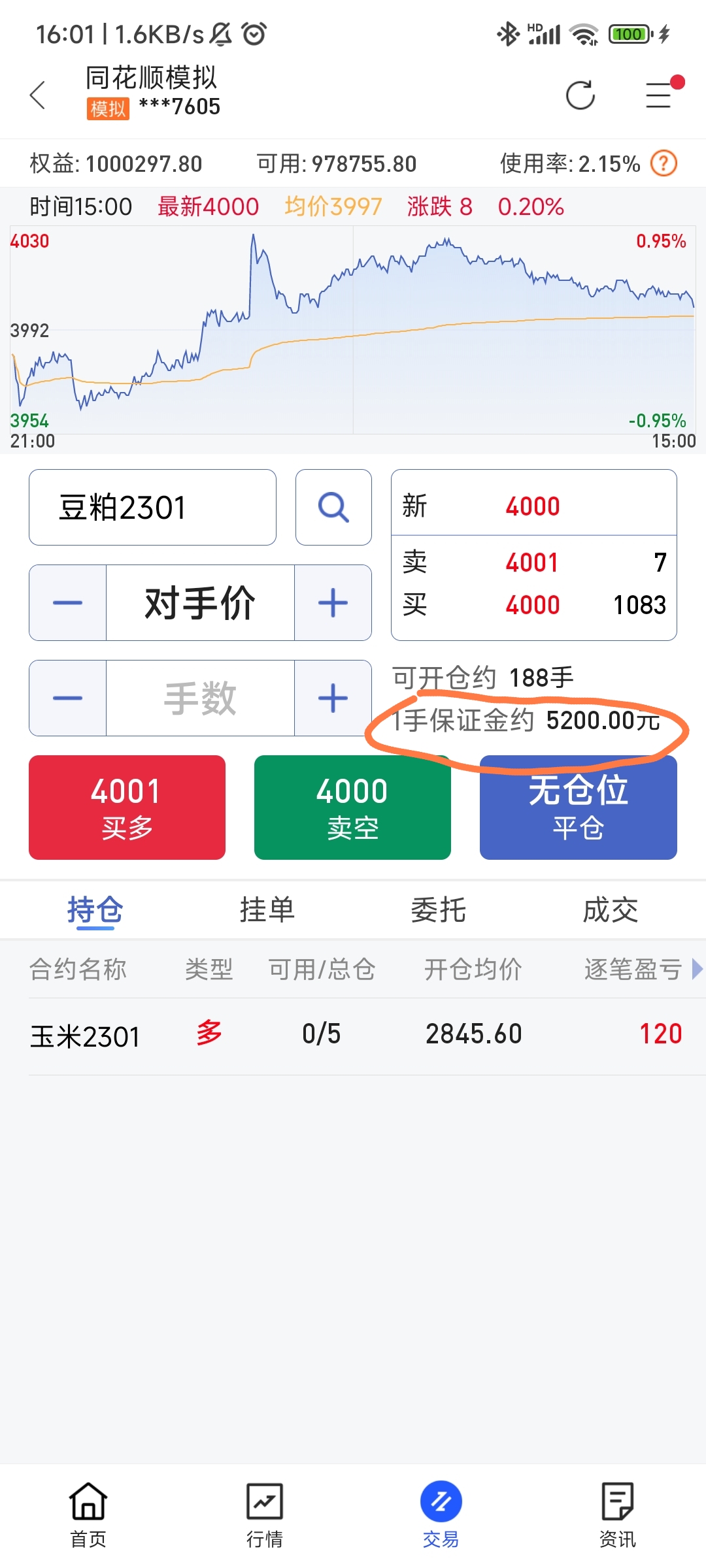
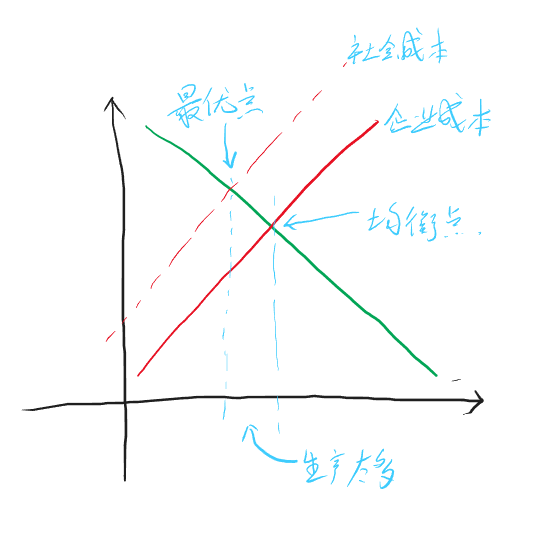
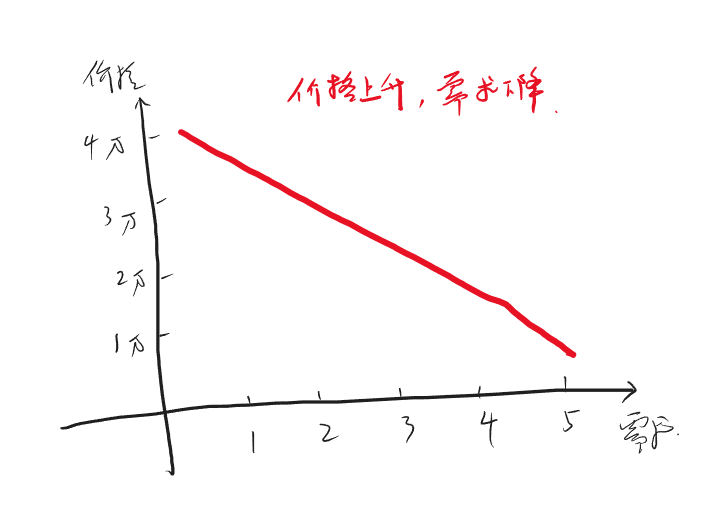
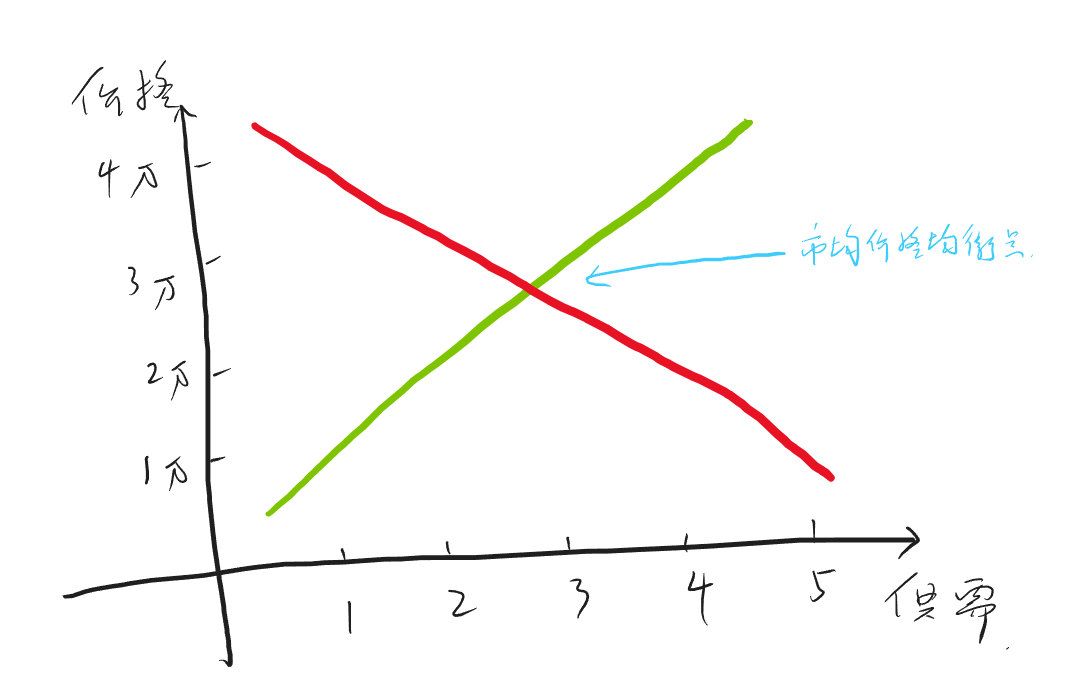
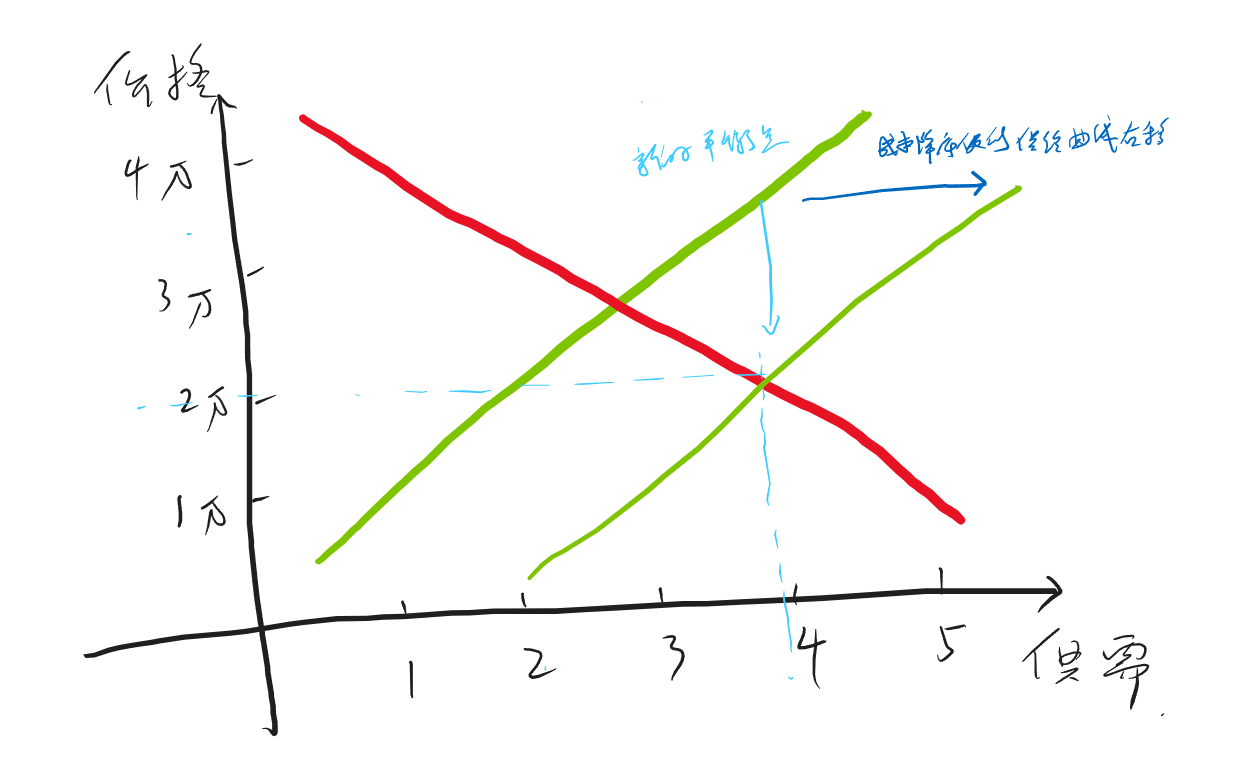
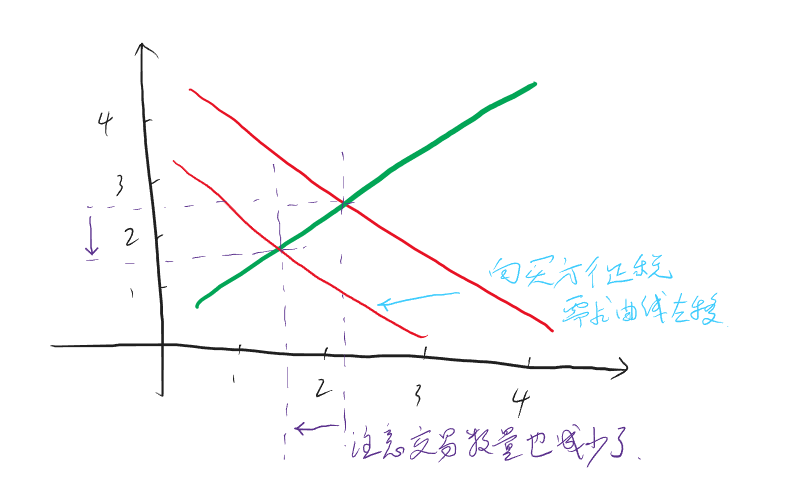
期货多/空头持仓市值计算
多头
多头比较简单也比较直观,公式如下:
\[ 多头持仓市值 = 持仓量 * 合约乘数 * 买一价 - 持仓量 * 合约乘数 * 成本价 * (1 - 保证金率) \ ]
可以这样理解这个公式:持仓量 * 合约乘数 * 买一价 得到的是多头持仓的实际市值,但是由于你在买这个仓位时并非”全款“买的,而是加了杠杆的,也就是说,你本来应该花 持仓量 * 合约乘数 * 成本价 这么多钱,实际上却只花了其 保证金率 的那部分,剩余部分是借来的,既然是借来的,那自然是要还的,所以得减去这部分
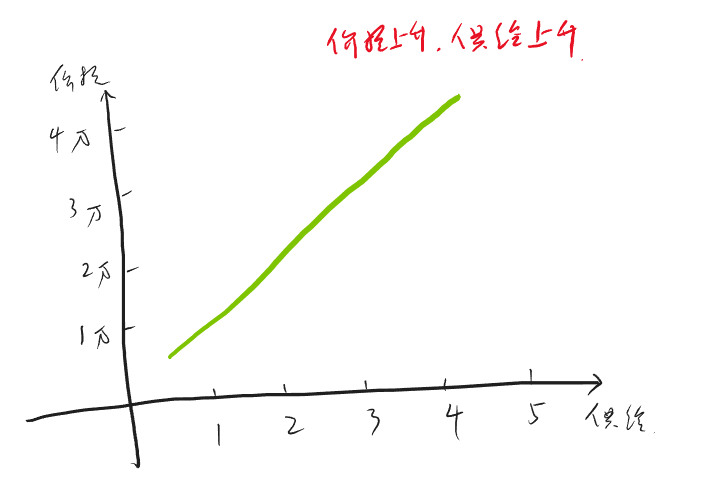
空头
空头不太好理解,至少我在推导这个公式的时候绕了不少时间。公式如下:
\[ 空头持仓市值 = 持仓量 * 合约乘数 * 成本价 * (1 + 保证金率) - 持仓量 * 合约乘数 * 卖一价 \ ]
空头简单说就是市场好的时候,你借别人的合约卖出去,然后等市场差的时候再低价买回来还回去。
可以这样理解这个公式:我认为这里比较绕的部分是,多头持仓是在你开头寸的时候花钱的,而在平的一瞬间是给你钱的,这就和平时买卖东西一样,而空头持仓是在你开的时候给你钱的,而在平的时候花钱的。但实际在交易空头过程中,你仍然是在开的时候花钱,平的时候给你钱,为什么会这样呢?因为开的时候是你向交易所借的头寸卖出去,这个时候交易所不会无缘无故借给你,所以你需要缴纳与头寸同价值的保证金,但是这个保证金也不是要你全额给,之需要你给保证金率那部分,与此同时,交易所将你借的头寸卖出去后,会得到卖的钱,理论上这个钱应该是直接给到你的账户,这样就符合上面说的逻辑,但实际上这个钱会直接给到交易所。至此,交易所那里就有你的两笔钱,一笔是你借头寸的保证金(带杠杆),一笔是卖期货的钱(全额),而你也在开空头的时候花了钱。当你平掉这个空头的时候,你需要去市场买同样多的头寸还给交易所,但因为开的时候卖期货的钱是给到了交易所,所以交易所会用卖期货得到的钱帮你去市场买这些头寸,所以平的时候你就不用花钱。与此同时,交易所会将之前那两部分钱还给你,并同时扣除平的时候去市场买头寸的钱。这就是上面这个公式的由来。
保证金和手续费
可以参见 期货开户知识
另外要注意:手续费是按手数收的,也就是说,你一次买 5 手,是收 5*手续费 这么多钱
windows文件管理器没有空白区域点右键
即使用了windows这么多年,这东西仍然让我非常抓狂。
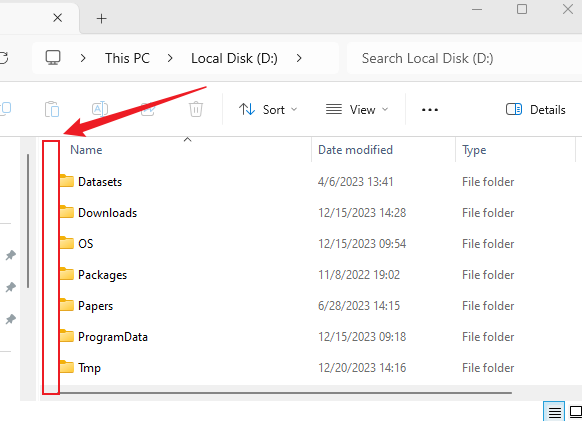
当你打开文件管理器,文件区域都被各种文件或文件夹占满了,此时你想在当前文件夹中右击鼠标(比如打开git bash、新建文件夹等),亦或者你需要从其他位置拖动一个文件到当前文件夹,此时如果你很容易就将这个文件移动到当前文件夹的一个子文件夹了,因为已经没有多余的空白位置给你点击右键了,有时候真的很让人抓狂
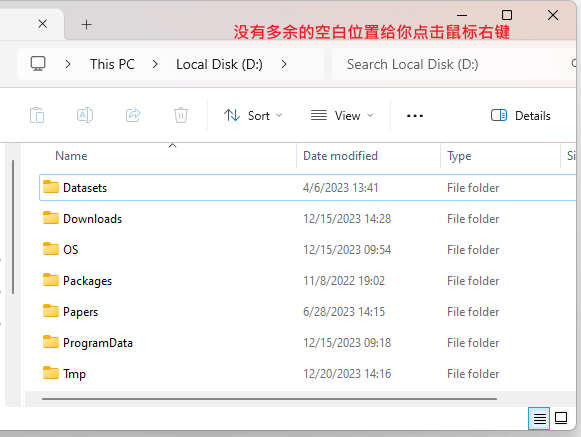
过去我一直都是小心翼翼地将鼠标移动到两个文件夹中间的空白位置,但很容易偏,以下为解决方法:
对于要拖动文件复制/移动到当前文件夹,可以将文件拖动到整个文件管理器下面的空白区域:
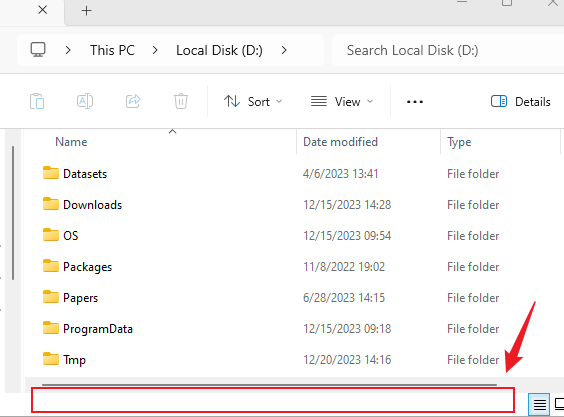
对于需要在当前文件夹右键的,可以选择这个区域:
Visual Studio 中文注释显示乱码
现象
下载的第三方源代码中的中文在 Visual Studio 2022 中显示乱码
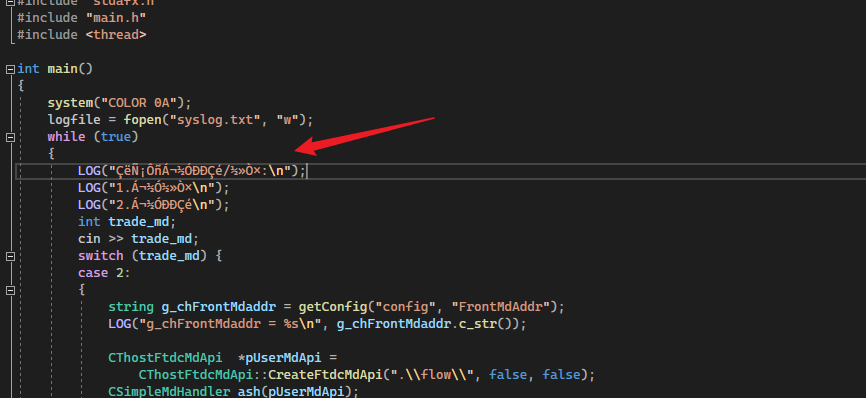
解决
右键要打开的代码文件,选择 “open with…”
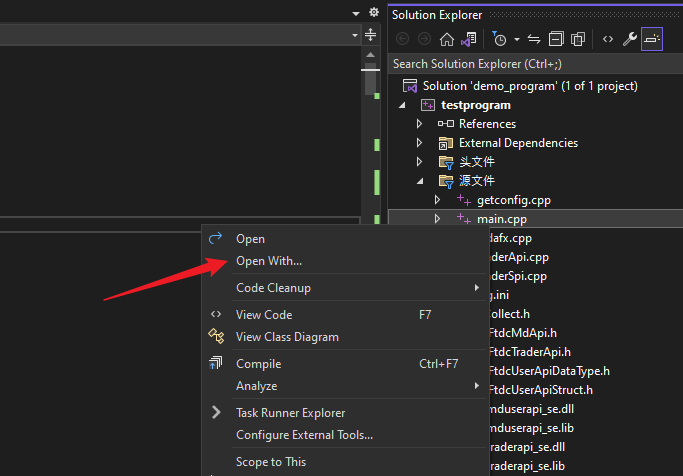
弹出的对话框选择:
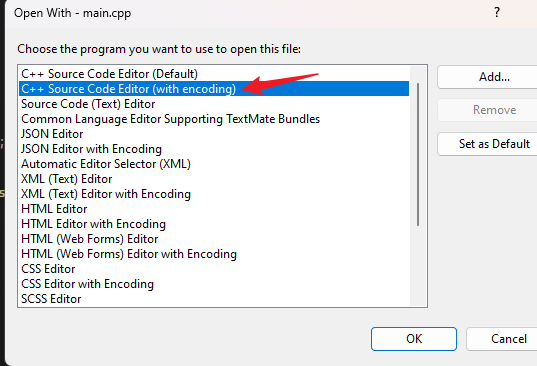
进一步可以选择 utf8 或者 gb2312 等,不行就多试几个
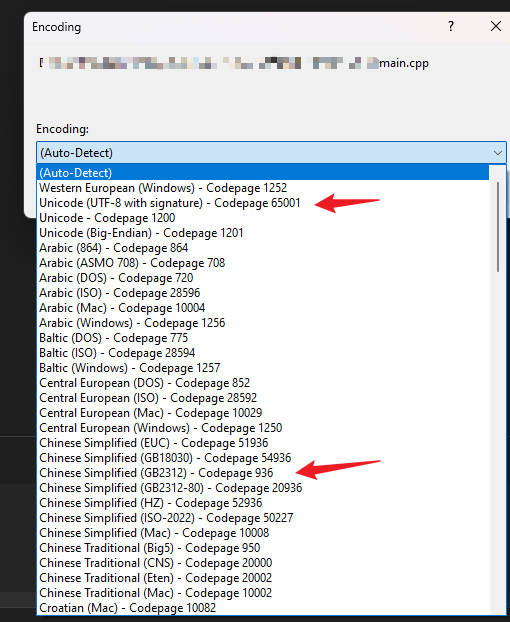
然后就能正常显示
参考
cmd显示乱码
源文件以gb2312保存的,所以终端也得用该编码显示,否则就会出现乱码
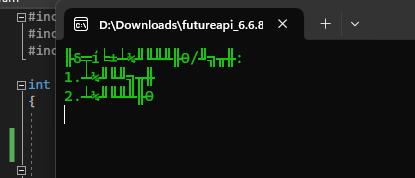
解决方法是在代码前加上
...system("chcp 936");cout << "你好"...
用于临时修改cmd的编码方式,其中chcp就是修改命令,936表示gb2312,65001表示utf8
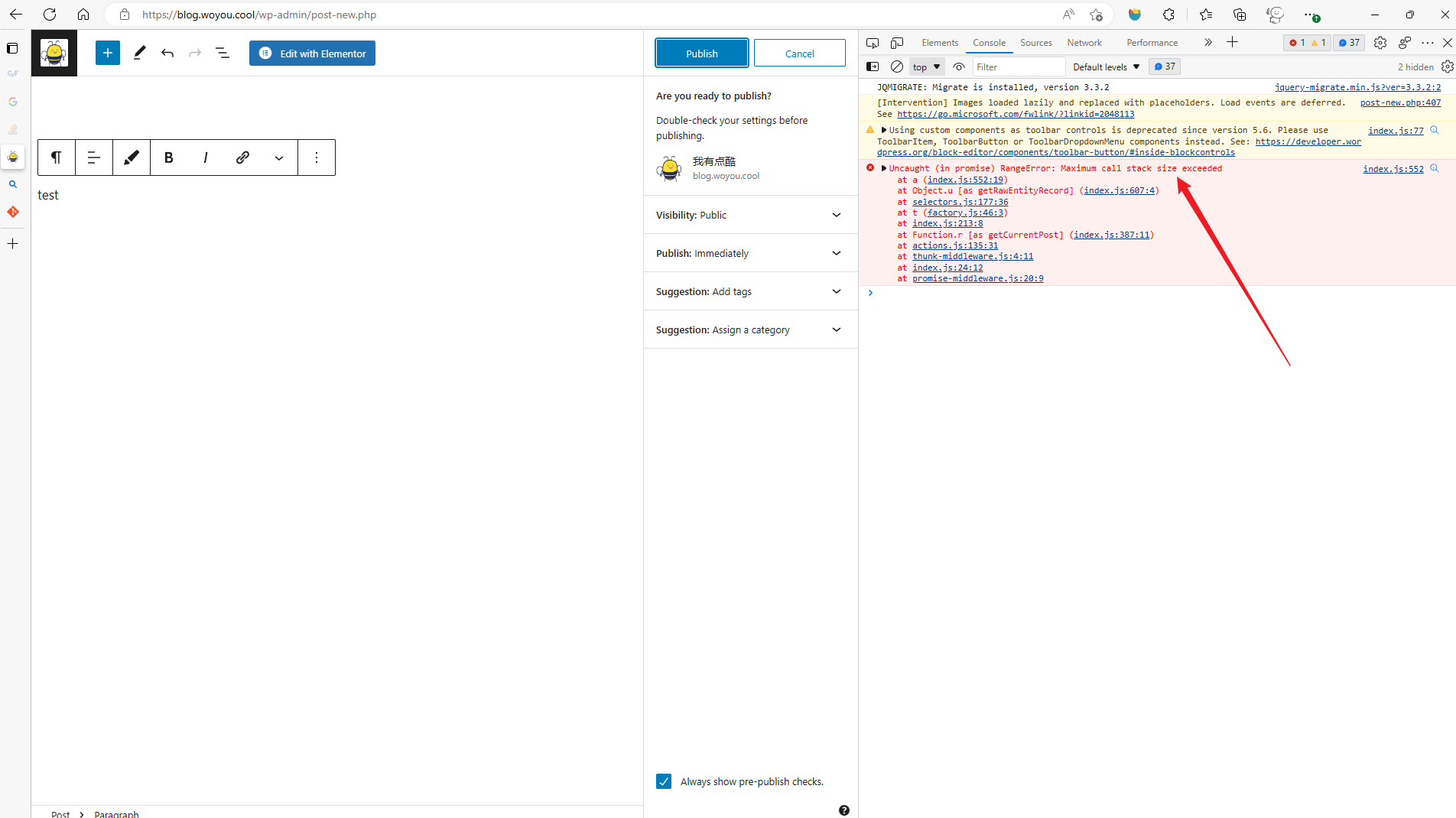
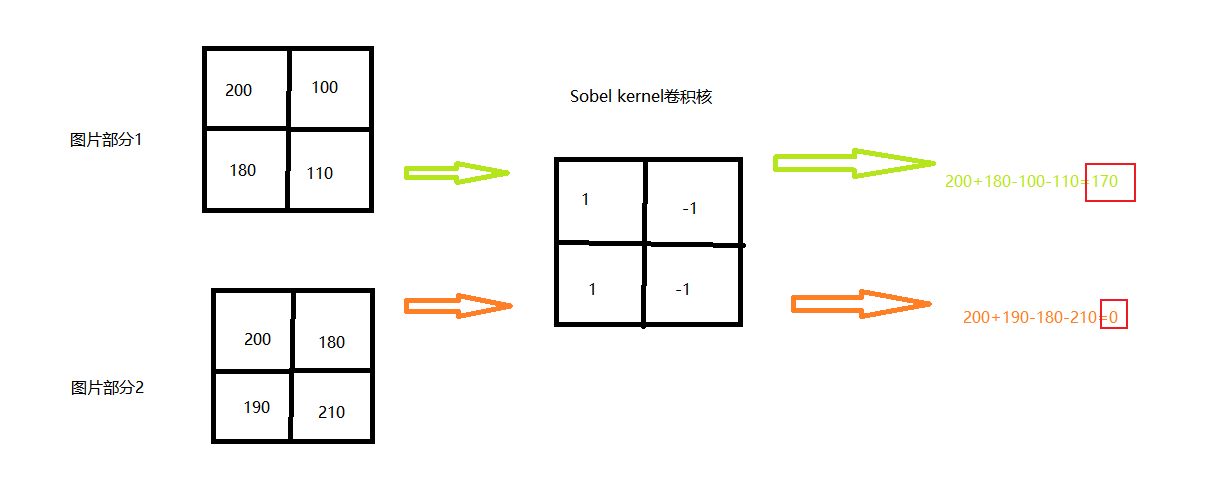
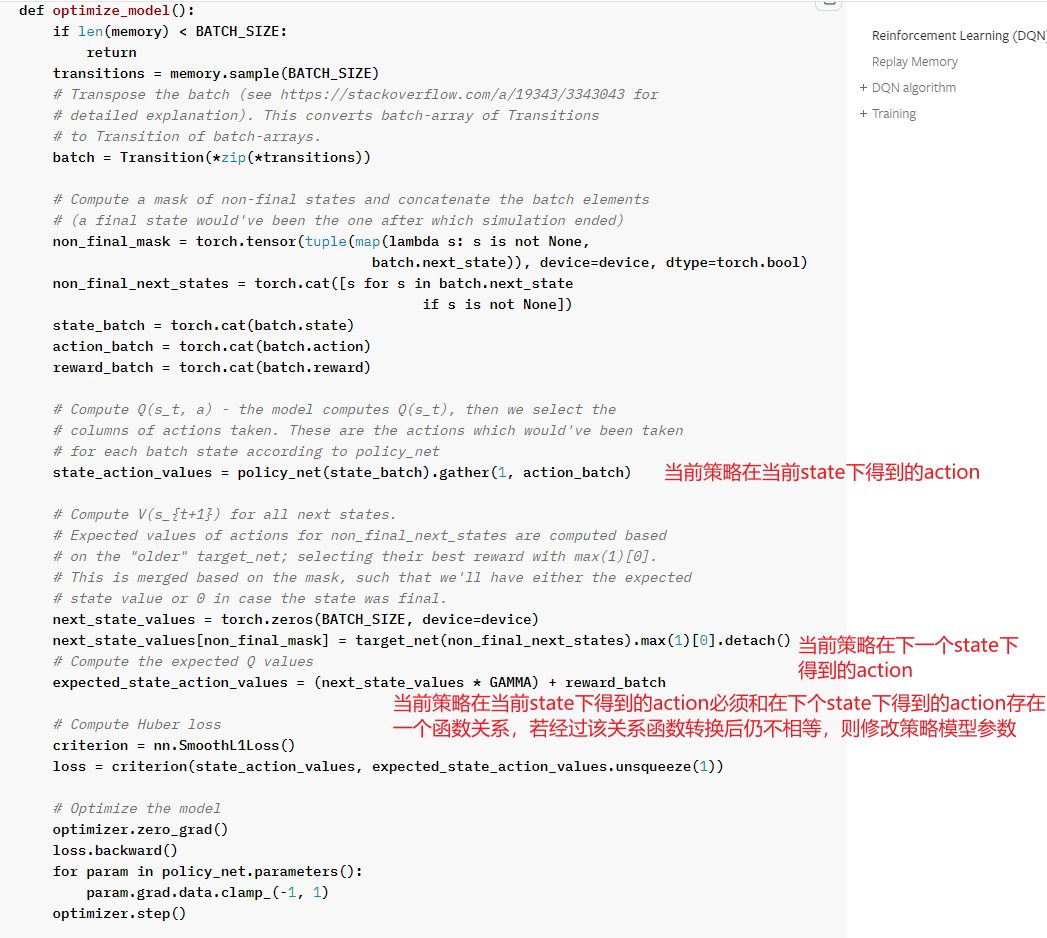
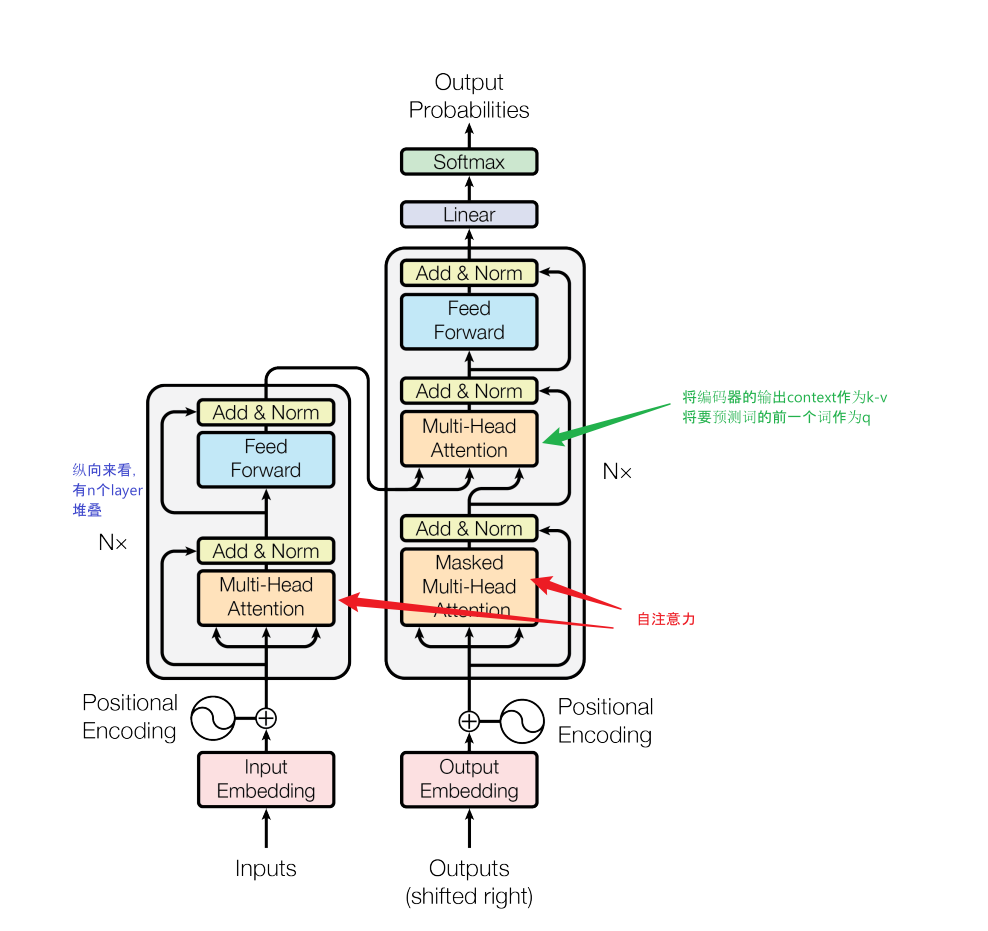
clipped surrogate loss in PPO
PPO是一种off policy的强化学习算法,它的优势就是可以重复使用之前policy与环境交互得到的数据,它通过将一个分布中的采样数据转换为从另一个分布中的采样数据,即从old policy这个分布转换为new policy这个分布
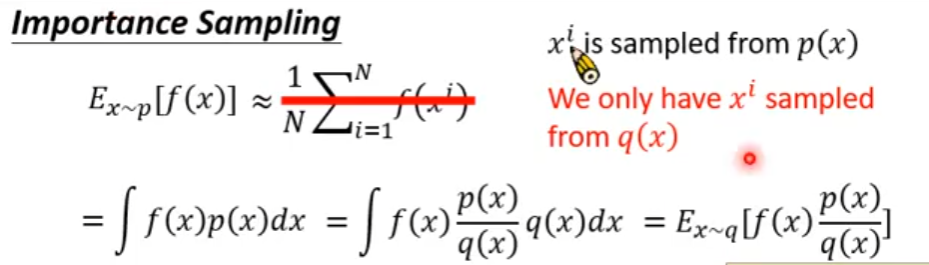
PPO就是在此基础上做了进一步优化使得其能适应强化学习的环境,其核心就是下面这个公式:
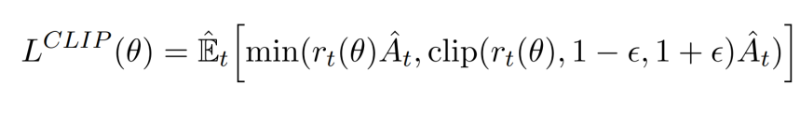
其中的 ( r_t(θ) \ ) 为:
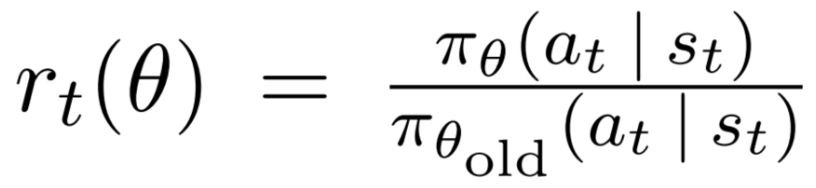
即新旧策略在状态St下得到at的概率比值,显然,如果该比值大于1,说明新的策略更倾向于选择该action
以下为 stable-baseline3 中该表达式的实现,其中,ratio就是上述的那个比值,clip_range取值为0.2
# clipped surrogate loss
policy_loss_1 = advantages * ratio
policy_loss_2 = advantages * th.clamp(ratio, 1 - clip_range, 1 + clip_range)
policy_loss = -th.min(policy_loss_1, policy_loss_2).mean()
现在就有两个问题,1)对clamp(clip)的理解,2)对min的理解
clamp
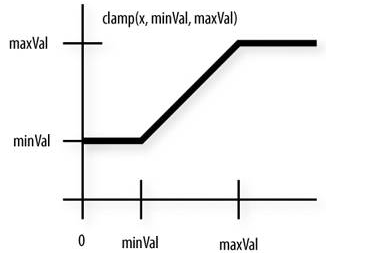
从公式中看出,clamp是对ratio的裁切,即避免它过大或过小,为什么要这么做呢?通过 Importance Sampling 的式子可以看出,将一个分布转换为另一个分布后,它的期望值是没变的,但是它们的方差是不同的,若仅采样有限数据,很容易出现误差

注意到上图中,两者方差的第一项是不同的,后者会多乘这个ratio。理论上来说,由于均值不受影响,所以只要采样的数据足够多,也不会对最终结果产生较大影响,但对于一个实际意义的马尔可夫奖励过程,几乎是不太可能采样足够多的
一个非常需要注意的点是,被clamp过的部分是没有梯度的,即梯度为0,根据链式求导法则,前面计算的梯度应该都是0
换句话说,我们并不希望new policy和old policy的差异过大,如果太大的话,干脆就不对模型做更新了
min
如果当前的Advantage是正值时,如果当前的new policy远小于(两者比值小于某个阈值)old policy得到该action的probability,我仍然希望模型能够学到东西(参数更新,增大policy取得该action的概率)。
相反,若此时,new policy的probability远大于old policy,因为此时advantage是正值,我们的目的就是要让new policy的probability更大,而它此时已经比old大了,所以我们就应该避免它更大,故此时反而应该将其clamp掉,使得其梯度为0,进而使其不做更新
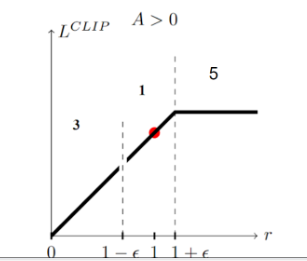
如果当前的advantage是负值时,若new policy的probability远大于old policy,则继续让其更新,因为我们要试图减小policy产生该action的概率,反之亦然
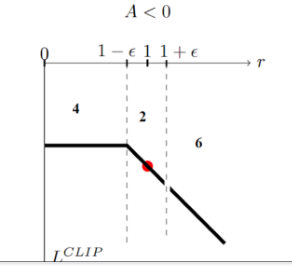
参考
https://huggingface.co/learn/deep-rl-course/unit8/clipped-surrogate-objective
https://huggingface.co/learn/deep-rl-course/unit8/visualize
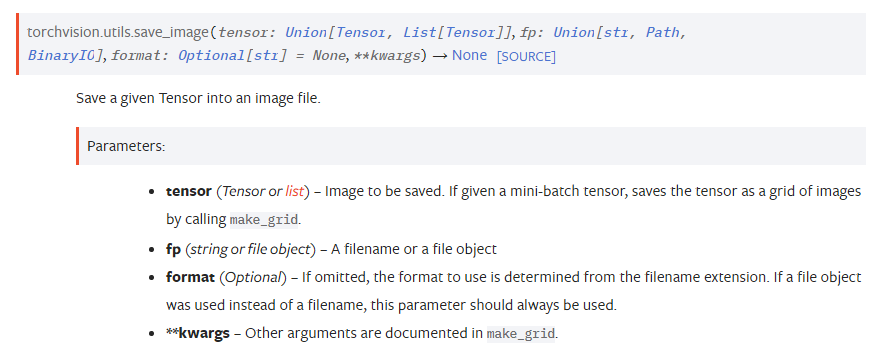
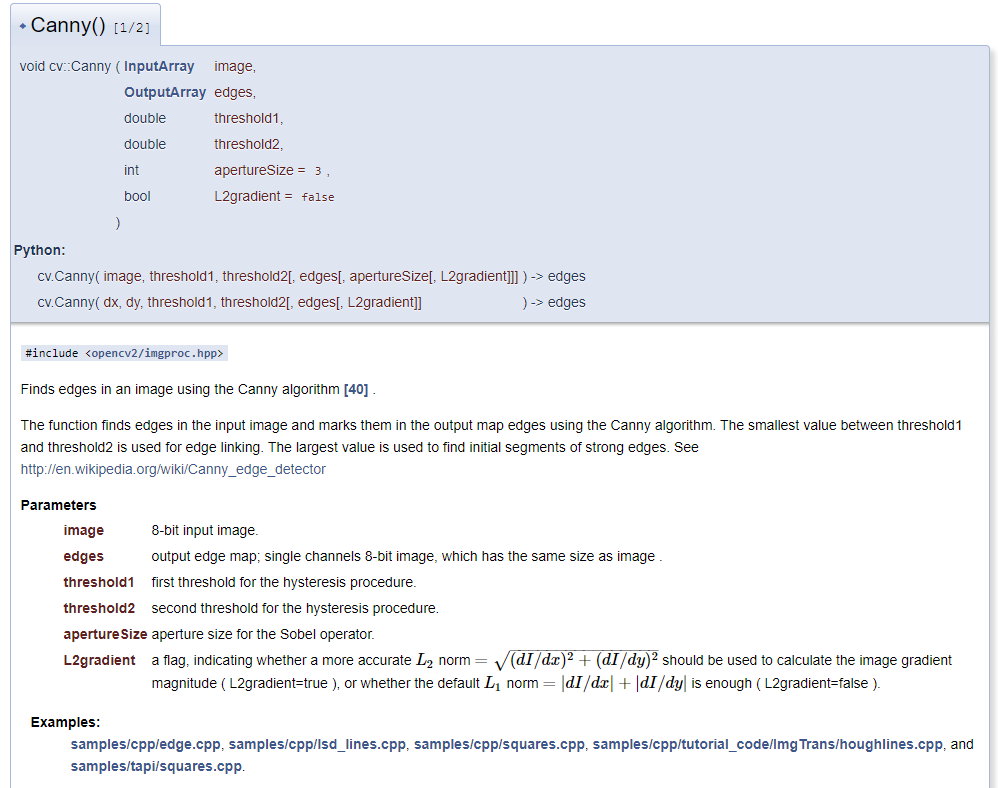
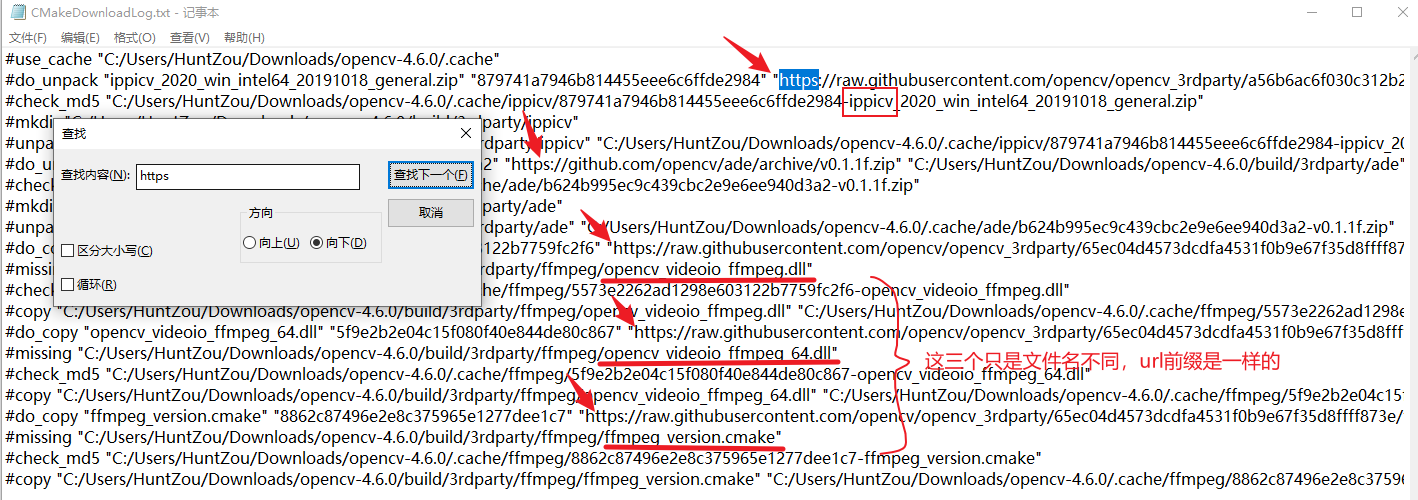
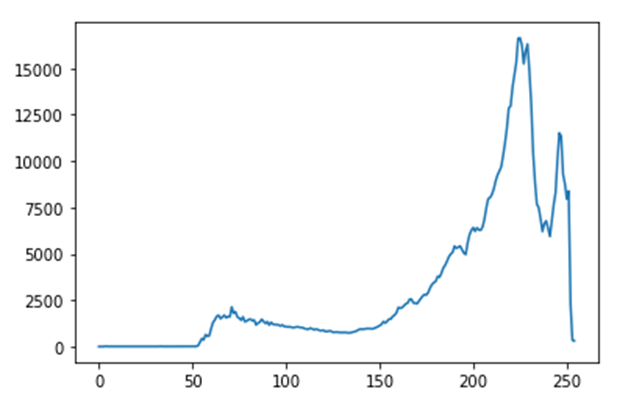
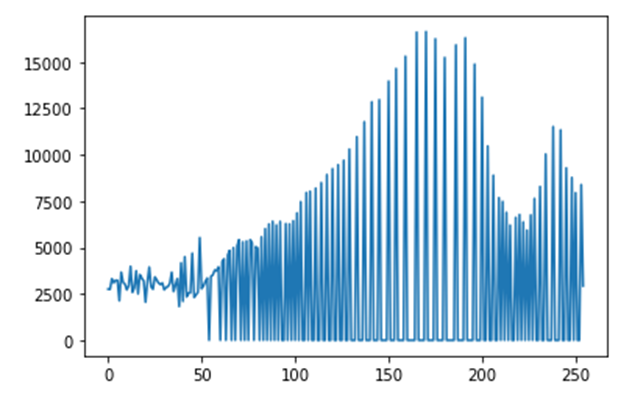
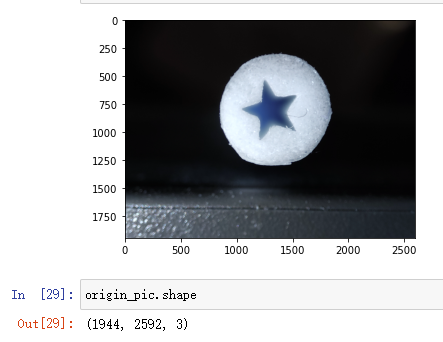
opencv不同环境下output不一致的一种场景
现象
opencv在c++和python中得到的结果不一致,即使是相同的语言相同的环境也可能得到不同的结果。
在做一个视觉项目时,其中有使用opencv,开发过程中我会先使用python写出基本的代码进行测试,可行的话再用c++(qt)复写一遍,本机测试完成后上传到服务器实机测试,一开始开发过程还算正常,后面就发现,服务器上有些图片识别的有问题,遂将有问题的图片都过程保存成 xxx.jpg,然后拉到本地看看啥问题,结果本地识别起来又没问题,甚至于有的时候,使用python处理后得到的中间结果再用c++继续处理就会出现和只用python处理的结果不一样。
这种情况并不普遍,几千张图片可能出现几个异常的情况。拉下来后本地又识别得没问题。
排查
一开始以为是缓存的原因,但是仔细重构代码后排除了这种可能
然后以为是并发的原因,因为之前也出现过一次使用qt出现的并发问题,多线程下一个野指针出现的问题,也是小概率出现,也是折腾了很久才解决。
反正就是搞了很久,还是无法百分百确定是不是并发造成的,于是想想是不是其他原因
甚至于我将每张出问题的图片的每个中间处理过程都保存下来和本地进行对比,输入一样(目视)但结果就是会出现不一致
最后,我将每张图片都保存后让程序进行重放(按原来顺序重新检测),经过对比发现,不是随机出现的,遂确定不是并发导致的,于是我将出问题的图片单独进行检测,奇迹出现了,不管是本机还是服务器,检测结果都一致了,我又试了多次,确实是一致的。
我的代码中,出问题的地方主要是霍夫圆检测上(HoughCircles),该函数基于Canny算子做边缘检测,然后我发现之前出问题的图片,虽然输入的图像目视是一样的,但Canny处理后的结果会出现些许不同。虽然不同的地方还是比较少,但我觉得霍夫圆检测对参数还是比较敏感的。
然后我突然想到,之前不一致的情况都经过了一次中间过程的存储,然后再进行读取的,那问题一定是出现在存储格式上。
解决
问题就出现在jpg这种图片格式上,其实从一开始我就有想到这个东西,因为我一直对傅里叶变换比较感兴趣,而jpg就是用该原理实现的,但不知道怎么的,后面忘了这茬了。将图片以位图的形式保存就好了。
// 原来的
cv::imwrite("img", "xxx.jpg")
// 现在的
cv::imwrite("img", "xxx.bmp")
后记
有一说一,c++/qt 好像做什么都比较麻烦,还不好debug,用惯了jetbrain的ide再用qtcreator感觉就像回到了上个世纪。
github双击.ipynb内容消失
症状
随意打开github上的一个.ipynb文件,例如这个,任意双击或者选中某个内容,然后整个文档就消失了,并且提示 “Unable to render code block”

刷新页面又出现了
原因
这是带弹窗的浏览器插件引起的,对于我来说,是 Saladict 这个插件,它的作用就是选中一个单词,然后出现一个弹窗显示该单词的内容
解决
关掉弹窗插件
stable-baselines3中的SAC
现象
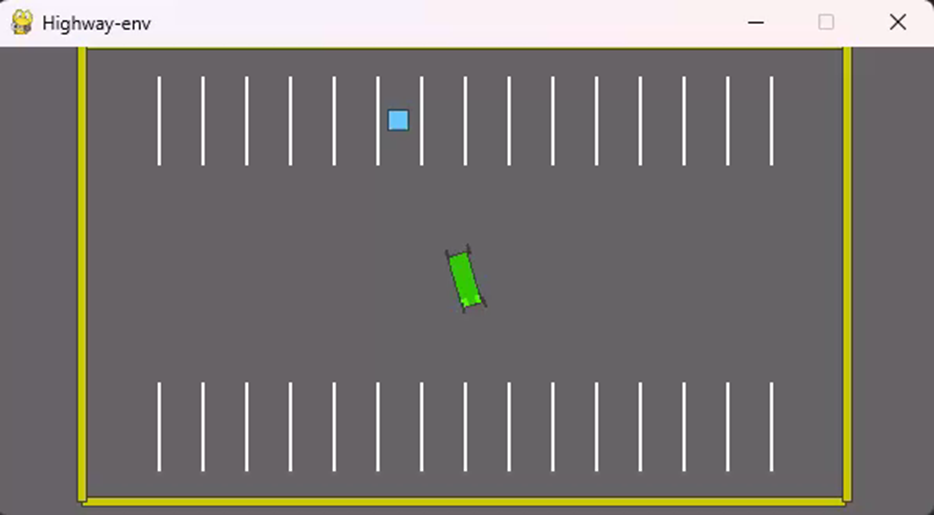
本来自己写了一个SAC模型用于测试parking环境(http://highway-env.farama.org/environments/parking/),该环境模拟自动停车过程,小车需要停到停车场随机的一个目标车位(见下视频)
无奈模型怎么也无法达到预期效果,经过多次测试发现,仅仅将DDPG修改为不确定性策略是可行的,但一旦加上最大熵(SAC的核心)模型就不不行了,然后使用stable-baselines3(https://github.com/DLR-RM/stable-baselines3/tree/master/stable_baselines3/sac)就可以,遂研究了一下两者代码的区别,发现,SB3默认会使用一个ent_coef的可学习参数,作为最大熵的系数,该参数可设置为固定值,以下分别为设置为固定值和可学习参数得到的效果:
使用固定值为1的效果,见日志中的 train/ent_coef,从最终效果中可以看到,好像小车有那么一点点趋势会向目标点靠近,但不多
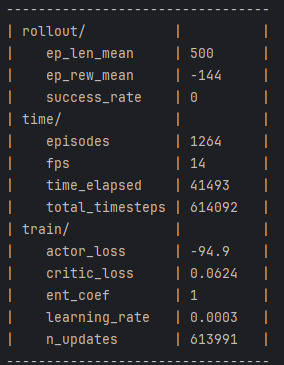
注意到 train/ent_coef 的值经过学习后变得很小(初始值为1),仅为0.02,从视频也能看到模型训练达到了预期的效果
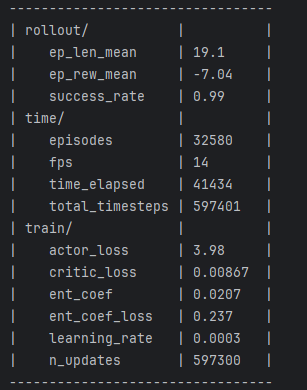
随后我在我自己的SAC代码中也加入该可学习参数,发现确实也work了,该参数经过一段时间的学习也变得非常小:
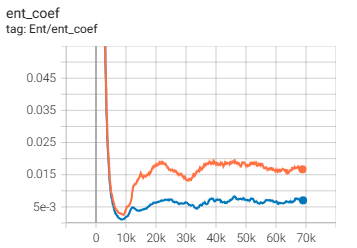
分析
对于SAC来说,貌似有两个理论上很少提到但是实际上又不可或缺的东西
log_ent_coef 最大熵的温度控制
该参数原始代码大概长这样:
# 定义一个可学习参数
log_ent_coef = torch.log(torch.ones(1, device=device)).requires_grad_(True)
ent_coef_optimizer = torch.optim.Adam([log_ent_coef], lr=1e-3)
...
# 将上述参数作为 -log_prob 的系数,即最大熵的系数
ent_coef = torch.exp(log_ent_coef.detach())
target_Q = self.critic_target(next_states, act_next) - ent_coef * log_prob_next.detach().sum(dim=1).reshape([-1, 1])
...
# 参数学习
act, act_log_prob = actor(current_states)
ent_coef_loss = -(log_ent_coef * (act_log_prob - np.prod(env.action_space.shape)).detach()).mean()
ent_coef_loss.backward()
如何理解这个loss函数呢?以下是我由果推因的想法:
将loss单独拿出来看:
ent_coef_loss = -(log_ent_coef * (act_log_prob - np.prod(env.action_space.shape)).detach()).mean() # np.prod(env.action_space.shape)=2
需要先说明的是,act_log_prob 这个变量是当前policy在当前state下得到的动作的log probability,由于模型输出的是一个高斯分布,其均值和方差可能为任意数,所以高斯密度函数输出的值也可能为任意数,故而 log probability 也可能为任意值,有正有负。
GAN已经很不稳定了
今天是十月底了,嗯,十月底了
GAN已经很不稳定了,再加上不确定性策略,只能说是知易行难呀
有几个月没看阮一峰的网络日志了,看看去
你的职业规划是什么?
前天一个二面,没怎么问技术,倒是问了我很多人生规划之类的东西
这种问题面试中很常见,但是我一直没做什么准备,很遗憾,这一次又被问到哑口无言,我决定给自己找一个一直不准备这个问题的借口:
每个人都是不一样的,每个人是性格都是不一样的,每个人的价值观都是不一样的,每个人对世界的认知都是不一样的,每个人对人生道路的规划都是不一样的
我并没有明确的职业目标,这肯定与面试官的期望想违背,但是我没有就是没有,我不想随便编一个
我小的时候倒是有,我想当一名发明家,我小的时候确实有往这方面努力,我半夜偷偷起床去隔壁小土屋里面搞我的发明,我搞了一个曲轴连杆的走路机器人,然后被我妈揪了回去。我做过很多手工玩具,那时候我想我可能真的会成为一名发明家吧。
我们班每个人有自己的职业梦想,但是有多少人实现了呢?
制定一个职业目标就好比参加一场马拉松,大多数人平时并不怎么跑步,或者并没有跑过很远,所以他对长跑的看法是很天真很理想的,跑过10公里就觉得20公里很简单,只不过是两个10公里相加,进而觉得40公里也不难。真正跑的时候才发现自己其实跑不了那么远,于是纷纷有人在半路上停下来。想成为医生的最终成为了护士,想成为科学家的最终成为了程序员。
并不是说目标定得太虚,而是因为世界无时无刻不在发生变化,你永远预测不到未来会发生什么。
就像那个面试官问我有没有职业规划,我说我未来五到十年钻研各种技术,希望自己至少能在一门技术上有所建树。然后他接着问我以后的规划呢?我说我可能成为不了人员管理相关的职业,所以可能会走项目管理相关的方向。然后他就问,那你对项目管理的目标有什么具体规划吗?
我能说什么呢?未来五到十年的东西我们根本无法知道,更远的东西我能做什么规划呢?
如果再有人问我这个问题,我只能这样回答:
我对未来的职业并没有一个明确的规划,但是这并不代表我对自己的认知不足,也不代表我目标不够明确。很多人实现理想的方式是制定一个目标,然后一步一步向这个方向走,而我不同,我是明确一个方向后一步一步向这个方向走,走到哪一步,取得什么成就,这并不是我当前应该关心的,我应该关心的就只是当前这一步走得对不对,好不好。至于其他,水到渠成。
java多线程编程实战指南 笔记
线程简介
进程是程序的运行实例,是动态的,运行一个java程序实际上就是一个java虚拟机进程
进程是程序向操作系统申请资源(内存空间、文件句柄等)的基本单位,线程是cpu调度的最小单位
一个进程可以包含多个线程,这些线程贡献进程申请的资源
Thread的start方法是启动一个线程,但该方法的调用并不一定立即启动线程,得看系统的线程调度器决定。线程是一次性的,即该方法只能调用一次
run方法是线程的具体任务逻辑,它是由JVM自动调用的,该方法执行结束,则线程也就结束了。由于该方法是一个public的方法,当然可以手动调用,不过手动调用时它就是在当前线程下执行的普通方法了
java种,一个线程就是一个对象,但与普通对象不同的是,线程对象需要额外分配操作栈空间内存,并且可能绑定一个内核线程
Thread、Runnable创建线程的区别
// 方式一:通过匿名内部类的方式创建Thread的子类
new Thread(){
@Override
public void run() {
// ...
}
}.start();
// 方式二:通过传入一个Runnable接口的实现类来启动一个Thread
new Thread(new Runnable() {
@Override
public void run() {
// ...
}
}).start();
-
继承Thread对象本质上是基于继承的技术,而通过创建一个Thread对象并在构造器中传入Runnable实现则是基于组合的方式。从解耦的原则上来说,组合优于继承
-
可以只创建一个Runnable的实现并传入多个Thread中,使得它们可以共享Runnable中的变量,但可能引发并发问题
-
Thread对象就是继承了Runnable接口,但需要明确的是,Runnable接口和多线程运行并没有强制的关系,它只是一种可以运行的方法的抽象,很多接口并不需要使用多线程调用Runnable,这种情况下,创建Thread对象会更消耗资源,因为它会自动开辟栈空间并且绑定内核线程
可以将线程设置为守护线程,但是必须在start方法之前设置,否则会抛异常。守护线程和用户线程的区别在于,是否会影响JVM的停止,当用户线程执行结束后,不管是否存在守护线程,都会停止JVM
一个线程可以创建另一个线程,则它们就是父子关系。默认情况下一个线程是否是守护线程,取决于其父线程是否是守护线程,它们会保持一致。
线程状态
-
new:创建而未启动,该状态只会出现一次
-
runnable:包含ready和running两个状态,可能获取到cpu也可能没有,但处于可运行状态
-
blocked:IO阻塞或者等待锁时
-
waiting:一些特定方法触发线程等待,例如:Object.wait()、Thread.join()、LockSupport.park(Object)等
-
timed_waiting:带超时时间的等待
-
terminated:run()正常或异常结束,该状态只会出现一次
线程安全
什么是竞态?
竞态就是指多线程环境下,对某共享变量的操作可能出现不符合预期的情况,例如多线程下的 i++ 操作
线程安全的问题主要体现在3个方面:原子性、可见性、有序性
原子性
原子操作不可分割,意思是从其他线程的角度来看,对某共享变量的操作要么没执行要么执行完成,不存在执行到一半的状态
java中有两种方式实现原子操作,一个是锁,另一个是CAS
注:
-
java中的long和double的操作不具备原子性,即多线程环境下可能读写一半的值。
-
java中的volatile不具备原子性
-
但是两者结合就不一样了,jvm规范中特别指明了,使用volatile修饰的long或double的写操作具有原子性
可见性
一个变量更新后,其他线程可以立即读取到最新的值,即为可见性
JMM用于屏蔽物理机内存模型,因为每个cpu都会有自己的寄存器,但它们也有共同的内存空间,这就和JMM模型一致了。程序中的可见性是多线程衍生出的问题,它与实际用多少个cpu是无关的,这是因为线程的切换会导致寄存器的值出现上下文的切换,从宏观角度来看,其实就是在模拟多cpu
有序性
多处理器的情况下,从一个处理器视角看另一个处理器运行的程序是按照程序预期顺序执行的(这句话容易引发歧义,见下)。有些情况下,处理器并不会按照程序代码的顺序执行,例如发生了指令重排序或内存重排序(见下)。
所谓有序性,就是指避免重排序对多线程环境产生影响
注:对有序性的一个误解是从一个处理器看另一个处理器执行的指令是完全按照程序代码顺序来的,这是错误的,所谓有序性本意并非不允许重排序,而是说另一个处理器执行的代码,就算发生了重排序,对我这个处理器执行的代码结果是按照代码预期顺序的,例如下面的代码:
处理器1
A = 0
B = 1
S = 2
-------------------t1时刻
处理器2
java内部类
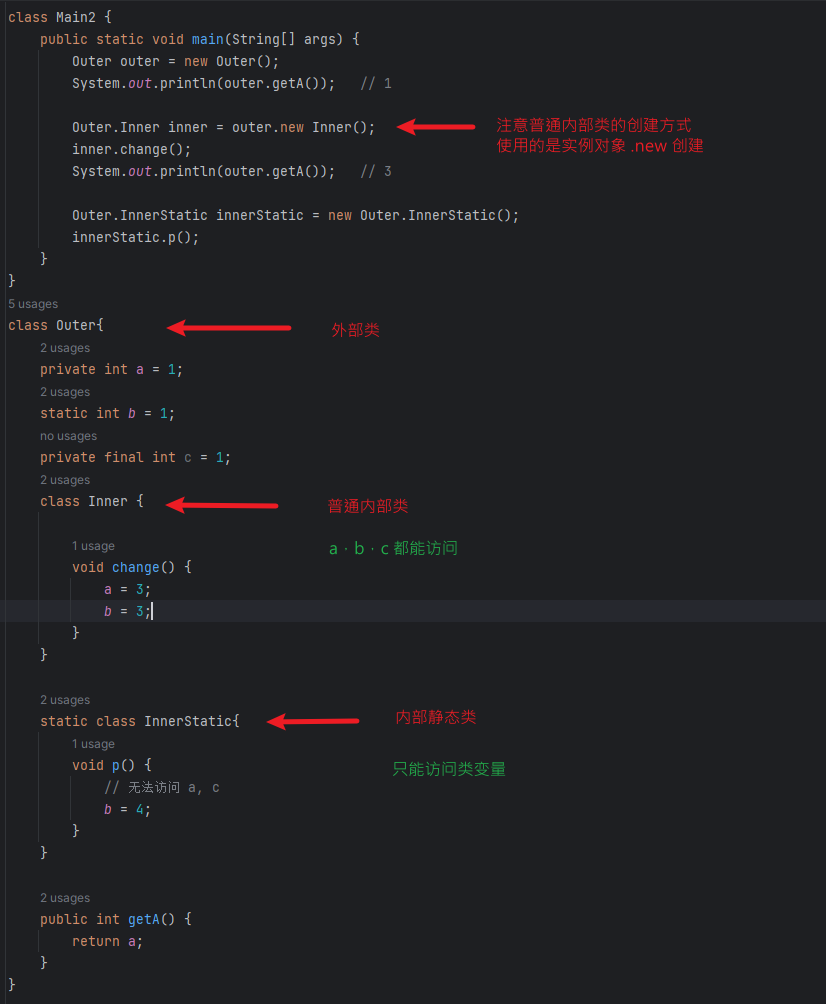
一般内部非静态类
class Outer {
public Integer data = 1;
class Inner{
void print() {
System.out.println(data);
}
}
}
public static void main(String[] args) {
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner(); // 注意内部类 new 的方式
inner.print(); // 1
outer.data = 2;
inner.print(); // 2
}
由此可见,一般内部类与外部类共享变量,并且可以对变量进行修改
方法内部类
class Outer {
public Integer data = 1;
public void fun(){
Integer funDate = 1;
class Inner{
void print() {
System.out.println(data);
System.out.println(funDate);
}
}
new Inner().print();
}
}
public static void main(String[] args) {
Outer outer = new Outer();
outer.fun(); // 输出 1 和 1
}
由此可见,方法内部类也是共享外部变量的,但是,对于方法内部的局部变量是不能做修改操作的,它可以不为final,但至少要保证不会修改它,否则编译就会报错
十月秋招
十一去了深圳,回来就是一场腾讯面试
怎么说呢,面试官就像个死人一样,我自我介绍完了,它就机械地开始问问题。第一个问题是说出tcp三次握手的过程,包括状态转换也说出来,我又惊又喜。惊的是这和我在牛客网上看到的面经一模一样,真是一模一样,他的话和面经中说的几乎一字不差,喜的是我特地将面经上的问题都仔细看过了,所以我就开始说了。随后的问题基本上也都是面经上一模一样的问题,但有些还是面经中没有的。有两三个问题吧,我没说上来,而且是面经中有的问题,比如建立socket连接会调用哪些函数、x86寄存器有哪些类型、DMA工作具体过程,这些面经都有,但是我没看,一是因为我觉得这和我应聘的岗位差太远了,二是我压根不敢相信面经真的就是原题,我想最起码每个人应该都会有差别吧
体验很差,面试官就像一个机器人一样,答完一题他直接问下一题,没有评价、没有过渡、两题直接可能没有任何关联、也没有任何语气或表情。
他问socket连接调用哪些函数的时候我就一再强调我不会C/C++,后面还问些什么函数的问题,还有那个epoll,我已经说过来它的三个函数,他后面还单独问我需要使用哪些函数,我一时没反应过来都懵了,我就说不知道了。
有一道算法题,也和面经上的一样,给你一个字符串表示的数,让你计算它除以另一个数的结果,面经上没说会有小数,但所幸我也找到了类似的代码,虽然那个代码也没实现小数部分,但我面试的时候写出来了,唯一可惜的是我忘记判断一个角标越界的问题,而且当时还没改,面完之后一下子就想到了。但是,面试官出题的时候说他看到我这边提示说腾讯会议版本过低无法写代码,于是让我在网上找一个在线编辑器写,我写好了发给他,众所周知,代码提交是有一定的格式的,比如实现的方法名啥的是固定的,他什么也没说,我写完就发给他,我想,如果他直接将代码复制到提交框中,肯定过不了
头天晚上八点面试的,第二天早上十点我看已经挂了
接着后面还有去哪儿面试,给我的邮件是下午五点多,因为在此之前还有另一个面试,面试结束后我就打开了去哪的面试房间,结果我正在看面经的时候面试就开始呼叫我了,当时才四点多,我想它可能是谁先进房间谁先排队吧。然后是一个女的,我还想难得见到女面试官,结果等我自我介绍完后她说这是测试开发岗位,我一看邮件,还真是,于是就说测开也是可以的,然后她就让我做一道算法题,题目不难,要是平时应该很快就能做出来,但是当时大脑有点懵,一直报错,我后面也懒得调了,然后一道sql题,然后就是问了我一个测试的问题,一个登录页面的测试点,我不知道什么是测试点,就瞎说,然后她说面完了
感觉是不怎么找得到工作了,特别是看到腾讯那么快把我挂了后,我觉得有些恍惚了,突然不知道自己在做什么,要做什么,腾讯那个我感觉不应该啊。
我越来越想去考公了,上班一个月也就那点钱,好迷茫
一些java面试题
对象创建过程?
首先根据字面量去常量区查找是否存在该class类,然后检查该class是否已经被加载过,如果没有则执行加载、链接、初始化的过程。然后去堆内存通过指针碰撞或者空闲列表的方式开辟内存,然后设置对象头信息(类指针、gc年龄、偏向锁等信息),最后执行 () 函数。
bool占几字节?
int占4字节,但boolean本身只占一个字节,但需要内部对齐,所以要补3个字节
为什么64位的机器下引用类型只占4字节?
本来应该是8字节,但jvm默认开启了类指针压缩,因为一个程序一般不会超过4G
Class对象是放在方法区还是堆中?
笼统地说是放在方法区,但实际上,由于jvm底层是使用c++实现的,所以每个class实际上不仅有java版的还有c++版的,c++版的是放在方法区,而java版的是放在堆中的,当创建一个对象时,它会先去堆中找class,如果找不到就去方法区找c++版的,找到的话就会在堆中创建一个java版的
双重校验锁创建单例对象是否要加volatile?
需要,因为创建对象至少由三部分组成,开辟空间赋0值 -> 执行init方法 -> 局部变量表赋值,假如后两步发生了指令重排序,那么多线程情况下可能出现使用未初始化的类,volatile可以防止指令重排序
arraylist VS linkedlist
序列化有一个很大的不同:arraylist由于存在动态扩容,所以它并不会直接将整个数组进行序列化(因为很有了可能有多的元素),而是只根据元素个数进行序列化。而linkedlist的序列化并不会存前后的指针,而是在序列化时按顺序存储,反序列化时再按照该顺序创建链表即可
插入效率也分情况:如果向最后插入数据,在涉及到数组扩容的情况下,arraylist要更慢
遍历的话:如果使用迭代器遍历linkedlist,两者效率差不多
CopyOnWriteArrayList
底层使用ReentrantLock和volatile来保证多线程安全。
copyOnWriteArrayList底层维护一个volatile修饰的数组,读时不加锁,增删改时添加可重入锁。
当修改数据时,会创建一个新的数组,并将原来的数组复制过来,再添加新元素。这个过程中,读取操作是不影响的,它还是会读取到旧值。只有修改完成后,才会将数组引用指向新修改的数组地址完成修改。并且由于有volatile存在,所以修改后立即可见。
分布式锁的实现方式有哪些?
redis的setnx、mysql的主键唯一性(不能重复添加id相同的数据)、zookeeper的临时顺序节点
redis做分布式锁需要注意什么?
加锁后要用 delete key 进行解锁、给锁设置超时时间,释放锁的过程使用lua脚本可以实现原子操作,Redisson的看门狗机制是自动给锁续期,可重入锁可能多次释放锁,故还需要一个重入计数器,集群环境下,需要对集群一半以上的设备加锁成功才算成功获取锁
base理论
不像CAP理论要么追求强一致性,要么追求高可用性。base追求在核心功能一致性的前提下尽可能使得周边功能也达到一致性
例如网络购物,一个东西是否支付成功,实际上有两个服务,第一个是真正支付的服务,第二个是给用户显示的界面。强一直性的情况下,如果支付成功了,则用户页面必须也显示支付成功,但在base理论下,核心功能是支付功能,支付成功了,但我允许页面上显示正在支付或者系统繁忙等信息,即通知页面服务不需要保证一致性
wait/notify VS await/signal VS LockSupport
wait/notify 可以认为与 Lock 的 await/signal 等价,它们的区别在于:
wait/notify 必须在同步代码块中执行,而await/signal必须在 Lock.lock() 代码块中执行
public static void main(String[] args) {
Object lock = new Object();
Thread thread1 = new Thread(() -> {
synchronized (lock) {
// ...
// 阻塞线程
try {
lock.wait(); // wait / notify 必须在 synchronized 代码块中执行,会释放锁
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread thread2 = new Thread(() -> {
synchronized (lock) {
// ...
// 唤醒阻塞线程
lock.notify(); // wait / notify 必须在 synchronized 代码块中执行,会释放锁
}
});
}
public void test() {
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
Thread thread1 = new Thread(() -> {
lock.lock(); // await / notify 必须在 lock() 代码中执行
// ...
// 阻塞线程
try {
condition.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
lock.unlock();
});
Thread thread2 = new Thread(() -> {
lock.lock();
// ...
// 唤醒阻塞线程
condition.notify();
lock.unlock();
});
}
而LockSupport的park() 和 unpark() 方法都是静态方法,直接调用即可,并且它是基于许可证机制(内部保存了一个变量,用0和1表示是否有许可证),允许先unpark() 在 park()
九月校招
投了快一个月的校招简历,投了不知道多少公司,不知道做了多少测评和笔试题。
面试过的只有快手和美团,而且都挂了。
美团挂得我心服口服,快手挂得我心有不甘。
美团中我嘴快了说出了一个我不熟悉的东西。
快手的面试官看起来很年轻,他问的问题也很基础。
但就那么基础的问题,他自己都不会。
是真的不会,并不是我的臆想。
遗憾的是,算法题都没做出来。
其实是做出来了,但是我没有去运行。
目前为止所有面试过程中的算法题都没写出来过。
包括之前的社招。
九月就快结束了
今明两天还有两场面试
希望自己回答问题时慢一点
多想想
别慌
加油
Paxos/Raft协议
分为两个阶段:提出提案,提出提案的值
提议者向其他的接收者提出一个提案,并且给这个提案一个编号
接收者收到提案后,先看看自己是否已经接受过这个提案,如果没有,则返回一个成功的消息,如果是,则对比已经接收过的提案编号,如果新来的提案编号小,则忽视该提案消息,如果大,则将之前接收的提案对应的值返回
提议者收到响应后,如果收到了提案的值,则使用该值,如果都只是成功消息,则提出提案的值
接收者收到提案值后,和上面的接收提案类似,如果没有同意过该提案,则返回同意,如果之前同意过,则判断新的提案编号和之前同意过的谁大,如果本地的大,就不管该提案,如果新的大,则将本地的替换成新的并返回同意
https://www.cnblogs.com/Finley/p/9787702.html
raft协议:http://thesecretlivesofdata.com/raft/#overview
如何修改wordpress默认摘要显示长度
如果文章不写摘要,则默认将全文作为摘要,这会使得首页看起来很乱。
修改摘要显示长度的方法为:进入wordpress的wp-includes目录(主题编辑器看不到的),找到formatting.php,找到 $excerpt_length = (int) _x( '55', 'excerpt_length' ); 大概3993行,其中55就是摘要显示长度,具体来说,应该是显示block的数量,可以将其修改为1、2等较小的数,例如修改为1时,你的文章有3个block,就只会显示第一个block
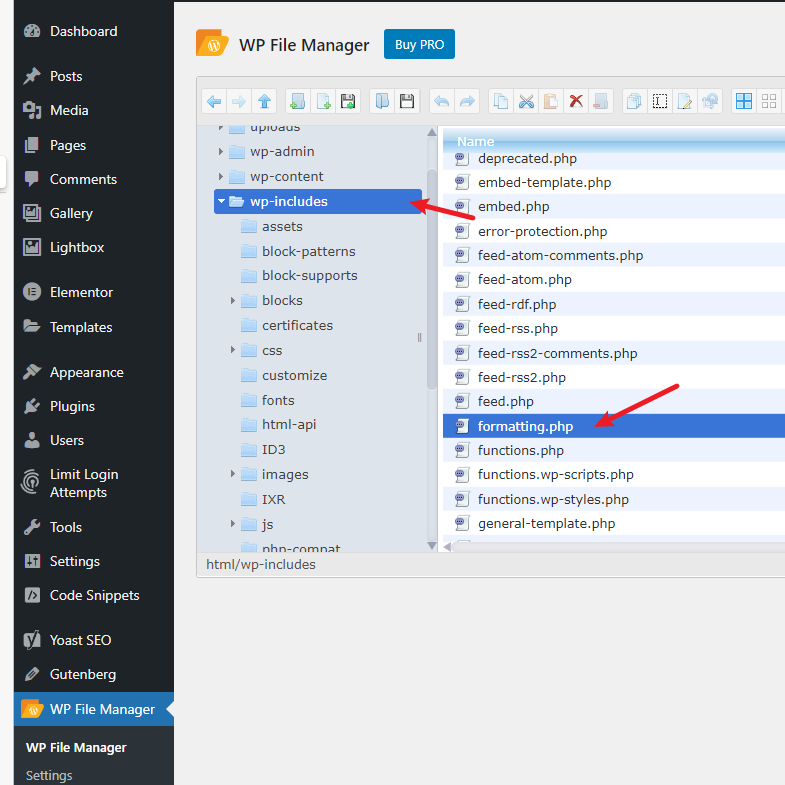
注1:这个只是修改将内容作为摘要后显示的长度,如果本身就指定了摘要,则其长度不受该参数影响
《深入理解java虚拟机》第三版笔记
- 第一款商用虚拟机ClassicVM使用的是基于句柄的对象查找方式。这样做的目的是当对象移动时不需要修改对象引用的位置。缺点是需要两次定位对象。
- GraalVM,是一个再HotSpot的基础上增强而来的跨语言全栈虚拟机,可以运行java、Scala、Kotlin等基于jvm的语言,还有C、C++、Rust等基于LLVM的语言,同时还支持JS、Ruby、Python等。GraalVM可以无额外开销地混用这些语言
- 自JDK10起,HotSpot加入了全新的Graal编译器,顾名思义,它源于GraalVM。它本身就是用java编写的,目的是替换C2编译器
- NIO引入基于Channel与Buffer的IO方式,直接分配堆外内存,避免java堆与Native堆来回复制数据
- 对象分配内存使用指针碰撞或者空闲列表的方式,具体使用哪个取决于垃圾回收器的实现。不管哪种方式都可能出现并发问题,jvm通过CAS和TLAB解决
- new对象过程:检查类有没有被加载,如果没有则先执行 加载链接初始化的过程 -> 堆内存中分配地址并赋0值 -> 设置对象头信息包括GC分代、锁状态等 -> 执行对象构造器方法
- 对象的内容包括 对象头、实例数据、对齐填充
- 对象头信息中包含markword、类型指针(非必须)、数组长度(数组类型才有)
- 实例数据中保存着对象中的各个字段内容,包括从父类继承下来的
- 不停添加栈帧是报栈溢出还是内存溢出异常?
当栈内存固定时报栈溢出(hotspot),如果是动态扩展的(classic),则是内存溢出
- 基于分区的垃圾回收器(G1、CMS等)可能出现待清理的分区中含有别的分区所引用的对象,为了避免整堆扫描,会给每个区分配一个 Remember Set 用于记录哪些对象被其他区引用,它也将加入GCroot中进行扫描。记忆集只是一个抽象接口,它的一个实现是卡表,卡表记录了分区之间是否存在对象依赖关系(只记录两个分区的依赖,并不记录分区内部具体哪个对象的依赖),卡表本质上只是一个标记数组
- 卡表是如何维护的?
如果其他区的对象引用了本区中的对象,则那个区的卡表就应该被修改,形成脏表。问题是如何实现这一过程,HotSpot是使用写屏障(和内存屏障不同)实现的,所谓写屏障,可以理解为是aop的过程,即在对象引用这个动作前后加上一段维护卡表的代码
- 进行GCroot扫描时,由于栈空间也很大,如果直接扫也很浪费时间,所以会将对象的引用专门存储到一个名为 OopMap 的数据结构中,扫描时只扫它就够了
- ParNew是Serial多线程版本,Parallel Scavenge与ParNew差不多,区别在于PS更关注吞吐量(用户线程时间/总时间),而CMS、ParNew等关注缩短单次STW的时间,两者是不一样的,缩短单次的时间意味着收集的次数变多,而每次收集都会有额外开销,所以反而使得吞吐量降低了。
- G1垃圾收集器中,为每一个region都设计了两个名为TAMS的指针,在并发标记过程中,如果有新的对象需要分配内存,就会分配到这两个指针内,这两个指针内区域的对象默认都是存活的,不会被垃圾回收
- 三色标记法如何解决并发标记过程中的动态引用变化?
CMS使用增量更新算法实现:已经标记为黑色(所有的引用它的对象都已经扫描过)对象再引用其他对象时就会被修改为灰色
G1使用原始快照算法实现:有新的引用关系建立时,就记录下这个关系,后续重新扫描这些记录
- Shenandoah是一款只有OpenJDK才有的垃圾收集器,它能实现再任何大小的堆内存中都将STW时间控制在十毫秒内,对比于G1和CMS,它不仅能进行并发标记,还能进行并发内存整理,并且其没有年轻代和老年代的区别,并将G1的每个region维护的记忆集修改为一个“连接矩阵”,便于统一管理维护。其他基本和G1差不多
- Shenandoah如何实现并发整理?
在原本的对象头前面增加一个指向该对象的指针,正常情况下,该指针指向本身这个对象,但在并发整理时,会将该对象复制到其他地方,该指针就会指向新的那个对象地址。缺点是每次对象访问都是两次定位,类似于句柄访问对象的方式。Shenandoah使用CAS的方式保证这一过程的安全
- ZGC的目标和Shenandoah相似,都是要实现不影响吞吐量的情况下,将任意堆的收集时间控制在10ms。它也是基于Region并且不设分代。区别在于ZGC的region可以动态变化,并且ZGC的并发整理要优秀很多(见下)
- ZGC的并发整理的原理?
实际上,GC过程中,很多步骤不需要知道对象的具体内容,而只需要知道对象的状态,例如在三色标记过程中,只需要知道对象之间的依赖关系,而不需要知道对象的内容。传统的做法是将一些与对象本身无关的信息记录在对象头,例如GC分代年龄、锁信息等,但如此一来,就是你只需要对象头中的某些信息,你也必须找到该对象的具体位置(因为对象头也是对象的一部分),这样会造成多余的消耗。而ZGC就是直接将一部分信息存放到对象的指针上,这样只要知道对象的指针就够了,而不用真正去访问对象的内容。这种方法称之为“染色指针”
为什么可以这样做?
因为实际上,在64位系统中,一个指针的范围非常大,而实际上现在的cpu架构也只会用到部分长度(AMD64只支持到52位长度),所以很大一分部都浪费掉了,ZGC就是利用指针的这部分空间存储相关数据
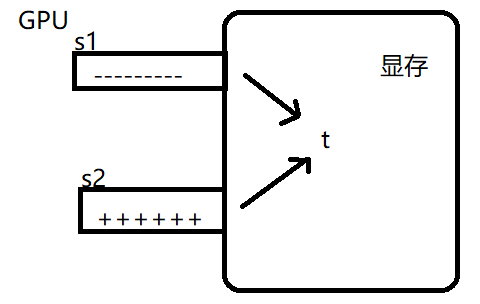
- 向 HashMap<Long, Long> 添加一个kv会额外占多大内存?
long类型占8字节,而包装称Long类型,则需要添加8字节的Markword,8字节的Klass指针,需要24字节,两个Long则需要48字节,然后这两个Long组成一个Map.Entry对象后,又需要16字节的对象头(markword和klass指针),并且Entry需要一个8字节的next字段和一个4字节的hash值(另外需要4字节填充),这一共又是32字节,然后HashMap需要有一个指向该Entry的8字节指针,所以一共占了 48 + 32 + 8 = 88 字节
java中匿名内部类和lambda的区别
对于只有一个抽象方法的接口,可以使用匿名内部类创建引用对象,也能使用lambda表达式来创建对象:
interface I {
void p();
}
// 使用匿名内部类创建对象
I imp = new I() {
@Override
public void p() {
System.out.println("aaaa");
}
};
// 使用lambda表达式创建对象
I imp = () -> System.out.println("bingo");
两者的区别在于:前者是在字节码层面创建了一个接口的实现类然后进行初始化,后者则使用了动态语言的特性:
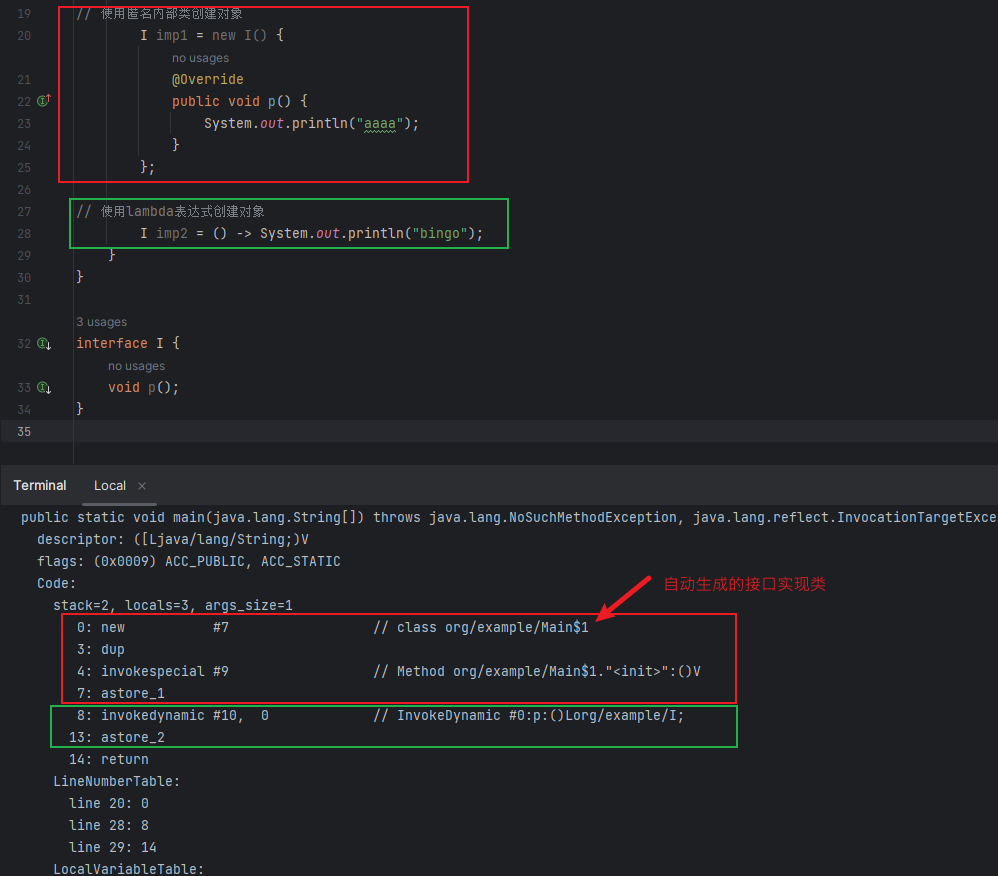
如何解释这个动态语言特性呢?
对于第一种方法,它的引用类型是固定的,即它只能是 I,不能替换成其他接口,而对于第二种,它的引用类型可以修改成任意其他只有一个抽象方法的接口
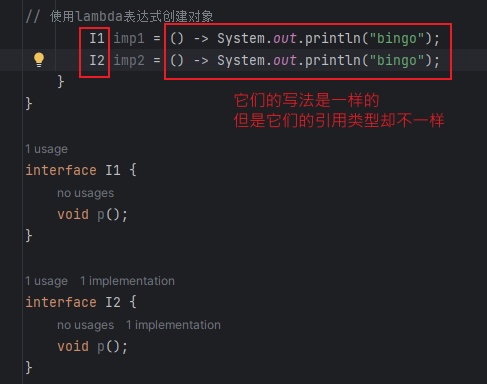
这是不是和java原本的强类型不太一样了,原本的强类型是指静态类型和实际类型一一对应,显然这里并不是这样。
为了使得java也具有动态类型的特性,jdk7引入了invokedynamic字节码指令,事实上,如果仅对于java语言来说,它早就可以通过反射实现动态语言的特性,之所以还要引入该指令,是因为反射是java语言的特性,而jvm不仅仅能运行java代码。
《MySQL是怎样运行的》笔记
https://book-how-mysql-runs.netlify.app/#/
结构
-
MySQL是 C/S 架构,一个服务端负责真正与储存的数据打交道,多个客户端连接服务端用于发送指令(例如SQL)
-
mysql客户端连接服务端:mysql -h localhost -u root -p12345(注:-p后面不能有空格)
服务端处理客户端请求的过程:
-
处理连接:客户端与服务器的连接方式有多种,例如TCP/IP连接、管道或共享内存、Unix域套接字
-
解析与优化:查询缓存(查询系统表时不会走缓存,8.0后不使用缓存,避免太大开销) -> 语法解析 -> 语法优化
-
存储引擎:InnoDB、MyISAM、Memory…,用于封装数据的存储和提取操作
通过上述内容可看出,mysql的架构也可以分为三层:客户端 -> MySQL server(负责管理客户端连接、缓存、语法解析和优化等操作) -> 存储引擎
查看MySQLServer支持的存储引擎:`show engines;`
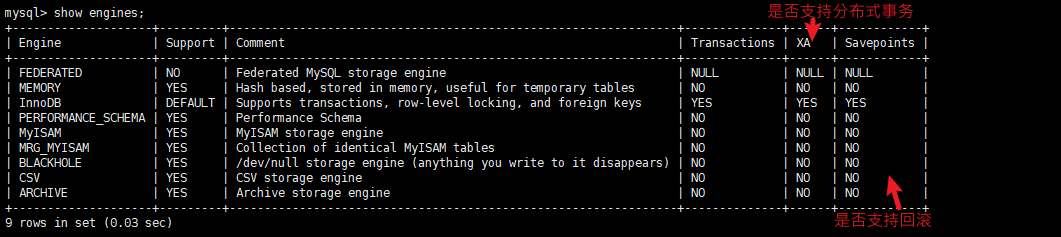
存储引擎是针对表的,可以在表创建时指定,也能在创建后使用alter命令修改。
配置
在启动mysql服务端或客户端时,可以在命令后面跟上一些参数用于控制mysql的默认行为。
例如,启动mysql 服务端可以通过 mysqld -P3307 或 mysqld --port 3307 来指定端口
也可以通过修改配置文件的方式,配置文件的查找路径为:`/etc/my.cnf、/etc/mysql/my.cnf、SYSCONFDIR/my.cnf、$MYSQL_HOME/my.cnf …`
配置文件内容
类似于 .ini 文件的配置
[server]
option1 = value1
(具体启动选项。。。)
[client]
(具体启动选项。。。)
[mysqld]
(具体启动选项。。。)
。。。
不同的启动命令所能读取的配置组是不同的,例如使用mysqld启动服务端就会读取 [ mysqld]、
\[server\]两个组,使用mysql 启动客户端就会读取
\[mysql\]、[client ] 两个配置组
配置优先级
配置文件可以有多个,会一个一个加载,就像springboot一样,如果有多个配置文件都配置了同一个选项,则以最后一个为准
同一个配置文件在不同配置组中出现了相同的配置,则也以最后一个组为准
如果启动命令中有相应的配置参数,则以命令中的为准
环境变量
可以使用以下命令查看:
Golang GMP模型 笔记
https://www.yuque.com/aceld/golang/srxd6d
https://www.bilibili.com/video/BV19r4y1w7Nx/?p=18
本篇文章只是这个视频的一个笔记,但视频其实有非常多让人困惑的地方并没有做解释,本文也没有深究
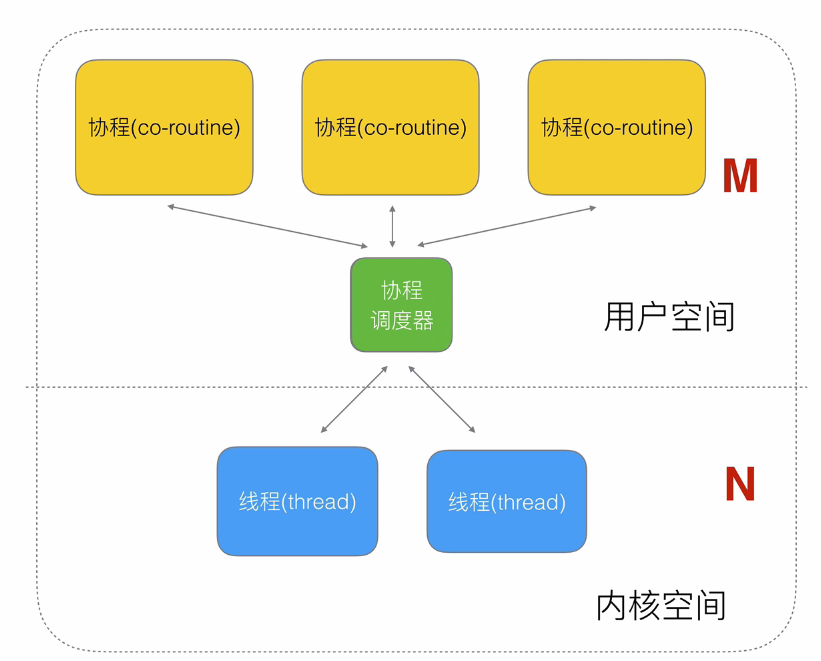
核心在于协程调度器的优化
什么是GMP模型?
-
G(goroutine):协程
-
P(Processor):协程处理器,一次只能处理一个协程,每个P都有一个协程队列,用于存放待处理的协程。P的数量可以通过环境变量或代码进行设置,它的数量表示Golang在某时刻支持的最大并行量
-
M(Thread):内核态线程
另外,还有一个全局G队列,当P队列都满了就会放到全局G队列中。
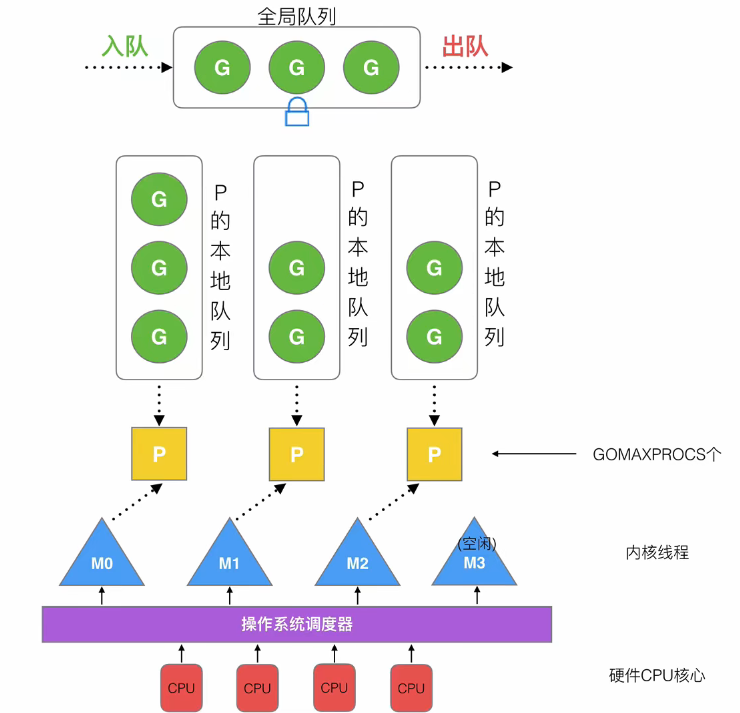
Golang调度器的设计策略
1. 线程复用
work stealing机制:当某个P队列空闲时,它会尝试从其他P队列中拉取G过来执行
hand off机制:正常情况下,一个P和一个M相绑定执行,但是当P正则执行的G发生阻塞时(例如执行read操作),它会唤醒一个新的M并将P绑定到这个新的M上执行,而原来那个M就专门负责执行阻塞的G ,如果G阻塞被唤醒了,就会重新加入到某个P队列中
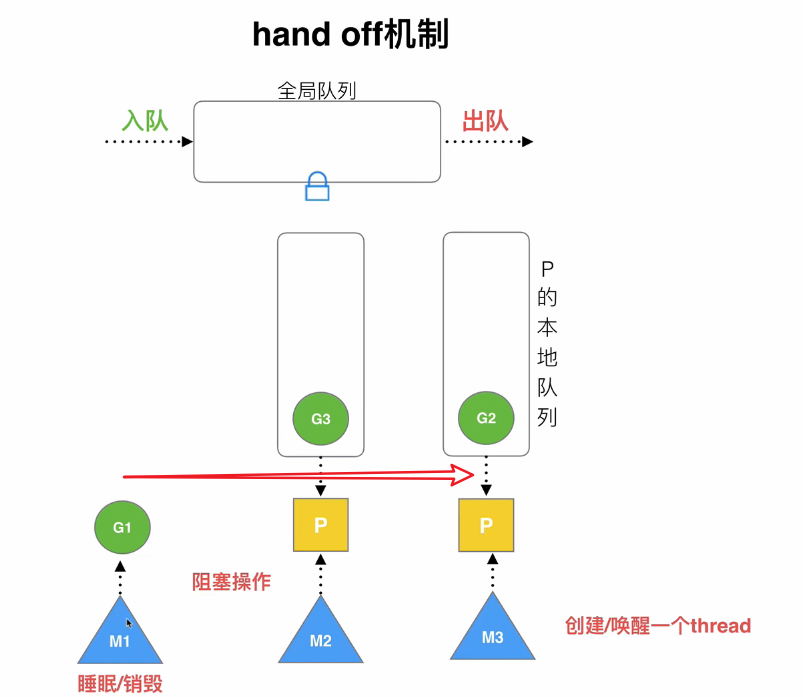
2. 利用并行
可以指定多个P,充分利用多核cpu
3. 抢占
goroutine也会存在类似进程抢占cpu的机制(不是使用的队列吗?怎么也是抢占式的)
4. 全局队列
如果空闲P无法从其他P队列中stealing G,则会尝试从全局队列中stealing一个G,这一过程涉及全局队列的加锁解锁,效率不高
M0 和 G0
go程序启动后,go的进程会创建第一个线程M0,M0 也创建一个G0用于创建Golang的协程环境,例如创建P和队列等。
每个P被创建时都会绑定一个G0用于G队列的调度,G0也会负责该P队列中所有G的调度,它不会放到P队列中,当一个G执行完成后,P会先加载其对于的G0,再由G0去它的P队列中取出G来给P执行
当开始执行main函数时,就会创建一个新的G加入到某个P队列中用于执行main的内容,当碰到go语句时,也会创建G添加到P队列中,如果P队列都是满的则会加入到全局队列中
简单来说,M0就是用来做初始化环境工作的,G0主要负责P队列中G的调度
golang中可以使用 trace 或者 GODEBUG 来查看GMP的调度信息
创建G
创建时有如下几种场景或机制:
局部性:如果某正则执行的G创建了一个新的G,很多情况下,它们可能存在一些共享资源,所以新建的G应该优先放到创建它的G所在的那个P队列
队列满:一个P队列容量是有限的(默认4G内存),如果它执行的某个G创建了非常多的G,根据局部性原则,这些新建的G都应该放到这个P队列中,如果P队列已经满了的情况下又新建了一个G,则Golang会将该P队列的前面一半G连同新建的G一起打乱顺序放到全局队列中,后一半的G就会向前移动,此时P队列就空出后一半的容量,如果再有新建的G就可以向P队列后面放,再满的话重复上述过程
自旋线程:每当一个G在创建另一个G时,它都会尝试唤醒休眠线程中的一个线程,当一个线程被唤醒后,它会绑定一个P,并执行它的G0,不过由于此时它的P队列是空的,所以它没有任务执行,它就会忙循环,称为自旋线程。自旋的同时,它也会尝试从全局队列中拉取G,但它会一次拉取多个(拉取数量 = min(全局队列长度/p数量+1,全局队列长度/2)),并停止自旋。该过程称为全局队列到P本地队列的负载均衡
stealing:当一个P队列执行完了,且全局队列也是空的,它又成为了自旋线程,此时它就会尝试从其他P队列中偷后面一半的G
自旋线程限制:自旋线程+执行线程 <= $GOMAXPROCS,当已经达到最大限制后,新创建的M就会放到休眠线程队列中,因为已经没有P可以和它绑定了
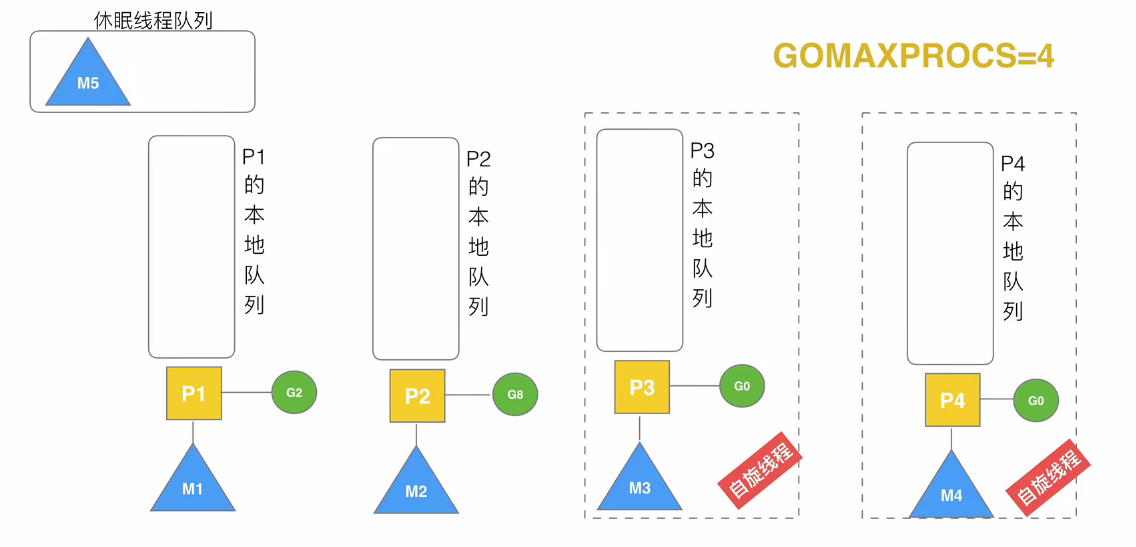
如果G8发生阻塞,P2就会重新去休眠线程队列中唤醒一个队列进行绑定,而M2负责等待G8阻塞结束
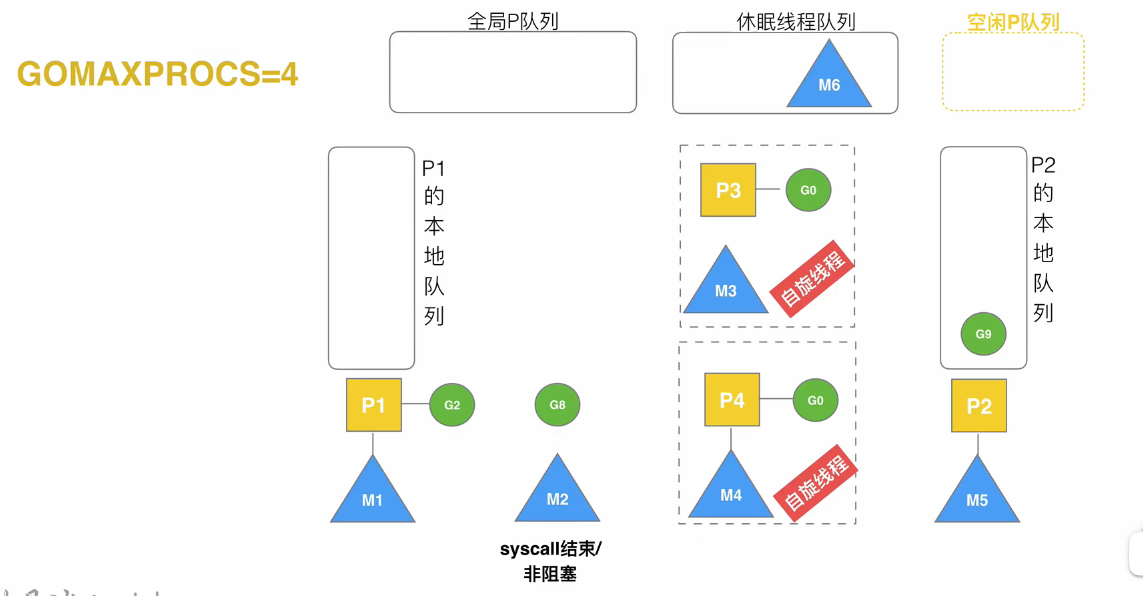
当G8阻塞结束后,它并不能直接在M2上执行,因为G必须在P上才能执行
此时,M2就会尝试 1)绑定原来的P2,但此时P2已经绑定了M5,所以失败。2)从空闲P队列中绑定一个P,但此时空闲P队列是空的,所以G8就会被加到全局队列,M2会进入休眠线程队列
Spring笔记
什么是Spring?
应该从容器和生态方面作答
什么是开闭原则:
给系统做功能扩展时,不应该修改已经写好的代码。即对扩展开放,对修改关闭
为什么要使用容器?
容器的核心功能是用于统一规范,只要符合规范的对象都可以放在容器中统一管理
Autowired和Resource的区别?
两者类似于JDBC和JPA的关系,Autowired是spring提供的注解,默认按照类型注入。Resource是j2ee提供的,默认按照名称注入
Spring中有哪些核心模块?
Spring并不是一个模块,而是一堆模块的集合,例如 Spring Core(核心类库,提供IOC功能),AOP(提供aop功能),MVC(web应用支持)等
Spring AOP的理解
能够提供哪些与业务无关的功能,降低模块的耦合度,有利于代码的扩展和维护。SpringAOP是基于动态代理的,如果要代理的对象实现了某个接口,则会通过JDK的动态代理去创建代理对象,如果没有实现指定接口,则使用CGlib动态代理生成一个被代理对象的子类作为代理对象。当然,SpringAOP也继承了AspectJ
Spring AOP 和 AspectJ AOP 的区别?
AOP是一种思想,这两者就是它的实现。SpringAOP基于动态代理,属于运行时增强,而AspectAOP基于字节码操作,属于编译时增强。
对Spring IOC的理解
对象生命周期管理权的转移,用于解耦,它是整个Spring的基础核心
Bean的创建过程?
Bean的创建过程大致为:根据配置文件或注解生成BeanDefinition —> 执行 BeanFactory 的后置处理器(钩子,对BeanDefinition做修改或增强) —> 实例化对象 —> 填充属性(populate方法) —> 设置Aware接口 —>执行 Bean 创建的前置处理器 —> 执行 init-method 方法 —> 执行 Bean 创建的后置处理器 —> 创建完成
设置 Aware 接口有什么用?
Bean在创建时,有时可能需要知道一些关于容器的信息,例如可能需要知道BeanName,或者容器中其他的Bean,总之就是需要知道和容器相关的信息,但是Bean中并没有这些信息(这个Bean就是你需要交给Spring管理的类,你的类肯定没有容器相关的信息),此时就可以让该Bean实现某个 Aware 接口,例如实现 BeanNameAware 接口,该接口有一个 setBeanName(String name) 的方法,当Spring创建该Bean时,就会自动调用该接口并传入BeanName。这些Aware接口在业务开发中基本用不到,但如果要写一些BeanFactoryPostProcessor 或者 BeanPostProcessor 则很有可能需要实现Aware接口,因为这些PostProcessor其实也是Bean,也需要放到BeanFactory中才能生效。
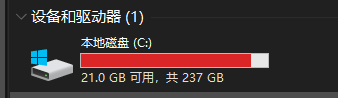
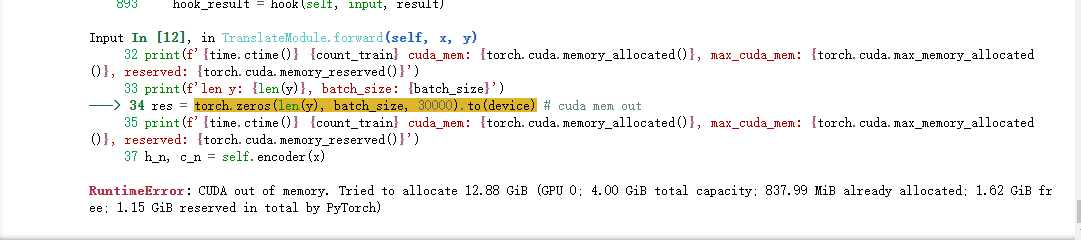
pytorch 安装
报错:
OSError: [WinError 126] The specified module could not be found. Error loading "xxx\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.安装 VC_redist.X64 没用(即Microsoft Visual C++ Redistributable,这是visual c++的一个运行环境,类比java的jre)
安装 Visual Studio 就可以了,https://visualstudio.microsoft.com/zh-hans/vs/features/cplusplus/
后面可能还会报没有 numpy,安装numpy后又报 _ARRAY_API not found 错误,检查一下是不是安装的 numpy 2.x,卸载重装
python -m pip uninstall numpy # 安装 1.24.0 也会报错 python -m pip install numpy==1.26.4JUC笔记
管程:锁对象
守护线程:为其他线程服务的后台线程
JMM
该部分为 《深入理解java虚拟机》第二版 中关于java内存模型的描述
为了屏蔽各个平台的内存差异,jvm创建了java内存模型。其主要目标是定义程序中各个变量(线程共享变量)向内存读写的规则
JMM规定所有的变量都存储在主内存中,每个线程都有自己的工作内存,线程所使用的变量都是主内存到工作内存的拷贝。但它们和堆栈内存是两个概念。
主内存和工作内存间的交互通过8个java原语实现,例如如果要将变量从主内存拷贝到工作内存,则需要顺序执行 read、load 两个原语,反之,则顺序执行 store、write。
volatile
可见性
禁止指令重排序
线程读取被volatile修饰的变量会强制从主内存刷新工作线程的值,修改也将立即向主内存同步,故而保证其对所有线程的可见性
但需要注意的是可见性并不一定线程安全,因为对变量的操作并非原子操作
除了volatile外,synchronized 和 final 也能保证可见性,同步代码块的可见性是因为:变量在执行unlock之前,必须同步回主内存中。所谓可见性,实际上指的是修改后的可见性,final修饰的变量在分配内存阶段就已经赋值了,且都不允许被修改,天然保证了可见性
所谓指令重排序,当两行代码的执行没有依赖关系时,可能在执行时顺序被交换,例如:
doInitialize() intialized = true实际执行时,cpu并不知道两者存在逻辑关系,所以可能将 intialized=true 提前执行,如果其他线程要根据该变量做一些判断,则可能出现问题
其实现方法是,创建一个内存屏障,内存屏障之后的代码不会被重排序到之前执行
synchronized也能解决指令重排序带来的问题,但它并不是防止指令重排序。指令重排序带来的问题本质上是多线程下才会出现的问题,而synchronized能保证在加锁状态下,变量只能被一个线程访问
happend-before
先行发生原则描述的是,在几种特定的场景下,代码会有明确的先后执行顺序。例如:线程的start()方法一定会比该线程的其他方法先发生,在同一个线程中对某变量的操作,书写在前面的代码总是比后面的代码先发生。这些原则有什么用呢?
它们就好比是数学中的一些基本假设或基本条件,由这些基本条件可以推导出很多复杂的结论。
多线程环境下,可以由这些原则判断程序代码是否安全。
实现线程安全的方法
互斥同步
同步指多线程在访问某资源时同一时刻只能有一个线程来访问,互斥是实现同步的一种手段
synchronized是实现同步的一种手段,同时它也是一种可重入锁,即如果是当前线程已经获取了锁对象,则它下次仍然可以进入被锁的代码块中。与之类似的还有juc中的ReentrantLock,它们都是可重入锁,只是使用的语法上有所区别,ReentrantLock使用lock()和unlock()两个api实现加锁和释放锁,而synchronized使用字节码指令monitorenter和monitorexit来加锁和释放锁。另一个区别为,RenntrantLock实现了更多高级的功能,例如:
等待可中断:可以为线程设置等待超时时间
公平锁:多个线程按照先来后到顺序获得锁
Condition:Object的wait和notify的另一种实现,可以实现对其他线程的独立控制
jvm在后续改进中,synchronized的性能和ReentrantLock的性能也差不多
非阻塞同步
互斥同步本质上是悲观锁,代码进入同步区域会首先加锁,而非阻塞同步则是乐观锁,即先进行操作,如果没有其他线程争用共享数据,则操作成功,如果产生了冲突,则采取其他的补救措施
乐观锁减少的是在冲突较少的场景下,加锁解锁的开销,而在冲突较多的场景下,乐观锁比悲观锁性能更差
CAS是乐观锁的一种实现,它有三个属性:目标值地址,旧的目标值,新的目标值。只有当旧的目标值和地址中的值相等时,才会将地址中的值修改为新的目标值。但可能出现ABA问题,JUC中使用变量版本号来解决该问题。不过一般来说,这种问题并不会对程序造成影响。
无同步
如果没有共享数据,那就不用考虑同步问题。例如纯函数,或者栈上分配技术,或者ThreadLocal数据等
锁优化
自旋锁
使用忙循环来代替线程阻塞唤醒的内核态开销
但自旋只适用于短时间的共享资源占用,jdk6引入自适应自旋,当上次自旋成功获得锁后,则认为这次也可能成功获得锁而自旋,因此运行自旋更长时间,但如果很少有自旋成功的,则自动省略自旋进入阻塞
锁消除
如果经过逃逸分析发现共享变量不会被其他线程共享操作,则将锁消除
锁粗化
如果一段代码内频繁地加锁解锁,则可能优化为对整段代码一次性加锁
轻量级锁
对象内存布局为:对象头+数据部分+对齐填充
而对象头又分为:markword + 指向方法区Class的指针(数组的话还需要加上数组的长度)
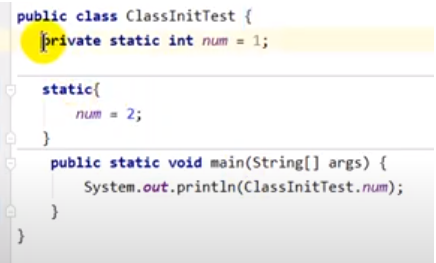
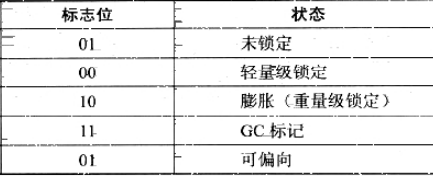
markword在32位机下长度为32位(64位机下为64位),其中25位存储对象hash值,4位存储GC年龄,2位存储锁标志位,1位表示偏向锁是否可用。其中前25+4+1=30位内容会随着锁标志位的变化而变化,具体为:
锁标志位 前29位存储内容 对象状态 01 对象hash+GC年龄 未锁定 00 指向栈帧中 锁记录 对象的指针 轻量级锁 10 指向Monitor(管程)对象的指针 重量级锁 01 偏向线程ID、偏向时间戳、GC年龄 可偏向 11 null GC标记 轻量级锁加锁过程:
4th和2nd的区别
很多地方可以看到数字后面有一个th、nd等符号,这个东西叫做 序数词,例如:\( 1^{st} \\)、\( 4-th \)、\( 3rd \ ) 等
我之前一直以为第n个表示为 n-th,今天才注意到这个细节,原来不同数字结尾的n表示的方式还不尽相同
表示第以1结尾的数字后缀为 st,其实是first的后缀,例如 \( 1^{st} \\)、\( 21^{st} \)、\( 301-st \) 等,但以11结尾例外,表示为 \( 11^{th} \)、 \( 4611^{th} \ )
表示第以2结尾的数字后缀为 nd,是second的后缀,例如 \( 2^{nd} \\) 等,但以12结尾例外,表示为 \( 12^{th} \)、\( 76512^{th} \ )
表示第以3结尾的数字后缀为 rd,是third的后缀,例如 \( 3^{rd} \\) 等,但以13结尾例外,表示为 \( 13^{th} \)、\( 813^{th} \ )
表示第以4到9结尾的数字后缀为 th,是fourth的后缀,例如 \( 4^{th} \\)、\( 35^{th} \)、\( 47-th \ )等
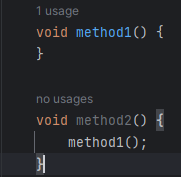
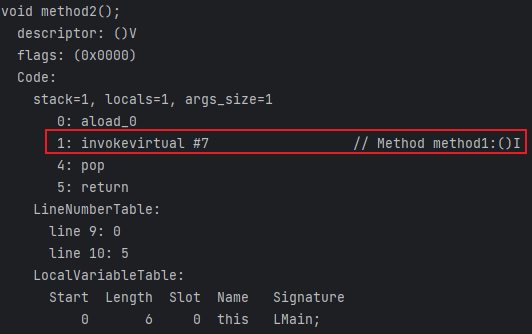
java中的动态链接
以下为我个人的理解:
在java中,有两个地方会提到动态链接,一不小心弄混了就会非常困惑
一个过程
假设我写了两个方法:
method2的字节码指令为:
其中 invokevirtual 表示执行的是一个虚方法,所谓虚方法,就是只有代码在运行期间才知道真正调用的是哪个方法(final 修饰的方法除外),而不是在编译期间就确定的。
后面的 #7 指的是常量池中字符串常量的引用,将引用具体化可以得到 Method method1:()I,后面得到的这一串字符就是符号引用
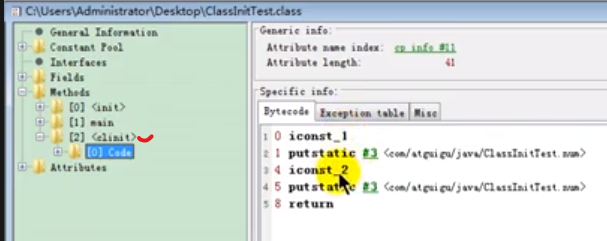
为什么这里执行 method1 是一个虚方法?因为你不确定子类或者父类是否重写了该方法,所以编译期间你根本不知道它调用的到底是哪个方法。只有真正运行后,知道是哪个对象调用的该方法后才能确定应该调用谁的方法
所以在真正调用该方法前,这个被调用的方法仅仅是一个符号引用,每次只有真正调用该方法时,才会将该引用转换为所调用方法的直接引用,这个运行时才确定直接引用的过程,就称之为动态链接。
注意:这里的动态链接是一个过程,或者说是一种思想
一个引用
JVM会在调用每一个方法前,都在方法栈头创建一个栈帧,该栈帧是一种能够支持函数调用所有信息的数据结构,它是一个具体的存在。
而栈帧中会保存一个指向常量池的指针,该指针实际指向常量池中该方法的实际引用。这个指针就是动态链接。
注意:这里的动态链接是一个指针,它是一个有形的实体
方法在调用时不是已经确定了自己的引用吗,为什么还要保存自己的引用?
便于获取栈信息:例如我们在debug或者保存栈快照时,它能告诉我们栈中到底有哪些函数
函数结束执行后可以知道它的返回值是哪个方法返回的
另一种说法是方法在调用时并不会一次性加载所有的方法信息,例如异常表等,只有真正出现异常后才去方法区加载该方法的异常表,那么这个过程肯定得知道该方法到底属于方法区的哪个方法。
引自上文:Often, it is better to take a more abstract and high-level view of things. An Activation Record is a data structure that holds all the information needed to support one call of a function. It contains all the local variables of that function, and a reference (or pointer) to another activation record; that pointer is known as the Dynamic Link. Stack Frames are an implementation of Activation Records. The dynamic link corresponds to the “saved FP” entry; it tells you which activation record to return to when the current function is finished. The frame pointer itself is simply a way of indicating which activation record is currently in use. The dynamic links tie all the activation records for a program together in one long linked list, showing the order they would appear in a stack.
Kafka笔记
https://www.bilibili.com/video/BV1vr4y1677k?p=79&vd_source=78951f3f7dcd752bebcfd9734a584537
什么是kafka
分布式的基于发布/订阅模式的消息队列
常见的消息队列:
KafKa、ActiveMQ、RabbitMQ、RocketMQ
消息队列的应用场景:
缓冲/消峰:使用一个消息队列缓存消息,解决消费者消费速度慢的问题
解耦:不同的数据源不用单独编写特定的发送数据的代码
异步通信:有些任务并不需要实时阻塞处理,可以将这些任务丢进任务队列,然后顺序处理
消息队列的两种形式
点对点模式:消息队列中间件维护一个消息队列,生产者向其他添加数据,消费者从里面拉取数据后删除消息队列中的数据
发布/订阅模式:消息队列中间件内部维护多个不同主题的消息队列,消费者按照主题拉取数据后,不删除队列中的数据,以便于其他消费者也能拉取同样的数据
架构
生产者 Producer
注:同一个topic分为多个partition,它们直接没有主从关系,只有同一个partition与其副本之间有主从关系,所说的leader或follower很多时候指的是它们所在的那个broker
数据发送过程:
主线程获取到数据后,调用send方法(分为同步和异步方式,同步模式下下一批数据必须等待上一批发送成功后才发)发送数据,数据在发送前会先经过拦截器(校验、修改等),然后经过序列化器,得到序列化数据之后,数据被传送到分区器(因为一个topic可能有多个分区),分区器中有一个发送缓冲区,有多少个分区,缓冲区中就有多少个双端队列,数据并不是直接放在双端队列中等待发送,而是将数据放到一个16k大小的内存块(batch.size)中,如果该内存块满了或者超过等待时间(linger.ms)才会将该内存块放入双端队列中等待发送(就好比寄快递,快递车不会一次只运一个快递,而是将多个快递丢到车上,车满了才走)
发送数据的任务由Sender线程做,它使用NIO的方法与每个broker保存连接,kafka集群收到数据后将根据配置做出响应,配置有三个可选值:
0:kafka集群不需要返回响应
1:leader收到数据则响应成功
-1:leader和副本(实际不是所有的副本,而是ISR中的副本,副本可以理解为一个broker)都收到数据则响应成功
Producer收到成功响应后才会将双端队列中的数据删掉,否则会不断重试
分区 Partition
为什么要分区?
每个Partition存放在一个Broker上,如此一来分区就有两个好处:
从空间上看,可以将一个大的数据分开放在多台服务器上
从时间上看,一次就能同时生产或消费多条数据,增加了吞吐量
分区数可以大于broker数,此时一个broker就可能有多个分区,可以自动分配也能手动分配
分区策略
默认分区策略:
如果发送数据时指定了分区,则使用该分区
如果发送数据指定了一个key,则计算该key的hash,并由hash映射到某分区
如果没有指定key,则使用上一次使用的分区,如果上一次使用的分区内存块满了(16kb),则再随机选一个分区发送数据
自定义分区器:
创建一个类实现Partitioner接口,并实现其中的partition方法即可。
生产者如何提高吞吐量
主要是对以下4个参数的调整:
batch.size 和 linger.ms 两个参数的调整
数据压缩参数
缓冲区大小
如何保证发送数据的可靠性
Producer向kafka集群发送数据,可以要求集群是否返回成功结果,以及何时返回成功结果,即上文中的 0,1,-1 三个配置,可靠性最高的为-1,但会出现一些其他的问题:
follower挂了:由于leader要等到所有的follower响应成功之后才会判定成功,如果此时有任意follower下线了,leader就阻塞住了。
所以并不是要等所有的follower都同步成功,kafka会维护一个ISR队列,里面保存了所有的Broker id,并由心跳机制检测所有的broker,如果30s后broker仍没响应,则将其从ISR中剔除(ISR中包含leader和活着的follower所在的broker)。
响应成功时,只有ISR中所有的节点都成功,才会返回保存成功数据重复:如果leader收到数据后向副本同步数据后,leader还没来得及向producer返回成功信号,挂了,此时副本就会晋升为leader,由于producer没有收到成功信号,所以就会重传,但实际上此时由副本晋升的leader以及有数据了,重传后就会发生数据重复的问题
如何保证数据不重复发送
幂等配置
kafka中有个配置 enable.idempotence 用于配置是否开启幂等性,默认开启,如果开启的话,则会:
producer生产的每一条数据都会自动加上一个由 <PID, Partition, SeqNumber> 三个元素组成的tag,当该tag以及存在时,kafka集群就会将该数据丢掉。其中,PID为kafka的重启版本号,每次重启kafka都会重置,partition则为消息的分区号,SeqNumber为一个自增的数,每次生产一个消息都会自增
事务
事务是依赖幂等配置的,用于解决kafka重启后,仍然可能重复接收数据的问题(PID重置了)
大致意思就是在调用send方法后,数据并没有真正持久化到kafka集群,而是还需要调用一个commit方法来提交该事务
如何保证发送数据顺序
默认条件下,只有单分区内数据的拉取是有序的
Netty笔记
https://www.bilibili.com/video/BV1py4y1E7oA
Java NIO
三大组件
Channel
两个进程共享的部分,是一个双向通道
常见的channel:
FileChannel:只能工作在阻塞模式下
DatagramChannel:用于UDP
SocketChannel:用于TCP客户端
ServerSocketChannel:用于TCP服务端
SocketChannel在进行网络通信时,会调用两个阻塞方法:
ServerSocketChannel的accept方法,用于获取新的socket连接,如果没有连接进来则会发生阻塞,它会返回一个SocketChannel对象(认为是一个socket对象,可以将其放入一个list中,后续循环调用其read方法读取数据)
但是,ServerSocketChannel可以手动设置为非阻塞模式,如此一来accept如果没有获取到连接则立即返回nullSocketChannel的read(buffer)方法,从channel中读取数据到buffer中,如果channel中没有数据则会发生阻塞
同上,SocketChannel也可以手动设置为非阻塞模式,如果read没有获取到数据,则返回0(正常返回读取到了多少字节数据)Buffer
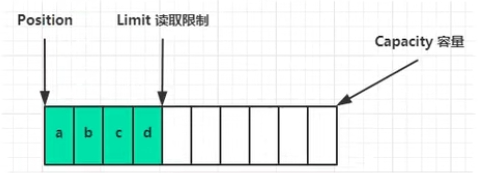
向channel读写的数据可以放在buffer中,常用的是 ByteBuffer
channel就像一个水井,buffer就像是桶,读写数据时就可以通过桶来一桶一桶地读写
ByteBuffer本质是一个byte数组,它有三个属性:
position:当前读写指针位置,默认为0
limit:当前最大读取位置
capacity:buffer容量
buffer有读和写两种模式,两种模式必须手动切换才可使用。切换方法为 buffer.flip()
当buffer为写模式时,limit指针不起作用,数据会从position位置一直写到capacity位置
当切换到读模式时,会将limit指针指向position位置,position指针移动到0位置,读取时,从position位置开始到limit结束,position会跟着移动
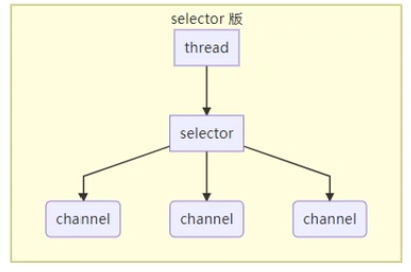
Selector
下图中,每个channel都可以看作是一个网络连接,每个网络连接可能有多个状态,例如发起连接、准备发送数据、关闭连接等,这些动作就需要线程来处理。
selector的作用就是监听这些channel的动作,如果某channel有什么事件就会告知selector,selector就会从线程池中找到一个线程来处理该事件请求,该过程称为多路复用,这种思想称为事件驱动
IO模型
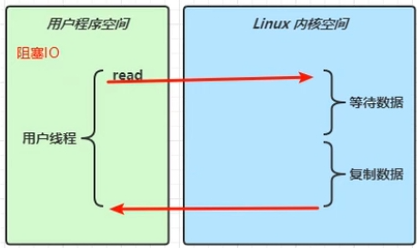
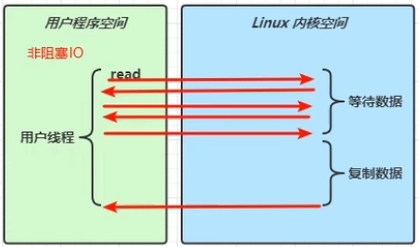
阻塞/非阻塞
用户程序调用read方法发起了一次读取操作(读取磁盘或网卡),会调用内核空间的读取程序(用户态到内核态的切换),而内核态读取数据分为两个阶段:
等待数据:网卡中还没有数据,需要等待客户端传输,一般阻塞耗时主要在这
复制数据:将网卡中的数据复制到内存(socket缓冲区)中,相对来说很快
然后数据再由内核空间复制到用户空间
阻塞和非阻塞的区别在于:
阻塞:用户程序的read方法会一直阻塞知道数据复制回用户空间
非阻塞:在内核态等待数据的阶段,用户程序会不断调用read方法进行查询网卡是否有数据,在复制数据阶段仍然处于阻塞状态
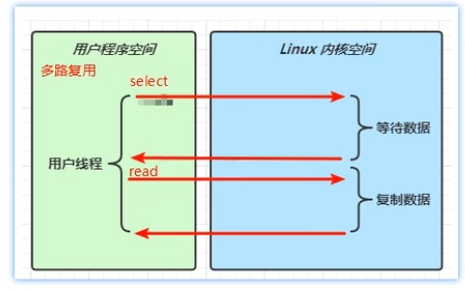
多路复用
用户程序调用selector的select方法,该方法会阻塞在内核态的等待数据过程,一旦有数据发送过来,selector就会告知用户程序,再由用户程序发起read方法读取数据,此时就可以直接复制网卡中的数据了,这一过程也是阻塞的,但是复制数据的耗时一般远远小于等待数据的耗时
异步io
selector接收到读写事件后,如果是直接在当前线程完成读写操作就是同步io,如果是使用其他线程完成读写就是异步io
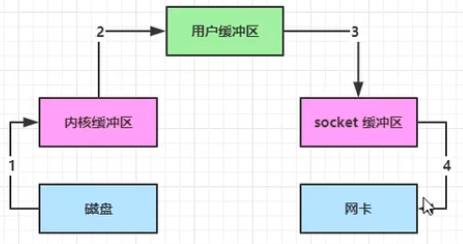
零拷贝
将一个文件内容发生到网络需要执行4次文件复制,读取网络数据同理
java中NIO的channel可以调用transferTo/transferFrom两个方法实现优化,它们在操作系统层面会调用内核的sendFile的方法,该方法可以将内核缓冲区和用户缓冲区统一(或者说不需要用户缓冲区),直接将文件从内核缓冲区复制到socket缓冲区,减少了两次文件的拷贝
到linux2.4版本后,sendFile方法实现了进一步优化,连socket缓冲区都不需要了,直接从内核缓冲区复制到网卡中。
上述这两种方法都是零拷贝,所谓零拷贝,其实说的是在用户态的零拷贝
阻塞/非阻塞 具体实现
以下为阻塞/非阻塞伪代码:
# 单线程实现非阻塞网络io ServerSocketChannel ssc = new ServerSocketChannel(ip, port) ssc.configureBlocking(false) # 配置为阻塞/非阻塞模式 List channels = new ArrayList() while true: SocketChannel sc = ssc.accept() sc.configureBlocking(false) # 这里也可以使用多线程处理,让每一个channel都单独创建一个线程处理 if sc != null: channels.append(sc) for channel in channels: int readCount = channel.read(buffer) if readCount > 0: print('data: ' + buffer.data)上述代码虽然可以使用单线程或多线程实现并发请求处理,但仍存在一个缺陷,如果长时间没有连接请求,而整个代码仍然会不停执行while true循环代码,对cpu来说是一种浪费,一个好的解决方法是如果没有请求或数据写入,则线程阻塞,如果有请求或数据写入则自动唤醒线程,由此可以使用selector
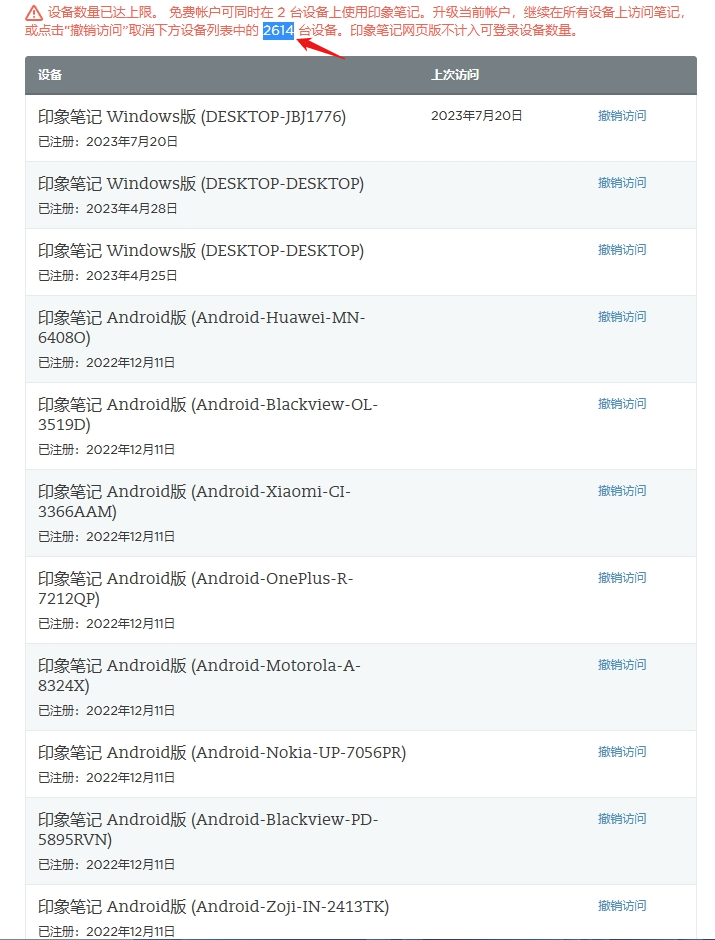
印象笔记莫名奇妙出现很多登录设备
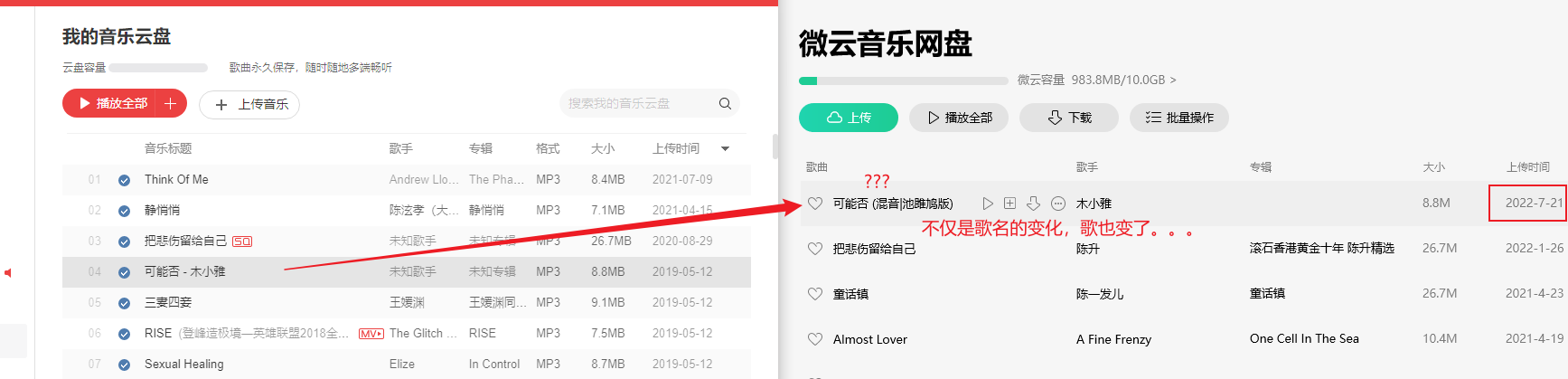
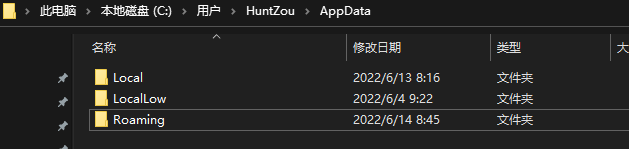
刚才想看看我之前的笔记,发现网页上很多笔记都显示不全,有些图片不显示,有些显示一半,有些甚至显示不出来,于是我就下载它的客户端,希望会好一点,刚登陆账户上去它就提示设备已经超过2台,需要先撤销其他设备授权才能继续,否则就强制退出
目前为止一切都还在预料之中,之前也是这么烂,于是我想撤销就撤销吧,于是就出现了这个:
我满脸问号,我啥时候登录过这么多设备了,而且这两千多台设备都集中在12月10/11号两天,而且每台设备手机型号都不一样。。。
先不说这些设备是哪来的,它竟然没有提供一个一键撤销的按钮,我一开始还没注意到两千多台,我还想着一台一台点一下撤销,但是,我确定我这是印象笔记而不是evernote,点即撤销访问按钮后,连接就一直转圈,靠点击去撤销这些设备是不太可能了,以后再用印象笔记也是不太可能了
我之前用印象笔记写了很多东西,尤其是一些开发相关的技术,之所以用它是因为它当时支持markdown,但是,该说不说,它的markdown文本一旦写的东西多点,整个文档就写不动了,十分地卡
而且经常会丢失一些内容,之前我倒一直以为是我自己没写或者只写了一半,后来发现是真的丢失内容
后来我也想尝试使用其他的笔记软件,稍微好点的就是notion,但它毕竟是国外的,而且也是处于发展初期,后面怎么样就不好说了,而且它仍然是有各种限制
这也是我现在都使用自建的wordpress和memos的原因
MySQL笔记
存储引擎
MySQL的结构:连接层 -> 服务层 -> 引擎层 -> 存储层
各存储引擎的特点:
InnoDB
支持 事务、外键、行级锁
MySQL中,数据库对应文件系统中的一个文件夹,每个InnoDB表都对应该文件夹下的一个 .ibd 表空间文件,该文件用于存储表结构、索引、数据
表空间文件存储的逻辑结构为:
一个表空间下存放多个段
一个段下存放多个区,一个区大小为1M
一个区下存放多个页,一页大小为16K
一个页下存放多个行
一行就表示表中一行数据,需要注意的是,除了本身就有的字段外,还额外有 事务id 和 Roll指针
MyISAM
不支持事务、外键、行级锁,支持表锁
在文件系统中以三个文件表示:.sdi(表结构) .MYD(数据) .MYI(索引)
Memory
数据存放在内存中,支持hash索引
只保存一个 .sdi 文件,用于保存表结构数据
索引
索引能提高查询速度,但会拖慢增删改的速度
索引设计原则总结:
索引结构
B+树索引:三个存储引擎都支持
Hash索引:只有Memory支持,高效率,不支持范围搜索,不支持排序
B树和B+树的区别:B+树所有数据都存放在叶子节点中,并且叶子节点形成一个单向链表。MySQL中,将单向链表修改为双向链表
为什么MySQL使用B+树做索引?
不管是用B树还是红黑树还是B+树,每个节点都需要保存在页中,而一页的大小是固定的(16K),如果在里面存放数据,则一页就存不了多少索引,而B+树只存放索引,故可以存放更多索引,层级更低,且将叶子节点连接可以用于顺序搜索
索引分类
索引类型:
主键索引:只能有一个
唯一索引:可以有多个
常规索引
全文索引
根据存储形式,又分为:
聚集索引:必须有且只有一个,叶子节点存放行数据。默认是主键索引,如果没有主键,则使用第一个唯一索引,否则自动生成一个rowid作为隐藏列当作聚集索引
二级索引:可以有多个,例如对任意列手动创建的一个普通索引。叶子节点存放主键,此时需要回表查询(根据主键再去查聚集索引)
索引操作
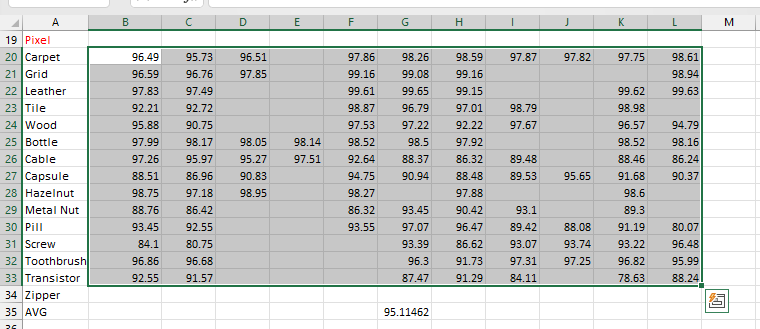
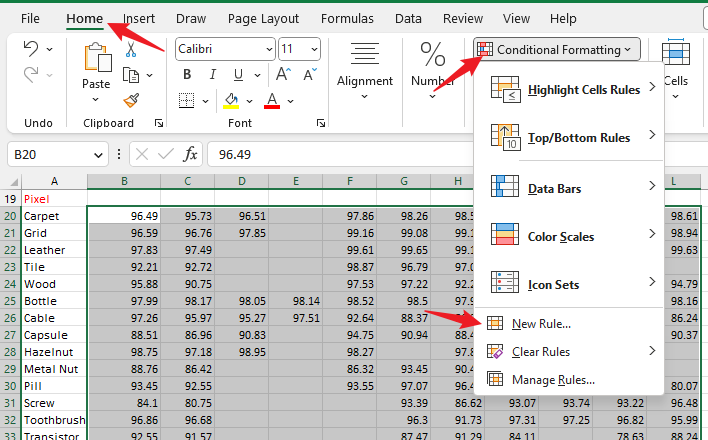
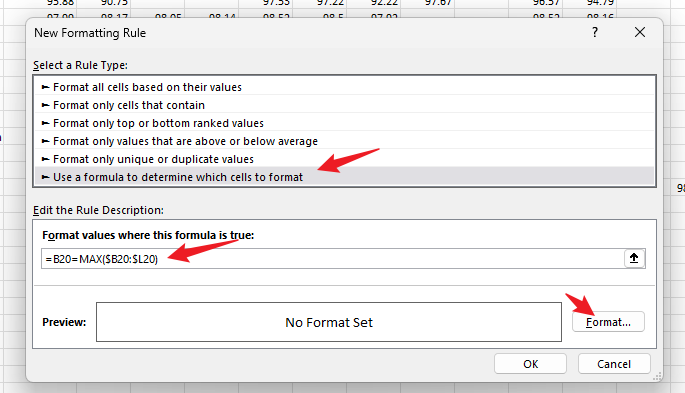
# 创建索引,加上 UNIQUE 表示创建唯一索引,索引可以指定多列,及为联合索引 CREATE [UNIQUE|FULLTEXT] INDEX index_name ON TABLE_NAME (col1, col2...) # 查看索引 SHOW INDEX FROM TABLE_NAME # 删除索引 DROP INDEX FROM TABLE_NAMESQL性能分析方式
慢查询日志
操作系统笔记
并发:一段时间内可以同时执行多个程序
并行:一个时刻时可以同时执行多个程序
操作系统的虚拟化技术:CPU的虚拟(时分复用)和磁盘的虚拟(空分复用)
分时操作系统:允许多用户同时操作系统,微观来看是时间切片(CPU的虚拟)
实时操作系统:分时操作系统没有重要性的概念,实时操作系统会对高优先级的程序实时响应
用户空间与内核空间:
所谓用户态与内核态的切换指的是:cpu执行的是用户空间的程序指令和内核空间的程序指令间的切换,例如我开发出一个程序,这个程序生成的指令都是用户空间的指令,如果程序需要调用文件资源,就会切换到内核空间的文件管理器指令,本质上是切换到了另一个程序,由于这个程序是内核空间的,因此这里需要一次用户态与内核态的切换。
用户态切换到内核态只能通过中断实现
为什么需要中断机制?
提高并发情况下CPU的利用率,例如某程序执行io时,可以中断切换到其他程序
外中断与内中断:外部设备引发的中断为外中断,例如敲击键盘。而内中断是指令执行过程中自己发出的,例如程序需要读取文件时会发送一个中断(陷入指令)切换到内核态的文件管理器程序,或者程序出现异常情况等。
中断处理流程:
保存当前上下文:保存当前执行的寄存器中的内容,并找到中断程序地址
执行中断程序
恢复原始上下文
什么是原语:一小段程序,由多条指令组合在一起,执行过程中不能被中断,就可以理解为一个函数或指令
高内聚低耦合:
高内聚:模块内的代码高度相关
低耦合:模块间的关系独立性好
进程管理
进程是程序一次执行过程的实体,是系统进行资源分配的最小单位
线程(轻量级进程):必须存在于进程中,是操作系统运算调度的最小单位
为什么引入线程?
为了提高OS的并发性
注意:进程中多个线程共享进程资源,线程并不拥有资源,只有资源的使用权,如此一来线程的切换开销比进程小很多
进程是如何运行的
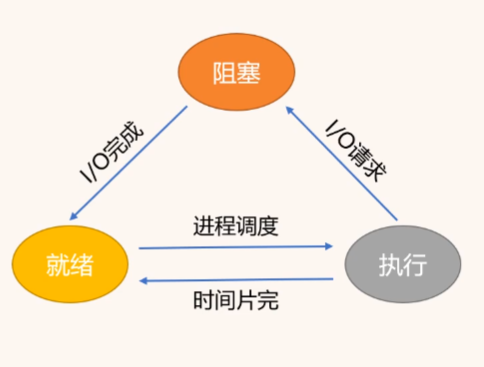
进程状态
三种基本状态:就绪(可以运行,等待CPU执行时间片)、执行、阻塞(等待IO操作、同步操作等完成)
另外还有创建和终止状态,创建完成后就会进入就绪状态,执行完成后或者出现异常退出就会进入终止状态
进程控制
OS通过原语操作实现进程控制(创建、撤销、挂起、阻塞、唤醒、切换),原语是由若干条指令组成的原子操作。可以理解为一个事务函数
例如,要将执行状态的进程转换为阻塞状态,则可以使用block原语,由阻塞转换到就绪使用wakeup原语
为了系统和用户观察分析进程,或者暂时不需要使用某进程,就可以使用suspend原语将进程挂起。例如,edge浏览器中,每次开启一个新的tab都会创建一个进程,假如某个tab长时间没打开,系统就会将该tab的进程挂起
与挂起相对的就是激活
只有创建、就绪、阻塞这三个状态才能被挂起,执行和终止状态不行。
挂起状态和另五种状态的不同在于,挂起状态会将进程所占的内存转移到外存(磁盘)上去,所以它不属于进程运行的状态(进程运行必须在内存)
进程调度
只有进程数远远大于内核数,才会出现进程调度。进程调度的目的是减少cpu空闲时间
调度方式:
抢占式调度:立即暂停当前进程,将cpu分配给其他进程,这种情况一般有 出现优先权更高的进程、时间片到了、有些进程所需时间很短,可能会先让它执行
非抢占式调度:等待当前进程完成或阻塞才执行
调度过程:
保存当前进程的context
切换进程
恢复原进程
调度算法:
先来先服务:就绪队列中,先进来的先分配cpu。有利于CPU繁忙进程,不利于io繁忙进程
短作业优先:先估算各进程所需时间,选择时间短的进程先执行。周转时间短,但估计可能不准确,长时间进程长时间得不到执行
高响应比优先:(等待时间+预估耗时)/预估耗时,值越大优先级越高
优先级调度:可以手动或自动设置调度优先级,低优先级可能长时间得不到执行
*时间片轮转调度:给就绪队列中的每个进程分配一个时间片,时间片到了就执行下一个进程的时间片,由时钟中断确定时间片是不是到了。本质上仍然需要排队。因此时间片设置多长就很重要。
*多级反馈队列调度:结合了上面 1、2、3、5 的优点,解释如下:
多级反馈队列调度:
初始化多个就绪队列,每个队列的优先级从高到低,每个队列中进程分配的时间片长度由短到长。新创建的进程都会放在优先级最高的队列中。cpu每次都从不为空的最高优先队列中pop出队顶进程,执行当前队列对应的时间片后将其放到下一级的就绪队列队尾。
如此一来有几个好处:
所有的进程都会被快速执行一次,不存在长时间得不到执行
也符合先到先服务原则,更公平,响应速度更快
耗时较长的进程优先级会逐渐降低,耗时较短的进程会更优先完成
也满足一定的实时性要求,一般来说,有实时性要求的作业大部分都是短作业,这个算法对短作业的优先级较高
进程协作
进程通信
共享空间:由操作系统提供一块公共的内存区域(提供一个队列数据结构或直接提供一块内存)。由于所有进程都可见,可能不安全
消息传递:每个进程维护一个消息缓冲队列,其他进程给它发消息就能放到这个队列中
管道通信:类似共享空间的方式,给两个进程之间创建一个管道(固定大小的缓冲区),不同点在于这个管道只能单向读写,并且读写过程互斥。若要双向读写则需要创建两个管道。
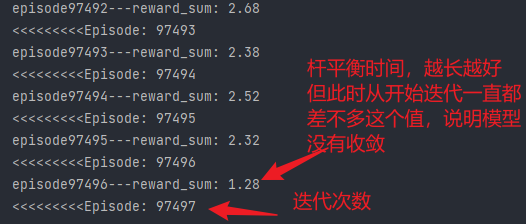
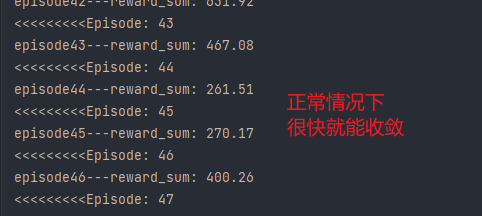
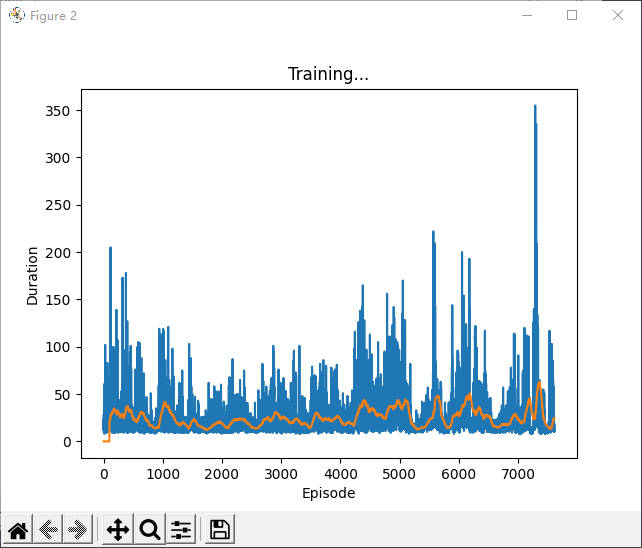
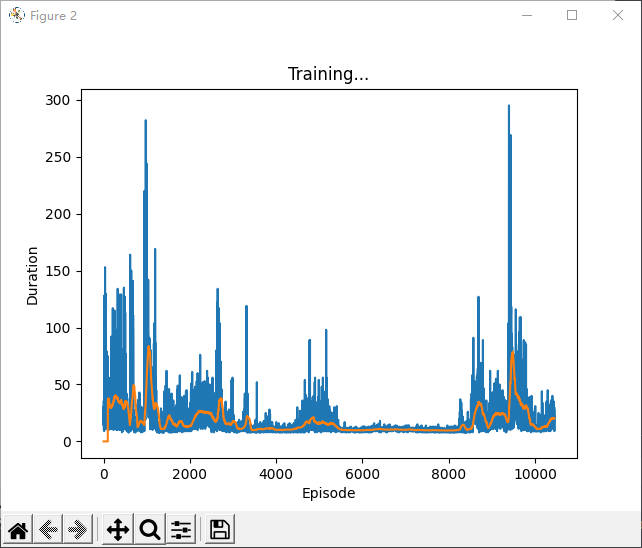
DDPG训练时如何判断有效收敛
注:本文没有给出真正的答案,只是作为一个记录
有效收敛是我自己创造的词,例如在训练过程中,模型收敛到输出与输入无关的状态,或者其他意料外的状态则为无效收敛,反之为有效收敛
DDPG的基本思想是 先训练一个critic,然后使用该critic训练actor,接着再用该actor训练critic。。。不停迭代,和GAN类似
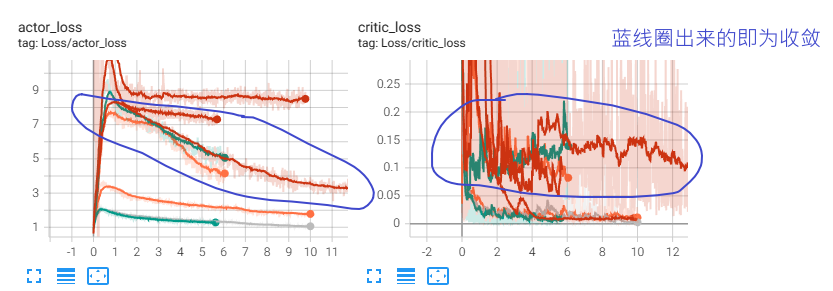
DDPG用到了一些trick,但我在实验中发现,对于某些任务,一些trick是无效的,为了验证哪些无效,我做了一些对比实验,本文目的不是记录这些实验,而是对比有效和无效的情况下,critic loss和actor loss的不同,我觉得这应该也能作为判断是否有效收敛的一个依据。
该实验可以通过critic loss明显看出有效收敛和无效收敛的区别:有效收敛的critic loss一直处于波动状态,并且不会收敛得很快,而出问题的那几个反而很快就收敛到0附近了
我想这应该是有一定道理的,因为critic和actor相互轮流训练,两者互相依赖,所以critic loss不应该收敛很快,因为actor一直在变。收敛很快很有可能出现 输出与输入无关 的情况,例如agent玩lol时,无论开始选择什么英雄,agent都会选择直接送塔,以避免被杀带来的损失。
计算机网络笔记
https://www.bilibili.com/video/BV19E411D78Q?p=75&vd_source=78951f3f7dcd752bebcfd9734a584537
计算机网络的分类:
按分布范围:广域网 WAN、城域网 MAN、局域网 LAN、个人区域网 PAN
按交换技术:电路交换(就像电话线一样,通信时独占线路)、报文交换、分组交换(这俩组合起来就是,通信路径被分割成多个节点的转发,数据也被切分为一个一个的报文,这样就不用独占一条线路且可以同时发送多条数据)
按传输技术分:广播式网络、点对点网络(使用分组存储转发和路由选择机制,两台计算机通信可能经过多个节点,并且数据只有目的主机才能收到)
性能指标
速率、带宽(宽带是网络设备支持的最高速率)、吞吐量(单位时间内通过某网络节点的数据量)
时延:发送时延(发送设备带宽限制)+ 传播时延 + 排队时延(路由器可能处理不过来,数据先放在缓存中等待) + 处理时延(检错、找出口等)
时延带宽积:传播时延 * 带宽 可以用来计算某一时刻,链路中存在的比特数
往返时延RTT:从发送方发送数据开始,到发送方收到接收方的确认信息(立即返回)。传播时延 * 2 + 接收方处理时延
分层结构
主要目的是将网络中出现的大问题分解成各种可能的小问题
法定标准:OSI七层模型
事实标准:TCP/IP四层模型
两者结合可以总结出5层体系
数据在传输过程中,在中间系统(路由器、网桥等)会解码到第3层,源/目的主机会解码所有的7层。
应用层:
和用户交互并能产生网络流量的程序,例如浏览器、邮箱等
典型的应用层服务有 文件传输(FTP)、电子邮件(SMTP)、万维网(HTTP)等
表示层:用于数据解码和加密等,例如 JPEG、MP4等文件格式都算是表示层协议
会话层:。。。
传输层:负责主机两个进程的通信,传输单位是报文段或用户数据报,主要协议:TCP/UDP
》功能:可靠/不可靠传输、差错控制(数据传输出错怎么办)、流量控制、复用分用(使用端口号区分数据报的目的程序)
网络层:将数据从源发送到目标端,IP、IPX、ICMP、ARP等协议
》功能:路由选择、流量控制、差错控制、拥塞控制(流量控制是针对某端口的,而拥塞控制是针对整个网络的宏观控制)
数据链路层:将网络层传下来的数据报组装成帧
》功能:定义帧的开始和结束(一堆01中哪些是开始哪些是结束)、差错控制(帧错、位错等)
物理层
解决如何在连接各种计算机的传输媒体上传输“数据比特流”,功能是确定传输媒体接口有关的特性,例如接口形状、引脚数目、电压范围、传输速率等
单工通信:只有一条信道,且信息只能单向传输
半双工通信:只有一条信道,但通信双方都可以发送和接收信息,同一时刻只能单向流动
全双工通信:两条信道,双向同时通信
什么是码元?高低电平可以表示1和0,高低电平就是两个码元,但我可以直接使用电压表示更多的数,例如0-3v表示01,3-6v表示11,6-9v表示10,9-12v表示00。那么这里一个有四个码元,一个码元就能表示两位数了,一次就能传输更多的数据。
香农定理可以计算出信道在有噪声的情况下数据传输速率的上限。
基带信号和宽带信号:将信号调制为数字信号进行传输就是基带信号,如果是在模拟信道上传输就是宽带信号。近距离一般使用基带传输,远距离使用宽带传输(不是数字信号更适合远距离传输吗?)
编码/解码:数据转换为数字信号
调制/解调:数据转换为模拟信号
报文交换和分组交换:数据在发送途中会经历很多的路由设备,某设备在接收到数据后先将数据存储起来然后排队转发,对报文大小没有限制就是报文交换,有限制就是分组交换(将原来一个大的报文分割成小报文并行发送)。之所以要限制是因为路由设备的容量是有限的
分组交换将源报文切割后还需要进行编号,避免乱序
这两种交换方式典型特征是数据在某路由器的下一跳在哪是不一定的(即使是同一台目的主机,因为有些路由器可能突然比较忙,就需要绕道),与之对应的就是电路交换,它会先确定一条完整的线路。
中继器:信号在传输时会出现损耗,中继器就是对信号进行强化还原
集线器:也叫多口中继器,将输入信号还原后发给其他所有的端口,跟总线一样,把所有设备连接在一起
一个集线器连接的所有设备构成一个冲突域,即任意时刻只能有一台主机能够发送信息
数据链路层
将数据封装成帧并透明传输
封装成帧:将原本的数据头和尾加上帧边界符
透明传输:要发送的数据内容不会影响传输过程,即数据对数据链路层是透明的(例如假设数据中包含了帧边界符的比特码应该有相应的处理方式)
如何做到透明传输?
字符计数法:以一个数字开头记录一帧的长度,但如果一个长度记录错误后面的全错
字符填充法:以特定字符标记帧起始和开始位置,数据中出现的边界符前加转义字符
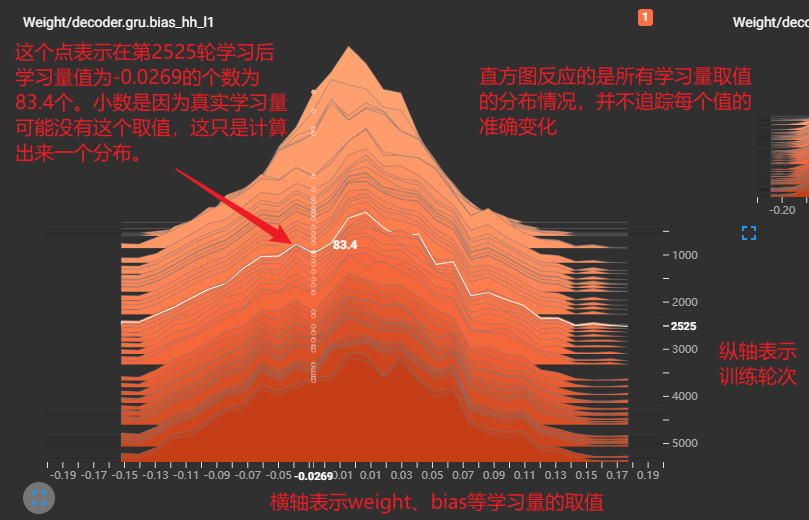
DDPG中各trick效果对比
本实验仅仅是一个简单的实验,用于比较在 “Pendulum-v1”(gym提供的一个小游戏,用于训练RL模型)环境下,使用:
double net:critic和actor都拷贝一个副本,并延迟同步参数,在计算目标q值时使用改副本进行计算
每轮迭代次数:之前都是一局游戏结束就从历史数据中sample一批数据更新一次网络,而这里就是进行多次sample然后更新多次
replay buffer:将之前采样的数据都保持在一个队列中,训练时就从队列中随机采样数据
三者对模型训练性能的影响。注意:这个实验的结果并不能说明太多问题,不同的环境下,它们的作用肯定也不尽相同,我也仅仅是做一个记录而已。
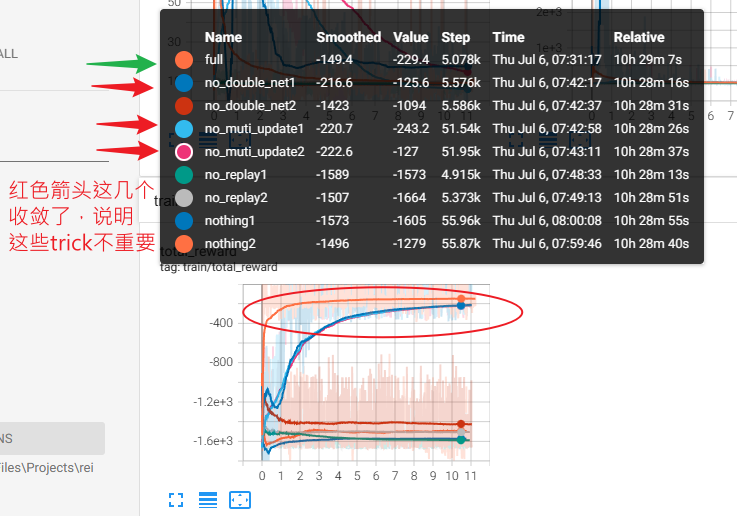
下图为各组实验在运行几个小时之后,在游戏中可以得到的reward
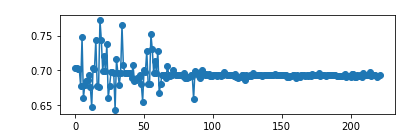
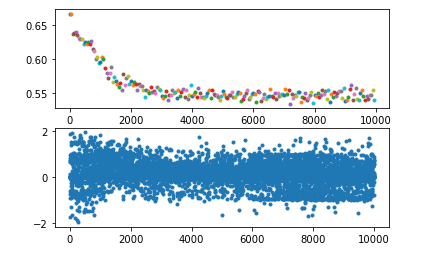
以full(所有trick都用上)作为对比,每个实验都做两组(上图中name后标有1,2),实验表明,在没有 “muti_update”(每一局游戏结束后,都对模型进行n轮训练,数据也都是历史数据中sample) 时,性能不会下降,只是比full收敛更慢,说明它不是很重要,只影响收敛速度,而不用 double net 时,一次可以达到理想水平,一次每练出来,即使是达到理想水平那一次,也可以看到其前面有一个不小的波动,也说明了 double net 可能对模型训练的稳定性起到了一定的作用,而没有 replay buffer 的两个实验和什么都没有的两个实验都gg了,可能说明了replay buffer的重要性。
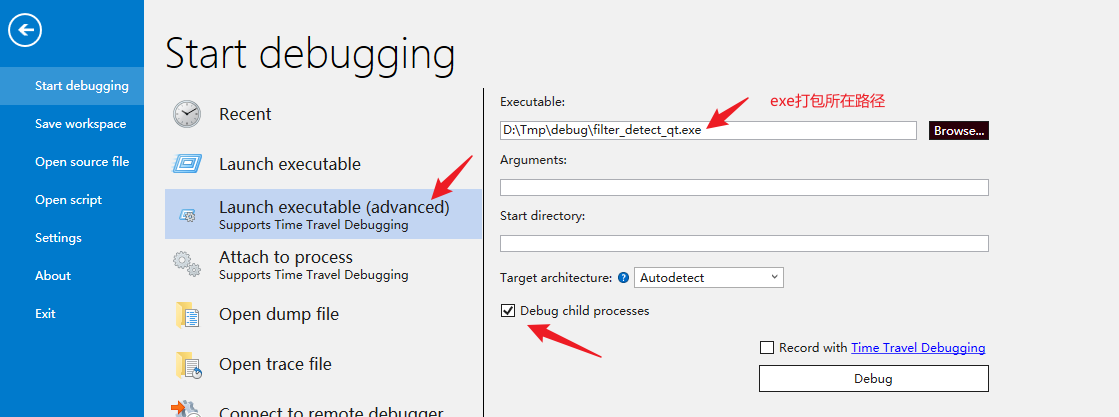
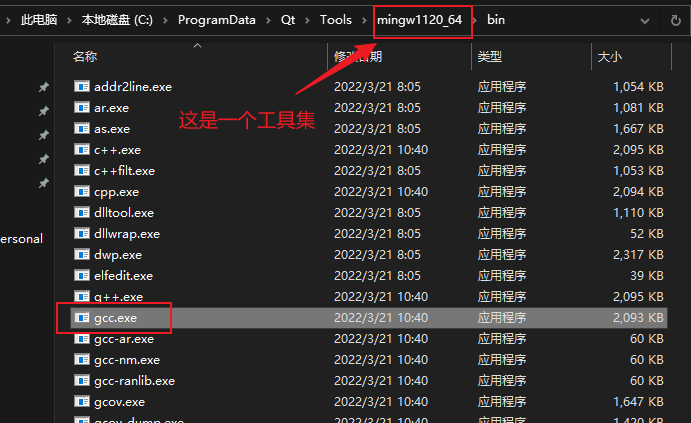
qt在线安装
可以在这个地址下找到安装包的下载地址:
https://download.qt.io/archive/online_installers/4.6/
一步一步安装即可
选择组件时可以加上勾选 qt 中的msvc编译器(还需要额外安装visual studio)或MinGW编译器
到下载这一步比较慢,可能显示需要好几天或几十个小时。
一个解决办法是使用镜像下载,最简单的使用方法为:
# 在上述下载好的安装包目录下执行 qt-unified-windows-x64-4.6.0-online.exe --mirror https://mirrors.ustc.edu.cn/qtproject
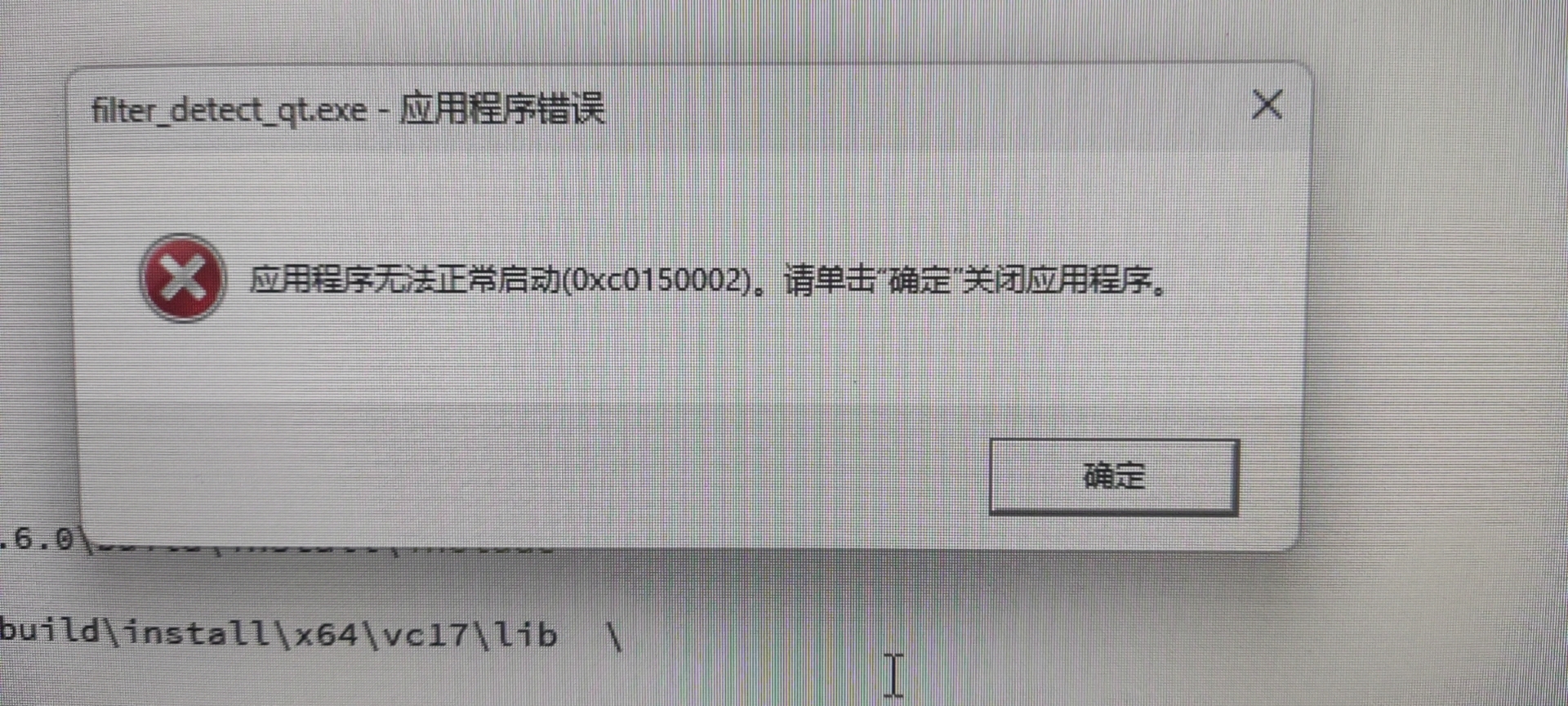
程序无法正常启动(0xc0150002)
解决方法:
到这个地址:https://www.microsoft.com/zh-CN/download/details.aspx?id=26368
下载这个
然后双击安装即可
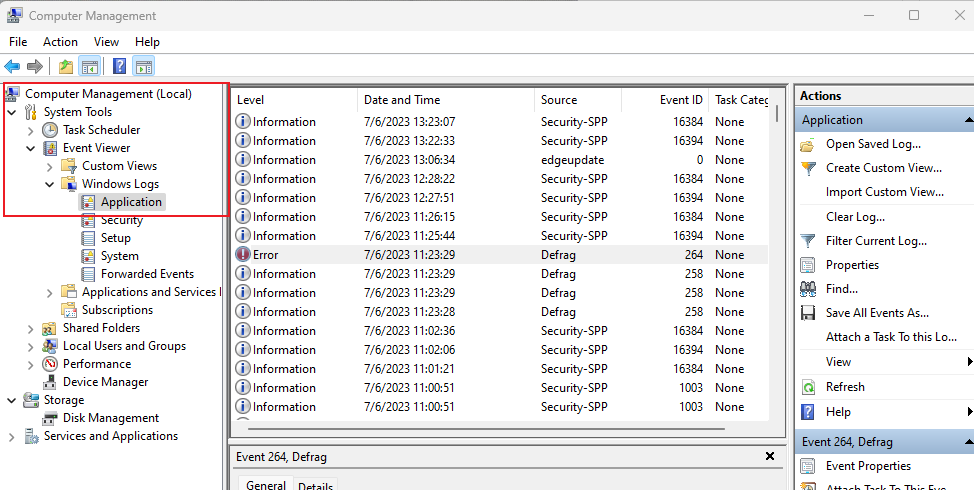
查看出错原因
打开计算机管理,依次打开 系统管理 - 事件查看器 - Windows 日志 - 应用程序,稍等一会就可以在右边的窗口看到级别为“错误”的日志了,如果没有或不确定是哪个,则可以重新运行程序,出错后刷新日志页面第一个就是。双击改日志条目即可看到出错原因。
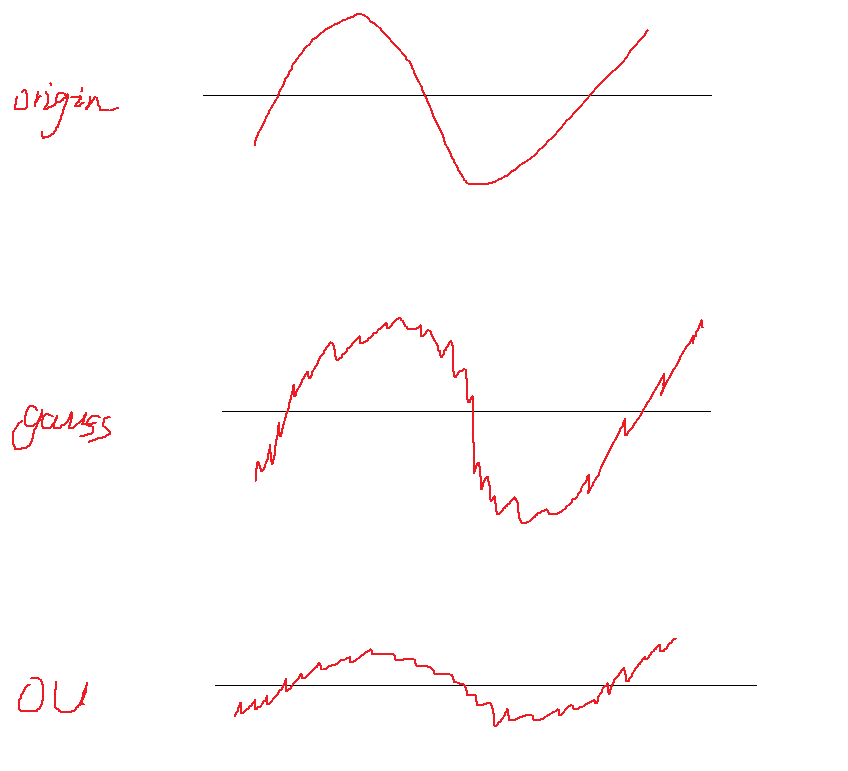
Ornstein Uhlenbeck 噪声
直观理解
在DDPG(一种强化学习方法)采集数据过程中,会在actor输出的action上加上随机噪声以获得更好的探索性。
action是一个连续值,下图中的origin表示一个输出序列(一段时间内模型输出的action值)
最简单的加噪声方式就是直接在输出上加随机噪声,例如高斯噪声(第二行图像)
假如此时actor控制的是一个一辆汽车的方向盘,方向盘转动的角度是有限的,所以此时如果采用随机噪声的方式,则会有很多action被clip到最值,也就是浪费了很多探索的机会。
OU噪声的基本思路就是,先将原始值往其历史均值靠拢一点,然后再加噪声,这样一来,噪声被clip的几率就大大减小,同时,还能通过超参数控制将原始值向均值靠拢多少(上图第三行的图)
数学理解
OU噪声公式为:
事实上理解起来相当简单,将其换一种形式写出来就是:
\[ X_{new} - X_{old} = -\theta (X_{old} - \overline X) + βW\ ]
它分为两部分:\( \\theta (X\_{old} - \\overline X) \\) 表示当前输出X与历史均值的差值,前面加个负号表示如果大于均值就往回拉一点,反之亦然。\( βW \ ) 则表示一个随机噪声(例如高斯噪声)
这里的两个超参数 θ 和 β 分别用来控制 1)往均值方向拉多少。2)添加多大的噪声
Actor-Critic优缺点
译自:https://www.linkedin.com/advice/0/what-advantages-disadvantages-using-actor-critic
优点:
1. 通过将critic net输出的q value作为baseline,可以降低policy gradient算法带来的误差,使得使用较少数据就能够使模型收敛
解释:PG算法性能好坏很大部分取决于采样的数据,假如某游戏绝大部分都是正reward,则PG会无脑增大它采样到的action概率,即使有些action并非好的决策。一个解决办法是使得reward有正有负,且概率为0.5。即将采样得到的reward减去reward的期望,在qlearning中,这个期望就是critic net的输出。
2. 原始的PG必须等到一局游戏结束才能训练,而引入critic net之后,它就可以实时训练而无需等到游戏结束。
解释:原始PG需要计算整局游戏的得分才能训练,所以必须得等到游戏结束,而引入critic net后,因为它的作用就是预测该局游戏可能的得分,所以就不需要等游戏结束了
3. 对于不同的应用场景,可以使用不同的critic net来训练同一个policy。例如使用 状态价值函数 或 动作价值函数作为critic net等
缺点:
1. 可以想象,如果critic net没有收敛,那用它训练出的policy肯定是有问题的,这大大增加了模型的训练成本和风险
2. 使用两个网络使得算法实现更为复杂
policy gradient处理连续动作空间
policy gradient可以直接输出action的概率来进行离散动作的选择,而对于连续动作空间,则需要直接输出动作的值,需要想办法将其转换为概率,方法就是输出一个action的分布(例如输出正态分布,就让模型输出 均值 和 方差 两个值即可),然后从该分布中采样一个action,进而计算该action在该分布中的概率,使用模型提高这个概率即可。
以下为连续动作空间的代码示例:
mean, std = actor(states) action_distribution = torch.distributions.normal.Normal(mean, std) action = action_distribution.sample() # 采样action prob = action_distribution.log_prob(action) # 获取该action在输出分布中的概率,后面就是和离散型的一样了 _, reward, _, _, _env.step(action) loss = reward * prob loss.backward() ...作为对比,以下为离散动作空间的代码:
action_probs = actor(states) action = torch.distributions.Categorical(action_probs).sample() # 采样action _, reward, _, _, _env.step(action) loss = reward * torch.log(action_probs) loss.backward() ...SAC、TD3、DDPG
本文不讲理论上的东西,只说实现上的不同。
事实上,如果单从实现来看,SAC和DDPG的差别不大。从 stable-baselines3 看,区别仅仅在于,SAC在训练critic和actor时,多在reward上加了一个熵值,而这也正是SAC的特性来源。
关于什么是熵,可以参见 https://blog.woyou.cool/posts/100/。简单来说,它就是一个值,与事件发生的概率呈负相关关系。因为在reward上加了这个值,也就是说,action发生的概率越小,这个值越大,额外奖励就越多,也就能达到鼓励模型进行探索。当然不仅仅是鼓励探索,本质上还有很多其他的作用,但这里简单先这样认为就够了。
SAC的训练仍然是同DDPG,在每轮训练中,先优化critic的参数,然后基于优化后的critic来优化actor的参数,区别仅仅是reward多了一项。
TD3是DDPG的改进,就像qlearning中引入dqn一样,使用两个critic网络,但是这两个网络独立更新,每次选择q值的时候就从两个网络中选择较小的那个,防止q值被高估。再者,TD3不会像DDPG那样每次迭代都同时更新critic和actor网络,而是critic每次都更新,但隔一段时间才更新actor。另一点就是引入了噪声增加鲁棒性
一些参考:
openAI关于强化学习的教程:https://spinningup.openai.com
openAI给出的各种强化学习基本实现,第三方优化版本 Stable Baselines3:https://github.com/DLR-RM/stable-baselines3/tree/master
Soft Actor-Critic Demystified,这篇文章给出了早期SAC的迭代公式并配有相应pytorch实现,早期的SAC有 Value network、Q network、Policy network 三个网络需要更新,而现在基本只更新 value 和 policy 两个网络:https://towardsdatascience.com/soft-actor-critic-demystified-b8427df61665,这个是他的代码:https://github.com/vaishak2future/sac/blob/master/sac.ipynb
深度解读Soft Actor-Critic 算法:https://zhuanlan.zhihu.com/p/70360272
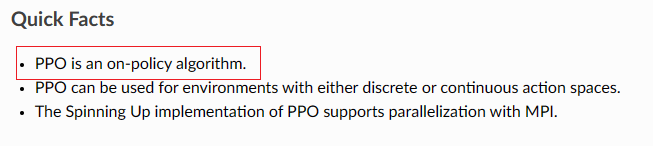
PPO:on policy OR off policy?
之前看李宏毅关于强化学习视频的时候,他说PPO是 off policy 的方法,但是刚看openai spinningup的时候,里面又明确写明它是一种on policy的方法。
如何区分
我个人觉得,一个非常简单的区分方法为:如果与环境交互的策略与目标策略相关,则是on policy的,否则是off policy的。
注意:我这里说的是“相关”,而严格定义来说应该是“相同”,为什么要这么区分,这就和本文题目有关了。
举两个典型的例子进行说明:
Q-learning:典型的off-policy策略。Qlearning在数据收集(与环境交互)过程中,可以采用任意策略,收集到的数据可以长久保存下来用于qtable或qnet的训练。这是因为训练得到的qtable或qnet本身就与模型无关,你可以使用它训练任意actor网络
SARSA:典型的on-policy策略。它和Qlearning唯一的区别在于,qlearning是直接找到\( S\_{t+1}\\)中最大的reward,而SARSA找到当前策略在\(S_{t+1}\ )时的能够获得的reward。显然,一个和目标策略无关,一个有关。
两者Q值的更新公式:
注:2式中,\( a\_{t+1} \\)表示的是当前策略在\( S_{t+1} \ )环境下所选择的action
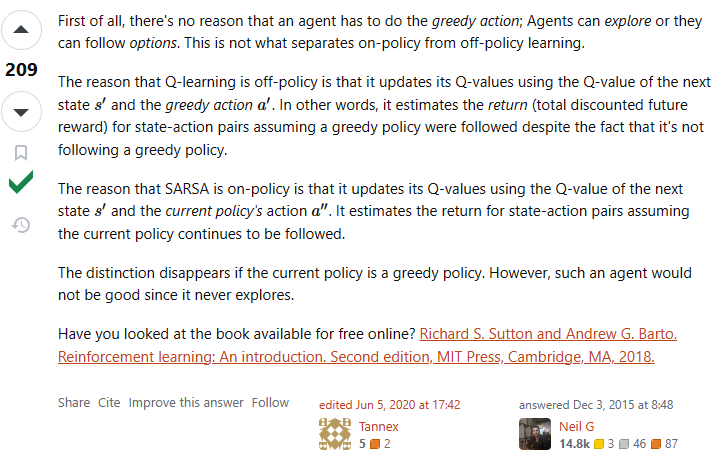
还看到另一种解释,我觉得更精简得说明了这个问题,但思想差不多:
PPO?
从上面说的角度来看,PPO确实应该归属于on policy策略。因为它收集数据所使用的policy与目标策略是相关的,这里的相关体现在收集数据所使用策略的参数必须每过一段时间与目标策略参数进行同步,它们不能相差太大。
但是如果从严格定义上来讲,虽然两个策略必须保持相似,但本质上还是两个策略,从这方面来说,它确实也是off policy的
gymnasium pygame windows 无响应
使用gymnasium的第三方游戏环境Flappybird(https://github.com/markub3327/flappy-bird-gymnasium)训练RL模型,游戏刚运行没多久窗口就会无响应
只是窗口渲染出问题,游戏逻辑实际仍然在运行
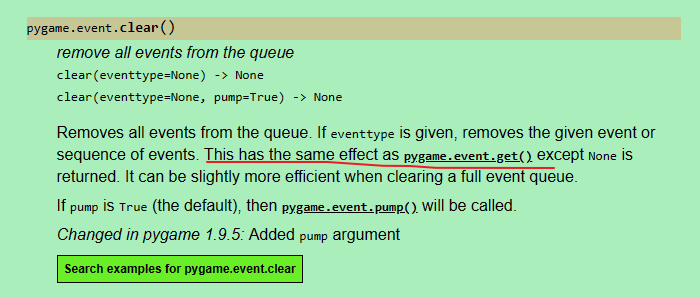
出现这个原因是因为 event queue 一直没取,满了,新的event进不去就会卡住,在游戏中加入以下代码即可:
env = gymnasium.make("FlappyBird-v0") while True: # game loop env.render() ... pygame.event.clear() # 加这个代码清空event queue,或者 pygame.event.get() ...
参见:https://www.pygame.org/docs/ref/event.html#pygame.event.clear
两个数组保持顺序合并能产生多少种排列组合
做这道题用到的:https://leetcode.com/problems/number-of-ways-to-reorder-array-to-get-same-bst/description/
求两个数组归并后可能产生多少种组合,要求归并后两个数组元素仍有保持原数组中的顺序
其实是个很简单的问题,是我开始想复杂了
假设两个数组长度分别为m和n,则归并后长度为m+n,则问题可以转换为从m+n个索引里面挑选出m个(或n个)索引有多少种方式
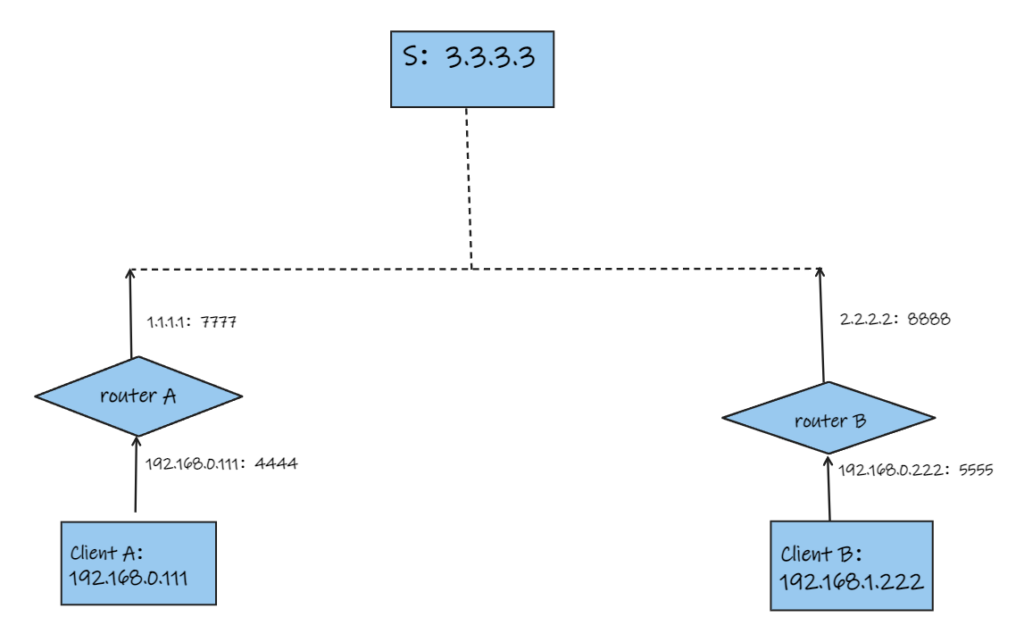
其实就是 ( C_{m+n}^m = C_{m+n}^n = \frac {(m+n)!}{m!×n!} \ )
组合(Combination)公式为
\[ C_n^k = \frac {n!}{k!×(n-k)!} \ ]
在python中可以用
math.comb(n, k)进行计算排列(Arrangement,从n个元素中选出k个元素并排序)公式为
\[ A_n^k = \frac {k!}{(n-k)!} \ ]
python中使用
math.perm(n, k)进行计算Adam优化器
优化器的进化
训练一个policy gradient模型时,发现如果使用SGD,模型练不起来,很容易就出问题,而使用Adam则会好很多,这里回顾一下Adam的原理:
梯度下降法的梯度迭代公式为:
\[ θ_t ← θ_{t-1} - μg_t \ ]
其中 ( g_t \ ) 为t时刻函数对θ的偏导,μ为学习率。
如此一来,在模型训练时就需要指定μ这个超参数,且模型中所有的参数将以一个恒定不变且相等的学习率进行更新。这样其实有两个缺点:
模型在训练初期梯度一般较大,而在末期一般较小,那么学习率设置得过小就会收敛很慢,而设置过大则可能在局部最优点左右横跳
不同的特征对模型的重要性不同,例如对于稀疏特征矩阵来说,那些趋近于0的位置表示与特征相关性较低,那么它们的梯度一般来说也较低,假如使用同样的学习率来更新这个参数的话,可能更新得很慢,比较浪费计算资源。
为了解决上述问题一,可以使用程序自动设置学习率,为了解决问题二,可以给每个参数单独设置一个学习率。两者结合可以得到新的迭代公式:
\[ θ_t ← θ_{t-1} - \frac {μ}{η(g_w)}g_t \ ]
发现学习率下多除了一个 ( η(g_w) \ ),它是学习参数w的函数,如此一来,每个参数都有单独的学习率了(仍然需要指定一个基础学习率μ,但它不用那么小心的选值了)
进一步地,Adagrad算法使用参数w的历史梯度来确定这个( η(g_w) \ ):
\[ θ_t ← θ_{t-1} - \frac {μ}{\sqrt {\sum_{k=0}^t {G_w}_k+ε}}g_t \ ]
其中,( \sum_{k=0}^t {G_w}_k \ ) 是t时刻之前,w参数的所有梯度平方和,_ε_是一个很小的数防止除0
如此一来,如果一个参数w的历史梯度越大,它的学习率就越小(这是符合直觉的,历史梯度越大,则说明这个参数代表的特征越重要,对于这种重要的特征,更新起来应该慎重,步步为营。而那些历史梯度小的参数,则应该避免无用地更新,最好能用大的学习率直接一步到位)
但这还是会出现之前所说的问题,一个参数的梯度是在动态变化的,可能开始很大,后面就很小了,那么如果一股脑使用所有的历史梯度来评估下一次的学习率,还是有些不太合适,如果仅用当前时刻t的前k步的历史梯度可能会好一点,但这样又缺乏对过往梯度的全面考量,如此一来 RMSProp 出现了,它引入了一个折扣因子的概念,让之前的历史梯度都乘以一个折扣因子α的 n 次方,这里的n就是历史梯度与当前时刻的时间跨度:
\[ θ_t ← θ_{t-1} - \frac {μ}{\sqrt {\sum_{k=0}^t α^{t-k}{G_w}_k+ε}}g_t \ ]
正梯度仍然使得policy的probability增大
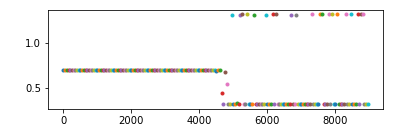
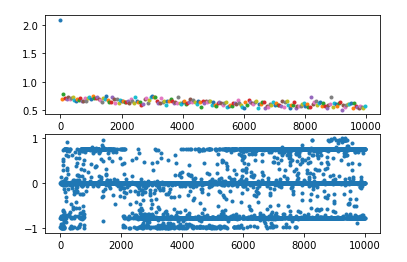
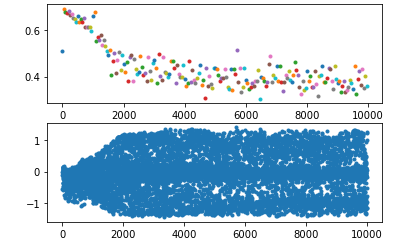
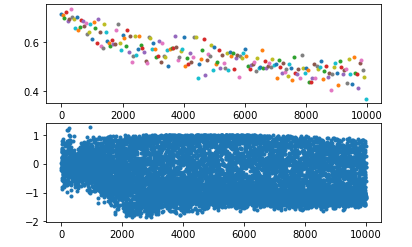
现象
使用policy gradient算法写了一个小模型,训练过程中发现模型很快会收敛到一个非常糟糕的结果,理论上不应该呀,因为按照policy gradient算法原理来说,对于某个action,如果你给了负的reward,那么模型会减小该action出现的概率,但我的实验表明,模型不仅没减小该action的概率,甚至还会增加它的概率,最终它的概率甚至会等于1。理论上,即使这个不好的action概率为1了,但是reward是负的,每次迭代应该还是会降低其概率,但我这个实验发现并没有,反而会继续降低另外一个好的action的概率——即使它已经无限逼近0了。
排查
首先我想,既然坏的action概率在增加,有没有可能是因为reward是正数(本来应该给负数),但是经过简单的排查后发现,该action的reward就是负数。
然后考虑到,policy gradient 对采样的样本action会无脑增大其发生概率(前提是该action的reward是正的),然而采样所使用的概率也是这个概率,那么就可能形成一个恶行循环:梯度上升导致概率增大->概率增大导致其更容易被采样->采样后概率继续增大…。但经过计算发现,即使它的概率会恶性增大,但如果采样的足够多,总是会采样到其他reward更大的action上,那么它的概率还是会减小很多。另一点就是经过排查,发现这个action的reward确实是负的,应该不会出现这个情况。
第三个想法是,因为这是一个神经网络,本质上就是一个函数,假如这个函数有图像的话,现将其简化想象成一个二维的曲线,那么上面的问题就类比于:如果我采样到上面某个点,经过计算发现下一次迭代后,这个点的位置应该下降(本质上是函数发生了变化,原本的函数更新为另一个新的函数),但是实验却发现下一次迭代后它还上升了。一个很直接的想法就是,有没有可能,如果单独更新这一个点时,它确实会下降,但实际上,我同时更新了多个点,在更新其他点时,更新的参数影响了这个点的值,那么它就有可能不降反升。理论上,这也确实是非常有可能的,但它发生的概率应该要远小于50%,否则模型只会越训练越差。但上述实验发现,好像这个值又接近50%,这就让人匪夷所思了。而且,理论上,就算出现这种问题,在迭代次数足够多后,这种情况应该越来越少。所以这个假设也被排除。
实验到此已经很晚了,我仍然没想通什么原因。于是我想会不会就算训练的时间不够导致的,于是我同时运行好几个相同的模型,其中只有部分有修改,例如有些使用 discount reward,有些使用 total reward,有些则更换优化器等,跑一个晚上看看结果。
如何使用梯度判断模型中间量的更新方向?
在pytorch中,只有叶子节点的变量(学习量)才可以直接获取梯度,但在上述问题中,我发现模型输出的某个概率增大了,我怀疑这里的梯度有问题,那么我想查看这个输出概率的梯度怎么办?很明显直接看是看不了的,因为它只是一个中间量,虽然会计算它的梯度,但并不会在backward后保存下来,因为并不需要真正更新它。
pytorch提供了
register_hook()函数来获取或修改这些中间量的梯度:output = model(input) ... # 如果同一个变量注册了多个 hook,则会顺序执行它们。 output.register_hook(lambda grad: print(grad)) # 读取梯度 output.register_hook(lambda grad: grad * 2) # 也可以直接修改梯度 ... loss = loss_model(output) loss.backward() # hook中的函数会在这里计算完梯度后执行 ...通过这种方法,你就可以知道下一次迭代时是会增加这个输出还是会减少这个输出了。由于迭代后的值等于原值减去梯度,如果梯度是正数,则会减小,反之会增加。下面是一个register_hook()使用方法的例子:
a = torch.tensor(2., requires_grad=True) b = 5 * a c = b * b b.register_hook(lambda g: print(f'b grad: {g}')) # b grad: 20.0,因为用c对b求偏导为 2b, 而b又等于 5*2,所以b的梯度为 2 * 5 * 2 c.backward()一个具体的例子:
Policy gradient中为什么必须给概率取log?
注意:这篇文章没有解释原因,只是探索了一个相似方法
一般认为是可以用来简化计算的,log可以将原本的累乘转换为累加,例如 a*b*c 总体加上一个log就可以转换为 loga+logb+logc,当然,能总体加log是因为log保留的原来函数的单调方向,转成加法还有个好处就是一定程度上可以防止梯度消失或爆炸,因为连乘很容易为0或无穷
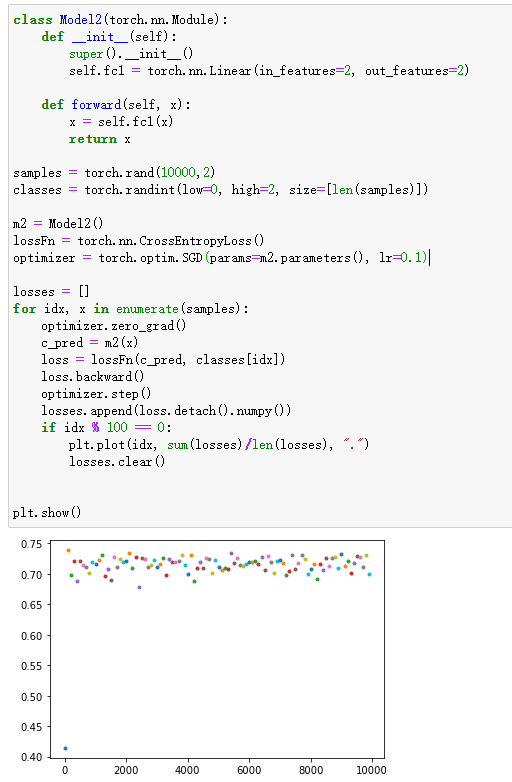
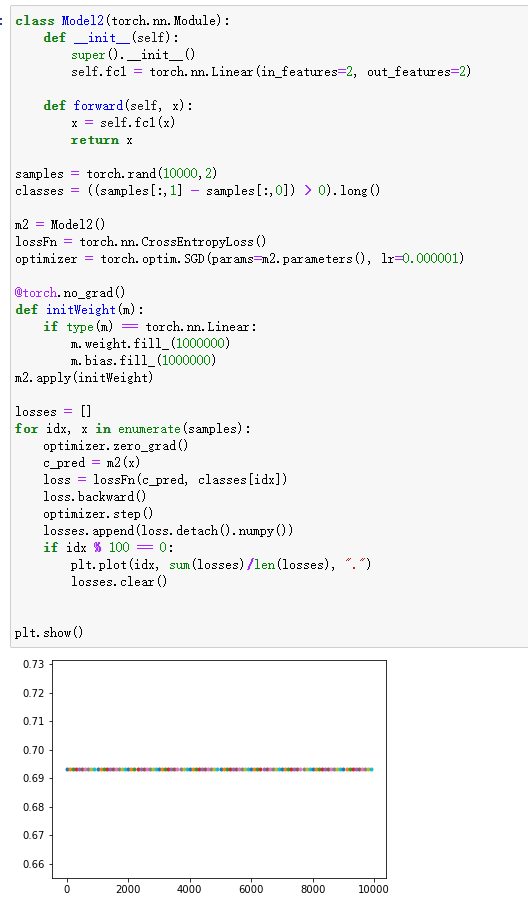
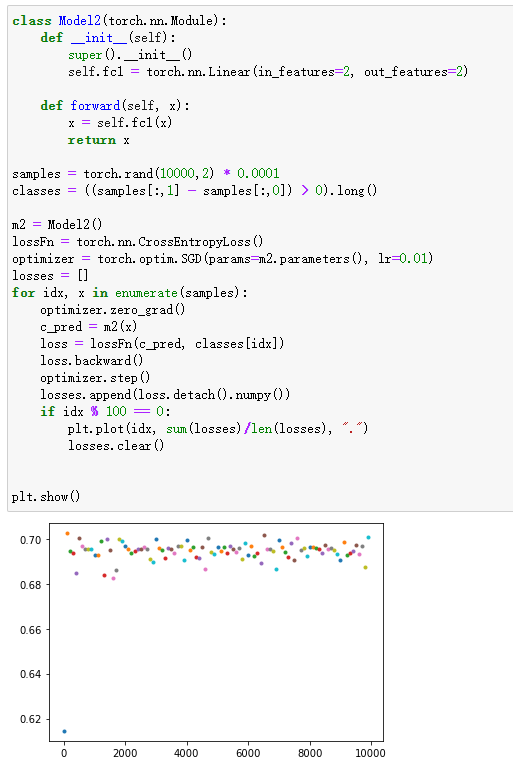
使用最朴素的policy gradient写了一个玩平衡杆的策略模型,发现如果使用SGD会出现一些问题
# 以下代码是有问题的 ... action_probabilities = model(current_env) ... choose_action_prob = action_probabilities[choose_action] ... loss = -reward * choose_action_prob loss.backward() ...问题出现在直接使用
choose_action_prob用作梯度上升。其实直观上感觉应该就是这样的:一局游戏的得分的期望等于这局的total reward乘以这局游戏中各个过程的出现概率。目标就是最大化这个期望,如果使用现有的梯度下降框架,则直接在前面乘以一个负号即可。感觉应该就是这样的,实验结果表明这样模型很有可能不会收敛,模型不会选择最优策略。
我猜测问题可能出现在负号上,理论上这个loss可以无限小,也就是它可能是无解的,但可以通过修改代码使得模型可以趋近于一个值(注:问题原因并不一定是这个,我猜的,但这个解决方法确实可以解决这个问题)
解决方法是让
choose_action_prob = -1/choose_action_prob,因为我们的目的是使得上面的loss更小,也就是使得这里的choose_action_prob更大,前面加上一个负号就可以让它和loss前面的负号抵消,然后让它做除数,即不影响它原本的单调性。我实验了一下,这种方法确实可行,但更常用的方法是取log
# 方法一 choose_action_prob = 1/choose_action_prob loss = reward * choose_action_prob # 方法二,注意后面加一个很小的数防止为0 choose_action_prob = torch.log(choose_action_prob + 1e-8) loss = -reward * choose_action_prob这样一来,loss应该是越趋近于0越好。不过实验结果表明,方法二的效果远远好于方法一,甚至于 -1/x+1 也比上面的1/x要好得多,why?
这是 log_e(x) 和 -1/x+1 的曲线
以下为完整代码:
import itertools import threading import gymnasium import numpy as np import torch from loguru import logger from torch.utils.tensorboard import SummaryWriter board = SummaryWriter('./logs/division_factor_random') torch.random.manual_seed(1) np.random.seed(0) def visualize_train(policy: torch.nn.Module): with torch.no_grad(): test_env = gymnasium.make("CartPole-v1", render_mode='human') for i in itertools.count(): total_reward = 0 obs, _ = test_env.reset(seed=0) while True: action = torch.argmax(policy(torch.FloatTensor(obs))) obs, reward, terminated, _, info = test_env.step(action.item()) total_reward += reward if terminated: board.add_scalar("test/reward", total_reward, i) logger.info(f"total reward: {total_reward}") break test_env.close() class Actor(torch.nn.Module): def __init__(self): super().__init__() self.dnn = torch.nn.Sequential( torch.nn.Linear(in_features=4, out_features=20), torch.nn.ReLU(), torch.nn.Linear(in_features=20, out_features=2), torch.nn.Softmax(dim=0) ) def forward(self, x): return self.dnn(x) actor = Actor() threading.Thread(target=visualize_train, args=(actor,)).start() optimizer = torch.optim.Adam(params=actor.parameters()) env = gymnasium.make("CartPole-v1", render_mode=None) for game_count in itertools.count(): obs, _ = env.reset(seed=0) acts = [] rewards = [] for s in itertools.count(): action_probs = actor(torch.tensor(obs, dtype=torch.float)) action = torch.distributions.Categorical(action_probs).sample().item() # if np.random.random() < 0.1: action = np.random.randint(0, 2) obs, reward, terminated, _, info = env.step(action) acts.append(1 / action_probs[action]) rewards.append(reward) if terminated: # loss with discount factor=0.99 loss = sum([a * weighted_r for a, weighted_r in zip(acts, [sum([r * 0.99 ** j for j, r in enumerate(rewards[i:])]) for i in range(len(rewards))])]) # loss = (sum(rewards) * sum(acts)) optimizer.zero_grad() loss.backward() optimizer.step() break env.close()gym实时渲染模型训练效果
深度强化学习模型在训练玩游戏时,不渲染游戏画面可以大大加快训练速度
# 将 render_mode 设置为 None 就不会渲染游戏,设置为 "human" 就会以图像帧的形式渲染 # 注:老版本需要调用 render 方法才会渲染,新版本会在调用 reset 方法时就自动渲染 env = gymnasium.make("CartPole-v1", render_mode='None')如果我想在训练过程中实时查看模型的训练效果,则可以使用多线程实现:
一个线程负责训练模型,另一个线程中重新创建一个一样的游戏环境,负责渲染,它们都从主线程获取最新的模型(训练线程就可以作为主线程)
import threading def render(model): render_env = gymnasium.make("CartPole-v1", render_mode='human') with torch.no_grad(): while True: obs, _ = render_env.reset() while True: act = convert_model_output_to_act(model(torch.FloatTensor(obs))) _, _, terminated, _, _ = render_env.step(act) if terminated: break m = MyPolicy() # 创建一个渲染线程,并将正在训练的模型作为参数传递进去,daemon=True 表示将其作为守护线程,主线程退出后它也跟着退出 threading.Thread(target=render, args=(m,), daemon=True).start() # 主线程就可以作为训练线程,下面部分就是模型训练相关的代码 train_env = gymnasium.make("CartPole-v1", render_mode='None') ...或者使用子进程也可以,使用方法基本一致,但是要注意,1)这里的 main 方法是必须的,2)进程中传递的args参数并不是引用传递,而是值传递,意味着在主进程中修改了actor的参数后,子进程仍然使用的是原来的actor:
import multiprocessing ... if __name__ == "__main__": multiprocessing.Process(target=visualize_train, args=(actor,), daemon=True).start()Policy gradient 与 e-greedy
在训练qlearning网络时,通常会设置一定的概率去做一些探索,以求能做出更好的决策。而在Policy gradient中,也是需要探索的,但是它会有一些问题
我写了一个MLP来作为policy,在训练过程中,每次做决策都使用 argmax 来寻找当前模型认为最好的action,模型不会收敛,想想它当然是不会收敛的,因为policy gradient训练模型本质上就是在提高采样样本中被采取的action的概率,即使这个action是一个不好的action,模型也会提升它,而之所以policy gradient能够训练出有效的模型,是因为提升每个action的程度不同,得到的reward多,提升得就高,反之提升得就低,如此一对比,提升得低的就相对是在降低了
而如果我在训练中每次都使用argmax获取action,也就是每次采样都是采样的模型输出概率更高的那个action。假设一开始各个action的概率是一样的,经过第一次采样,得到了一个样本(S,a),表示在状态S下采取了a的动作,那么,如果该游戏没有负reward的情况下,即使我采取a这个动作带来了不好的结果,那么reward也是正的,那么在梯度上升的加持下,模型就会提升在S这个状态下,a这个动作的概率,因为原本各action概率相同,如此一来a的概率就会比其他的都高,那么后续每次采样都只会采样到a了,a的概率也会逐渐增加知道趋近于1。
一个直观的想法是引入qlearning中的e-greedy方法,设置一个随机变量,在某次训练过程中如果该变量大于某阈值,则随机选择一个action,而不是使用argmax选择模型认为最好的action。这种想法看似可行,因为这样就避免了只会采样一个action的情况,但实际上这样还是有问题的,它对reward和随机变量的阈值都是有要求的
在一个trajectory中,会出现很多(S,a)对,表示在环境S下,policy选择了a这个action。不管a这个action是好的还是不好的,在最原始的policy下,它都会将这整个trajectory的total reward作为梯度增量的因子,所以,这种情况下,采样的a越多,其被再次采样的概率就越大,即使它不是一个好的action。
假设在S状态下有 A1,A2 两种action可以选择,选择A1可以得到reward=R1,选择A2得到 R2,经过设计有r1的概率选择A1,r2的概率选择A2。模型训练过程中,在做梯度更新时会将reward作为梯度增量的乘数因子,所以可以简单地认为reward就是训练一次后,各个action概率变化的增量。当概率的增量无法弥补选择的概率带来的差值时,模型的策略就不会发生变化(这里本来是要做一些数学计算的,但算着算着发现比我想象的要复杂得多),例如,R1=8,R2=9,r1=0.9,r2=0.1,假设 r 的更新公式为 r = (r + 0.01*R)/sum(r),则训练一次后,r1=0.84,r2=0.16,可见,正确的策略应该时选择A2,但此时r1仍然大于r2,要使r2>r1则需要很多轮的迭代,但要注意,这里讨论的仅仅是一个特定状态S下的情况,而真实情况下,采样的S每次可能都不一样,再加上reward本身可能是个随机变量,那么又要要求采样很多个S模型才能选择正确的策略,这个概率似乎还是有点低。还有一点更为重要,这里其实说的是不同的reward下的情况,它最终应该能收敛,但是在同一个trajectory,不使用折扣因子的情况下,其实它们的reward是一样的,这却情况下,谁被采样得多,谁就更有可能再被采样。经过实验证实,如果引入折扣因子,这个问题也会被解决
当奖励没有区分度的时候,被采样的次数越多,被采样的概率也就越变越大,这是一个恶性循环
由此可知,在使用policy gradient方法时,应尽量使得采样样本更丰富,例如训练过程中选择action时,不直接使用argmax选择,而是将模型的输出作为action的选择概率分布,然后随机选择:
# pytorch提供的方法 action = action_space[torch.distributions.Categorical(action_probs).sample().item()] # 甚至于在某些简单的情况下,你可以完全采用随机的action,但是使用argmax是不会收敛的 action = torch.randint(0, 2)当然,上面讨论的都是在reward都为正的情况下,如果有正有负则有可能不会出现这种情况,所以另一个解决方法是给reward减去一个baseline,详见 深度强化学习简介
深度强化学习简介
这是一篇深度强化学习视频的笔记 https://www.bilibili.com/video/BV1XP4y1d7Bk
什么是强化学习
强化学习方法分为三类:Policy-based(训练一个actor,例如 policy gradient)、Value-based(训练一个critic,例如 Q-learning)、Actor-Critic
所谓的actor就是一个agent,即决策者,它能根据一个输入状态,输出一个行为。例如输入一帧游戏画面,它输出前进还是后退等,然后系统根据游戏结果给出相应奖励
所谓critic就是一个预言家。它用来预测某个人执行某种行为的预期结果
某人(actor)问预言家:我现在破产了(当前状态),如果我去抢银行或者去打工(可以采取的动作),我会得到什么后果?预言家说:如果你去抢银行,你会被抓住,后半生就在监狱度过,如果去打工,由于你的人品不错,你会遇到一个贵人,他会让你飞黄腾达(对这个人采取某个行为的预言)。
事实上,上面问预言家(critic)的过程就是Actor-Critic,actor不会真的去抢银行或者打工,他只是提出这个做法,让critic去评价,然后他得到这些评价内容后来审视自己,比如说他知道打工会遇到贵人是因为自己人品好,他就会让自己人品更好,而预言家看到了这个人的改变后又会给出新的预言,两者不断更新
关系梳理
下面的图来源于《深度强化学习》一书,我觉得这些图对学习强化学习的路径规划有很强的指导意义
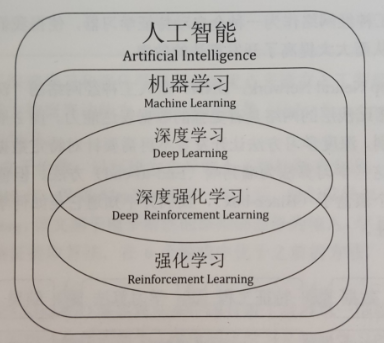
强化学习在人工智能领域的位置
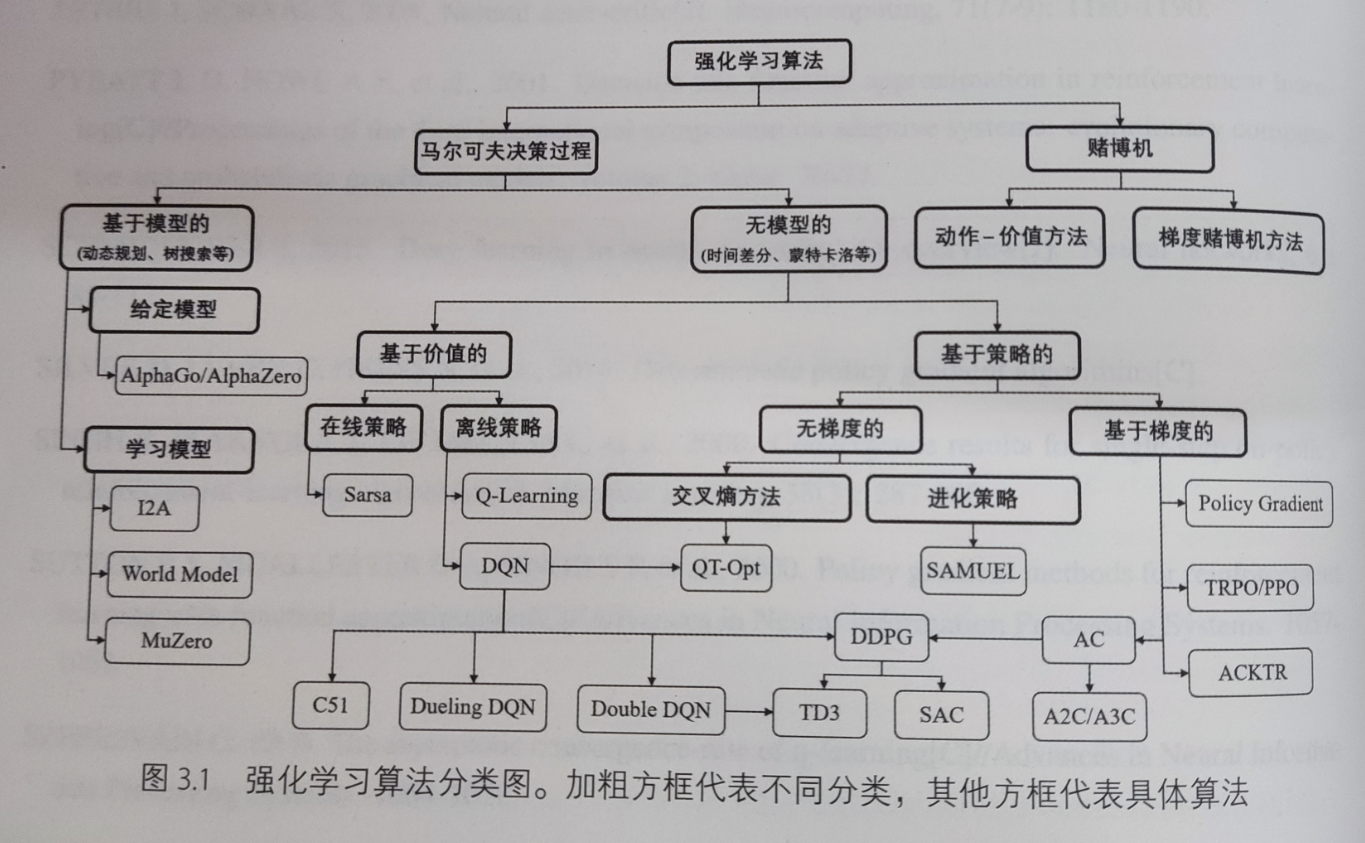
强化学习算法分类:
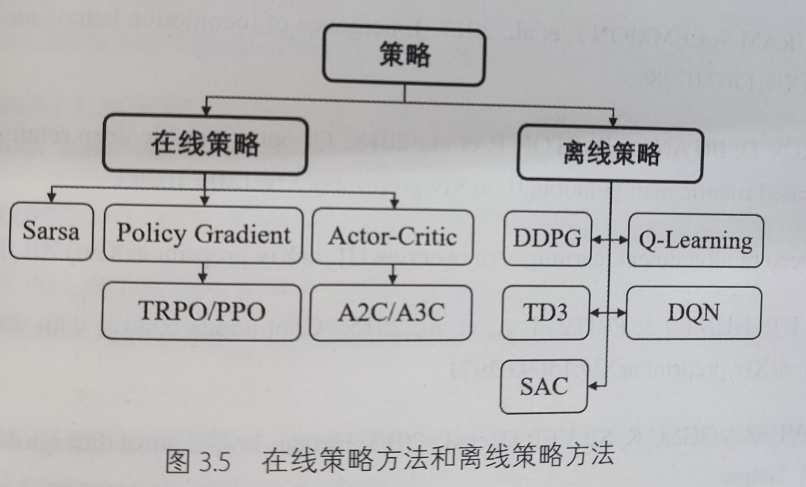
在线策略和离线策略分类
蒙特卡罗法(MC)和时序差分法(TD)分类
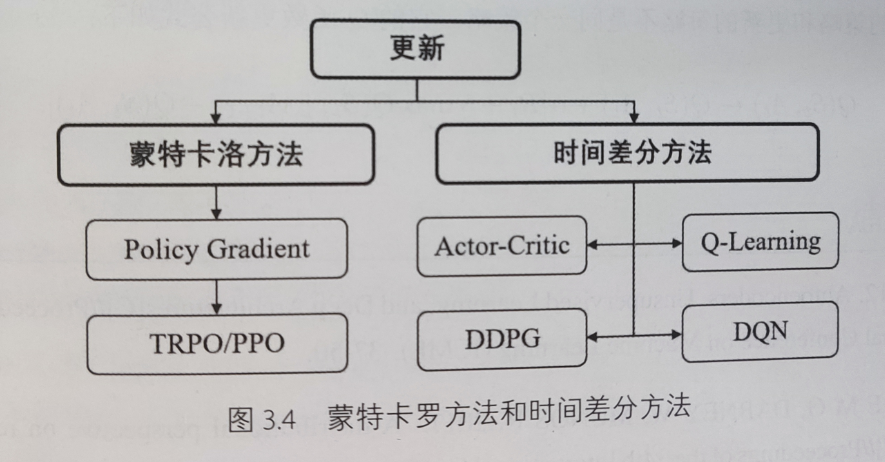
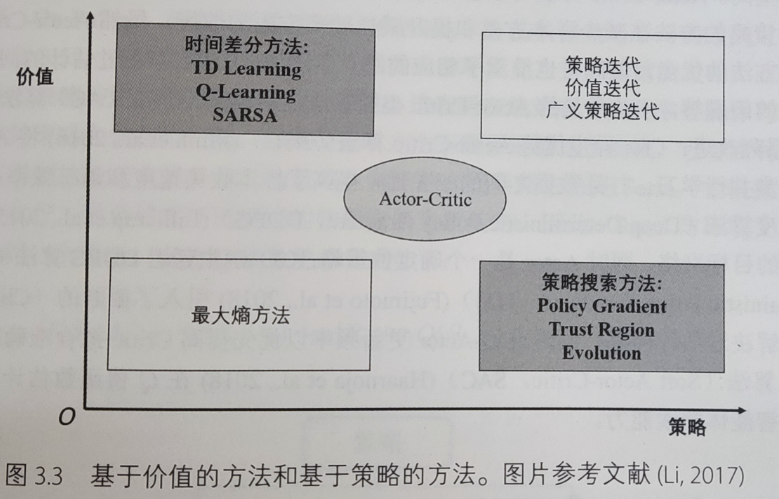
value-based 和 policy-based 方法分类
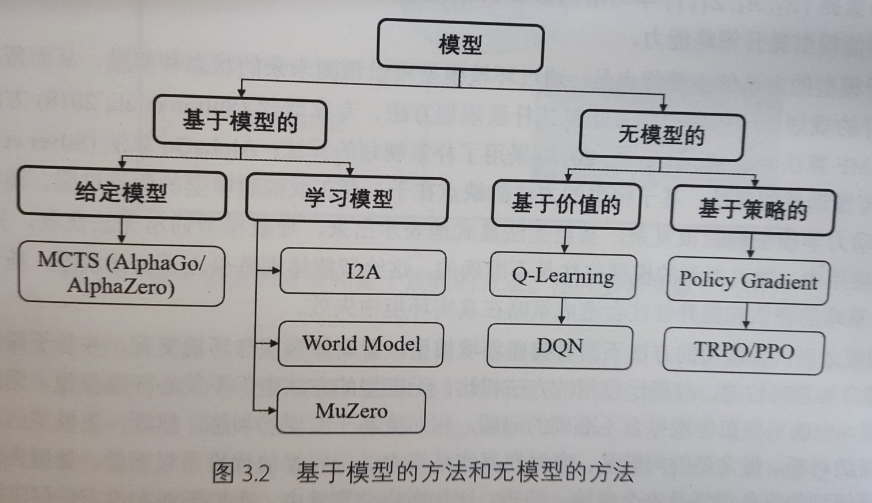
基于模型的方法和无模型的方法分类(不是深度学习模型,是数学模型)
policy gradient
每一局游戏都是由 状态-动作-奖励-状态-动作-奖励。。。不断循环进行的
\[ trajectory τ = {S_1, a_1, r_1, S_2, a_2, r_2…, S_T, a_T, r_T} \ ]
所以一个trajectory发生的可能性为:
\[ p_θ(τ) = p(S_1)p_θ(a_1|S_1) p(S_2|S1, a_1)p_θ(a_2|S_2)p(S_3|S_2, a_2)… = p(S_1)\prod_{t=1}^Tp_θ(a_t|S_t)p(S_{t+1}|S_t, a_t) \ ]
对于任意一个trajectory来说,它的total reward为:
\[ R(τ) = \sum_{t=1}^Tr_t \ ]
那么对所有trajectory来说,它的reward期望就是每个trajectory发生的概率乘以其total reward:
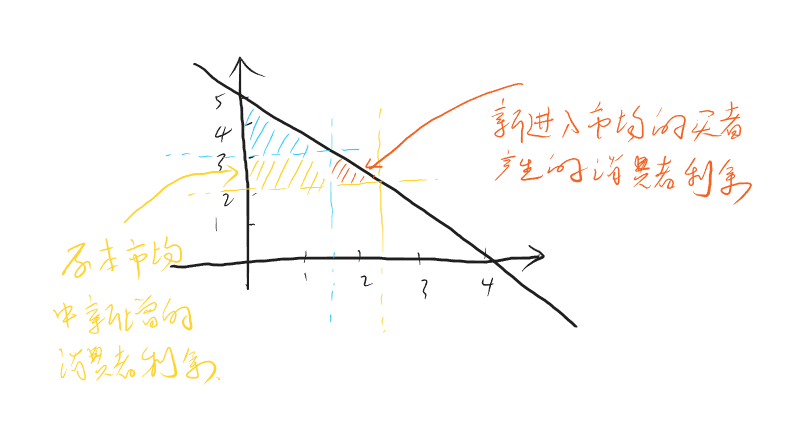
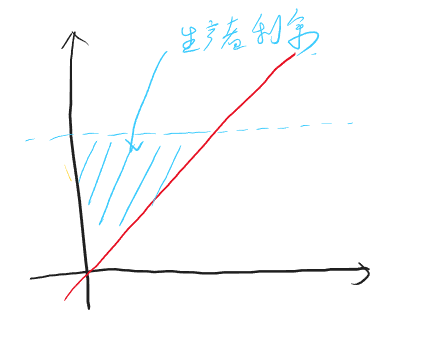
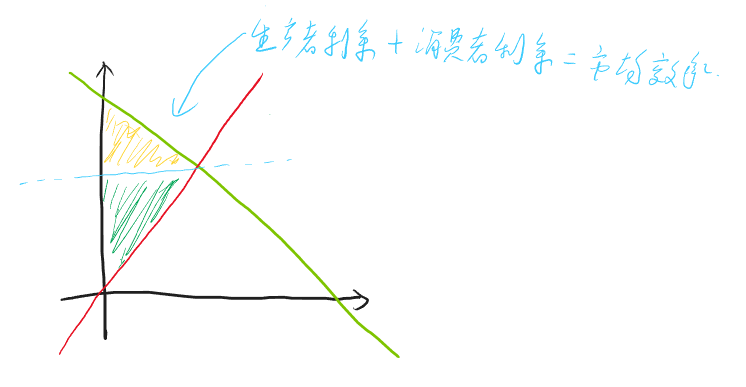
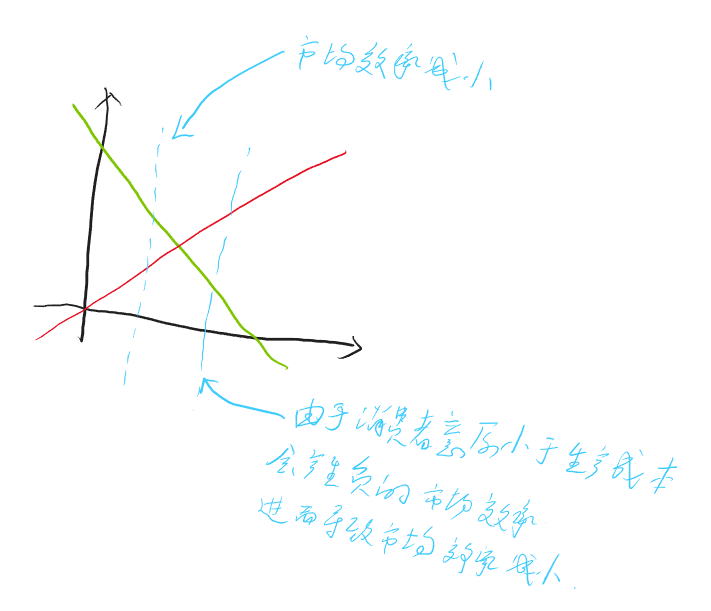
\[ \overline{R}_θ = \sum_τp_θ(τ)R(τ) =E_{τ\sim p_θ(τ)}
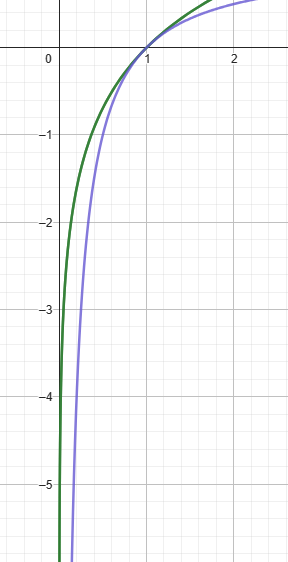
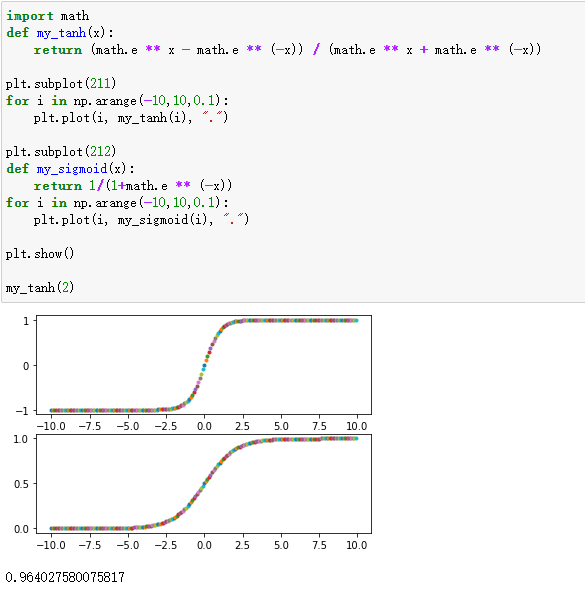
随机到之前不会的题
刚才刷leetcode时候随机了一题,发现这道题我竟然点过赞,并且加入了收藏
我想这应该是我很久之前刷过的一题,没有提交记录,当时应该没做出来,并且应该看过了其他人的解决方案还是没做出来的那种,觉得方法很巧妙也很common,所以才点赞加收藏,希望下次能做出来。
我有理由相信我当时应该花了很长时间来做这道题,甚至几个小时,因为那时我做一题基本是按小时计时的,那个时候刷题完全没有章法,也完全不会总结,就是硬刷,那个时候也不懂动态规划,对递归的使用也是似懂非懂。
最近每次刷到那种完全没有头绪的题,我都会怀疑这段时间的训练是否又和之前刷题一样,毫无章法,毫无意义。
这次又随机到了这道题,我可以仅用4分钟,用4行代码就解决了,我想,这段时间的训练确实应该是有效果的。
Shortest Path in Binary Matrix
https://leetcode.com/problems/shortest-path-in-binary-matrix/
以下为我的思考过程:
我首先想到能否使用动态规划解题,因为,假设要求解的坐标为(i,j),那么我只需要知道其邻域八个坐标的解,即对于给定任意grid中的坐标,如果该坐标值为0,则我只需使用
1+min(邻域坐标最短路径)即可求解。但细想一下也不对,因为这八个坐标并不全是求解坐标的子问题,因为如果要满足子问题的规模,则子规模的坐标必须都大于或者小于求解坐标,显然邻域坐标中,有些大于(i,j),有些小于(i,j)。这说明这题应该不适用于动态规划。于是又想,既然是求解路径,dfs应该是可行的,于是写代码:
class Solution: def shortestPathBinaryMatrix(self, grid: List[List[int]]) -> int: if grid[-1][-1] == 1 or grid[0][0]: return -1 def dfs(i, j, path): if (i, j) in path or i < 0 or i > len(grid)-1 or j < 0 or j > len(grid)-1: return -1 if i == len(grid)-1 and j == len(grid)-1: return 1 return -1 if grid[i][j] != 0 else 1 + min(filter(lambda x: x>0, [dfs(i-1, j-1, path+[(i, j)]), dfs(i-1, j, path+[(i, j)]), dfs(i-1, j+1, path+[(i, j)]) , dfs(i, j-1, path+[(i, j)]), dfs(i, j+1, path+[(i, j)]) , dfs(i+1, j-1, path+[(i, j)]), dfs(i+1, j, path+[(i, j)]), dfs(i+1, j+1, path+[(i, j)])]), default=-2) return dfs(0, 0, [])但这个会超时,原因在于,dfs会遍历所有可能的路径,然后找到一条最短路径。有没有直接找最短路径的方法呢?那就是BFS,可以想象,如果让你在一棵树中找到达叶子节点的最短路径,一个可行的方法就是逐层遍历树,遇到的第一个叶子节点就是路径最短的叶子节点,因为其深度最低
Content-Type: multipart/form-data
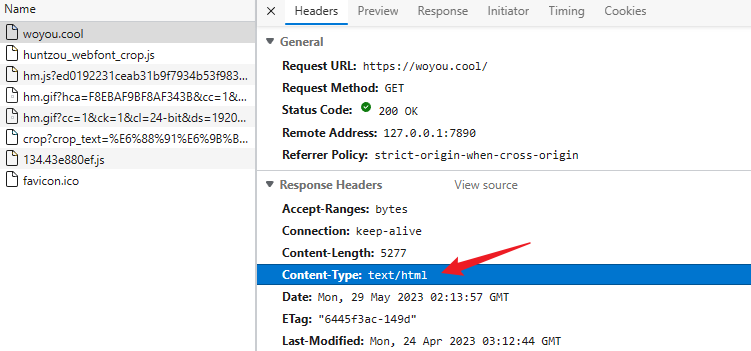
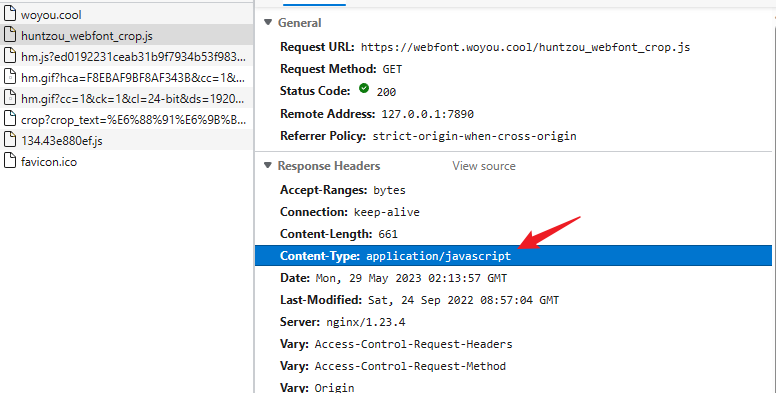
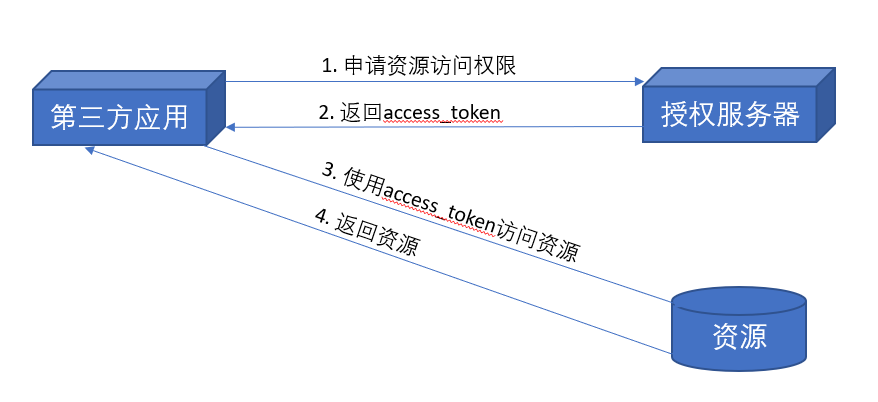
什么是 Content-Type 头
在http响应头或请求头中会看到一个名为
Content-Type的头信息,它表示的就是文档的类型信息(Multipurpose Internet Mail Extensions or MIME type 即MIME type)
一个url其实就是一个远程文件的地址,通常一个文件可以通过后缀名来区分文件类型,但是浏览器通过url访问文件并不会使用后缀名来判断,而是使用content-type这个头来判断,这也是为什么一个html可以有不同的后缀名,甚至不要后缀都可以,只有content-type这个头设置正确即可
Content-type 头结构
Content-type表示的是文档类型,它是有一个固定的结构的
type/subtype // 或带参数的 type/subtype;parameter=value这里的
type表示的是一个文件的大类别,例如 文本文件(text)、视频文件(video)等
subtype表示文件的子类别,例如,对于文本文件(text),其可能是常规文本(plain)、HTML文件(html)等。例如对于一个静态页来说,其MIME type就是text/html文档类别是可以携带参数的,例如
text/plain;charset=UTF-8type
type分为两种:单类型(discrete)和混合类型(multipart),其中,单类型就是文档就是一个类型的文件,例如html文件、视频文件等,而混合类型则表示多种类型的文件混合类型,典型的例如在表单提交时,会有文本、文件等多种类型混合提交的,或者接收的邮件中既有文本也有文件
discrete
text、image、font、video、model、audio、example、application等
multipart
对于混合类型的http响应,除了 Content-type 为
multipart/form-data或者multipart/byteranges外,其他的类型都会被浏览器当作下载文件处理(Chrome右上角显示一个另存为的提示)混合类型实际上也是要对每个子类型进行说明的,下文中有举例
混合类型的 type 有:
multipart和messageMIME types举例
application/octet-stream:默认的二进制文件类型,浏览器会直接显示“另存为”的提示
text/plain:浏览器会直接显示,值得注意的是,浏览器不会将这种类型的文档解释为特定类型,例如你不能在里面写js或css等,浏览器不会主动解释
text/css、text/html、text/javascript等
image/apng、image/gif、image/jpeg、image/png、image/webp等
video/webm、audio/webm。。。
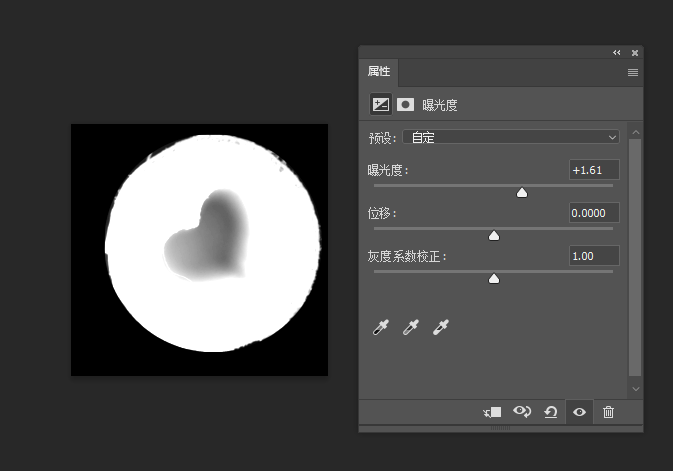
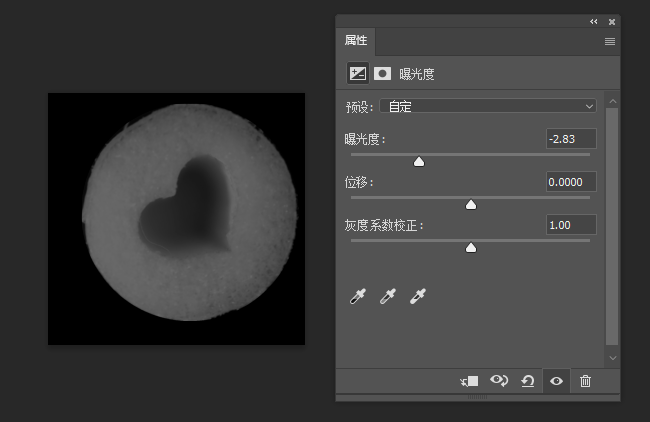
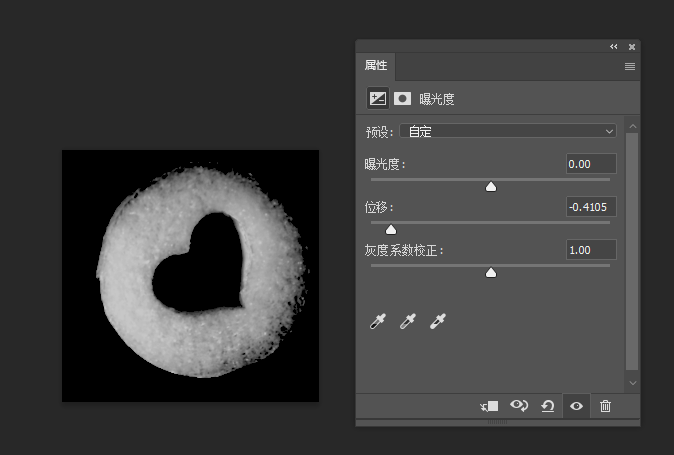
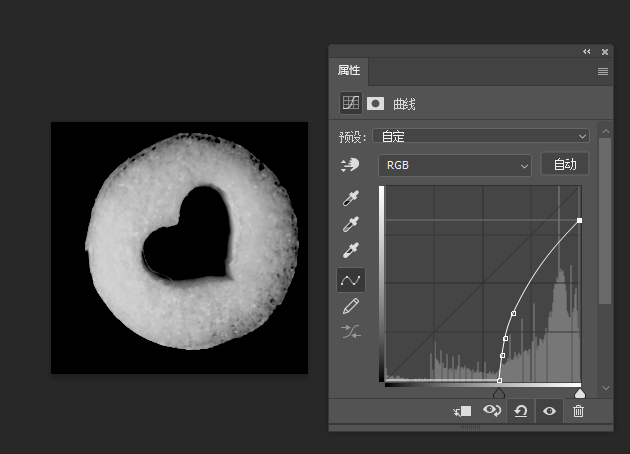
multipart/form-data
这个头常见于表单提交的请求头中,以前一直没搞懂它是怎么运作的,这里做一个解释
对于这种混合类型的文档,它的content-type实际上也是由各个类型的单类型组合而成的。例如对于以下表单:
<form action="http://localhost:8000/" method="post" enctype="multipart/form-data"> <label>Name: <input name="myTextField" value="Test" /></label> <label><input type="checkbox" name="myCheckBox" /> Check</label> <label> Upload file: <input type="file" name="myFile" value="test.txt" /> </label> <button>Send the file</button> </form>它里面有三个input标签,其中两个是文本类型,一个是文件类型,那么在提交时,实际的请求体为:
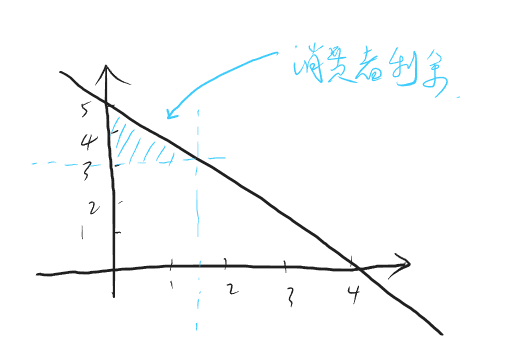
异或产生的思考
刚才做一道算法题,觉得它的解很有启发性,题目是:给定一个int数组,数组只有一个数字只出现了一次,其他都是成对出现的,数组是乱序的,请找出这个数字 https://leetcode.com/problems/single-number/description/。
题目很简单,我的做法是先排序,然后再遍历入栈,若栈顶元素与当前元素相同则出栈,最后栈中剩余的那个数即为所求。时间复杂度为 O(nlogn),但是还有个非常精妙的做法是使用异或操作(xor:相同位为0,不同为1):将所有的数都异或,则最终的异或结果即为所求,时间复杂度为 O(n),我惊讶的是这个想法。
我想,这可能是一种非常快速且节约资源的对比算法,例如,假如我有两个无序数组,我想快速对比两个数组的元素是否相同,我并不需要非常准确的结果,我只希望其占用的系统资源尽量低。一个可行的做法是分别对两个数组中的元素做异或操作,然后对比结果,如果相同,则说明这两个数组“有可能相同”,如果不同,则说明这两个数组“一定不同”
之所以说有可能相同,是因为不同的数组也可能计算出相同的异或结果。例如:[ 1100, 0011] 的异或结果为 1111,但是 [1010, 0101 ] 的异或结果也是 1111,但它们确实是两个完全不同的数组
这很像布隆过滤器,它们都不要求绝对的准确率,但是对时间、空间复杂度却有很高要求,事实上,我觉得这两个方法从某种角度来看近乎是同一个方法。
我想到一个可能的应用:做数据校验
我们知道,数据在网络传输过程中是不稳定的,从小的说,一般数据报文在传输时会在报文头部或者尾部添加校验位,用于校验数据传输过程中是否出现错误,往大了说,一般在下载东西的时候,别人不仅会提供下载文件,还会提供一个校验文件,也是校验下载的内容是否完整的,这个校验文件一般使用一些数字签名算法例如md5等,我想应该也可以使用这种异或的简单算法:先将待下载文件平均切分成n份,然后对它们做异或,最终得到的异或结果就可以当作校验文件。用户下载完文件后,也将文件切分为n份,然后将得到的异或结果与别人提供的结果做对比,达到校验完整性的作用。
我觉得这个东西可能在加密方面也能有点应用,我甚至觉得它应该可以用来神经网络上,这样应该可以大大加快模型的推理速度
例如卷积神经网络,它本质就是一个模式匹配的过程,那异或不也是模式匹配吗,稍有不同的是,在卷积过程中,相同则为1,不同则为0,这与异或正好相反,不过可以使用 1-x 的方法来解决
再者,我甚至可以认为对多个数据异或的过程就是一个编码的过程,相当于做了数据降维,这个过程是否可以用在 encoder-decoder 模式的网络中
自己的键盘
闲鱼上买了一盒摩斯码键帽,卖家很久都没发货,中途我还去淘宝等地方找了下,到处都没卖的,也就闲鱼上有一家卖,但是他一直不发货,我一度以为他也是代购的,就在我正准备发起退款前夕,卖家发货了。
“z”和“k”和“7”键印错了,“UP”和“DOWN”键也是也没有对应高度的
一开始用还真有点不习惯,但后面应该会慢慢习惯的,一旦用惯了后,这就是我的专属键盘了——别人想用也都不会用
这里记录一下键盘的一些设置方法和按键对应关系:
LM67键盘套件蓝牙连接方法:按 FN+Q 切换到蓝牙模式,短按 FN+A/S/D 切换三种蓝牙设备,长按则是重新配对,长按 FN+G 清除所有蓝牙配对记录
说明书来源:http://www.teamwolf.cc/home/services
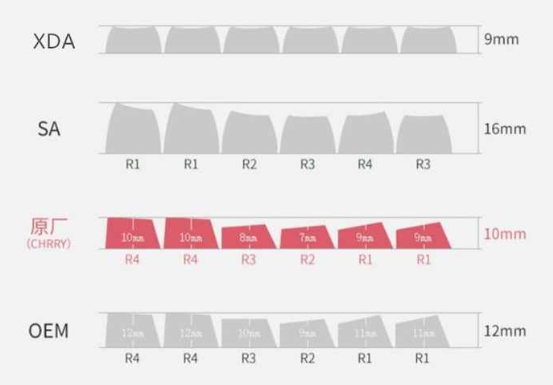
按键高度:
LM67:客制化的第一顿毒打
完全无用的gasket
下面这张图是我将pcb板掀开的图,可以很清晰看到usb线的接口突出很大一块,由于太高了,它会直接将整块pcb顶在电池上。
进而导致这个pcb是不平衡的,被额外顶起来很高
加上外壳本身就很矮,再加上gasket减震垫(图中四周黑色的长条)本身就薄,所以定位板实际上并没有压在减震垫上,而是直接压在消音垫上的。
下图为左边正常一点的gasket减震垫高度,可以看到它其实还是比消音垫要高一点的
下图为右边被顶起来的部分,可以明显看到gasket减震垫与消音垫持平甚至更低了,所以这部分定位板压根没有压在减震垫上。
下面这个视频中,键盘左边相对来说是可以压下去一点的,但右边由于整体被顶起来了,所以根本压不下去
但实际上我感觉,之所以能按压下去,都是因为这个定位板本身就是软的
另外这块定位板本身大小也是有问题的,它太大了,以至于外壳底板上的几个螺丝孔都是压在它下面的,所以这个定位板前边缘都是被底壳撑着的
再另外就是上盖也是,由于gasket减震垫太薄,加上定位板太大,整个上盖压下去之后,定位板边缘几乎都是直接被上盖压着的,减震垫根本没起作用
综上所述,我可以说,这个gasket完全就是无用的
以下为我的一些解决方法:
打磨轴下的消音垫,把凸起来那部分削薄一些(或者直接换薄的填充物)
将与螺丝孔接触部分的定位板削一下
将定位板边缘都削一下,缩小一圈
买点厚的gasket减震垫,重新垫一下
将电池卧插削一下
这是削之后的效果
严重松动
pcb没有和底板固定,但也太松了,导致每次拨动pcb上的开关时,整个板子都会跟着一起动
电池
可以明显感觉,这个外壳根本做的时候根本没有考虑到电池的问题,它使用两块电池并联,但由于底部位置很小而且是个梯形空间,所以这两个电池必须非常薄,而且只能放在靠底壳尾部的位置,再大一点都不行,然后在中间加强筋的位置直接烧出一个槽,用于过线。事实上这个槽烧不烧都可以,因为pcb已经被顶起来了,压根压不到这个线。
再者就是这个板子是直接使用的gas67的板子,它根本没有查看电量方法。如果是一开始有考虑使用电池的话,应该不至于连这个功能都没有。
宣传的是使用了2000毫安时的电池,但是它使用的是两块电池并联的,而其中一块贴有标识的电池上写的是2000mAh
但它有两块电池,是不是就是4000?哦 我想到了,其实这两块电池是一起的,也就是那个标识就是指的两块电池的,难怪只有一块电池有标识。
说明书
我想连一下蓝牙,发现包装里放了两个一样的说明书,关键是这个说明书什么都没说,就说这个东西可以连蓝牙,怎么连,提都没提。
说明书字都打错了,可想而知他们是以一种什么心态在做东西
BTW,我也是看了其他型号的键盘说明书才猜出蓝牙是如何连接的:先按 FN+Q 切到蓝牙模式,再按FN+A/S/D切换三个不同的蓝牙设备,长按FN+A/S/D则是重新配对,长按FN+G则是清除所有配对信息
总结
这个套件是从Gas67直接改过来的,只不过Gas67不支持三模,只支持有线连接,可以很明显地感觉做Gas67时根本没考虑到三模版本,这就是一个用来收割的东西。
尤其是这个主推的 gasket 结构,完全就是没有用的。甚至还使得其他能做好的地方变差了
但是我已经买了,而且我不打算退换,我想这就是命吧,我自己想想办法改改,多折腾折腾,它总是要有个归宿,它已经很可怜了。
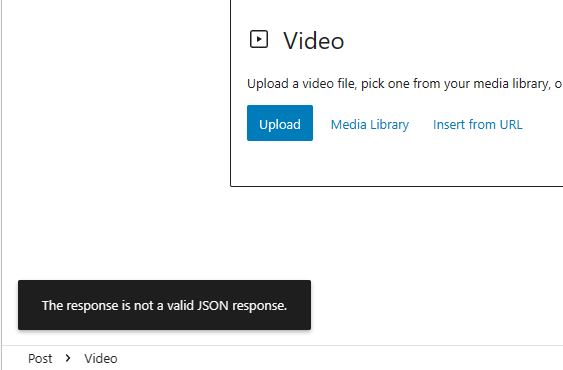
wordpress上传文件:The response is not a valid JSON response
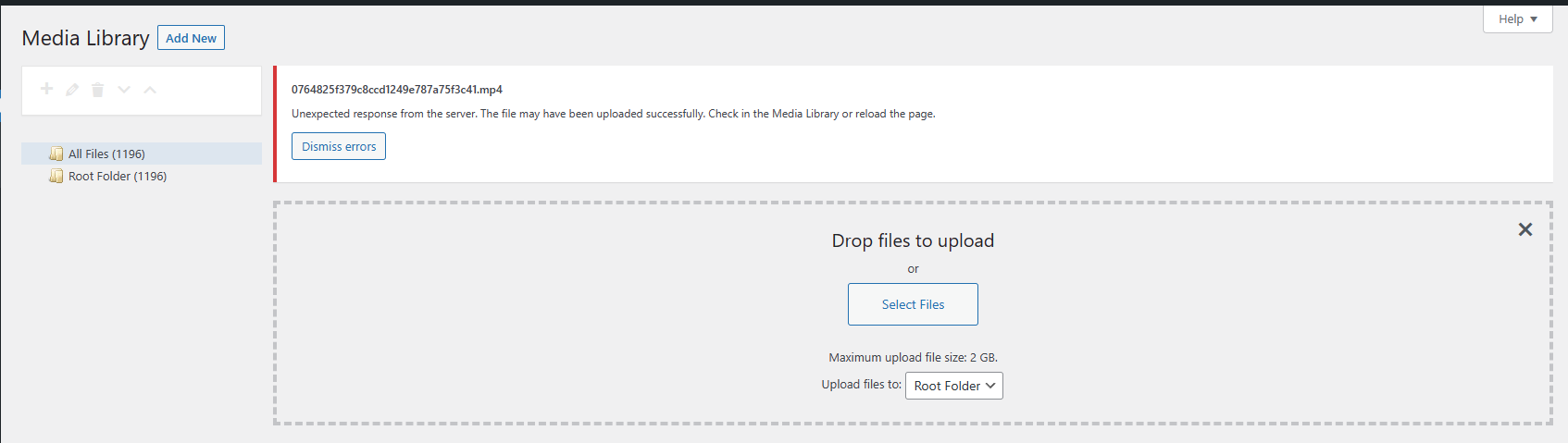
现象
wordpress媒体库中上传文件出错:
Unexpected response from the server. The file may have been uploaded successfully. Check in the Media Library or reload the page.同时,直接在文章页面上传文件也出错:
The response is not a valid JSON response
解决
wordpress默认会限制上传文件的大小,但我肯定不是这个问题,我很早就将这个限制修改了。
我在wordpress前使用了nginx做反向代理,问题也就出在这,解决方法:
在nginx的配置文件
http{}模块中修改最大允许的请求体大小client_max_body_size:http { client_max_body_size 256M; server{...} ... }重新加载配置文件或重启nginx即可
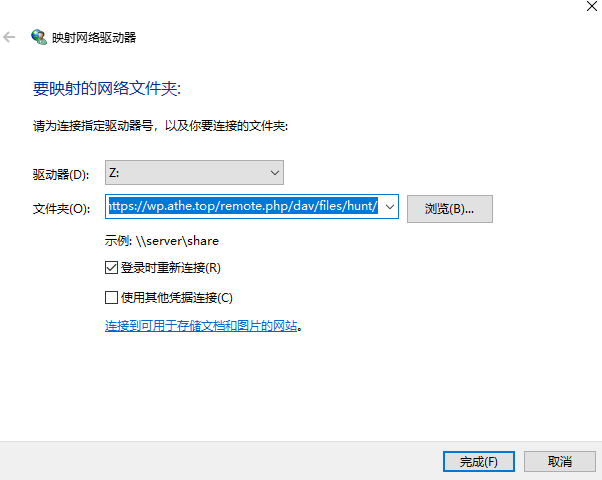
参考
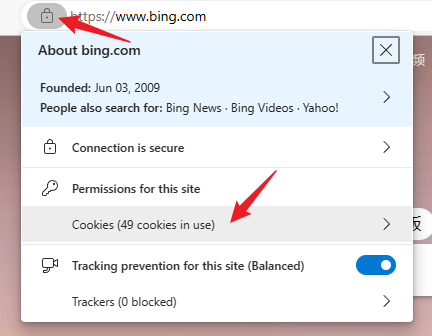
new bing 自动重定向到 bing
现象
已经申请通过newbing的情况下,在浏览器输入 https://bing.com/new 会自动重定向到 https://www.bing.com/
解决
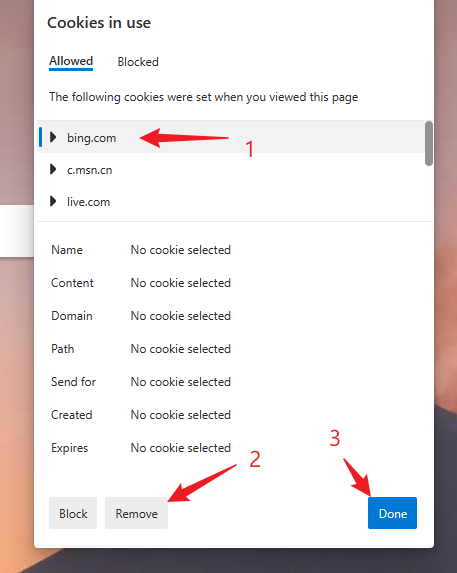
删除
bing.com的cookie
其他
注1:使用newbing需要挂梯子
注2:这种解决方法并非永久有效,过段时间又会出现这种情况,仍然这样操作一下就像
客制化键盘
所谓客制化键盘我觉得应该叫模块化键盘,因为其本质是将一个键盘分为 套件、轴体、键帽 三个部分,市面上有很多分别卖这三部分的零售商,所以你可以买回来自由拼接成一块完整的键盘。
键盘的分类
键盘有很多种分类方法,其中最影响体验的就是轴体分类、按键数分类和按键排布位置分类
轴体类别
薄膜键盘、机械键盘、静电容键盘等
按键数量
推荐一个网站:http://kle.geekark.com/,这个网站是用来设计键帽的,但可以选择各种不同的配列直观来看
100%尺寸,104或108键,全功能键盘。
80%尺寸,87键,去掉了数字区域。
75%尺寸,82/76键,将几个光标键整合到主键区。
60%尺寸,61键,只剩下主键区。
40%尺寸,42键左右,进一步压缩主键区,打数字需要按“Fn”切换。
Alice排布
alice排布是一种符合人体工程学的键盘排布方式,但比较贵,而且有些键帽(例如空格键、Shift等)不和普通布局通用
套件
套件是键盘的基础设施,简单说就是拔掉按键后剩余的部分,它是由外壳和pcb板组成,它规定了键盘整体的外观(除开键帽部分)、键盘的连接方式(有线、无线)等。
pcb
pcb版就是一块电路板,只不过上面没有焊接按键,自己买来插在上面即可,一般分为3脚的和5脚的按键,能插5脚的就兼容3脚的。有些pcb上会有rgb灯,有些可以后期手动焊接。
但是套件的整体结构(pcb与外壳的连接方式等)还会影响到敲击按键的声音(例如按下按键后可能会与外壳出现共振或者声音在壳体内反弹),所以衍生出很多不同结构的套件。
例如,最原始的就是直接将pcb板通过螺丝钉固定在外壳底板上,然后将买来的按键插在pcb上,按键都是一个一个插上去的,为了使得各个按键不容易晃动,还需要一块定位板。
定位板
定位板是一块硬质板,上面有和按键孔位相对应的按键孔,先将按键固定到定位板上,然后再统一插到pcb上,后面使用时按键就不容易晃动,同时,敲击按键的力也会传导到定位板上,就可能发出奇怪的声音。不同的人对这个声音有不同的追求,所以可以选择软硬不同的定位板,大致原理就类似于一个东西砸到钢板上和砸到塑料上这种感觉,有的声音大且脆,有的小但闷。
夹心棉/底棉
pcb和定位板是要夹在一起的,但它们中间一定会存在缝隙,那么就可能产生空腔音,一个解决办法是使用海绵等东西将这部分填充起来,没有了空腔自然就没有了空腔音。夹心棉就是其填充空腔的作用的。与之类似的还有底棉。
pcb固定到外壳底板上,则下面一定会存在一定的空隙,填充这一空隙的棉就被称为底棉
键盘中,所有的棉都可以认为是填充空腔用的,有空腔的地方就会有棉。
轴下垫
轴体固定在定位板上,然后使用轴体的引脚插在pcb上,那么在敲击按键时,震动就会通过轴体传播到定位板和pcb上。定位板必须和轴体硬连接,因为它需要起固定支撑的作用,但是轴体与pcb只需要金属引脚的连接,所以为了减小pcb板因为按键引起的震动,可以在pcb上覆盖一层缓冲物,而轴体的引脚会刺穿这个缓冲物连接到pcb上,当敲击按键时,轴体的震动就会被这层缓冲物吸收避免pcb震动,这层缓冲物就是轴下垫。
结构
一般来说,定位板和pcb是用螺丝固定在一起的,中间可能还有各种棉,它们可以看成一个整体,以下称为核心板。
核心板与外壳连接方式可以分为两种:
第一种就是将其直接通过螺丝与外壳硬质连接(有些连接在外壳的底板上,有些连接在外壳的上边框上)
第二种就是与外壳形成 下底板——核心板——上边框 的三明治结构,这种结构下,核心板是被压在中间的,所以可以通过在挤压部分添加缓冲材料(硅胶、泡沫、海绵等)来使得整个核心板在按压时是可以活动的。比较典型的就是gasket结构。
敲击键盘时,力会传导到核心板上,如果核心板与外壳硬连接,则可能发生共振,但如果是这种有缓冲的结构,则核心板的震动就会被吸收掉,听到的声音将是更纯粹的轴体音。
卫星轴
影响敲击声音的另一大因素是卫星轴
卫星轴本身并不属于某种轴体,也没有和pcb连接,它只存在于一些较大的按键下,例如空格键,正是因为卫星轴的存在,你才可以在那么长的空格键上敲击任意位置触发真正的轴体按下,它就像中心轴体的卫星一样,是联动的。
为了使得三者(两个卫星轴和一个中心轴)同时联动,两个卫星轴中间是有硬质铁丝连接的,按下一边时,铁丝将力传导到另一边,使得它们被同步按下,也正是因为这根铁丝,才给了客制化键盘很大的优化空间,因为铁丝会和按键摩擦,产生很多金属杂音,键盘好不好,和这个声音有直接的关系。
很多套件都是自带卫星轴的,但是有些自带的卫星轴很拉跨(去淘宝上看看套件的评价,很大一部分会和这个有关),所以很多人会选择另购卫星轴替换,或者买一些润滑脂涂在铁杆和卫星轴内壁上,减小摩擦增大润滑度。
轴体
常说的青轴、茶轴、红轴、黑轴等就是指轴体,一般以轴心颜色命名。
轴体大致分两类:线性轴和段落轴。线性轴就是轴中间就是一根弹簧,按起来比较肉,而段落轴则会多一个小机构,该机构可以使敲击按键像在按圆珠笔头一样,会有咔哒一下的感觉。青轴和茶轴就是典型的段落轴,红轴和黑轴就是典型的线性轴。
同一种轴体还可以在很多其他方面做文章,例如青轴的声音比较大,茶轴的声音比较小。如果使用的弹簧不同,还会影响按压的力度等等。
除了上面说的四种轴外,还有很多其他的轴,例如白银轴、金粉轴等,它们各自有各自的特点。
键帽
键帽就是最体现个性的部分了,网上有卖各种各样键帽的。需要关注的主要有:高度、材质、工艺、数量等
材质
键帽根据材质分类,主要分为 ABS和PBT
ABS的容易打油,例如用一段时间就变得油光水滑的
PBT的啥都好就是贵
高度
键盘的按键被划分为多个区域,不同类别的键帽,每个区域高度有所区别
根据每个区域高度不同,可以将键帽分为四类:XDA、SA、Cherry原厂高度、OEM高度。
其他
驱动是和套件相关的,能否支持自定义改键得看套件提供的软件驱动是否支持
它们还有自己的圈子,常去的有 装备前线,在这里,经常会有团长开团卖自己设计的键盘,优点类似于众筹的形式,通常付款后需要等几个月才能收到货。
%:取余 vs 取模
刚才发现,这个符号在python中表示取模,而在其他一些语言中,例如 Java、Javascript、Golang 等,表示的是取余。这两者有什么区别呢?
现象
计算下面这个式子:
-5 % 3 # 在 python 中,它等于 1 # 在 java 中,它等于 -2计算
优势
python中经常会有切片操作,取模则可以简化这一操作,例如取一个长度为5的数组中倒数第3个元素,最直接的做法为 arr[ -3],当然也可以写 arr[2 ]。事实上,如果你使用python计算 -3 % 5 你就能得到 2,正方向index和负方向index可以很轻易地转化。但是使用 java计算得到的却是 -3。
OAuth2.0的授权码方式
TL;DR:OAuth在很多地方都能遇到,例如单点登录、微信小程序申请使用用户头像、google Map申请访问google Drive等。其核心是要给第三方应用发放一个代表用户权限的token,以便于第三方应用可以直接使用该token访问用户资源。OAuth的主要目的就是如何安全地发放这个token。
背景
下面将以一个应用开发者的角度说明OAuth2.0的过程,OAuth2.0实际上有多种授权方式,这里介绍最常用也是最复杂同时也是最安全的授权码方式。
假如我要开发一款浏览相册的web应用,这个应用需要用到用户网盘中的相册数据。这里就出现了四个角色:
用户 —> 浏览器 —> 相册应用后台 —> 网盘提供商
浏览器负责展示,相册应用后台负责计算,网盘提供商负责提供数据
过程
申请Client_ID
首先我需要向网盘提供商申请一个 client_id 和 client_secret。这就好比,如果我作为第三方应用需要用到网盘提供商中用户的数据,那么我就应该提前在网盘提供商那里备案,否则,随便一个第三方应用都可以冒充我的身份去网盘提供商那里获取数据然后捣乱。
获取授权码
用户通过浏览器进入到我的系统后,此时因为我还没能拿到用户的网盘数据,我需要先让用户给我网盘数据的使用权限。具体方式为:跳转到网盘提供商专门提供的授权页面:
https://wangpan-authorization-server.com/authorize? response_type=code &client_id=8Ybgz6u_gCuEyuW2OokUuDh5 &redirect_uri=https://www.xiangce.com/authorization-code.html &scope=photo+offline_access &state=F0Pte-EQQ97NTw2o其中
wangpan-authorization-server.com为网盘提供商的授权服务器地址,进入该页面会先需要登录网盘账户,然后会弹出提示是否给相册应用权限
如果用户点击允许,则授权服务器会将页面重定向到
redirect_url页面,同时附上授权码参数code:https://www.xiangce.com/authorization-code.html? state=F0Pte-EQQ97NTw2o &code=EOC2fKbZ6d_fIkdNx9pXWs3-HB7ohhg_ppjNAE1oAZl4f4GK此时,浏览器就会将该code参数发送给相册应用后台。
注:
state是浏览器随机生成的一个字符串,用于防止CSRF攻击。不是本文重点,需要时再百度。获取token
相册应用后台得到授权码
code后就会发送一条post请求到网盘提供商的授权服务器,用于申请token:POST https://wangpan-authorization-server.com/authorize grant_type=authorization_code &client_id=8Ybgz6u_gCuEyuW2OokUuDh5 &client_secret=HIRDkHcvdK8FkucGDviXjFiIxdRiZiJ_proRt44IbtzfAx_c &redirect_uri=https://www.xiangce.com/authorization-code.html &code=EOC2fKbZ6d_fIkdNx9pXWs3-HB7ohhg_ppjNAE1oAZl4f4GK网盘提供商的授权服务器收到这个请求后,校验完参数就会将
access token返回给网盘应用后台{ "token_type": "Bearer", "expires_in": 86400, "access_token": "Ovkoc4dSjhc0IcXTG60ApSSQv8F6PRa5fBp-Cu4GjmCNDEuXU8XmXEk7sYHptNnbBAkjjpUw", "scope": "photo offline_access", "refresh_token": "vEmuz3SrhaYw8pyfGXU7gvEY" }应用token
有了
access token后,相册应用就可以将其加到请求头中,访问用户在网盘提供商中的数据了,例如,我想要获得某个网盘中的照片就可以用这个请求:那天,旅行者1号与太阳的距离和先驱者10号相同
先驱者10号(1972年3月2日)比旅行者1号(1977年9月5号)早5年发射,我们也应该知道它。
在2007年7月7日,先锋号和航海家号的位置和追踪。图片指出了航海家2号比先锋11号远并且由于其-55度的偏角只能表示在图片中的一个位置,而航海家1号则是因为太过于遥远而只能表示在图片中的另一个大略位置
先驱者10号(左)和先驱者11号、旅行者1号、旅行者2号的飞行轨迹
pytorch多卡训练的一些问题
多卡训练时的batch_size设置
问:假设我有4张卡,我将batch_size设置为64,那么是每张卡上都有64的batch同时训练,还是每张卡batch为64/4=16?
答:不管是dp还是ddp模式,batch_size都是单张卡上的batch大小,即每张卡训练的都是batch=64
我觉得挺奇怪,如果我是因为显存不足而使用多卡训练,模型中又有大量batch_norm,那么是不是这里的多卡训练就达不到我想要的效果?因为,如果对batch_norm来说,batch越大效果越好,则我希望是多张卡能够合起来组成一个大的batch,但实际上它还是几个小的batch单独计算batch_norm
当然,有需求就会有市场,batch_norm也是有跨gpu版本的,名为 SyncBatchNorm
DP vs DDP
dp和ddp的区别在于梯度计算的过程
当使用dp模式时,多张卡计算的loss结果会concatenate到第一张卡上,然后由这张卡计算整个batch的梯度,然后累加起来再求平均
当使用ddp模式时,每张卡单独计算这张卡上的mini_batch的梯度,然后再将所有的卡上的梯度求和,再除以卡的数量,这样一来就让每张卡上的梯度一样了,然后每张卡单独backward,因为每张卡的超参数都一样,且梯度一样,所以更新后的梯度也是一样的
学习率
使用多卡训练时,不需要刻意对学习率进行调整
参考
https://discuss.pytorch.org/t/comparison-data-parallel-distributed-data-parallel/93271
wordpress引用其他文章链接会创建一条新的评论
当我在一篇文章中加入了其他文章的链接,wordpress后台就会自动为引用的文章添加一个comment
这个东西并不是bug,而是feature,名为 “Pingbacks”
关掉这个功能很简单,进入到后台,找到 设置–>讨论–>pingbacks 和 notify 前面的勾去掉就行了
参考:https://wordpress.com/support/comments/pingbacks/#can-i-stop-self-pings
重启网卡后docker容器的web服务不可用
我使用docker部署了几个web服务,这些web服务会暴露出一些端口出来提供服务。
现象
如果我使用下面的命令重启了计算机网络
nmcli networking off && nmcli networking on则docker提供的那些web服务就不可用了
# 在宿主机中执行以下命令,8096是docker容器中web服务暴露出的端口 curl localhost:8096 > curl (56) Recv failure: Connection reset by peer但是,如果进入到容器内部发现服务确实是可用的
docker exec -it CONTAINER bash # 下面命令是在容器内执行的 curl localhost:8096 > <html>...</html>通过
docker ps命令查看容器确实正常运行的,也确实有把端口暴露出来排查
从上面的现象可以看出,服务运行是没问题的,那么问题肯定出在容器到宿主机直接的网络转换过程了,docker中容器同宿主机通信是建立在docker建立的虚拟网卡之上的
使用
netstat -rn或者ip r查看宿主机路由表时会发现没有docker创建的虚拟网卡,正常情况下docker会在启动时创建名为docker0的虚拟网卡,并且也会为每个桥接网络的容器创建一个单独的虚拟网卡:
这就说明应该是重启网络时,这些虚拟网卡都被清除了
解决
简单方式就是重启网络后再重启docker,它就会重新创建虚拟网卡
systemctl restart docker如果容器创建时没有指定
restart: unless-stopped参数,则还需要手动将容器启动从白噪声到柏林噪声
以前很好奇,为什么我的世界游戏本身就那么小,但是你却可以根据一个种子得到一个固定的地图,总不可能作者把每个种子都手动生成了地图然后保存吧,但是我随机输入一个种子都可以,那工作量也太大了,而且跟游戏大小相悖,后来了解到他可能就是使用了柏林噪声加随机种子生成的。
下面是从白噪声到柏林噪声的过程:
每个像素点完全随机生成的噪声就是白噪声
import matplotlib.pyplot as pltimport numpy as nppic = np.random.randint(0, 255, [256, 256])plt.imshow(pic, cmap='gray')plt.show()
这种噪声形成的图像色块之间的过渡十分生硬,一个办法就是将图像分块,只对每块的四个角随机生成灰度值,而块中间部分则使用双线性插值法(距离加权均值)填充灰度值
import matplotlib.pyplot as pltimport cv2import numpy as nppic = np.random.randint(0, 255, [8, 8], dtype=np.uint8)pic = cv2.resize(pic, dsize=[256, 256], interpolation=cv2.INTER_LINEAR) # cv2.INTER_LINEAR表示使用双线性插值的方式扩展plt.imshow(pic, cmap='gray')plt.show()
但是这种噪声看起来仍然非常生硬,特别是里面的高光部分,很规整,于是就想办法改进。
之前的做法就是在四个角生成一个随机数作为灰度值,然后在中间插入均值,这也是为什么这种噪声晶格感严重的原因,因为在单个晶格中,所有灰度值变化的梯度方向是相同的,就好像在这个格子中拉了一条渐变线一样。
解决的办法也是让各个灰度值梯度方向不同,现在,在每个顶点上随机生成一个向量表示颜色梯度方向。
可以将这4个颜色梯度方向的模长都设定为1,在计算晶格中间某个像素点的灰度值时,将P和Q两个向量(从同一个顶点出发的两个向量)计算内积,四个顶点都计算完后再累加就是该点的灰度值了,其中Q表示四个顶点到目标点的向量。
如此一来,噪声就不会像之前那样有很直的横线或者竖线
但晶格感还是很严重,所以真正给柏林噪声注入灵魂的是对原始坐标进行变换的“激活函数”(缓动曲线),它的作用就是让晶格的坐标点过渡更自然(见下方代码)
完整的柏林噪声代码:
import numpy as npimport cv2import matplotlib.pyplot as pltdef interpolant(t): """ 缓动曲线 """ return t*t*t*(t*(t*6 - 15) + 10)def generate_perlin_noise_2d( shape, res, tileable=(False, False), interpolant=interpolant): delta = (res[0] / shape[0], res[1] / shape[1]) # 8 / 256 d = (shape[0] // res[0], shape[1] // res[1]) grid = np.mgrid[0:res[0]:delta[0], 0:res[1]:delta[1]].transpose(1, 2, 0) % 1 # 只取小数部分,生成每个像素点坐标特征量 # Gradients angles = 2*np.pi*np.random.rand(res[0]+1, res[1]+1) gradients = np.dstack((np.cos(angles), np.sin(angles))) if tileable[0]: gradients[-1,:] = gradients[0,:] if tileable[1]: gradients[:,-1] = gradients[:,0] gradients = gradients.repeat(d[0], 0).repeat(d[1], 1) g00 = gradients[ :-d[0], :-d[1]] g10 = gradients[d[0]: , :-d[1]] g01 = gradients[ :-d[0],d[1]: ] g11 = gradients[d[0]: ,d[1]: ] # Ramps n00 = np.sum(np.dstack((grid[:,:,0] , grid[:,:,1] )) * g00, 2) n10 = np.sum(np.dstack((grid[:,:,0]-1, grid[:,:,1] )) * g10, 2) n01 = np.sum(np.dstack((grid[:,:,0] , grid[:,:,1]-1)) * g01, 2) n11 = np.sum(np.dstack((grid[:,:,0]-1, grid[:,:,1]-1)) * g11, 2) # Interpolation t = interpolant(grid) # 使用缓动曲线映射每个像素点坐标(不是真的坐标,只是坐标的一个特征量) n0 = n00*(1-t[:,:,0]) + t[:,:,0]*n10 n1 = n01*(1-t[:,:,0]) + t[:,:,0]*n11 return np.sqrt(2)*((1-t[:,:,1])*n0 + t[:,:,1]*n1)pic = generate_perlin_noise_2d((256, 256), [8,8])plt.imshow(pic,cmap='gray')plt.show()其中,缓动曲线的图形为(也可以选择其他的缓动曲线):
HTTPs原理
https核心目的是防止内容被篡改,核心方法是非对称加密
在http中,所有的信息都是明文传输,例如我要让服务器随机返回一个数字,整个过程如下:
如果有人想恶意篡改响应,就变成下面的流程了:
这种情况在以前很常见,很多时候你浏览一个网页时,页面中会塞满各种广告,但实际上服务提供商并没有加这些广告,而是网络运营商硬塞的,很恶心。有的时候也会非常不安全,因为可以使用这一方式制作钓鱼网站等。
所以,https的核心目的就是防止内容被篡改。一种较好的方式就是使用非对称加密。
服务器使用私钥加密内容后,客户端使用已知的公钥进行解密。在此过程中,黑客无法篡改内容,因为他没有服务器的私钥,无法加密篡改后的内容。
就好比你是一个攻击者,我告诉客户端一个随机字符串“sjdk”和一个公钥PubK,你拦截了该信息,并用这个公钥解密这个字符串得到数字5,但你不可能将这个数字5修改为8,因为你无法确定哪个字符串使用这个公钥PubK解密后能得到数字8。
但是,如果你连这个公钥都篡改了呢?譬如你拦截到信息后,使用自己的私钥生成数字8的加密字符串,并将这个字符串连同自己的公钥一同发给客户端。所以,这个问题就转换为如何保证公钥不会被篡改的问题。
如何保证服务器的公钥不会被篡改呢?
我不找服务器要它的公钥,而是找到一个可以信赖的第三方要这个公钥即可,这个第三方机构就是CA机构。
这样,即使黑客妄想篡改server返回的内容,他也无法篡改CA返回的私钥。
那么,如果他同时对两边进行篡改,即既修改server返回的内容,也修改CA返回的内容(server的公钥),可不可以呢?
理论上他无法修改CA的返回,因为CA返回server的公钥也是使用CA的私钥加密过的,客户端本地保存了CA的公钥,并且,这个公钥是随着操作系统安装一并保存的,或者由用户手动信任安装的,故可以认为CA的公钥是没有问题的,也就是可以认为CA返回的server公钥是没有被篡改过的。
由此可以说,你得到的server公钥没有被篡改,则使用该公钥解密的server的res内容也就不会被篡改了。
但实际情况和上面的流程还是有很大的区别的,但基本思路是一致的。server的公钥并不是由CA自己进行返回的,而是由server自己返回的,这是因为有了这种非对称加密的方式后,不论信息是由谁返回的,都可以保证信息是原始信息没有被其他服务器篡改过。所以一般的做法还是server从一开始就向CA申请一个证书,证书中会包含网站的信息(域名等)以及server的公钥,CA会使用自己的私钥来对该证书生成一个类似md5这种数字签名(注:只是对证书生成签名,里面的公钥仍然是明文,不会加密),然后返回给server保存起来,客户端申请和server建立https链接时,server就会将该证书返回,这里面也包括了CA生成的数字签名,客户端收到响应后使用本地已有的CA公钥来解密数字签名,然后使用同样的数字签名的方法对证书生成一个数字签名,对比自己生成的数字签名和CA公钥解密的数字签名就能判断这个证书是否真实有效,如果对不上或者本地没有这个CA的公钥,一些浏览器就会发出红色警告或者直接阻止用户访问以保护用户。
如果对上了,就使用证书里面的公钥加密要发给server的req,server就能通过它自己的私钥来解密这个信息。
这个过程中,就算黑客拦截了证书信息并妄想进行伪造,他也无法生成有效的证书签名
这里面的一个很大的问题就是,整个过程完全建立在对CA机构的信任上,如果CA机构被攻破,这个过程自然也就不安全了。其实任何CA机构(包括自建本地CA)的安全性都大差不差,之所以有些CA机构收费那么贵,其实本质上就是买了一份保险,保费越高,出了问题后的赔付也就越大。当然,还有一部分开销在于你向CA机构申请证书时,提供了一些信息(网站域名、主体等),越贵的CA机构对这个的审查就越严谨,这也是需要人工去完成的(便宜的或者免费的就不会用人工审查,而是使用 ACME 协议自动审查,例如使用DNS校验或者文件校验,Let’s Encrypt就是用的acme,总之,要验证这个域名确实是这个申请人的)
当然,这个加密和解密的过程其实相当复杂,对计算机来说也是一笔非常大的开销,所以https中并不会已知使用这种做法来传输信息,而是只有在建立https请求时,使用这种加密方式传输一个对称密钥,后续所有的内容都会直接使用这个对称密钥进行加密,这个过程就和http是一样的了。
注1:生成证书后一般会有三个文件(例如:Nginx反向代理wordpress开启HTTPS),它们的作用分别是:
xxx.crt: 证书文件,就算CA颁布给你的证书,最重要的就算它了
xxx.key: 你网站的公钥,客户端需要这个东西,它会和上面那个证书一同发给客户端
xxx.csr: 证书请求文件,你向CA申请证书时就需要给它这个文件,你需要提前使用自己是私钥以及网站信息生成好。相当于你要去办理业务时提交的材料。
注2:如果你看网上的一些生成本地CA证书的教程,会发现在生成证书签名时并没有使用到公钥,而是只用到了私钥
openssl req -new -key xxx_private.key -out localhost.csr这是因为私钥中其实也是包含公钥的,所以csr中同样也是包含公钥的,这样一来证书签名就是完整的(同时签名了网站信息和server公钥)
注3:CA机构也是具有层级关系的,每个CA机构也是需要上层CA颁发的证书的。最顶层的root CA则会自己给自己颁发证书。
注4:有的时候还会看到 .pem 文件,它其实就算一种文件格式。例如一般也会将私钥保存为pem格式,你就可以将其命名为:xxx_private.key.pem。
如果将 .crt .key .csr 比作期刊要求的内容格式(标题怎么写、正文字体等),则pem就相当于文档格式,如 doc pdf 等
注5:很多时候可能会看到 challenge 这个单词,它的意思就是做审查用的,即CA验证域名是不是你的,可以使用dns验证或者文件验证等方式
参考:
如何让localhost具备https(本地自签名):https://www.section.io/engineering-education/how-to-get-ssl-https-for-localhost/
自建本地CA:https://blog.csdn.net/weixin_40228200/article/details/121895791
csr中有公钥信息吗:https://security.stackexchange.com/questions/111136/where-in-the-csr-is-the-public-key
为什么模型训练这么吃显存?
现象
我有一个pytorch深度学习模型,模型本身不大,经过计算发现其自身只有约40 million的待学习参数量,大约仅需要150m内存就够了,但是我在一块有24g显存的显卡上训练时,很容易OOM,即使将batch size调整到刚刚能训练且不爆显存的大小,在backward阶段仍然会OOM,问题在于为什么这么小的模型却需要这么大的显存?
排查
搜索一番发现显存占用主要存在于4个方面:
模型参数(parameters)
模型参数的梯度(gradients)
优化器状态(optimizer states)
中间激活值(intermediate activations)
问题是它们会在什么时候才开始占用显存?会占用多大显存?
模型参数
模型创建时就会占用,占用大小为模型的 weights 和 bias 的总数。例如,创建下面这个线性模型:
self.fc = torch.nn.Linear(in_features=3, out_features=2)一共需要
(3+ 1) * 2 * 4字节的显存,其中 (3 + 1) 是3个weight和1个bias,将这个模型展开其实就是下面这个方程组:w11 * x1 + w12 * x2 + w13 * x3 = y1 w21 * x1 + w22 * x2 + w23 * x3 = y2这个占用大小一般都是固定的,不会在训练过程中变化
模型参数的梯度
这个会在backward调用时占用,这也是为什么训练的时候没用OOM,一backward就出错,所以设置batch size的时候应适当留一些显存用于存储梯度。
它占用的大小和模型参数相同,一个学习参数对应一个梯度嘛。占用大小也是固定不变的
优化器状态
会在 optimizer.step() 的时候占用,但是占用大小和具体优化器实现有关,例如,如果使用的是SGD,则其不会占用额外空间,但如果使用的是Adam,则会再额外占用2倍模型参数那么多空间,因为它还需要为每个参数保存两个梯度更新状态。
训练过程中占用大小固定不变。
中间激活值
这就是为什么这么小的模型需要这么大显存训练的原因,它会占所有显存的大头,但会在backward过程中(求导之后)被gc。并且其占用的显存会随着batch size的增大而增大。
pytorch中的unfold
torch.nn.functional.unfold
如果将卷积看作 滑动窗口+求和 的话,那么这个方法就是只有 滑动窗口 这一步了。
如图,a.unfold(0, 2, 1),表示在a的第0维以卷积核长度为2步长为1的方式开始取值。a的维度为(5,5),其第0维相当于行,所以图中是竖着取值的,最终得到维度为(4,5,2)的结果,因为a的0维只有5个数,而你要以步长为1两个两个地取,故只能取出4对,第二维中的5表示有5行,第三维中的2表示取出来的两个对。
假如要对二维图像进行卷积,卷积核要是二维的怎么做呢?则可以连续使用两次unfold(先对行卷,再对列卷)
注意两次unfold所在的维度是不同的,得到的结果就是维度为(4,4,2,2)的结果。
torch.nn.Unfold
nn包中的Unfold有点不同,它可以指定一个多维的卷积核,直观感觉上,它应该是直接将特征图中的每个像素点扩展成卷积核的感受野部分,比如直接将(2,3,3)的图像升维成(2,2,2,2,2)这种(第二维为channel,使用2*2的卷积核),但实际上并不是这样。
输入是(2,3,3)得到的却是一个(8,4)的矩阵。
其实这里除了滑动窗口外它还多做了两步
将滑动窗口得到的结果展平成1维数组
将多个channel得到的展平后结果进行拼接(想象n个channel上有n个窗口同时滑动,每次都将所有的滑动窗口拼接成一个长的一维数组)
所以结果维度中的8表示的是C * kernel_w * kernel_h(即文档中的 C*Π(kernel_size)),这是因为它表示的是将kernel得到的结果展平并拼接所有channel的结果,4则表示单个channel中可以卷4次。
要想得到预想的结果,可以直接再reshape成(2,2,2,2,2)就行。
另,Unfold的第二个参数 dilation 表示卷积空洞数量,想想空洞卷积是怎样的。
jellyfin、plex、emby、kodi
都可以用来搭建self-host stream media service,都至少支持web端和android端,以下为个人使用对比(均使用docker安装)
最不推荐的是plex,它需要连接官网账号才能用,并且android端体验极差,加载任何东西都很慢而且经常超时,貌似观影流量还是走了plex的转发,速度很慢,若要使用Android app还需要收费(终生30,否则只能看1分钟),就我体验了一下,基本可以说不可用的状态,而且它很多东西依赖官网服务,就不是完全self-host的service
jellyfin是最self-host的,完全不需要连接外部服务,所有的体验都很好,但它有个致命缺陷,就是当我观看某个电视剧时,我看完一集然后退出,下一次打开就需要手动找到上次看完的那集,才能继续看,它并没有提供resume play的功能,而且还没有观看历史(有活动记录),我觉得很不可思议,一开始我一直以为是我部署的问题,折腾了好久才发现,它就是没有。我架设这个东西主要就是看蜡笔小新,一季接近一千集了,我怎么可能每次还去找上次看到哪了。
目前看来貌似emby相对来说还不错,android免费,ios收费30元永久。它也有一个会员服务,不知道干嘛的,感觉事情并没有想象的那么简单。
另:连续剧的目录结构必须为 剧名 > S1 > 集,或者 剧名 > Season 1 > 集,注意中间的季名,规定死了,不能写成 第1季之类的。
kodi可以看成是一个播放器,但它可以设置网络路径源。但它天生就是为使用遥控器控制的电视开发的,电脑和手机使用起来非常别扭。它有一个优势就是使用客户端解码,上面说的emby等属于服务端解码(下面有说明什么是解码),对于大分辨率视频可能会很耗费服务器资源和带宽,而kodi直接将源视频发送给客户端解码再播放,压力就来到了客户端,画面会更清晰更流畅。
很多人会使用 emby + kodi 的组合,即创建一个资源文件夹并设置网络路径用于kodi,同时将该文件夹挂载到emby的资源文件夹目录,这样你上传一个电影到该文件夹后,emby会自动帮你做刮削(自动去网络上寻找这个电影的海报、字幕、简介等,然后保存到该目录下,事实上,刮削是plex、jellyfin、emby非常非常重要的一个功能,很多人用它们就是因为这个功能)。用户使用kodi观看时就能看到刮削的东西了。
- 什么是视频编码?
一般看到的 mp4、flv、avi 等属于视频的_打包_格式,它只是将视频(视频是没声音的)、音频等文件打包成一个文件。而这里面的视频、音频等文件又会有各自不同的编码。例如一个视频可能是 h.264、h.265、av1、vp9 等编码格式,所谓编码格式,可以理解为将原来一张一张的原始图片压缩成一些关键帧和变化帧的方法,这样可以对原始视频进行压缩打包,但是如此一来你就不能直接播放这些视频,必须使用解码器将这些变化帧还原成原始图像。所以你的视频播放器并不一定可以打开所有的MP4类型的视频,如果你的播放器没有h265解码器就不能播放使用h265编码的MP4文件。h265是一种比较新的编码器,播放器要使用它需要交授权费,但如果在项目中使用像ffmpeg这种开源实现就不用要授权,因为ffmpeg已经有授权了。我感觉我需要的东西很简单,你就搞个跟windows文件管理器一样的东西,然后能够记录播放历史,能在同一目录下根据名称顺序自动播放下一集就够了,怎么就那么难呢。
所有人都在仰望星空,但总要有人埋头苦行
好像在一瞬间,软件行业所有的目光都转向了AI,尤其是以ChatGPT为首的大规模语言模型。就好像原来散落的铁屑突然被一大坨吸铁石吸引了一样。已经很长一段时间,我打开github的trending,几乎全部都是GPT相关的东西了。
包括整个自然社会,随处可见关于这些语言模型的讨论。早先几个月,我看知乎热榜也是很多关于ChatGPT的东西,我的第一直觉是这东西像再被资本炒作一样。为什么这么说,我当然是知道ChatGPT有多神奇,毕竟我是它的免费用户,我也是DALL-E2的用户,可是这玩意在国内是被ban的呀,普通人根本就没机会体验和接触这个东西。那整个社会这么大的舆论究竟从何而来,大家都只知道喊这东西厉害,但都没用过,很典型的炒作行为。
ChatGPT我用得非常多,确实很好用,但也并没有说的那么夸张,它会犯很多错误,甚至很频繁的去编造一些事实,所以大多数情况下,我还是会使用搜索引擎去寻找答案。但动不动就来个颠覆传统颠覆世界,多少我觉得都有币圈的意思。我不否认它确实很厉害,也确实颠覆了我的认知,但我反感的是很多人啥都不知道就跟着一起盲目吹嘘,技术本应造福人类,而不应沦为资本运作的工具,人也不应该成为资本运作的工具。如果它可以颠覆世界,那就让它颠覆世界,疯狂去鼓吹有什么用,除了那帮人赚的盆满钵满外有可能又只剩一地鸡毛。
深度神经网络确实没什么门槛,作为业内人士去学习了解一下也无可厚非,但凡事我们都应该抱着一种理性的思考去看待问题,而不是一窝蜂无脑冲。更多的程序员更应该关注的是如何提升自己开发方面的技术,技术也应该是遍地开花而不能一枝独秀。空想的繁荣都是蜜罐,脚踏实地才能进步。
github周排行25个项目中,只有5个不是和ai有关系的。
Excel 高亮每行最大值
step 1: 选中要操作的区域
step 2: 选择“条件格式”中的创建规则
step 3: 选择“使用公式决定要格式的单元格”,并在下方输入
=B20=MAX($B20:$L20)
公式中,第一个B20表示区域的起始位置,MAX($B20:$L20)函数表示选择B20到L20最大值,要求最小值时就使用MIN函数,B20中的B表示第B列,20表示第20行,前面的
$表示锁定列这个位置,锁定后,当它向表格其他行填充时,仍然会锁定 B:L 这两个列的位置,行号由于没有锁定,所以会自动修改,例如到下一行就会自动变为 MAX($B21:$L21)基于锁定的特性,可以推出如果想要计算每一列的最大值,则只需要将公式修改为:
=B20=MAX(B$20:B$34)step 4: 点击“格式”按钮调整选中单元格的格式,我这里选择填充橙色背景
点击确定就好了
千万不要用ChatGPT写论文
本来想用ChatGPT生成论文的Introduction部分的,发现它还能自动生成一些引用信息,大喜过望之余我又让它生成Related work部分,很快它生成好了,并且带有相当多的example以及引用出处,写的那真是头头是道。我非常高兴毕竟这能省下相当多的精力。
今天想着去看看这些引用的原文,结果发现全都是编的,作者是编的,论文标题也是编的,啥都是编的。啊~
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver....
今天学校突然断电了一下,导致两台cuda服务器重启,其中一台重启就无法使用显卡了,使用
nvidia-smi就会报错:NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running经查,这是因为内核自动升级导致与原本的显卡驱动不兼容了
方法一:重装驱动
我的解决办法是重装驱动即可
# opengl是用于图形绘制的库,这里不需要 sudo ./NVIDIA-Linux-x86_64-515.76.run --no-opengl-files驱动下载地址:https://www.nvidia.cn/Download/index.aspx
如果在重装驱动时提示有显卡占用,但实际没有cuda程序在运行的话(例如桌面程序可能还在运行),可以使用以下命令解除占用:
# step 1: 停止图形用户界面并只保留基本的命令行界面 sudo systemctl isolate multi-user.target # step 2: 卸载Linux内核模块nvidia-drm,该模块是nvidia显卡驱动的一部分 # 或者使用 rmmod 也能卸载模块 sudo modprobe -r nvidia-drm # step 3: 安装驱动,如果这里还报上述错误,使用 `lsmod | grep nvidia.drm` 命令查看是否还没卸载,如果没有可以重启试试 # lsmod 命令用于在列出已经加载的所有内核模块 sudo ./NVIDIA-Linux-x86_64-515.76.run --no-opengl-files # step 4: 开启图形界面 sudo systemctl start graphical.target方法二:DKMS
简介
DKMS(Dynamic Kernel Module Support)是一个软件,需要手动安装。用来管理和维护一些原本依赖内核的模块,使得它们能够独立出来不再依赖内核版本。例如nvidia驱动就依赖内核版本,假如内核更新了则驱动就需要重新编译安装。但如果将这些模块交予DKMS来管理则会方便许多,他会自动检测系统内核,如果有升级它就会自动重新编译和安装它所管理的内核模块。
Post 3
Occaecat aliqua consequat laborum ut ex aute aliqua culpa quis irure esse magna dolore quis. Proident fugiat labore eu laboris officia Lorem enim. Ipsum occaecat cillum ut tempor id sint aliqua incididunt nisi incididunt reprehenderit. Voluptate ad minim sint est aute aliquip esse occaecat tempor officia qui sunt. Aute ex ipsum id ut in est velit est laborum incididunt. Aliqua qui id do esse sunt eiusmod id deserunt eu nostrud aute sit ipsum. Deserunt esse cillum Lorem non magna adipisicing mollit amet consequat.
为什么贝叶斯公式重要
公式
\[ P(A_i|B) = \frac {P(A_i)*P(B|A_i)}{\sum_j {P(A_j)*P(B|A_j)}} \ ]
举例
贝叶斯公式直观来说就是一个从已知推测未知的过程,这在日常生活中非常常见,例如警察破案就是一种典型的从结果(已知)推原因(未知)的过程。
某地警察发现一人死亡,调查发现此人很有可能死于某种毒品或某种药物,警察需要知道哪种可能性更大。以下为调查过程:
要计算分别死于某种毒品或药物概率——
后验概率 posterior probability调查发现此人生前吸食这种毒品和服用这种药物的概率分别为5%和90%——
先验概率 prior probability从医院统计获悉这种毒品致死率为50%,而药物致死率为9%——
条件似然 conditional likelihood此人一定死于毒品或药品的概率为 (50%*5% + 9%*90% = 10.6%)——
整体似然 total likelihood 又或者称为归一化因子,用来使得整体概率和为1此时拿出贝叶斯公式开始计算,以计算服用毒品致死的概率举例:
\[ P(服用毒品|死亡) = P(服用毒品) * \frac {P(死亡|服用毒品)}{P(死于毒品或药品)} \ ]
将上述调查数据带入上式得出 \( P(服用毒品|死亡)=5\\% \* \\frac {50\\%}{10.6\\%} ≈ 23.6\\% \\),同理可得 \( P(服用药物|死亡)=90\% * \frac{9\%}{10.6\%} ≈ 76.4\% \ ),计算此人更有可能是死于药物的,这是因为虽然此人吸食毒品,且毒品的致死率比药物要高很多,但因为此人吸食毒品的概率较低,所以可以得到这个结论。
但经过警察进一步的调查发现,死者生前非常亢奋,且已知吸食这种毒品引发亢奋的可能性为90%,而药物引发兴奋的概率为1%,则上述公式可更新为:
\[ P(服用毒品|死亡 U 亢奋) = P(服用毒品) * \frac {P(死亡|服用毒品)*P(亢奋|服用毒品)}{P(死于毒品或药品)} \ ]
得到 \( P(服用毒品|死亡 U 亢奋) = 5\\% \* \\frac {50\\%\*90\\%}{2.3\\%} ≈ 97.8\\%\\),而 \(P(服用药物|死亡 U 亢奋) = 90\% * \frac{9\%*1\%}{2.3\%} ≈ 3.5\%\),其中,\(2.3\%≈5\%*50\%*90\% + 90\%*9\%*1\%\ ),所以随着新证据的加入表明死者更有可能死于吸毒。
Wordpress: Maximum call stack size exceeded
在wordpress中使用古腾堡编辑器(Gutenberg)写文章点击发布后没反应,再次点击就一直转圈,查看浏览器控制台发现如下报错
我这里是因为
EditorsKit插件的问题引起的,将其禁用掉就好了
记一次模型训练速度优化的过程
优化之前每轮训练大概需要 3'10’’,优化之后大概只需要 35‘’
优化前
优化后
问题提出
我有一个图像异常检测的模型,训练过程很慢,且在训练过程中GPU的使用率剧烈波动,一会100%一会又降到0。我使用的是GTX3090 24G显卡,在MVTec数据集上训练,该数据集有15个类别,单卡全部训练完大约需要4天。
寻找原因
python或pytorch本身提供了一些性能分析的工具,但我担心并行环境下,一些方法执行耗时并不能反应真实的代码性能,所以我采用一种较为简单粗暴的方法:控制变量法。不断注释或修改某些函数,或者在死循环中执行某些语句,查看执行的速度和GPU占用。
一旦找到出问题的语句就能对该代码进行优化,手段包括但不限于:避免对tensor元素的for循环、tensor直接创建到GPU上、修改pytorch中Dataloader的一些优化参数等
下面是一个具体的优化过程:
我发现代码在loss函数上执行的特别慢,为了验证,我在loss计算和backward这里使用了一个死循环
注意:pytorch的backward计算是基于计算图的,默认情况下,执行backward之后就会删掉计算图,如果尝试再次backward就会报错,解决办法就是如图所示,加上 retain_graph=True 参数即可保留特征图
代码执行过程中发现,GPU利用率剧烈上下波动,可以肯定loss函数是出了问题的,追踪代码进入到loss函数的实现,可以发现它是由三个loss相加得到的,故还是一个一个注释看效果,前两个loss计算时,GPU基本能处于满载,但是到第三个loss时,GPU使用率又开始上下翻动,再进去查看实现,发现代码并不多
依然是给可能出问题的语句使用死循环执行,发现第455行和457行执行得极慢,且当代码执行到这时,原本满载的GPU很快就降到0了,与此同时cpu使用率开始增大。问题一定出在这。
torch.randperm(num)函数的作用是随机打乱一个序列,例如这里为了增加模型的鲁棒性,会随机打乱norm和anom两个矩阵中元素的索引。通过pytorch文档查询到该函数会返回一个随机序列的tensor,问题就出在这,如果没有指定device参数,该tensor将在cpu上生成,由于我这里要打乱的序列长度较大(亿级别),故cpu执行时,需要1~2s,而GPU则可以瞬间完成,故指定device为目标训练设备即可(这里是GPU)
结合一些其他的代码优化,模型训练过程中可以看到GPU基本一直处于满载状态,训练速度大大提升。
优化建议
tensor直接创建到GPU
pytorch提供的很多创建tensor的方法都会有一个
device参数用于指定tensor创建位置,可以直接指定创建到GPU。或者在cpu上创建tensor之后使用.to(device)函数复制到GPU上,显然直接指定device会好很多,免去了复制过程且避免使用cpu做计算,例如上面那个例子。记录一次排查服务器卡顿原因的过程
提出问题
今天在服务器上运行一个程序很慢,执行命令半天没反应,内存还有很多,cpu也并不高
寻找原因
通过top命令发现cpu等待磁盘io时间过长(wa表示io阻塞造成的cpu空闲与cpu总空闲时间比,一般来说若>5则应该引起重视)
swap分区
并且,我发现swap分区使用率一直为100%,猜测可能是交换分区导致的,因为我的实际内存较大(250g),还有很多没用到,故应该尽量使用物理内存。系统环境中有个变量
vm.swappiness可以用来控制物理内存与交换分区占用情况,可以使用命令sysctl vm.swappiness来查看,它的取值为 0-100,当取0时即尽可能使用物理内存,取100则表示尽可能使用交换分区,默认情况下是60,我这里直接将其修改为1,因为系统中有些程序必须要用交换内存,否则会出错。修改方式为:
临时修改命令:
sysctl vm.swappiness=1,立即生效,无需重启系统永久修改方案:修改配置文件
sudo echo "vm.swappiness=1" >> /etc/sysctl.conf,然后使用sudo sysctl -p使其生效但这样做之后,一段时间后物理内存使用率确实上去了,但情况并没有什么改善,所以应该不是交换分区io的问题。
iostat
iostat命令可以查看io的使用情况,使用该命令需要先安装
sysstat工具包sudo apt install -y sysstat使用
iostat命令可以查看当前磁盘io的使用情况,加上-x可以查看更多额外的信息,比如某磁盘的io利用率。这是相对空闲的机器io情况
这是较为繁忙的机器情况
可以看到卡顿的机器磁盘io很高,流量也很大,接下来去查看是什么应用导致这么大的io
可以使用
iotop命令来查看各个软件的io情况,需手动安装sudo apt install -y iotop。该命令的执行需要管理员权限gitattributes
简介
该配置文件可以控制git各种命令的行为。例如执行git diff时是否对比二进制文件内部差异,亦或者使用自定义的diff方法去对比文件,例如控制git如何去merge两个文件,还有个最常用的应用场景就是对换行符的处理,下面会提到。
.gitattributes文件的配置形式为:# 要匹配的文件 属性1 属性2 ... pattern attr1 attr2 ...例如:
* text=auto # 文件的行尾自动转换。如果是文本文件,则在文件入Git库时,行尾自动转换为LF。如果已经在入Git库中的文件的行尾是GRLF,则文件在入Git库时,不再转换为LF。 *.txt text # 对于.txt文件,标记为文本文件,并进行行尾规范化。 *.jpg -text # 对于`.jpg`文件,标记为非文本文件 *.vcproj text eol=crlf # 对于.vcproj文件,标记为文本文件,在文件入Git库时进行规范化,行尾转换为LF。在检测到出工作目录时,行尾自动转换为CRLF。 *.sh text eol=lf # 对于sh文件,标记为文本文件,在文件入Git库时进行规范化,即行尾为LF。在检出到工作目录时,行尾也不会转换为CRLF(即保持LF)。 *.py eol=lf # 对于py文件,只针对工作目录中的文件,行尾为LF。 *.bat text eol=crlf # 无格式的文本文件,保证 Windows 的批处理文件在 checkout 至工作区时,始终被转换为 CRLF 风格的换行符; *.bin binary # bin文件为二进制文件处理同gitignore一样,第一列为需要匹配的文件,可以为目录,当为目录时就是匹配该目录下所有的文件(不会递归匹配二级目录下的文件,这点和gitignore不同)
右边则为属性,例如上面配置文件中,text、eol、binary 均为属性,所有的属性都有4个状态:set、unset、unspecified、set a value
当为set状态时,则会设置该属性的值为true,例如上文中的 text 或 binary,该属性为true则会将匹配的文件视为text/binary文件处理。与之相反的状态为unset(视为text类型就能处理换行符,也就是下面的eol属性会生效,如果为binary则eol就不会生效)
当为set a value 状态时,则会使用该值,例如上文中的 eol,它用来配置如何处理文本文件的换行符,当它设置为lf时,它就会保证在git仓库中的文件结尾都为lf(如果原本时crlf则在提交到版本库时也会自动转成lf)
gitattributes提供了很多属性可以设置,其中就包含例如 text、diff、merge等,具体参见官方文档
体验一下zsh
linux人机交互使用的是shell,shell是一个统称,具体的,比如 sh、bash、zsh等,一般来说,linux都默认安装bash作为默认shell,mac默认为zsh,今天来体验一下zsh。
zsh在使用ohmyzsh进行配置后有很多很花的玩法,界面主题也花里胡哨,各种跳转补全啥的也花里胡哨
安装
ubuntu中可以直接使用命令安装:
sudo apt install zsh安装完成后,就能使用
zsh命令切换到zsh了,因为是使用bash打开的zsh,所以bash中的环境变量也会被zsh继承。当然,也可以通过以下命令将zsh设置为默认shell,这样的话下次再打开shell就是zsh了(例如如果没有设置默认,重新进入shell后又会回到bash):sudo chsh -s /bin/zsh配置
同bash有自己的配置文件
~/.bashrc一样,zsh也有自己的配置文件.zshrc,它们本质上都是一个shell启动时的执行脚本,关于shell的配置文件,详见这里(注:zsh并不读取/etc/profile环境配置,而是使用/etc/zsh/zprofile作为环境变量配置)zsh同bash一样,可以有很多自定义配置,但往往个人配置起来耗时费力,所以有个项目可以帮你减少这些配置 “ohmyzsh”,它实际上就是一个shell脚本,运行这个脚本之后它会替换掉你home目录下的
.zshrc文件,并且创建一些列文件夹用于保存要安装的插件、主题等。根据ohmyzsh官网说明安装很简单:
# 官网提供了很多种安装方式,但本质上都是下载一个shell脚本并执行 sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"执行完成后它会将你原本的
.zshrc文件重命名为.zshrc.pre-oh-my-zsh,并在home目录下创建一个.oh-my-zsh文件夹,里面存放zsh下载的主题、插件等文件,并创建环境变量$ZSH指向该文件夹主题和插件
安装ohmyzsh之后,打开
.zshrc文件,若要修改主题,找到变量ZSH_THEME,改变其值即可,可以修改的主题名详见这里,每个主题都有截图
若要安装插件,则找到
plugins变量,它是一个数组,将要安装的插件名写到里面即可(插件之间使用空格、tab、换行区分,不能使用逗号)。可以直接写名称的插件见这里(事实上,这些插件都已经下载好了并存放在~/.oh-my-zsh/plugins/目录下)有些插件不是官方提供的,可以直接将插件目录复制到
~/.oh-my-zsh/plugins/目录下,然后在配置种写上该名称即可。
推荐主题和插件
主题看很多人用的是 agnoster,安装这个主题之前通常还要安装一个字符集,不然显示可能不正常
sudo apt-get install fonts-powerline,vscode终端显示异常解决办法见下文插件一般安装:
git:在git仓库文件夹下会有很多关于git状态的提示
zsh-autosuggestions:这个插件可以在输入命令时,以灰色字体提示历史命令,免去了按
ctrl+r操作,需要下载后安装
下载插件到
~/.oh-my-zsh/plugins/目录下:git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions在
.zshrc的plugins中加上 zsh-autosuggestions 即可执行
source .zshrc使其生效注:由于有些终端(xterm或者screen等)默认只有8色,不支持很多其他颜色,故该插件实际显示效果上会有bug,解决办法:在
~/.zshrc中加入下面这段代码修改默认终端:# 原本为 xterm/screen,现修改为xterm-256color将支持更多颜色,可以使用 tput colors 命令查看支持颜色数量 export TERM=xterm-256color
期货ctp配置
贯通期货:
APPID:client_jzqt_1.0.0
授权码:LE5WF4FXUSCLUFVZBROKEID: 0037
服务器地址 端口
看穿式前置front_se
上海电信:
交易1:101.231.208.152 41208
行情1:101.231.208.152 41215交易2:180.166.134.102 41208
行情2:180.166.134.102 41215
看穿式前置front_se
上海联通:
交易1:112.64.149.72 41208
行情1:112.64.149.72 41215
交易2:140.206.103.92 41208
行情2:140.206.103.92 41215jellyfin流媒体搭建
官网有docker安装教程:https://jellyfin.org/downloads/docker
但是我没有使用docker run 命令运行,而是采用了 docker-compose 的方式
docker容器部署在旧笔记本上,使用frpc连接到百度云服务器,云服务器上再使用nginx docker容器进行转发,基本过程为:
http://stream.woyou.cool —> nginx —> http://frps:8896(云服务器的docker内部) —> 旧笔记本的frpc端口 —> 旧笔记本的8896端口 —> jellyfin docker容器
docker-compose.yml文件用于创建jellyfin容器,在旧笔记本的 /home/hunt/Documents/docker_properties/jellyfin 目录下,内容为:
version: "2.1" services: jellyfin: image: lscr.io/linuxserver/jellyfin:latest container_name: jellyfin environment: - PUID=1000 - PGID=1000 - TZ=Etc/UTC volumes: #- /home/hunt/Documents/docker_properties/jellyfin/volumes/config:/config #- /home/hunt/Documents/docker_properties/jellyfin/volumes/data/tvshows:/data/tvshows #- /home/hunt/Documents/docker_properties/jellyfin/volumes/data/movies:/data/movies - /home/hunt/Documents/docker_properties/jellyfin/volumes/data/:/media ports: - 8096:8096 restart: unless-stopped在该配置文件下创建好 volumes/data 目录,然后执行
sudo docker-compose up -d即可创建并运行容器然后修改旧笔记本上 frpc 的配置文件:/opt/frp_0.44.0_linux_amd64/frpc.ini
[common] server_addr = woyou.cool server_port = 7001 tls_enable = true #protocol = kcp [jellyfin] type = tcp local_ip = 127.0.0.1 local_port = 8096 remote_port = 8096 use_compression = true云服务器需要在nginx的配置文件中加上jellyfin的server项
路由过程
基本过程
数据包从主机1.1.1.1发送到目标主机5.5.5.5的过程
首先从初始网关(一个路由器)中查找路由表,路由表形式如下(windows下使用
route print查看):
注:网关中的“on-link”表示该目标网络和该主机存在同一个子网下,不需要经过路由转发
根据前两列(目标网络和网络掩码)确认目标主机应该从以哪个接口(第四列,下面有解释)发送给哪个网关(第三列,即路由的下一跳地址)
路由表的第一行为默认网关,如果在下面的路由表中找不到对应目标主机的网络记录,则发送给默认网关,后续的路由过程也是如此
例如一般本机的路由表中都只会记录局域网的路由记录,如果是发送数据到公网或其他局域网的主机,一般都是走默认网关,可以使用
tracert destination-ip查看路由过程(一般默认网关ip都是一1结尾,下图中可以看到先走了两次默认网关)
如果有多个匹配的目标网络地址,则根据最优匹配规则(最长前缀等)及路由表的Metric列(数值越小,路径越短)选择最合适的网关进行发送
当然,网关只是一个ip地址,属于传输层,它还需要根据ip地址找到mac地址才能进行发送,这里就是arp协议的功能了
网关 vs 接口
一台路由器或主机可能通过交换机连接着多台路由器,每个路由器都可以看作是下一跳的备选地址,具体选择哪一个就是根据目标网络和网络掩码决定。在路由表上的体现就是根据前两列找到某一行,第三列网关就是下一跳路由器的地址。
一台主机可能有多张网卡,所以就会有多个ip地址,例如,你本机可能和校园网在一个子网,则校园网会给你分配一个ip。你在主机上使用VMware使用“仅主机”的网络模式开启了其他的虚拟机,则你的主机又和这些虚拟机组成一个局域网,它又会给你分配一个ip。如此你的主机就会有两个ip,路由表中的接口作用就是说,数据包在发送给网关时,选择使用哪个ip。
路由器 vs 交换机
交换机:有6台主机要相互通信,则需要使用 6*5=30 根网线将它们连接起来,但是如果用交换机的话,则每台主机都只用连在交换机上,当两台主机要进行通信时,交换机负责将它们连接起来。这样就只需要6根网线。交换机的数据转发是基于mac地址的,它会维护一个mac地址与端口的映射表。
路由器:同一个子网之间通信不需要路由器,只用交换机就行了,路由器只有在数据包发送给其他局域网时才会有作用,路由器一般有两个或多个网络接口,分别连接多个子网,找到数据包下一跳接口的过程就是路由。
若一个网络没有路由器而只有交换机,主机之间也是可以通过ip进行访问的,例如某台主机具有dhcp的功能,则其他主机会先广播找到dhcp服务器的mac地址,然后将自己的mac地址发送给dhcp服务器,它就会返回一个ip。或者也可以手动配置静态ip等
同服务器一样,你应该将路由器看作是一个软件而不是硬件,任何主机都可以做路由器,就像任何主机都可以做服务器一样,只不过主机上安装的软件不同,我们对它的叫法也就不同
网关 vs 路由器
网关只是一个统称,所有流量需要经过的地方就是网关,路由过程中,下一跳的路由器就是一个网关。但在路由表中,网关又被具体化成下一跳的路由地址。
Q&A
如果路由过程中,某路由器存在多个符合条件的路由记录,它们的优先级相同,数据包会如何发送?
数据包被复制成多份并同时发送给这些符合条件的网关路由,由于它们具有相同的目标网络地址,则当它们到达目标网络的路由器时,路由器会自动去重,保证只有一个数据包发送给目标主机
自动去重的一种解决方案:网络设备维护一个长度为100个数据包缓存的队列,当新的数据包到来时,其和队列中的数据包进行hash比对,若存在则将其丢弃,不存在则弹出队列头部的数据包,并将新数据包添加到队尾路由表如何更新?
路由表可以手动修改(静态路由)也能自动更新(动态路由)。它使用动态路由协议来自动更新路由表,例如rip是一种动态路由协议,它规定每过30秒就和相邻的路由器同步路由表。当同步次数足够多时,所有的路由表都会收敛成定值(排除网络环境的变化)。路由表会不会无限增大?
不会,它可以根据一定策略更新本地路由表,而不是盲目地把所有拉取的记录都保存下来,例如跳数过多的记录就不会被保存
第1个路由器拉取第2个路由器的路由表,第2个路由器拉取第1个和第3个路由器的路由表,如此持续下去并且不停迭代,若不加以限制,所有的路由器中的路由表都会变成一样的(每个路由器的网关还是不同的,因为单个路由器的路由表中的网关只能是其相邻路由器的地址,所以即便第1个路由器最终会有第99个路由器的网络记录,但该记录的网关还是第2个或其他相邻路由器的地址,但此时跳数为98),但跳数是不一样的,故如果跳数过大,则不进行记录路由表会不会形成环路
会,但可以尽量避免,即使形成了环路,也会有一定的检查和修改措施,这些都是自动完成的ctp穿透测试过程记录
以冠通期货为例子(windows11):
根据期货经理发过来的文档进行申请即可:https://mp.weixin.qq.com/s/L5p5QiPj61WGzd2dcEsccA
在贯通期货app里面有个“掌厅 –> 外部信息系统接入申请”
按要求填写,或者直接按照文档中的示例填写,完成后需要阅读四个协议并署名。然后等待审核
这期间你可以准备ctptest软件,这里使用vnpy,去其官网下载并进行安装,安装过程需要python环境,可以使用conda
官网有两种安装方式,如果选择手动安装则在安装结束后再手动安装
pip install vnpy_ctptest见:https://toscode.gitee.com/vnpy/vnpy_ctptest/
在vnpy的 vnpy-3.6.0\examples 目录下创建一个veighna_cpttest目录并在其中创建一个run.py文件,内容如下:
from vnpy.event import EventEngine from vnpy.trader.engine import MainEngine from vnpy.trader.ui import MainWindow, create_qapp from vnpy_ctptest import CtptestGateway def main(): """主入口函数""" qapp = create_qapp() event_engine = EventEngine() main_engine = MainEngine(event_engine) main_engine.add_gateway(CtptestGateway) main_window = MainWindow(main_engine, event_engine) main_window.showMaximized() qapp.exec() if __name__ == "__main__": main()然后使用 python ./run.py 就能运行了。
审核通过后期货经理就会把申请得到的一些信息发给你,对应填写在vnpy的ctptest软件上,得到的信息如下
由于它们的系统要求api版本必须为6.3.13_T4,故我这里需要做替换掉原来的dll和lib
https://files.woyou.cool/s/3fcTEoCx6PDZFRs
找到vnpy_ctptest包的路径,例如我这里是“C:\Users\zouhe.conda\envs\vnpy\Lib\site-packages\vnpy_ctptest\api”,将原来的dll删除或重命名,并将需要的版本拷贝进来
然后点击vnpy的连接按钮,左下角就能看到验证成功的信息
参考:
贷款的利率和利息
贷款有两个重要的考量因素:利率和利息
利率
现在实行的是
LPR利率,什么是LPR利率?商业银行对企业或个人房贷都需要锚定一个基准利率,这个基准利率是由央行决定的,即MLF利率。MLF利率反应了央行对市场的调控,例如若要刺激经济则降低它,人们就会多贷款少存款用于消费(MLF利率实际是央行贷款给商行的利率)
不同的商业银行可能服务的侧重点不一样,于是它们又联合讨论出一个调整因子,用于对MLF利率进行微调
由于个人或企业的资质不同,所以商业银行针对每个贷款单位还会设置一个单独的
加点所以:房贷利率 = MLF利率 + 调整因子 + 个人加点,前两项之和就是
LPR利率。因此:房贷利率 = LPR + 个人加点LPR每月20日(遇节假日顺延)对外公布一次,目前包括1年期、5年期以上两个品种。LPR根据定价周期变动,但是个人加点不变。
例如:最新公布的lpr利率 2023/01/20:1年期3.65%,5年期以上4.3%,我的个人加点为0.5%,房贷一般使用5年期利率,则该月利率为 4.3%+0.5%=4.8%
还有一种固定利率,如果你长期看涨lpr利率,则可以选择固定利率,例如固定为5%,以后就不会变
利息
利息支付方式分为
等额本金和等额本息等额本金
就是你每个月偿还本金不变,但利息会随着贷款额的减少而减少
例如贷款12万,分12个月偿还,年化利率为4.8%(则月利率为0.4%),则每个月固定还1万本金加上剩余贷款额的利息。例如:
第一个月:1w + 12w * 0.4% = 10480
第二个月:1w + 11w * 0.4% = 10440
第三个月:1w + 10w * 0.4% = 10400
。。。
可以看到每个月的还款额呈等差数列递减(利息逐渐减少)
等额本息
就是你每个月的还款额都不变,这其中就包含本金和利息
还是上面的例子,假如使用该方式还款的话你每个月固定还款 10261.9元,具体计算方式可以使用房价计算器
等额本金和等额本息只是两种计算方式,实际上对最终的中利息是没有多大改变的,如果希望每个月还款额固定,则可以选择等额本息,等额本金则会让你前几个月比较吃紧
贷款的年化利率如何计算?
假设贷款30万,月费率0.5%,分60期,等本等息,实际年利率是多少?
是月费率0.5%*12=6%?不是的
实际年化利率为10.85%
费率转利率的计算方法较为复杂,一般使用软件计算。但有一种大致的速算法:
月费率 * 12 * 1.85
即:0.5% * 12 * 1.85 = 11.1% ≈ 10.85%《权力的游戏》观后感
听说很好看,目前第五季看完,我觉得一般,并且不会继续往后看了。
首先一点是人物关系,虽然我看到第五季,但除了剧中频繁出现的那几个人我能对应出名字外,绝大多数人名我都不能第一反应出是谁,看到后面也能知道个大概人物关系,但前期确实很费劲,人物关系太复杂了,而且是几条线同时叙述,不适合我这种不带脑子看的。今天也去翻了翻一些影评,更是懵逼,什么猫娘、小剥皮什么什么的各种外号,更是不知道谁是谁了。
再一点就是剧情,首先就是剧情的各种出乎意料,人物说死就死,我也是看到中间才想起来以前听人说这个剧没有什么主角光环,之前还浓墨重彩刻画出的形象,可能一个转身就没了。这确实会给人意料之外的感觉,但有的时候确实让人很气,这就是下面一个槽点。
我觉得如果这个剧是国产剧的话,它应该归为苦情剧一类。就是那种我明明知道你是好人,我偏偏不让你好过,反而让坏人耀武扬威。我觉得如果这部剧真配得上它的名声的话,至少人物刻画不能这个片面,大反派仿佛都是恶魔降生,一举一动都单纯透露出恶,编剧导演可能希望籍此来吸引人,让人们期望他们不得好死。有些人真是死的莫名其妙,那个弗什么的king,作恶好几季,吃个饭莫名其妙毒死了,我第五季看完了我还是没搞明白小指头和那个老婆婆弄死他的目的,而且怎么弄死他不行,偏偏在婚礼上,那么多人情况下下毒。相比较而言,那个罗伯虽然也是婚礼上突然被杀,但事后来看确实也有那么一点合理性。还有瑟曦的女儿,嫁给的那个国家具体什么情况我还是没整清楚,就知道他们和她的家族原本有仇,后联姻结盟,她女儿我印象中就没出场多少,就那样死了,以至于我连那个女的为什么要杀她都没搞清楚,整得我以为她会有什么很重要的剧情一样,就很莫名其妙,想起来了,是因为他们一个什么王子在对决的时候被爆头了,但还是觉得莫名其妙,人死得莫名其妙,剧情莫名其妙。
再者,我觉得可能是文化差异,欧美那边人看这个剧的感觉肯定和国内人看这个感觉不一样,就好比国人看星球大战,他们看西游记一样,如果没有文化背景看起来肯定都是一脸懵逼,但总有些尬吹尬黑的。就比如日常生活中,看到一些人说自己多喜欢光剑,多么炫酷啥的,总让我觉得有些浮夸,怎么没见哪个外国人拿个金箍棒在街上到处跑的。
回到这个剧,听人说后面烂尾了,我也看了一些影评,对后面有一定的剧透,有些剧情确实离谱。
在家或者外面我还不敢看这个,时不时蹦出个限制级镜头,要是恰巧被不了解的人看到,多尴尬。并非批判,而是如果对于推进剧情用无可厚非,如果是单纯用作吸引人眼球引发舆论则大可不必,毕竟我是带着看剧休闲的想法看这个剧的。
前面也看过几级纸牌屋,看得不多,人物关系还不太清楚,所以对我吸引还不大,后面再看什么。
Post 2
Anim eiusmod irure incididunt sint cupidatat. Incididunt irure irure irure nisi ipsum do ut quis fugiat consectetur proident cupidatat incididunt cillum. Dolore voluptate occaecat qui mollit laborum ullamco et. Ipsum laboris officia anim laboris culpa eiusmod ex magna ex cupidatat anim ipsum aute. Mollit aliquip occaecat qui sunt velit ut cupidatat reprehenderit enim sunt laborum. Velit veniam in officia nulla adipisicing ut duis officia.
Exercitation voluptate irure in irure tempor mollit Lorem nostrud ad officia. Velit id fugiat occaecat do tempor. Sit officia Lorem aliquip eu deserunt consectetur. Aute proident deserunt in nulla aliquip dolore ipsum Lorem ut cupidatat consectetur sit sint laborum. Esse cupidatat sit sint sunt tempor exercitation deserunt. Labore dolor duis laborum est do nisi ut veniam dolor et nostrud nostrud.
Post 1
Tempor proident minim aliquip reprehenderit dolor et ad anim Lorem duis sint eiusmod. Labore ut ea duis dolor. Incididunt consectetur proident qui occaecat incididunt do nisi Lorem. Tempor do laborum elit laboris excepteur eiusmod do. Eiusmod nisi excepteur ut amet pariatur adipisicing Lorem.
Occaecat nulla excepteur dolore excepteur duis eiusmod ullamco officia anim in voluptate ea occaecat officia. Cillum sint esse velit ea officia minim fugiat. Elit ea esse id aliquip pariatur cupidatat id duis minim incididunt ea ea. Anim ut duis sunt nisi. Culpa cillum sit voluptate voluptate eiusmod dolor. Enim nisi Lorem ipsum irure est excepteur voluptate eu in enim nisi. Nostrud ipsum Lorem anim sint labore consequat do.
Ubuntu22安装MySQL8
安装
首先更新一下源
sudo apt updatesudo apt upgrade比较慢或者常报网络错误可以使用国内镜像,使用方法和镜像地址见:https://mirror.tuna.tsinghua.edu.cn/help/ubuntu/
安装很简单,一条命令即可
sudo apt install mysql-server启动MySQL
sudo service mysql start至此,有些教程会说 执行
sudo mysql_secure_installation命令,但其实在测试环境中,这个命令不是必要的,并且它默认使用 auth_socket 这个密码插件,这个插件可以让你不需要密码登录MySQL,所以会让你觉得困惑,我怎么都不用设置root密码?所以我建议先跳过这一步,待下面的步骤都走完了,再执行这个进行安全设置也不迟注:auth_socket是一个密码校验的插件,它可以让你使用本机用户登录MySQL,另外还有 mysql_native_password 以及MySQL8中默认的 caching_sha2_password,这俩就需要设定密码。参见:https://kohasupport.com/what-is-the-difference-between-mysql-plugins-mysql_native_password-caching_sha2_password-and-auth_socket-plugins/
修改配置使得其可以远程访问
这点很重要,默认只能本机访问,我一开始觉得很纳闷,明明我创建了可以远程访问的账户,但依旧是无法访问,后来发现这里没改
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf将原本的
修改为
其中 0.0.0.0 表示任何主机都可以访问,也可以将其改为指定的主机
初始安装MySQL后,root不需要密码,可以直接使用下面的命令进入MySQL-CLI
sudo mysql修改root密码
alter user 'root'@'localhost' IDENTIFIED WITH mysql_native_password by 'yourpassword';修改完成后,退出MySQL-CLI,再进入的话就需要root密码了,使用以下命令进入
mysql -u root -pyourpassword注意,仅在做实验测试的话可以直接将密码写出来,-p后面直接跟密码,不需要空格
创建用户
此时还不能远程访问,因为目前的root用户为 ‘root’@’localhost’,即仅为本机可以访问,最佳实践是创建一个新的管理员账户
create user 'hunt'@'%' identified with mysql_native_password by 'yourpassword';主机部分使用 % 即表示该用户可以从任何主机访问
其中 with mysql_native_password 表示使用 mysql_native_password 这个授权插件进行密码校验,可以不要该部分,在MySQL8.0环境下,默认使用的是 caching_sha2_password 这个密码插件,它更安全但是较慢。
linux下用户名太长被用加号代替
ps命令
linux中 ps 命令输出,如果用户名很长则会只显示部分名称,后面用一个 “+” 代替
BSD语法允许我们修改输出格式,而 ps 命令支持该语法(以下描述来源 man ps)
例如,以下命令就能修改 ps 命令输出中的 user 列显示长度:
# 命令中的20表示user列最长显示20个字符 # -O表示将默认的其他列也显示出来,也可以使用 -o,则只会显示指定的列,例如该命令则只会显示user列 ps ax -O user:20 # 或者这个命令 ps ax -O ruser=WIDE-RUSER-COLUMN
参考:https://askubuntu.com/questions/523673/ps-aux-for-long-charactered-usernames-shows-a-plus-sign
top命令
top命令下名字太长也会被用+代替,解决办法是:进入top后,按下
X可以调整每列显示的宽度,输入一个合适的数,比如3 即可
用户名被用+代替
将列宽增加3个单位
Ubuntu22 Xorg占用Nvidia显卡问题解决办法
刚配置完一台cuda服务器,使用 nvidia-smi 命令看到每张显卡上都有一个 xorg 程序,这是 linux 下的桌面程序。我希望 xorg 使用核显就行,而独显专门用于模型的训练。以下为操作步骤:
任意切换到一个 tty 终端:
init 3创建 xorg 配置文件
# 该命令的作用是,如果你想修改 xorg 的默认配置,该命令会自动帮你生成一套配置文件模板 # 官网解释:https://www.x.org/wiki/ConfigurationHelp/ Xorg -configure它会在
/usr/share/X11/xorg.conf.d目录下生成一系列配置文件,其中有个nvidia-drm-outputclass.conf文件,该文件用于自动检测并使用nvidia显卡程序。将其删除或者改名即可mv nvidia-drm-outputclass.conf nvidia-drm-outputclass.conf.bak重启系统就行了
我在网上看到很多人说修改
/etc/X11/xorg.conf也行,但据说会有壁纸显示的问题,我没试过本文参考:https://blog.csdn.net/xiaohaier8593/article/details/122852810
pytorch保存特征图
pytorch子项目torchvision提供了用于保存tensor为图片的方法
torchvision.utils.save_image
其中,参数tensor的维度为(batch_size, channel_size, H, W) 或者 (channel_size, H, W) 或者 (H, W),fp则为文件保存路径
注意:该处batch_size应该为同类图片的张数,而channel应该为单张图片的通道数(例如灰度图为1,rgb图为3),而不是你训练的batch size,也不是特征图的通道数
事实上,当输入tensor为minibatch时,其内部还会调用
torchvision.utils.make_grid方法对所有的图片合成一张大图
在
torchvision.utils.save_image参数中,可以直接使用kv的形式传递torchvision.utils.make_grid的参数,通过save_image的源码可以看到,它是直接将后面的参数传递给了make_grid,由此你就可以在save_image方法中调整拼接图的间距(本该是make_grid的参数)
示例:
# 将上一个模型得到的特征图x保存下来 # x的第一维是train的batch size,每一个batch并不属于同一个物品,故将每个物品的特征图单独保存(单独取出每个train的batch) # 每个物品的特征图有很多,每个特征图又是一张单独的灰度图,故将特征图的数量作为save_image的batch_size,而每张图是单通道的灰度图,故给每张图都增加一个维度用于表示其通道数为一维 # nrow 用于指定每一行并排拼接多少张图片,为了让整个大图看起来更方,这个就用特征图数量的开方 torchvision.utils.save_image(x[0].unsqueeze(1), r"D:\Tmp\feature.jpg", nrow=int(math.sqrt(x.shape[1])), padding=8)结果就是本文最开头的那个图片
莫尔斯电码解惑
如何区分字符和单词边界
通过间隔时间长短区分。字符用3个间隔时间,单词用7个间隔时间
出错了该如何修正
古老的做法是在错误的单词后面敲出8个
".",但是这样听起来很突兀,所以现在更一般的做法是敲两个i,即".. ..",例如:# how r u today .... --- .-- .-. ..- - --- -.. .- -.-- # how r u todax ii today .... --- .-- .-. ..- - --- -.. .- -..- .. .. - --- -.. .- -.--但是很多情况下是会直接忽略这些错误,毕竟超收人也能明白你的意思,并且一般一条消息会重复多次发送,你后面发对就好了
中文怎么发
类似unicode编码,先将所有中文编码成四位或六位数字,然后发送数字即可,抄手方根据数字再查表,这样做唯一的好处是不用中间停顿了,可以像机关枪一样一直发(如果中间参杂着字母或符号还是要停)
反正是要查表,所以它还有个好处,就是能做对称加密
除此以外,一无是处
怎么不用哈夫曼编码
哈夫曼编码有很多好处,可以给常用的字符分配更短的编码,节省发送字节数。并且哈夫曼编码不需要分隔符,可以连续发送。
那为啥不用哈夫曼编码呢,以下为我自己的理解
首先,哈夫曼编码虽然可以根据频次给字符分配最优前缀编码,但其单字符编码长度依旧是很长的,莫尔斯编码相比就短很多。
并且哈夫曼编码的容错率太低了。由于哈夫曼编码不用分隔符,它更适用于环境相对稳定的场景,例如计算机之间的通信。计算机有很多纠错机制,使得两台计算机之间的数据传输很少会发生错误。而人去抄收和发送就不一样了,出错概率更大,一旦某些位置出错,则后面很大概率都会出问题。
再着,莫尔斯编码发明于1836年,而哈夫曼树发明于1952年
练习软件
我发现一款手机app名为
MorseMania,可以用来练习发送和抄收,不过练着练着就要收费了还有个app叫
Morse code,UI没上面那个好看,但功能更多并且免费pytorch自定义激活函数
代码
自定义函数需要继承
torch.autograd.Function类,并实现两个静态方法forward和backwardimport torch # 自定义函数 class MyFunc(torch.autograd.Function): @staticmethod def forward(ctx, input): """ 该自定义函数作用是将输入乘以2 使用以下方法将函数输入保存下来给backward中使用 ctx.save_for_backward(input) """ return input * 2 @staticmethod def backward(ctx, grad_output): """ 返回一个固定的梯度 这里结果必须乘上grad_output,下文有解释 使用以下方法获取forward过程中的输入 input, = ctx.saved_tensors """ return torch.tensor(3.) * grad_output # 使用 x = torch.tensor(1., requires_grad=True) y = MyFunc().apply(x) # 注意使用apply函数调用 y.backward() print(f'grad: {x.grad}') # 输出 # grad: 3.0解释
两个函数的作用
forward 函数用于forward过程中,backward 函数用于backward过程中,两者并没有直接关系,所以上述代码其实是 \( y=w\*x \\quad where \\quad x=1, w=2\\) ,但 \(\frac {dy}{dw}=3\ )(本来应该等于2的)。这也是为什么backward中要想得到函数的输入就需要在forward中先保存
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'
出现问题
远程ubuntu主机安装有anaconda,ssh远程登陆,发现命令提示符行首没有conda环境名称。输入
conda activate env-name提示shell没有配置正确,并建议使用conda init命令初始化shell,但使用该命令后仍然无效
但使用
source activate env-name可行解决方案
以下六个方法对我均有效,为什么有效见 原因 部分的分析,其中,前五种方法为临时解决方案,第六种为永久解决方案
方法一:使用
source命令激活环境source activate env-name方法二:
eval "$(conda shell.bash hook)" conda activate <env-name>方法三:
source ~/anaconda3/etc/profile.d/conda.sh conda activate my_env方法四:
bash conda activate my_env方法五:
source ~/.bashrc conda activate my_env方法六(永久生效):
在
~/.bash_profile中(若没有则创建)添加以下代码# if running bash if [ -n "$BASH_VERSION" ]; then # include .bashrc if it exists if [ -f "$HOME/.bashrc" ]; then . "$HOME/.bashrc" fi fi原因
我出现该问题的原因是环境变量设置的问题,我也有看到说若之前没有正确退出conda环境就退出shell也可能出现该问题,见这里
android 后台服务不会接收陀螺仪传感器的数据
挺喜欢玩lol的,出手游后就经常玩手游,但视角问题很难受,lol是自由视角,lolm强制锁定自己的视角,需要查看其它的地方还需要拖动一下,松开就又弹回固定视角。尤其是在开团或者绕后的时候,很难受
所以我打算开发一个辅助工具,它本质上是一个android service,它不断接收陀螺仪传感器的数据,然后模拟人手在屏幕上滑动改变视角。
上午下载好ide配置好环境,结果service中怎么也得不到陀螺仪传感器的数据。刚看到文档才知道,自android pie版本之后,service不再能接收连续型的传感器数据了
文档:https://developer.android.com/about/versions/pie/android-9.0-changes-all
不过倒是可以使用前台服务,只需要给定一个权限并创建通知栏通知即可
Visual Studio Code Server
VScode实现了C/S分离,可以实现只要有浏览器就能使用你开发机上的VScode
之前做法
在 VScode server 出现之前,你也可以通过安装
Remote - SSH插件的形式达到远程使用VScode编辑服务器上的代码的目的
但我体验下来其实并不是很好,至少在其他插件使用上还是有不少问题
VScode server
官网:https://code.visualstudio.com/docs/remote/vscode-server
使用场景
通过浏览器连接到 SSH 受限的远程机器上做开发
在一些不能安装vscode的设备上做开发(但支持浏览器),例如 iPad、手机上
想在某个隔离环境做开发,不想污染本地文件系统
快速开始
1. 安装 vscode server
- linux or macOS
wget -O- https://aka.ms/install-vscode-server/setup.sh | sh
- Windows(x64)
运行完成之后需重启terminal使环境变量生效
New-Item "$HOME\.vscode-server-launcher\bin" -ItemType "directory" -Force Invoke-WebRequest "https://aka.ms/vscode-server-launcher/x86_64-pc-windows-msvc" -OutFile "$HOME\.vscode-server-launcher\bin\code-server.exe" [Environment]::SetEnvironmentVariable("Path", [Environment]::GetEnvironmentVariable("Path", "User") + ";$HOME\.vscode-server-launcher\bin", "User")
- Windows(ARM)
New-Item "$HOME\.vscode-server-launcher\bin" -ItemType "directory" -Force Invoke-WebRequest "https://aka.ms/vscode-server-launcher/aarch64-pc-windows-msvc" -OutFile "$HOME\.vscode-server-launcher\bin\code-server.exe" [Environment]::SetEnvironmentVariable("Path", [Environment]::GetEnvironmentVariable("Path", "User") + ";$HOME\.vscode-server-launcher\bin", "User")2. 在terminal中启动vscode server
《孔乙己》——鲁迅
鲁镇的酒店的格局,是和别处不同的:都是当街一个曲尺形的大柜台,柜里面预备着热水,可以随时温酒。做工的人,傍午傍晚散了工,每每花四文铜钱,买一碗酒,——这是二十多年前的事,现在每碗要涨到十文,——靠柜外站着,热一热的喝了休息;倘肯多花一文,便可以买一碟盐煮笋,或者茴香豆,做下酒物了,如果出到十几文,那就能买一样荤菜,但这些顾客,多是短衣帮,大抵没有这样阔绰。只有穿长衫的,才踱进店面隔壁的房子里,要酒要菜,慢慢地坐喝。
我从十二岁起,便在镇口的咸亨酒店里当伙计,掌柜说,样子太傻,怕侍候不了长衫主顾,就在外面做点事罢。外面的短衣主顾,虽然容易说话,但唠唠叨叨缠夹不清的也很不少。他们往往要亲眼看着黄酒从坛子里舀出,看过壶子底里有水没有,又亲看将壶子放在热水里,然后放心:在这严重兼督下,羼水也很为难。所以过了几天,掌柜又说我干不了这事。幸亏荐头的情面大,辞退不得,便改为专管温酒的一种无聊职务了。
我从此便整天的站在柜台里,专管我的职务。虽然没有什么失职,但总觉得有些单调,有些无聊。掌柜是一副凶脸孔,主顾也没有好声气,教人活泼不得;只有孔乙己到店,才可以笑几声,所以至今还记得。
孔乙己是站着喝酒而穿长衫的唯一的人。他身材很高大;青白脸色,皱纹间时常夹些伤痕;一部乱蓬蓬的花白的胡子。穿的虽然是长衫,可是又脏又破,似乎十多年没有补,也没有洗。他对人说话,总是满口之乎者也,教人半懂不懂的。因为他姓孔,别人便从描红纸上的“上大人孔乙己”这半懂不懂的话里,替他取下一个绰号,叫作孔乙己。孔乙己一到店,所有喝酒的人便都看着他笑,有的叫道,“孔乙己,你脸上又添上新伤疤了!”他不回答,对柜里说,“温两碗酒,要一碟茴香豆。”便排一出九文大钱。他们又故意的高声嚷道,“你一定又偷了人家的东西了!”孔乙己睁大眼睛说,“你怎么这样凭空污人清白……”“什么清白?我前天亲眼见你偷了何家的书,吊着打。”孔乙己便涨红了脸,额上的青筋条条绽出,争辩道,“窃书不能算偷……窃书!……读书人的事,能算偷么?”接连便是难懂的话,什么“君子固穷”,什么“者乎”之类,引得众人都哄笑起来:店内外充满了快活的空气。
听人家背地里谈论,孔乙己原来也读过书,但终于没有进学,又不会营生;于是愈过愈穷,弄到将要讨饭了。幸而写得一笔好字,便替一人家钞钞书,换一碗饭吃。可惜他又有一样坏脾气,便是好吃懒做。坐不到几天,便连人和书籍纸张笔砚,一齐失踪。如是几次,叫他钞书的人也没有了。孔乙己没有法,便免不了偶然做些偷窃的事。但他在我们店里,品行却比别人都好,就是从不拖欠;虽然间或没有现钱,暂时记在粉板上,但不出一月,定然还清,从粉板上拭去了孔乙己的名字。
孔乙己喝过半碗酒,涨红的脸色渐渐复了原,旁人便又问道,“孔乙己,你当真认识字么?”孔乙己看着问他的人,显出不屑置辩的神气。他们便接着说道,“你怎的连半个秀才也捞不到呢?”孔乙己立刻显出颓唐不安模样,脸上笼上了一层灰色,嘴里说些话;这回可是全是之乎者也之类,一些不懂了。在这时候,众人也都哄笑起来:店内外充满了快活的空气。
在这些时候,我可以附和着笑,掌柜是决不责备的。而且掌柜见了孔乙己,也每每这样问他,引人发笑。孔乙己自己知道不能和他们谈天,便只好向孩子说话。有一回对我说道,“你读过书么?”我略略点一点头。他说,“读过书,……我便考你一考。茴香豆的茴字,怎样写的?”我想,讨饭一样的人,也配考我么?便回过脸去,不再理会。孔乙己等了许久,很恳切的说道,“不能写罢?……我教给你,记着!这些字应该记着。将来做掌柜的时候,写账要用。”我暗想我和掌柜的等级还很远呢,而且我们掌柜也从不将茴香豆上账;又好笑,又不耐烦,懒懒的答他道,“谁要你教,不是草头底下一个来回的回字么?”孔乙己显出极高兴的样子,将两个指头的长指甲敲着柜台,点头说,“对呀对呀!……回字有四样写法,你知道么?”我愈不耐烦了,努着嘴走远。孔乙己刚用指甲蘸了酒,想在柜上写字,见我毫不热心,便又叹一口气,显出极惋惜的样子。
有几回,邻居孩子听得笑声,也赶热闹,围住了孔乙己。他便给他们吃茴香豆,一人一颗。孩子吃完豆,仍然不散,眼睛都望着碟子。孔乙己着了慌,伸开五指将碟子罩住,弯腰下去说道,“不多了,我已经不多了。”直起身又看一看豆,自己摇头说,“不多不多!多乎哉?不多也。”于是这一群孩子都在笑声里走散了。
孔乙己是这样的使人快活,可是没有他,别人也便这么过。
有一天,大约是中秋前的两三天,掌柜正在慢慢的结账,取下粉板,忽然说,“孔乙己长久没有来了。还欠十九个钱呢!”我才也觉得他的确长久没有来了。一个喝酒的人说道,“他怎么会来?……他打折了腿了。”掌柜说,“哦!”“他总仍旧是偷。这一回,是自己发昏,竟偷到丁举人家里去了。他家的东西,偷得的么?”“后来怎么样?”“怎么样?先写服辩,后来是打,打了大半夜,再打折了腿。”“后来呢?”“后来打折了腿了。”“打折了怎样呢?”“怎样?……谁晓得?许是死了。”掌柜也不再问,仍然慢慢的算他的账。
中秋之后,秋风是一天凉比一天,看看将近初冬;我整天的靠着火,也须穿上棉袄了。一天的下半天,没有一个顾客,我正合了眼坐着。忽然间听得一个声音,“温一碗酒。”这声音虽然极低,却很耳熟。看时又全没有人。站起来向外一望,那孔乙己便在柜台下对了门槛坐着。他脸上黑而且瘦,已经不成样子;穿一件破夹袄,盘着两一腿,下面垫一个蒲包,用草绳在肩上挂住;见了我,又说道,“温一碗酒。”掌柜也伸出头去,一面说,“孔乙己么?你还欠十九个钱呢!”孔乙己很颓唐的仰面答道,“这……下回还清罢。这一回是现钱,酒要好。”掌柜仍然同平常一样,笑着对他说,“孔乙己,你又偷了东西了!”但他这回却不十分分辩,单说了一句“不要取笑!”“取笑?要是不偷,怎么会打断腿?”孔乙己低声说道,“跌断,跌,跌……”他的眼色,很像恳求掌柜,不要再提。此时已经聚集了几个人,便和掌柜都笑了。我温了酒,端出去,放在门槛上。他从破衣袋里摸出四文大钱,放在我手里,见他满手是泥,原来他便用这手走来的。不一会,他喝完酒,便又在旁人的说笑声中,坐着用这手慢慢走去了。
自此以后,又长久没有看见孔乙己。到了年关,掌柜取下粉板说,“孔乙己还欠十九个钱呢!”到第二年的端午,又说“孔乙己还欠十九个钱呢!”到中秋可是没有说,再到年关也没有看见他。
我到现在终于没有见——大约孔乙己的确死了。
Golang,基于Module和基于GOPATH
本文译自:https://go.dev/ref/mod#non-module-compat
Golang的导包有两种模式,一种是基于GOPATH的(老),一种是基于Module的(新),自1.16版本后,默认开启基于Module的方式,不管
go.mod文件存不存在对非Module模式项目的兼容方式
对即使没有
go.mod的项目(非module项目),go也能使用module模式处理package当你需要导入的模块和其仓库根目录相同时,若在其仓库根目录没有
go.mod文件,go就会在module cache(module下载下来后保存在本地的路径)中自动生成一个go.mod,但其中只包含了module path(例:module golang.org/x/net),并没有包含该module依赖的其他module(即 go.mod 中的require语句),所以,当其他module需要依赖该module时就需要一些额外的require语句来获取这些依赖(即在require后面跟着 // indirect 的那些个依赖)版本号兼容
对于版本号大于1的module,需在其module path上加上版本号后缀,例如 /golang.org/x/v2/net 表示x这个module的第2个版本(这里的v2不会被当作是目录名)
但对于一些较老的module,它已经迭代了很多版本了,但当时还没有这个规定。可以使用
+incompatible来兼容它们。例如require example.com/m v4.1.2+incompatible。基于module的命令
绝大多数命令都可以运行在这两个模式下,在module模式下,go命令使用 go.mod 文件去寻找依赖,一般情况下都是在
GOPATH/pkg/mod目录下寻找,如果找不到也会下载到该目录下。在GOPATH模式下,go命令会在 vendor 目录和 GOPATH 目录下寻找依赖在go 1.16 版本后,不管是否存在go.mod文件都会使用module模式(早期会根据是否存在该文件而做判断)
当
GO111MODULE=off,go命令会忽视 go.mod 文件直接使用GOPATH模式当
GO111MODULE=on或者为空时,则会使用module模式,即使 go.mod 文件不存在当
GO111MODULE=auto,若当前文件夹或任何父文件夹存在 go.mod 文件,则使用module模式在module模式下,GOPATH不再作为编译时导包方式了,但它仍然用作存储下载下来的依赖目录(GOPATH/pkg/mod 目录)和install之后的文件保存目录(GOPATH/bin)
编译命令
一些加载包信息的命令都可以使用module模式,其中包括
go build
go fix
go generate
go get
go install
go list
How go module "import" works?
此文翻译自官方文档:https://go.dev/ref/mod#resolve-pkg-mod
当你使用 import xxx 方式导包时,它首先需要判断这个包来自哪个module
go首先会在 build list寻找是否有哪个module的前缀与导入的包前缀的相同,例如,如果你想导入
example.com/a/b,并且example.com/a存在与 build list(go.mod中列出的依赖,类似 package.json 或者 build.gradle 这种),然后go将会检查example.com/a是否存在b这个目录,且其下面至少包含一个go文件。如果在build list中找到匹配的module的话就使用它,如果没找到或者找到了多个module都提供了这个package(为啥会这样?),go就会报错。但如果设定了-mod=mod参数的话,go就会尝试去寻找这个包,go get和go mod tidy命令会自动做这件事情怎么找呢?它会首先检查
GOPROXY这个环境变量,该命令可以设置多个代理地址,使用逗号分开。或是将其设置为off,表示不使用代理。他会遍历所有的代理地址,并寻找所有可能提供该pkg的module(就是所有的pkg前缀都当作module名尝试寻找),对于每个可能的module,go都会将其最新版本下载下来,并且去看它是否真的提供所需的pkg。如果有多个module都提供了这个包,则以名称长的那个module为准。如果都不提供或者找不到可能的module,则报错。
例如:你的代码中
import golang.org/x/net/html并且
GOPROXY=https://corp.example.com,https://proxy.golang.orggo就会同时在两个代理服务器中找:
- 在 https://corp.example.com/ 中(并发寻找多个可能的module):
golang.org/x/net/html
golang.org/x/net
golang.org/x
golang.org
如果在第一个代理服务器中没找到,则继续按上述寻找方式在第二个代理服务器中找,以此类推
找到后则会下载并更新
go.mod和go.sum文件,go会在go.mod中新增一个关于该module路径和版本的requirement语句,如果寻找的这个package不是直接被 main module 使用,这条新加的 requirement 语句后面就会跟上一个// indirect的注释记一次QT程序Debug的过程(WinDbg的使用)
环境
WinDbg preview,Debugger client version: 1.2210.3001.0,Debugger engine version: 10.0.25200.1003
下载路径:https://learn.microsoft.com/zh-cn/windows-hardware/drivers/debugger/debugger-download-tools
QtCreator 7.0.2,Qt 6.2.3,MSVC 2019 64位
现象
程序异常退出,没有提示原因
找原因
1. debug方式qt打包exe
步骤见:https://blog.woyou.cool/post/4225
2. 使用WinDbg打开exe
3. 设置debug环境
pdb文件干啥的?
如果用debug模式打的包会在exe同级目录下生成一个pdb文件,该文件保存了一些debug需要的符号信息,如果没有该文件的话报错提示就会很隐晦
为啥需要设置源文件?
为了报错后能定位到报错位置,你本身已经打包成exe了,不包含源码了
也可以使用命令设置它们
# 设置源码位置 .srcpath [your source code location]
4. 启动程序
5. 程序崩溃时就会有堆栈信息
6. 查看详细异常信息
输入命令
!analyze -v
然后就能看到如下信息
由上述信息就可知出现空指针的位置
问题
源码显示不对应
见下图,一开始我很奇怪为什么我源码都注释掉了它还是提示这个地方有问题,更奇怪的是它竟然还有注释掉的局部变量信息
这其实就是上面第3步中源码和pdb文件位置设置的不对导致的,或者你在开始debug后修改了源码(这里显示的源码是和文件中的修改实时同步)
debug release版本
在 pro 文件中加入以下两行代码
# 生成pdb文件 QMAKE_LFLAGS_RELEASE = $$QMAKE_LFLAGS_RELEASE_WITH_DEBUGINFO QMAKE_CXXFLAGS_RELEASE = $$QMAKE_CFLAGS_RELEASE_WITH_DEBUGINFO没有 QMAKE_LFLAGS_RELEASE = $$QMAKE_LFLAGS_RELEASE_WITH_DEBUGINFO 无法生成 pdb 文件
QT程序打包
打包过程举例
以下项目将生成一个名为 filter_detect_qt.exe 的包,用它来举例
1. 编译
2. 找到输出文件
3. 将该 exe 文件复制到另外一个空的目录
4. 该目录下打开 cmd 窗口,运行代码:
# 注:windeployqt 命令这里有个坑,见下文中的注意事项 windeployqt filter_detect_qt.exe完成后会自动将一些库文件复制进来
5. 手动将一些依赖动态库复制进来
第4步会将qt相关的一些库自动复制进来,但代码中的一些依赖动态库还需自己手动复制。可以打开 filter_detect_qt.exe 提示你缺什么库就复制什么
以下为手动复制进来的库文件(注:因为是动态库文件,所以仅仅打开exe查看报错是不够的,有些库文件只有在特定情况下才会使用,所以最好是在项目开发过程中就维护好这些动态库文件)
再次打开 exe 文件发现可以正常运行了。
遇到的问题
windeployqt 找不到库文件
从报错可以看出这应该是环境变量的问题,它使用了 anaconda 下的某个 windeployqt 程序,可以使用 where 命令查看命令路径:
# 类似于 linux 下的 whereis 命令 where windeployqt # 如果在 powershell 下 where 命令无输出的话,使用 where.exe where.exe windeployqt
而我们真正要使用的是 Qt 下的 windeployqt 命令,可以使用 everything 找到
python:多进程共享复杂的可写对象
本来想用该方法共享一个模型的,一个进程用于收集训练数据,一个进程用于训练,但是仍然不行。但基本的进程共享内存空间对象还是可以的:
from multiprocessing import Process from multiprocessing.managers import BaseManager # 第一步:定义需要共享的类 class Data: """ 该对象处于共享内存中,其内部属性(即使是自定义对象)也是在共享内存中 """ def __init__(self, n=0): self.num = n def add(self, i): # 注:该操作进程不安全,需要加锁才能保证安全 self.num += i def get_num(self): return self.num # 第二步:创建一个继承 BaseManager 的类,内容可以为空 class MyManger(BaseManager): ... # 第三步:注册共享类 MyManger.register("Data", Data) if __name__ == '__main__': # 第四步:创建自定义Manager对象并启动 manager = MyManger() manager.start() # 第五步:获取共享对象的引用,该对象已经位于共享内存中,但它其实是一个代理对象,其类型为 AutoProxy[Data],所以你不能直接获取其 num 属性 d = manager.Data() p1 = Process(target=d.add, args=(1,)) p2 = Process(target=d.add, args=(1,)) p1.start() p2.start() p1.join() p2.join() # 注:再次强调,由于 d 是一个代理对象,所以你不能直接通过 d.num 获取num的值 print(d.get_num()) # 2,两个进程各自加1python中进程池要使用 Semaphore 时,需要使用 multiprocessing.Manager().Semaphore() 对象,而不是 multiprocessing.Semaphore() 对象,相应的 Lock、Value也是
python:直观感受GIL锁
以下代码可以直观感受GIL锁对性能的影响
import time from multiprocessing import Process from threading import Thread def count(): i = 100000000 while i > 0: i -= 1 if __name__ == '__main__': start = time.time() count() count() count() print("单线程运行3个任务", time.time() - start) start = time.time() ts = [Thread(target=count) for i in range(3)] [t.start() for t in ts] [t.join() for t in ts] print("多线程运行3个任务", time.time() - start) start = time.time() ts = [Process(target=count) for i in range(3)] [t.start() for t in ts] [t.join() for t in ts] print("多进程运行3个任务", time.time() - start)运行结果:
OpenStack vs Kubernetes
关系
简单来说,Kubernetes 管理容器,OpenStack 管理虚拟机
所以两者可以配合使用:将 Kubernetes 的容器部署在 OpenStack 的虚拟机上。这样就实现了 “在虚拟机中使用虚拟机”,提升了隔离性,但降低了性能。
K8s也可以直接用在物理机集群的,所以K8s再发展下去,OpenStack地位是不是有点危险了
OpenStack是个什么东西
早期云计算就 AWS 一家独大,后来出现了开源的 OpenStack 与其竞争,国内也有像阿里云、腾讯云等。可以简单认为,OpenStack 可以将多个物理机组成一个硬件资源池,然后使用这些资源创建一堆虚拟机供用户使用。当然不仅仅是虚拟机的管理,OpenStack 还要负责这些资源的分配、网络的配置等等。
就像 SpringBoot 框架的各项功能的实现都是各种 Starter 实现的,OpenStack 也只是一个框架,其各种功能由不同的模块实现。例如对于虚拟机的创建,就可以使用 KVM、Xen 或其他的虚拟化工具实现
参考:OpenStack介绍
虚拟机 vs 容器
KVM(Kernel-based Virtual Machine),linux系统集成的开源虚拟机管理软件,可以类比为 Vmware 等。你可以用它来将多台物理机组成一个资源池,然后创建和管理虚拟机。用它创建的虚拟机会直接使用内核调用,而不是模拟内核调用,提高了虚拟机的性能
不同于虚拟化技术要完整虚拟化一台计算机,容器技术更像是操作系统层面的虚拟化,它只需要虚拟出一个操作系统环境。
LXC技术就是这种方案的一个典型代表,全称是LinuX Container,通过Linux内核的Cgroups技术和namespace技术的支撑,隔离操作系统文件、网络等资源,在原生操作系统上隔离出一个单独的空间,将应用程序置于其中运行,这个空间的形态上类似于一个容器将应用程序包含在其中,故取名容器技术。
kubernetes 和 docker 的关系
就目前来看(k8s 1.24以后),kubernetes 和 docker 应该是属于并列的关系,它们都是容器的一种管理方式。
而kubernetes重在集群的管理,docker则侧重单机的管理,但docker中有个docker swarm(见 https://blog.woyou.cool/post/653),也是侧重集群管理的,但显然,它并没有打赢k8s
首先需要明确的是,容器这个概念并不是docker创造的,在其之前就存在,docker只是将其发扬光大了,docker只是用来管理容器的。
OCI
容器的创建、销毁、查看等操作本身就有一个接口,名叫 OCI(开放容器接口),runc 就是该接口的一个实现。类似于java中接口与实现的关系。
Containerd
光有容器还不行,是你还需要对容器周边的一些东西进行管理,例如镜像、标签等,这个东西就是 containerd,你可以用它来拉取镜像,或者用它来调用 OCI 实现对容器的操作等。
例如:containerd 提供了 ctr 工具,你可以用该工具拉取镜像:
ctr image pull docker.io/library/nginx:alpine给镜像打标签:
ctr image tag docker.io/library/nginx:alpine harbor.k8s.local/course/nginx:alpine也可以使用 ctr 调用 OCI 操作容器,例如创建一个容器:
ctr container create docker.io/library/nginx:alpine nginx查看容器:
ctr container info nginx启动容器:
ctr task start -d nginx进入容器:
ctr task exec --exec-id 0 -t nginx sh也就是说,你可以不依赖 docker 而直接安装 containerd 进行容器和镜像的操作,由于 containerd 依赖 runc,故需先安装 runc
如果把容器比作虚拟机,那么 containerd 就相当于 VMware、VirtulBox 等软件,OCI 就相当于这些软件对虚拟机的操作,例如创建、删除、启动等。
GNOME、KDE是什么
GNOME:GNU Network Object Environment(什么是 GNU:https://blog.woyou.cool/post/2202)
KDE:Kool Desktop Environment
早期 windows 只是 DOS 下的一个软件,启动 DOS 系统后只会进入命令行环境,需手动启动 windows 才会进入桌面环境
后面又将 windows 写入内核,每次启动系统后自动打开 windows 进入桌面环境,相当于设置了开机自启动。随着 windows 与内核的耦合性不断增大,windows 逐渐成为内核的一部分,成为了 windows 系统,并在后面彻底抛弃了 DOS 实现了翻身农奴把歌唱。
若将 linux 类比早期的 DOS 系统,则 KDE 和 GNOME 则类比于两个不同的 windows 软件,直观来说,KDE风格和windows系统类似,而GNOME则更像macos一些。
故现在 linux 系统是可以切换和选择不同的桌面环境的,例如 ubuntu 默认使用 GNOME,但可以再安装 KDE,启动系统后就可以选择使用哪一个桌面环境
安装教程:https://zhuanlan.zhihu.com/p/338666316
你也可以将 KDE 和 GNOME 类比为 Unity3D 和 UE 两种游戏引擎,或者 chrome 和 firefox 两种内核的浏览器,它们的作用就是渲染各种不同的界面,但其底层实现是不同的。
早期unix或linux没有桌面环境,后来有人开发出一套GUI接口(只是对资源的调度,并不是UI的渲染),称为 X Window,任何人都可以基于它开发出自己的GUI环境。
X Window 分为三层,unix内核、X server 和 X client。
nohup 多个命令 &
问题
我需要执行多个任务(task1、task2),要求:
串行执行,task1执行成功后执行task2
后台执行,整个执行过程不能因session中断而停止
每个task的输出到单独的文件中
问:以下方案中,哪些是可行的:
nohup task1 > out1 && task2 > out2 & nohup task1 > out1 & && nohup task2 > out2 & nohup task1 > out1 && nohup task2 > out2 & nohup task1 > out1 & nohup task2 > out2 &结果
上述命令都无法完成要求
原因
&& 和 &
两者都可以用来分割命令,区别在于 && 只有在前一个命令执行成功(return 0)才会执行下一个命令,而 & 只是将其前面的命令放入后台执行,并立即返回
例如:
command1 && command2 && command3 # 只有 command1 执行成功后才会执行 command2,后面同理 command1 & command2 & command3 # 当程序读到第一个 & 时,会将其之前的命令放到后台执行 # 例如,读到第一个 & 时,将 command1 切割出来并放到后台执行,此时立即返回状态,继续向后读命令,又读到第二个 & 则又将 command2 切割放到后台执行并立即返回,继续往后执行命令,由于 command3 没有 &,故其只会在前台执行 command1 && command2 & # & 的优先级比 && 高,故该代码会先整体进入后台,然后再通过 && 分割执行&&、&、;、||
四个都可以用来分割命令,区别在于
ubuntu22启动运行脚本
早先的系统可能使用 rc.locl 或者 init.d 的方式,但这些都已经被逐步淘汰了,ubuntu16以后推荐使用注册systemd的方式
要创建一个自启动服务(脚本),分为以下三步:
创建shell脚本
向服务目录添加服务信息
enable服务
例如我要创建一个mytouch服务,它会自动在启动时向桌面创建一个bingo文件
创建shell脚本 /usr/local/bin/mytouch.sh
向服务目录添加服务信息,即向
/etc/systemd/system添加一个名为 mytouch.service 的文件,内容如下:[Unit] After=network.target [Service] ExecStart=/usr/local/bin/mytouch.sh [Install] WantedBy=default.target该文件相当于服务的元信息,其内容为 INI 格式,分三个部分:
Unit:服务的基本信息,例如描述、依赖、启动顺序等,例如After=network,target表示网络就绪后启动脚本
Service:服务的执行方式,例如服务启动命令、环境变量、工作目录等
Install:服务的安装方式,也可以用于设置启动级别、启动顺序等,wantedBy就是用于设置启动级别的,常见的有 poweroff.target(关机时)、multi-user.target(多用户模式下)、reboot.target(重启时)等
注:这里有点问题,好像unit和install的功能重复了?
这俩文件创建完后别忘了赋予执行权限,否则,脚本不会执行,并且也没有报错,你会以为哪里写的有问题。
创建该文件就已经将服务注册进systemd了,但还需要enable服务,即执行命令
systemctl enable mytouch.service
此时系统启动就会自动运行该服务脚本了,对于本脚本来说,系统启动后就自动在桌面创建一个bingo文件
当然,既然已经注册成为了服务,就可以使用systemctl进行管理,例如可以随时使用 systemctl start mytouch.service 来执行脚本
若不想使用该服务了,执行
systemctl disable mytouch.service然后删除上述两个文件即可
注:
服务注册好之后,脚本内容可以随时更改
脚本会以root用户权限运行
参考:
https://www.yii666.com/blog/662568.html
https://www.tutorialspoint.com/run-a-script-on-startup-in-linux
将微信或qq用于办公的都是傻逼
如题
rm删除文件
问题
father_dir 目录下有个文件 some_file,当前用户对其有读写权限,问:该用户能否删除该文件?
答:
不一定,取决于父目录的权限
若父目录对当前用户无写权限,则无法删除
原因
文件或文件夹的权限表示的并不是其本身的操作权限,而是其内容的操作权限。
你对该文件有读写权限,仅仅意味着你可以对该文件的内容进行读写。而该文件应该属于其父目录的内容,删除该文件就是对其父目录进行修改,所有需要有父目录的写权限才行。
解决
为父目录增加写权限:
chmod u+w father_dir
附录
权限字符串第1位表示文件类型,d表示目录,-表示文件,l表示软链接
前三个表示文件所有者的权限,用 u 表示,中间三位表示文件所有者所在组的权限,用 g 表示,后三位表示其他用户权限,用 o 表示
例如:
# 为其他用户递归添加目录读写权限 chmod -R o+wr some_dir # 去除文件所有者的执行权限 chmod u-x some_file《Learning Statistical Texture for Semantic Segmentation》
- 现存的语义分割模型重在高层抽象语义分析,例如CNNs就能很好完成这一点。但高层抽象语义往往会忽略一些底层的特征,例如边缘信息、纹理信息等
- 本文利用低层特征信息的优点提出了 Texture Learning Network(STLNet)用于语义分割
- 本文设计了一个 Quantization and Counting Operator(QCO)用于统计和描述纹理信息
- 基于QCO设计除了 Texture Enhance Module(TEM)纹理增强模块,和Pyramid Texture Feature Extraction Module(PTFEM)模块用于从多尺度提取纹理统计信息
- 底层的卷积往往能提取到纹理信息,随着深度的增加,提取的信息也越来越抽象。将底层卷积核可视化
- QCO中,将输入特征放到多层神经网络中,每一层都代表一个纹理特征的统计信息。然后计算每一层的强度用作特征编码
- STLNet分为两层
首先使用ResNet101提取特征,后跟一个 ASPP 池化层
使用ResNet的前两层作为纹理提取分支的输入,先将这两层下采样到与模型整体输出相同的shape,再将它们连接起来,然后将其串联输送到TEM和PTFEM中。如图,在整个过程中,还需要多次将各个模型的输入和其他模型的输出连接起来,作为下一个模型的输入(图中黄色圈的的C,即concat)
- QCO可以分为两类:1维的用于TEM,2维的用于PTFEM。
- 1维QCO
理解1维QCO的关键在于知道它要做什么:和灰度直方图相似,它计算每个特征图像素点与平均特征距离的统计值。
首先使用全局平均池化得到每个channel的均值 g(图中A后面那个横着的长条,其实就是每个channel特征图像素值的平均值)
可以想象,g是一个 c 维向量(c指channel数),而A中每个像素也是一个c维向量,两个向量就可以计算cos值作为相似度,计算完之后得到图中的 S 矩阵,再将其reshape为1维向量
将所得的相似度分成 n 个区间,计算每个像素所在的空间,即图中的E矩阵,每一行表示图片的哪些像素在第n个区间中,若不在则该位置的值赋0,在的话则是一个非0的数
将E中每一行求和并除以E矩阵的总和(相当于计算每个灰度阶下像素个数的占比),将其和每个阶对应的起始灰度值连接起来,形成C矩阵,相当于组成一个List<Map<»,map的key为灰度阶起始值,value为该阶所有像素值数量占比
将C矩阵使用MLP升维,并将g上采样,然后将两者连接起来输出D
- 2维QCO
1维QCO只是统计了像素的数量信息,但并没有表示出各个像素之间的关系,所以需要2维QCO,其本质同灰度共生矩阵
2维QCO输出E矩阵的过程同1维QCO,但后续处理不同
将输出的E矩阵reshape为
N*1*H*W,相当于将一维向量还原成二维图片,并且图片的每一个像素值是一个 N*1 的向量(类似与将每个像素 one-hot 成L个灰度阶)计算每个像素和其后面一个像素转置的点乘。因为每个像素为 N*1 的维度,故点乘后得到 N*N 的维度,又由于每个像素的N维中,只有其所在阶的值不为0,故该 N*N 维的输出中,只有这两个相邻像素所在阶交叉的地方不为0。若当前像素灰度阶为m,其下一个像素灰度阶为n,则只有(m, n)的位置不为0
《SegFix: Model-Agnostic Boundary Refinement for Segmentation》
2020_eccv_SegFix-Model-Agnostic-Boundary-Refinement-for-segmenationDownload
- 目的是提升现存分割模型的边界像素预测质量,现阶段的分割模型普遍的情况是:越接近物体边界的像素预测准确度越低
- 本文提出的解决方法是:在现有模型预测完成的结果上,仅对边界像素分类进行微调。
现有模型基本上都是直接预测出物体的边界像素位置,但往往预测出错就出现在这些边界像素上。
本文的方法与用哪个分割模型无关,因为它只是在分割完成的结果上做进一步修正。
- 本文提出的方法仅对输入图像做两步处理:1)定位轮廓边界像素。2)找到与轮廓边界像素相对应的内部像素
- 模型结构如图:
训练过程为:先使用一个Backbone对原始图片进行特征提取,然后将提取到的特征作为两个预测模型的输入:
- Boundary 分支负责预测物体的边界,得到一个 boundary map,该map只有(0,1)两个数,1表示边界像素
- Direction 分支负责预测从边界指向内部像素的方向(想象一个人站在任意像素上看向离他最近边界的反方向),得到一个 direction map
使用 boundary map 作为 direction map 的mask,即可得到仅含边界的 direction map,将该 map 作为 offset 分支的输入,得到一个offset map
offset 分支不是一个神经网络,而只是一个值转换函数,direction map 中每个元素表示的方向取值是 (0,360] 的连续值,而 offset branch 则将它们分类为 n 个方向上的离散值(例如分成每45°就划分为一个方向,共分为8个方向)
- 通过SegFix模型得到了一个 offset map,再将其作用与任意分割模型的分割结果上
最终产生的分割边界为:
其中 L 表示边界的label map(一张图中哪些是边界),L帽表示经过SegFix精炼过后的label map,Pi 表示边界像素 i 的坐标,Δqi表示边界像素偏移量(即上述模型的 offset map ) ,pi + Δqi 即为将边界向偏移量方向偏移后的新像素位置
- 应用举例
/bin/sh: 1: :/usr/local/cuda/bin/nvcc: not found
设置cuda的环境变量即可:
export CUDA_HOME=/usr/local/cudanvcc是cuda的编译器,更多关于cuda的信息:https://blog.woyou.cool/post/2719
IoU 和 mIoU
在语义分割领域常用这两个指标评估模型性能。例如下图中:P(整个黑框)表示 ground-truth 像素区域,Q(整个绿框)表示模型预测的像素区域
IoU全称为:Intersection over Union
交并比(IoU)
\[ IoU = \frac {P ∩ Q} {P ∪ Q} \ ]
当 IoU==1 时,表示 P 和 Q 完全重叠,即预测完全正确,当 IoU==0 时,两者完全独立,即预测没有丝毫正确的地方
平均交并比(mIoU)
很多情况下,模型预测的类别往往不止一个,假设类别为 k 个,则对这 k 个预测的 IoU取均值即可
\[ mIoU = \frac {1} {k} \sum_{i=1}^{k}IoU_i \ ]
成长的过程就好比往一个气球里面不断塞石子的过程
石子有大有小,有圆有方。气球还需要不停地移动以适应环境变化。
你不知道下一个塞进来的石子是棱角分明还是温润圆滑,你也不知道下一个石子有多大,你都不知道还要塞进来多少石子。
随着气球的移动,石子在里面不断地翻滚摩擦,有些小的石子很快就被磨得平滑了,而有些大的石头,很久很久都没法磨平,它们日以继夜地刮蹭着气球的内壁。
幸好你这个气球足够结实。
色彩模型 RGB、HSL、HSV
RGB
使用rgb三原色表示某个颜色有一定的缺陷:人眼对不同颜色变化的灵敏度是不同的,例如,对红色变化的敏感度就比蓝色低。所以对rgb表示的颜色变化感觉上并不线性。
故而RGB在工业生产上用得多,如果是普通人调色的话,则更多用到 HSV 或 HSL
HSV
HSV使用 Hue(色调、色相)、Saturation(饱和度、色彩纯净度)、Value(明度)三元组表示一个颜色。
例如在 PS 中就有:
色相表示各种不同的颜色,就好比它将各种颜色按照光波频率进行排序了一样,不同数值表示不同颜色
饱和度就好比颜色的纯净程度,想象对染料的稀释过程,加水越多,颜色越淡,即饱和度越低
明度就好比往染料中添加墨水,明度越小,加的墨水越多,则颜色越来越暗
HSL
HSL表示 Hue(色调、色相)、Saturation(饱和度、色彩纯净度)、Lightness(亮度)
例如,windows自带的画图程序,打开编辑颜色就能看到
HSL和HSV的不同在于最后一个值
在HSL中,亮度就好比将一个手电筒照在一块带有颜色的布上,明度越高,手电筒的光越亮,则布的颜色越来越泛白,反之则越来越黑
可以在这个网站直观体验到三个值对颜色的影响:https://www.w3schools.com/colors/colors_hsl.asp
参考
https://zhuanlan.zhihu.com/p/67930839
linux命令行环境下下载cityscapes数据集
官网地址:https://www.cityscapes-dataset.com/downloads/
下载数据前需要注册登录,必须使用企业或教育邮箱。未登录状态下点击下载链接会跳转到登录页面。这使得若直接在命令行环境下用wget下载只会下载一个html文件(即登录页面)。解决办法就是在wget中添加已登录的cookie信息。
1. 先去官网注册登录
2. 打开浏览器控制台(一般为 f12 键)
3. 进入官网的下载页面,点击你要下载的数据集链接。此时浏览器就会开始下载数据或者询问下载位置,直接取消下载即可。同时网络监控器下会显示本次的请求,点开即可看到如下信息
4. 复制请求URL和cookie,转到linux命令行,使用如下命令进行下载
wget --header="Cookie: <你复制过来的cookie>" --content-disposition <你的请求URL>回车即可开始下载
当然,由于大文件通常会下载几个小时,故推荐使用 nohup 和 & 进行后台下载(添加–no-verbose 参数避免频繁输出下载进度)
nohup wget --no-verbose --header="Cookie: <你复制过来的cookie>" --content-disposition <你的请求URL> &
下载过程中,可以使用
ps -aux | grep wget找到该后台任务id,使用kill -9 <id>即可停止下载
使用
tail -f nohup.out即可查看下载过程中的输出内容SSL/TLS
ssl 协议 3.0 版本以上称为 tls ,例如 tls1.0 就是 ssl3.1
因此 tls1.0 协议是可以降级为 ssl3.0 协议使用的(但不是兼容)
目前所说的ssl绝大多数情况下指的就是tls。现代浏览器基本不再使用ssl,而是使用 tls1.2、tls1.3
ssl 协议工作在传输层和应用层之间(传输层使用tcp,应用层使用https、ssh、ftps等)。这其实也可以看出osi模型的局限性,至少在这里它就不能准确将ssl协议归为七层或五层中的某一层,而应该是一个位于传输层和应用层中间的一个新层
参考:https://zhuanlan.zhihu.com/p/345943705
《上帝会来救我的》
一场大风暴导致河堤即将溃坝,洪水将袭击整个小镇。当地警方已经提前发出警告,现正在有序疏散村民。
一个虔诚的基督教徒听到了警告,但他还是决定留下了。他相信如果自己陷入绝境,上帝一定会显灵来救他。
邻居撤离时经过他家喊道:“我车里还有空位,快跟我们一起走吧”。但他婉拒了,他说:“我相信上帝一定会来救我的”
大水快要淹没门廊,一个人划着小舟经过:“快上船吧,水涨得太快了,很危险!”。但是他仍然坚持道:“你快走吧,我要等上帝来救我。”
水越来越高,逐渐快要淹没他的房间。警察驾驶摩托艇经过,透过窗户看到房间里的他,大喊道:“别担心,我们现在就来救你!”。但是他冲警察摆手喊道:“其他人更需要你们的帮助,抓紧时间救他们吧,上帝会来救我的。”
洪水没过了他的房子,他不得不爬到房顶上。
一架直升机发现了他,并抛下绳梯。救护人员下来劝他快跟着一起离开。他仍然一动不动:“别管我,上帝会来救我的。”
没一会,洪水就冲垮了他的房子,他还是淹死了。
上了天堂,他来到上帝面前问道:“我一生都那么相信你,为什么你就是不来救我?”
上帝说:“孩子,我先是给你发了警告,然后派了一辆车过去接你,我还派了一艘船过去,再派了一辆摩托艇,你都是不为所动,我甚至为你派了一架直升机,你还要我怎么救你?”
A terrible storm came into a town and local officials sent out an emergency warning that the riverbanks would soon overflow and flood the nearby homes. They ordered everyone in the town to evacuate immediately.
A faithful Christian man heard the warning and decided to stay, saying to himself, “I will trust God and if I am in danger, then God will send a divine miracle to save me.”
《没有一种痛是单为你准备的》——马德
记住,这个世界,没有一种痛是单为你准备的。
因此,不要认为你是孤独的疼痛者。也不要认为,自己经历着最疼的疼痛。尘世的屋檐下,有多少人,就有多少事,就有多少痛,就有多少断肠人。
活着,就是要痛一痛的。有声有色地活过,其实就是有滋有味地痛过。当然了,有时候,你觉得痛,不是你有多苦,有多委屈,只是觉得自己很可怜,很无助,很孤单。
痛也是怕比较的。了断痛的一种方式是比较。把自己的痛放到万千的人群中,比完了,你也就放下了。
我的意思是,在芸芸众生的痛苦里,你才会发现,自己的这点痛,真的不算什么。从理论上讲,我们身边是60亿人。但,这一辈子,我们最多活在60个人中间。而让你至爱与至痛,至喜与至悲,至生与至死的,最多不过几个人。
这几个人,才是你的世界。
所以,更多的人,更多的事,你都不必去在意。在意的越多,就会沉陷得越深,就会纠缠得越久,就会被折磨得越苦。
简单点。简单便是快活。
心的愉悦,有两重境界:一曰饱,一曰滋润。
尘俗中有些事,譬如,挣大钱,谋重权,赢盛名,鲜花掌声,轰轰烈烈,这种让心灵愉悦的状态,即为饱。但饱了之后,愉悦便不再是愉悦,而只剩下刺激了。
尘俗中的另一些事,譬如,喝茶,访山,看云,赏月,风敲叶响,云动鸟惊,这种让心灵愉悦的状态,即为滋润。滋润给心灵的感受是,不厌,不腻,不绝。
这个世界上,凡是跟功利有关的事,于心灵,你只可以喂饱它,却不能滋润它。
有时候,能容下多少他人,就能拥有多少快乐。
换一个说法就是,你跟多少人作对,就是跟自己本该拥有的多少快乐作对。
有的快乐是自生的。有的快乐,是与他人和谐相处中获得的。结怨,会疼;周旋,会累。有时候,退一步,妥协一点,甚至投降一次,都不算什么,但你会一下子找到轻松快乐的自己。
生活没那么复杂。你把自己搞复杂了,烂摊子,也只好自己去收拾。
更多的人,关注的是你有多少钱,有多少套房子,在哪里上班,有什么职位,有多深的社会背景。因为,从世俗的角度衡量,这才是有用的东西。
同样是炫耀,你要是说这些东西,会赢得艳羡、仰慕甚至是尊重。但是,你若跟别人说,你每天看过多少次蚂蚁奔走,赏过多少次晚霞流逸,听过多少鸟叫,闻过几次花香,你的内心有多安宁,你的灵魂有多快乐,大家认为你,不过是无聊罢了。因为,在他们看来,这些都是无用的东西。
这个世界的价值体系已经乱了,但,你最好不要乱。学会放下一些东西吧,譬如那些不必要的面子,譬如那些无所谓的虚荣。
我是说,这样做,你就是最好地疼惜了自己。
《CutPaste: Self-Supervised Learning for Anomaly Detection and Localization》
1. 不使用异常数据训练出一个高性能异常检测模型
2. 提出了一个2阶段的结构
3. CutPaste:一种数据增强策略,裁剪图片的一部分并随机放在图片的任意位置
4. 因为异常信息分布是没办法提前知道的(你不能知道异常到底会是什么样子,你要提前知道了那就不叫异常了),所以绝大部分单分类模型都是仅仅使用正常样本去得到正常特征,若该模型无法很好匹配某个样本,则认为该样本为异常样本
5. 重构模型或者生成式模型都缺乏捕获抽象的语义信息的能力
6. 目前大多数的模型都主要做的不同类的异常检测(例如训练一个猫的检测器,然后给它一张狗或猪的照片),但对同类的异常检测表现不佳
7. 本文构造了一个两阶段网络,首先使用代理任务进行自监督学习得到一些特征信息,然后使用生成式单分类器学习正常样本的特征分布
8. 本文的创新在于,其提出了一种新的代理任务(proxy task)用于自监督学习,名为CutPaste
9. CutPaste目的是产生一种空间混乱去模拟真实的异常,尽管这种模拟出来的异常和真实异常还是很不一样的,但从结果来看,使用这种方法的模型确实性能更好
10. CutPaste:1)从正常样本种随机裁剪一个大小和长宽比不定的长方形。2)(可选)任意旋转或者调整该区域的像素。3)随便在原图上找一个地方贴上去
11. 自监督损失函数:
其中,CE为交叉熵损失,g为二分类模型,CP为CutPaste
12. CutPaste的变种:1)CutPaste-Scar: 裁剪部分为一个细长的长方形。2)Multi-Class Classification: CutPaste-Scar 和 CutPaste 虽然看起来很相似,但是它们在不同的异常问题有着自己的优势,为了评价它们的能力,文章提出了一个细粒度的3分类器,除了判断是否异常外,还需判断是否为CutPaste-Scar 或 CutPaste的图片。3)Similarity between CutPaste and real defects:CutPaste 创造的图片和真正异常的图片有很大差距,但这并不妨碍它对那种没见过的异常有很强的识别能力
13. 异常定位:这一块我没弄明白,它是随机从正常样本种挖一块出来作为输入样本再重复异常检测步骤?貌似公式就是这个意思呀
其中c函数就是随机从输入x种裁剪一块下来,剩下的就和上面的目标损失函数一样了。有源码,我先看看源码
cp/mv 命令
总是忘记,每次使用这些命令时都不敢确定,稍做记录:
目的目录要不要存在
cp(mv) src dir/dest总结:
若 dest 目录存在,则会将 src 放在 dest 目录下:dir/dest/src
若 dest 目录不存在,则会将 src 放到 dir 目录下,并重命名为 dest:dir/dest
若 dest 存在,且和 src 一个是目录 一个是文件,则报错
源地址要不要加反斜杠
cp(mv) src/ dest cp(mv) src dest这俩有区别吗?有,在不同的系统上表现还不一样。在FreeBSD中,前者是将 src 目录下的内容拷贝到 dest,后者是将整个 src 目录拷贝过去。而在CentOS7中,两者都是将整个 src 拷过去。
故,若想拷贝目录下的内容,应该统一用 cp src/* dest ,而拷贝目录则用 cp src dest
参考:https://blog.csdn.net/weixin_30212009/article/details/116683175
cp 覆盖
使用 cp -rf 可以递归覆盖内容,否则它就会每次遇到相同的文件都会询问
若 -f 命令不起作用,则考虑是否给 cp 设置了别名,导致执行 cp 时默认执行的是 cp -i,这种情况下则可以在cp命令前加一个反斜杠解决(反斜杠的作用就是调用别名的原始命令):
\cp -rf xxx xxx # 或直接使用原生命令 /bin/cp -rf xxx xxx参考:https://blog.csdn.net/xuehuagongzi000/article/details/88657089
一个月230g流量的电话卡
前两天在学校办了一张电话卡,19月租,含200g校园流量(只能在学校范围内使用)和30g全国通用流量
注:
1. 图中显示的是39元套餐,但实际每个月会返还20元话费
2. 此卡需使用两年才能销号
3. 校园卡流量也只有4年,过期后仅有30g国内流量(依旧能打)
稍作解释就能感觉到这有多恐怖
1. 作为对比,移动到现在还没取消5元30m的流量包
换算下来,移动这个约 0.167元/m,而我这个卡约为 0.00008元/m,相差2066倍
2. 初看230g每月可能没啥概念,做一下计算
一部电影2g,若每部电影按2小时计算,一直昼夜不休在线看电影的话,可以连看18天
3. 下载的东西可以把我现在用的电脑硬盘塞满
模拟信号计算机与深度学习
刚看了一个视频,讲的是模拟信号计算机的发展,模拟信号计算机最开始用于计算潮汐涨落,后用于军事。二战期间被数字信号计算机代替。
我突然意识到这东西如果运用到深度学习上可能大有作为。视频作者也是这样想的,于是在第二段视频就是讲模拟信号计算机在深度学习方面的发展。真的是很有意思。
- 模拟信号计算速度快:它不需要复杂的计算电路堆积,例如对于加法计算,你只需要讲两个线路并联就能得到电流相加的结果,对于乘法则只需要根据欧姆定律 V = IR 即可计算
- 模拟信号抗干扰能力差,计算结果不稳定。但对深度学习来说,其本身就是不可预测的。甚至有的时候机器学习就需要这种不稳定的因素存在,例如遗传算法
- 节能。就视频所说,某公司开发出的一款模拟信号芯片,每秒钟计算250亿次仅需3瓦,但使用gpu计算虽然计算能力有上千亿次计算能力,但其功耗也能到上百瓦,且体积巨大
作者提到现在摩尔定律已经失效,这很有可能是模拟信号重出江湖的机会。
我又想到之前看过一些量子计算机的科普视频,我觉得量子计算机和这种模拟信号计算机有很大相似的地方,它们由输入得到输出都不是很依赖计算过程,而是直接给出结果(例如并联电路得到电流数值相加的结果)。
我很期待能看到量子计算机和模拟信号计算机在AI领域有所建树,但又害怕那一天的到来,不知道如果那一天真的来到了,我们这帮学不动的老骨头会不会就被淘汰了。
视频地址:
https://www.youtube.com/watch?v=IgF3OX8nT0w
https://www.youtube.com/watch?v=GVsUOuSjvcg
docker save和docker export及docer commit命令的区别
注:使用import迁移容器后,直接暗转原始run命令是运行不了的,还需要在run命令后面接上容器启动后的命令参数,在原宿主机使用 docker ps –no-trunc 可查看
参考来源:http://www.doczj.com/doc/d95212547.html
即:commit用来将容器dump为镜像,然后使用save将该镜像持久化为文件进行存储和发送
export则类似以上两步的合并,直接将容器持久化为文件
区别在于,前者是新加了一个layer,并保存完整的镜像层,而后者仅仅相当于当前容器的快照,相当于将所有的镜像层合并为了一层
用法:
docker commit -a "提交的镜像作者" -m "提交时的说明文字" a404 ubuntu:load docker save -o ubuntu.tar ubuntu:load docker load -i ubuntu.tar docker export -o ubuntu.tar a404 docker import ubuntu.tar ubuntu:import分类模型常用性能评估方式
准确率的缺陷
某些情况下,准确率并不能很好得反应模型的性能。例如:若100个样本中,90个正样本,10个负样本。模型A将它们全都预测为正样本,则准确率为 90%,若模型B将90个正样本中的80个预测为正样本,且将10个负样本中的9个预测为负样本,则其准确率为 89%。单从准确率来说,模型A要优于模型B的,但从实际结果来看,模型B的性能要更优于A的。
所以就需要一些新的模型评判标准
ROC曲线
Receiver Operating Characteristic curve
二分类器通常输出一个样本为正的概率,例如模型对某张图片预测为猫的概率为0.7。单就这个概率来讲,你不能说模型是否任务图片是不是猫,你还需要一个阈值。例如,若阈值为0.5,则认为该图片是猫,若阈值为0.8则不是。
在指定某阈值的情况下,使用二分类器对样本进行预测可得以下四个数值,例如:TP 表示正样本中预测也为正的样本总数
由此可计算出:
1. 所有正样本中,预测为正的概率(或:所有正样本中,预测正确的概率。亦或:预测为正的样本中,预测正确的样本在所有真正为正样本中的占比)。其本质是预测正确的概率,应该越大越好。(也就是下文中的recall召回率)
\[ TPR = \frac{TP}{TP + FN} \ ]
2. 所有负样本中,预测为正的概率(或:所有负样本中,预测出错的概率。亦或:预测为正的样本中,预测错误的样本在所有真正为负样本中的占比)。其本质是预测出错的概率,应该越小越好
\[ FPR = \frac{FP}{FP + TN} \ ]
在最开始100个样本的例子中,模型A的 TPR=90/90=1,FPR=10/10=1。模型B的 TPR=80/90=0.89,FPR=1/10=0.1。虽然模型A的TPR很高,但是其FPR也高。模型B则TPR远高于FPR,由此可知模型B要更好一点
同一个模型,分类阈值设定不同,其 TPR 和 FPR 也会不同。例如:若将阈值设定很小,则 TP 和 FP 就会增大,使得 TPR 和 FPR 都增大(最大都为1)。反之,两者都会趋近于0
由此,设定不同的阈值,每个阈值下都能得到一个坐标对 (TPR, FPR),若将该坐标画在平面坐标系上可得:
(截图来自:https://blog.csdn.net/u013385925/article/details/80385873,不用在意上面的数字,知道有这些点就够了)
再将它们连在一起可得一条曲线,这就是 ROC 曲线
AUC(AUROC)值
Area Under Curve(Area Under Receiver Operating Characteristic curve)
TPR本质上是某种预测准确的概率,所以其越高越好,FPR本质是某种预测错误的概率,故应该越低越好。
从ROC角度来说,若一个模型的 RPR > 0.5 而 FPR < 0.5 则说明其预测效果优于随机瞎猜
马尔可夫决策过程
马尔可夫性
简单表述为:下一个状态只与当前状态有关。
例如下象棋就满足马尔可夫性,但斗地主则不满足。因为对于象棋来说,你仅需看到当前棋子位置便能做出下一步的决策,例如残局。但斗地主则不行,你不能只看当前自己的牌面去选择打什么牌,你还需要记住已经打过哪些牌了才能做出最好的决策,这就和历史状态有关了。(当然,如果将已经出牌的过程作为当前状态的要素,则也是满足马尔可夫性的)
用公式表示为:
$$ P(s\_{t+1}|s\_t) = P(s\_{t+1}|s\_t, s\_{t-1}, s\_{t-2}...s\_0) $$解释为:从状态 \( s\_t \\) 转移到状态 \(s_{t+1}\) 的概率与从状态 \(s_{t0}->s_{t1}->…s_t\) 转移到 \(s_t\ ) 的概率相同
马尔可夫链(MP)
或称马尔可夫过程,满足马尔可夫性的状态转移过程
如下图看着貌似复杂,其实很简单,就是从一个状态转移到另一个状态的概率。例如从宿舍去网吧的概率为30%,而从宿舍到教室学习的概率为50%,还有20%的概率是呆在宿舍。
这些状态转移的过程就形成了一条条的链,例如:从宿舍到网吧,再到健身房,再成为三和大神就是一条链。
马尔可夫奖励过程(MRP)
上面图中的每个状态都对应一个奖励(图中表示的就是自信心增长程度,可能为负)。
宿舍 -> 网吧 -> 健身房 -> 三和大神 这个过程的总奖励(最终精神状态)为 -1 -2 +10 -30 = -23
但是,我从网吧出来有可能去健身房最终走向人生巅峰,也有可能直接成为大神,它们的奖励不同,我该如何评价我在网吧这个状态呢?显然你不能简单得说它是好还是不好。最简单的方式就是计算该状态下,可能得到所有奖励的数学期望。即:
$$ R\_s = \\mathbb{E}[ R\_{t+1} | S\_t = s ] $$\( t \\) 时刻的状态 \( S_t \) 为 \( s \),其下一个时刻 \( t+1 \) 可能进入 \( S_{t+1} \) 状态,该新状态得到的奖励值为 \(R_{t+1} \),\( R_s \) 即为所有可能的 \( S_{t+1} \ ) 状态奖励的期望。
U盘安装操作系统原理
.iso文件
由于光盘具有只读特性,导致其数据较为安全,故windows早期发布系统都是使用光盘刻录。但现在很少有人使用光盘了,而是使用系统镜像文件模拟光盘,该文件一般为 .iso 文件,也有其他格式。
一个iso文件就是将一张光盘的内容全部打包的文件,包括文件的内容以及文件系统相关内容等等。
简单的说,你可以直接将一个iso文件理解为一张光盘(或者一个需特定硬件才能读取的硬盘)
虚拟光驱
早期电脑上都带有物理光驱,你可以将光盘放进去,通过该光驱电脑就可以读取光盘的内容。
虚拟光盘iso文件也需要一个光驱才能读取,只不过这是一个软件虚拟出来的光驱。windows系统下自带虚拟光驱,故它可以用来读取iso文件的内容
装载功能就是使用虚拟光驱加载虚拟光盘iso文件,这就是在模拟物理光驱装载光盘的过程,所以它叫装载。事实上,其本质就是对该文件进行解压缩操作。
装载完成后,你就可以在资源管理器中看到该虚拟光盘了
此时你就可以自由读取该虚拟光盘中的内容了,完成操作后,你可以像取出真实光盘一样,选择弹出该虚拟光盘
U盘安装系统
1. 烧录镜像
U盘安装系统本质就是在模拟光盘安装系统。比如软通碟、balenaEtcher这类软件本质就是一个虚拟光驱,制作U盘启动盘时,实际上是在:
格式化U盘,将其格式改为光盘的形式(让系统将U盘识别成光盘)
烧录iso文件的内容到U盘(即制作一个有系统安装文件的光盘)
这样,你的电脑bios启动时就会将u盘当作一个系统光盘使用,它就能安装操作系统啦
2. U盘启动盘
类似于老毛桃、大白菜这类的,它就是将你的U盘当作一块硬盘,并在里面安装一个pe操作系统,该操作系统带有虚拟光驱,然后读取iso镜像文件并将系统安装到电脑的硬盘上
U盘启动盘
很多时候安装系统需要先制作一个U盘启动盘,例如使用Rufus、UltraISO、Etcher等工具。制作U盘启动盘需要使用一个iso文件,前文说iso文件其实就可以看成是一个光盘,那么U盘启动盘是什么呢?
早期的主机都有一个物理光驱,安装系统时需要将光碟放入光驱中进行系统安装,而现在的机器都没有物理光驱,且光盘也是使用iso文件模拟出来的。U盘启动盘其实就是在模拟一个物理光驱,向里面烧录的iso文件其实就相当于向该光驱中插入了一张光碟。然后设置系统从该U盘启动,引导系统执行光碟(iso)中系统安装的流程。
另外还有一种方式是在U盘中安装一个PE系统,然后在用该PE系统安装系统,虽然都是用U盘安装,但这种做法和使用U盘启动盘是完全两种原理,U盘启动盘是直接模拟物理光驱直接安装系统,而PE更多用于系统的维护备份等等,安装系统只是它的功能之一。
在windows下,其实可以直接将iso文件挂载到文件管理器,然后手动点击执行系统安装文件进行系统安装。
既然U盘启动盘是在模拟物理光驱,那么为什么在制作U盘启动盘的时候还需要指定iso文件呢?物理光驱和光碟不应该是解耦的吗?
光碟其实就可以理解为一个不可修改的硬盘,它里面也有mbr引导分区用于引导安装操作系统,这也就意味着iso文件种应该也存在模拟mbr分区的这部分数据。直观感觉上,应该是先制作一个和iso无关的U盘启动盘,然后需要什么iso文件就直接拷贝进去即可。但这里的关键就是U盘其实也是一个存储介质,按照这种说法来讲,要想从U盘启动,首先U盘自己就得有mbr分区,然后再去装载iso的mbr,这其实是pe系统安装了,而不是U盘启动盘安装。U盘启动盘的做法是直接讲iso文件的mbr作为U盘启动的mbr。所以理解这个问题的关键就是,U盘也是一个磁盘,并非真的光驱。
PE系统
一个临时用的系统,或者可以认为是双系统中的一个,或者是装在U盘中的系统。
总之,意思就是说,它是安装在另一块盘(相较于原本系统安装的C盘来说的,可以是其他硬盘或者U盘)和原来的系统共用一套硬件的系统。
它和双系统是差不多的,只不过电脑安装双系统一般都是安装到两个不同的盘符上,而PE一般安装在U盘上的。它们都是在电脑启动时选择进入哪一个系统,我们知道,系统本质上只是软件,而软件本质上只是文件,所以无论进入哪一个系统,你都能直接访问电脑上的其他硬盘(或U盘),进而找到其他系统文件所在的目录。
有些电脑主系统可能由于存在恶意文件或其他东西,进不去系统或蓝屏等,此时就可以进入PE系统去删除原本系统目录中的恶意文件了。
此时就有个问题,那我其他盘中存放的文件是不是可以直接在PE系统中读取了?确实是这样,所以如果有保密方面的需求,最好将文件加密。
U盘安装PE系统后仍然是可以当作正常的U盘来使用的,就像你在C盘装了系统后,仍然可以在C盘自由存取文件一样
PE系统里面一般会安装很多的工具软件,例如磁盘分区软件、密码破解软件等,比较有名的PE系统例如 微PE 优启通 等,它们内置了各种各样的工具,有些PE系统支持联网。
那我是否可以在一个U盘上安装多个PE系统,取长补短?当然是可以的,使用 ventoy 这个软件就行,安装多个PE后,启动时会让你选择启动哪一个PE
马丁格尔与反马丁格尔策略
游戏规则
押大小,押多少钱赚多少钱。例如,押1元,赢了得2元,输了就亏1元,押5元,赢了得10元,输了亏5元
马丁格尔策略(Martingale)
输的情况下持续翻倍下注,直到赢。
(游戏开始)第一局押1元,赢了收手赚1元,游戏从头开始,输了的话第二局赌注翻倍
(第一局输)第二局押2元,赢了收手赚 2 - 1 = 1 元,游戏从头开始,输了的话第三局赌注翻倍
(第二局输)第三局押4元,赢了收手赚 4 - 2 - 1 = 1 元,游戏从头开始,输了的话第四局赌注翻倍
(第三局输)第二局押8元,赢了收手赚 8 - 4 - 2 - 1 = 1 元,游戏从头开始,输了的话第五局赌注翻倍
。。。
可以看到,这种情况下,每次只会赢1元,只要赌资足够多,就不存在亏损
数学期望
假设某游戏输的概率为 p,赢了的话可得押注的k倍,赌徒初始押注 b 元,输了的话下一局押注为上一局的s倍,一直连输n局爆仓(假设赌资有限,无限的情况不符合实际),则:
连输 n 局的概率为 \( p^n \\),到第 n 局一共押了 \( \sum_{i=1}^{n}b*s^{i-1} = b(s^{n-1} + \frac{1-s^{n-1}}{1-s}) \ )
n 局中至少赢一局的概率为 \( 1 - p^n \\),假设第m次赢,则可赢 \( b*k^{m-1} - \sum_{i=1}^{m-1}b*s^{i-1} = b(k^{m-1} - s^{m-2} - \frac{1-s^{m-2}}{1-s}) \ ) 元。
Springboot中的ClassPathResource
现象
在获取resource目录下的文件时,我发现一个现象:
如图,我分别在classpath和resourcepath下放了两个文件,然后使用ClassPathResource去获取这两个文件,使用相同的路径形式,我发现它们竟然可以被正确找到
原因
Springboot中定义了很多资源加载器,其中就有两个文件资源加载器
sun.misc.URLClassPath
使用ClassPathResource传入一个路径时,它就会遍历这些加载器,若某路径存在该文件,则返回,否则抛出IOException
sun.misc.URLClassPath
jar包问题
当把项目打成jar包之后,本来正常读取resource的代码又报文件找不到异常。
以后有机会再看看这种问题的最佳实践
当前最好的方法还是将一些文件放在项目以外的路径中保存
一个webfont精简服务
由于中文汉字数量巨大,导致一个字体文件动辄好几M。一个页面为了渲染几个字而加载这么大的文件实属不划算
一个想法是创建一个在线服务,将需要渲染的文字发送给该服务,它就能将原始字体文件进行裁剪,使其只包含要被渲染的文字即可,这样一个字体包也就几k了
基于这种想法我开发了一个web服务,详情及源码:https://github.com/HuntZou/webfont
效果如图:
搞了两个手续费较低的期货账户
某大学室友从大二就开始研究期货,目前也是全职搞这个,昨天联系他让帮忙介绍两个期货公司经理,想申请个较低的手续费账户
我是没想到那么轻松,我就给他们说了一下,一个给我 加一分和90%的交返,一个给我+0和70的交返(欲得交返,月交易得到十万),中间没有任何波折,我以为还要扯半天呢
浏览器使用webfont加载自定义字体
有时候为了美观想要在网页中使用一些特殊的字体
font-family
可以使用css中的font-family属性
它支持cursive、fangsong、sans-serif、serif等属性值。有三点需要注意:
1. 只有在本机中安装了某个字体,font-family属性设置的值才会生效。例如:设置font-family: “华文仿宋”,若本机没有安装该字体,则该字体设置无效,回退到默认字体显示
2. 上述的 cursive、fangsong、sans-serif、serif 等并不是某个字体名称,而是一类字体名称。例如 cursive 表示草书,若你电脑中安装了归类为草书的字体,则使用该字体,否则回退到默认字体。
3. 正是因为以上两个特性,font-family支持同时指定多个字体。例如京东网站的设置:
可以看到它同时指定了特定字体、字体类别。当前一个字体设备不支持时,自动检测下一个字体。其最后设置的是 sans-serif,这是一种无衬线字体类别,一般设备都有该类字体,也算是最后的fallback。
webfont & font-face
有时候我就想用某种字体,而它又不是所有设备都安装的怎么办?那就可以考虑使用webfont,一种让网页自备字体的技术。
font-face可以让网页主动加载某种字体
font-face API: https://developer.mozilla.org/zh-CN/docs/Web/CSS/@font-face
<css> @font-face { font-family: "some font"; /*为了兼容性,可以同时加载多种格式的字体*/ src: url("https://www.somewhere.com/some-webfont.woff2") format("woff2"), url("/somewhere/some-webfont.woff") format("woff"); font-weight: normal; font-style: normal; font-display: auto; } .my-class { font-family: "some font", serif; } </css>但这样有两个非常大的问题:
1. 字体文件较大,网络加载缓慢
webfont在欧美发展比较成熟,原因是拉丁字母就那几个,所以一个字体文件也就几kb,几乎不影响网页加载。但汉字有好几万个,这导致一个中文的字体文件普遍在3-10Mb左右,加载很慢
2. font-face有个font-display属性,该属性默认值为auto,一些情况下,这会导致字体先不显示,过一会再以默认字体显示,再过一会才会以设置的字体显示,视觉体验及其割裂。
设置为auto或block时,其渲染过程为:阻塞文字渲染(导致显示空白),等待字体下载完成。在chrome中,若3秒后还没下载完成,则先使用默认字体渲染,字体下载完成后再使用指定字体重新渲染(其他浏览器可能会有不同)
当然,也可以设置成swap,就没有阻塞过程,直接使用默认字体渲染,但也会出现割裂。
font-display API:https://developer.mozilla.org/en-US/docs/Web/CSS/@font-face/font-display
能不能快一点
有两种办法(本质是一样的):
1. 在字体文件中只抽取页面中使用过的汉字
有个叫 font-spider 的工具,它可以根据网页内容大大精简字体文件,我没用过。
期货开户知识
期货交易所 vs 期货公司 vs 同花顺
所有的期货交易需在交易所完成,但需要一定资质才能在交易所开户交易。所以我们可以通过期货公司间接帮助我们交易,他们在交易所开有账户。我们在期货公司下单后,期货公司会帮我们去交易所完成下单。我们可以开通很多期货公司的账户,为了便于管理这些账户,就可以将他们都绑定到一个同花顺账户上,这样就可以在同花顺中随意切换期货公司账户进行交易了
我国目前有6个期货交易所
有149家期货公司
例如:银河期货有限公司、国泰君安期货有限公司、华鑫期货有限公司 等
开户
个人一般没有资质直接去交易所开户,故我们一般去开某个期货公司的户。
可以直接下载对应期货公司的app开户,或者直接去公司官网开户,或者联系公司内部经理人开户,亦或直接在同花顺里面也能开各个公司的户。
开户的方式会影响日后交易的手续费。一般来说,直接联系公司内部经理人开户能拿到较低手续费,因为你可以和他讨价还价。去公司官网开户手续费较高,因为他默认欺负你是小白,啥都不懂
手续费
交易就会产生手续费,有些是固定的,有些则是按成交比例计算的
手续费分为两部分:交易所 + 期货公司
交易所的手续费一般固定不变,期货公司手续费由他们自己定。
例如某产品一手交易手续费为:交易所收取3元 + 期货公司收取0.5元 = 共3.5 元
期货公司手续费最低能到0.01元,需要有关系
保证金
简单理解为购买价格
若某产品1000元一吨,一手为10吨,则一手的价格为10000。
但期货交易是自带杠杆的,它都会有一个保证金率。例如,若上述产品保证金率为10%,则买一手的价格为:
$$ 1000\_{元/吨} \* 10\_吨 \* 10\\% = 1000\_元 $$
上图中 1手保证金计算过程为:4000 * 10 * (10%+3%) = 5200 元
保证金率
保证金率也分为两部分:交易所 + 期货公司
交易所保证金率一般固定不变,期货公司则会在其基础上做动态调整(增加)
例如:某产品交易所保证金为 12%,期货公司追加8个点,则对用户来说,保证金率为20%
一般来说,新人的保证金率会更高,因为保证金率越高,杠杆率越低(10%保证金下,你花10块钱就能买100元的东西,20%保证金下得花20元),对于期货公司来说,其风险就越低
股票、期货、期权
股票没有杠杆,100块的股票就必须要用100元买
期货与股票差不多,但期货有10倍左右的杠杆,100块的商品只需要花10块钱就能买到
期权杠杆更高,和股权类似,它规定你可以在一段时间内以一定价格购买某种商品,这个钱最终是不会返还的,相当于花钱买了个权力。股权是赠与的,而期权是花钱买的
例如:
S 股票股价为100元
F 期货的标的物为S股票,一手保证金为10元。按每股100元交割
O 期权的标的物也为S股票,一手为1元。规定三个月内可以按照100元的价格购买S股票
现在你手上有100元现金,你有三个选择:
- 买1手股票
- 买10手期货——相当于买了10手股票
- 买100手期权——相当于买了100手股票
一个月后,该股价上涨为102元,则上面三个选择的结局为:
- 赚了2元——卖出股票,涨多少赚多少
- 赚了20元——若选择交割,则可以按90元(因为还交了10元保证金)的价格买入10股S,后以市场价102元卖出,净赚20元
- 赚了100元——可以按照100元的价格买入100股,再卖出,赚200元,但因为花了100元买这个期权,这是不会返回的,故净赚100元
参考:https://zhuanlan.zhihu.com/p/342208525
DQN学习与实验
实验环境
dqn本质上只是使用函数去拟合qlearning中的qtable
本文将训练ai完成 Frozen Lake 游戏,一个4*4大小的格子表示一块冰面,冰面中有一些随机的破洞,这些洞一旦指定就不会改变,agent的目标就是从格子的左上角成功走到右下角。
每个格子标号为1-16,即agent的observation为1-16。agent的action为0-3,分别表示上下左右移动
详见:https://www.gymlibrary.dev/environments/toy_text/frozen_lake/
QLearning
import gym import numpy as np import random # qTable qtable = np.zeros(shape=(4 * 4, 4)) # 学习率, alpha = 0.5 # 折损率,未来得到的奖励多大程度上依赖当前行为 gamma = 0.8 def choose_act(state): # return random.sample(range(3), 1)[0] # 在qTable中找到当前状态下最优的动作,若最优动作有多个,则随机从中选择一个 return random.sample(np.where(qtable[state] == np.max(qtable[state]))[0].tolist(), 1)[0] def qlearning(): env = gym.make('FrozenLake-v1', desc=None, map_name="4x4", is_slippery=False, render_mode='human', new_step_api=True) state = env.reset() # 进行1000局游戏 for i in range(1000): # 每一局都可以进行无限步,知道该局游戏结束 while True: act = choose_act(state) # terminate表示该局游戏是否终止,truncated表示该局游戏是否为不正常结束,例如由于时间限制,或agent跑到地图边界外了 next_state, reward, terminate, truncated, info = env.step(act) # 惩罚条件,由于该游戏原本只有成功奖励,而没设置惩罚条件,所以导致agent学不到错误的知识,训练过程异常缓慢 # if state == next_state or truncated or (terminate and reward == 0): # reward -= 1 # reward -= 0.1 # 根据贝尔曼方程更新qTable qtable[state, act] = (1 - alpha) * qtable[state, act] + alpha * (reward + gamma * np.max(qtable[next_state])) state = next_state env.render() if terminate or truncated: state = env.reset() break if __name__ == "__main__": qlearning()使用qlearning处理这种小型离散认为可以很快收敛
OpenCV中的Canny()函数
Canny()函数用作检测图像中的边缘。
实现
1. 降低噪音
因为边缘检测易受噪声的影响,故Canny函数会首先使用 5*5 的核进行高斯模糊处理
2. 找到高梯度的位置
使用 Sobel kernel 做横向和纵向的检测。
对 Sobel kernel 的解释(纵向为例):
显然,使用Sobel kernel可以计算像素间灰度值的梯度,梯度越大,则说明色差越大,则越有可能是某种边缘。
随后,将横向和纵向梯度相加,计算出实际梯度和角度
3. 使用非极大值抑制减少候选区
关于非极大值抑制不做过多解释,其作用是:如果多个候选区有重叠的部分,则只选取其中一个候选区即可。
4. 阈值筛选
显然,从梯度计算方式来看,其可能计算出各种大小值的梯度,如何判断哪些梯度可被视作为边缘则需要用户指定一个阈值。例如若用户指定阈值为100,则若检测梯度大于100,则其一定认为是边缘。若其梯度小于50(opencv规定下界阈值为上界的一半),则其一定不是边缘。对于大于50而小于100的部分,如果其与梯度大于100的边缘相连着的,则也认为其是边缘,否则,则不是边缘,丢弃。
上图中,A线超过maxVal的部分被认为一定是边缘,因为C线与A线相连,且其没有低于minVal,所以它也被认为是边缘。B处于两个阈值之间,但独立存在,故其不会被认为是边缘,丢弃。
参数
写本文的目的也是因为绝大部分中文博客互相抄来抄去,都抄的是错的。特别是哪个threshold1参数,几乎没看到对的
threshold1参数表示上述原理中第四步中的maxVal(上界阈值),它指的是梯度,而非绝大多数人说的像素值。
threshold2指的是minVal,也是梯度值
参考
本文大部分译自官网说明:https://docs.opencv.org/3.4/da/d22/tutorial_py_canny.html
api说明:https://docs.opencv.org/3.4/dd/d1a/group__imgproc__feature.html#ga04723e007ed888ddf11d9ba04e2232de
Proof-of-stake(POS)是如何工作的
以太坊昨天完成了从pow到pos的升级,这将大大节省资源,但同时也可能隐含巨大的隐患
什么是共识机制
区块链本质上是一个数据库,它满足以下特性:
- 它同时有多个管理者,只有他们有权修改数据库,每个管理者手上都有该数据库的备份。
- 对数据库做任何修改操作都将获得奖励。
- 必须保证任何时候都有一半以上的管理者手上是数据库备份是一致的。因此,对数据库任何的修改请求都必须获得大多数管理者的同意。
故,一旦有人发起了修改数据库的请求,所有的管理者都会抢着作为该请求的负责人。问题来了,到底该让谁负责该次请求,这就需要所有的管理者达成一个共识。
POW vs POS
一种做法是,当一个请求来的时候,让所有管理者猜字谜(挖矿),谁猜到就让谁负责,当然,谁负责谁就受益。并且,由于这是大家都同意的竞选方式,所有人都需要跟着该负责人一同修改数据库。这种猜字谜选择负责人的方式就是 POW。
由此可以想象,假如某个管理者有很多的随从(显卡),那他就可以让这些人一起帮他猜。哪个管理者的随从多,谁就更可能猜出这个字谜。
另一种做法是,当一个请求来的时候,随机从所有的管理者中选取一个来负责。这样就不需要管理者有很多随从了。这种做法就是 POS。
当然,这里的随机肯定不是普通的随机,它必须是所有人都认可的一种随机方法
POS
pow机制中,任何人都可以当管理者,反正都是猜字谜,各凭本事即可。但若想成为pos中的管理者,则至少需要交一定量的保证金(比如38ETH)。只有你交完保证金成为管理者后,你才有机会被选中当作某次修改数据库的负责人。
如果你被选中了负责某次修改请求,你就必须校验该次请求是否合法(验证区块内的交易是否都合法),这其中也包括对之前以及提交的请求的校验。若没问题,你就可以向数据库提交修改了,同时其他管理者也需随你一同修改自己身上的数据库。
倘若你胡乱修改数据库,被后续其他负责人发现的话,你的保证金就没了,同时后续的选举你也无缘了。
如果你尽职尽责带领所有管理者完成了该次修改请求,那么你将获得一定量(但远小于保证金)的奖励。
pow验证者的选举
有些人他就要富贵险中求,不就是38ETH嘛,没了就没了,但要是没被发现,那就赚大了。所以pow还规定,谁交的保证金多,谁就更有机会成为责任人。
这就是一个博弈的过程了,由于大家都希望成为责任人得到奖励,所以大家的保证金也就越交越多。保证金多的话再去作弊那就不划算了。所以就必须老老实实,尽职尽责。
但如果只是这样的话,有钱的是不是就越来越有钱了。因为我有钱能交更多保证金 —> 我就更有机会成为责任人获得奖励 —> 我就又有更多钱交保证金 —>…
确实是这样的,为了解决这个问题就引入币龄的概念。币龄 = 你的保证金 * 持保证金天数。其使用方式如下:
例如你交了100保证金,我交了200保证金。第一天,我成为责任人的几率是你的两倍(因为我保证金是你的两倍,同时我们的持币天数都是0。注:真实情况不一定是两倍,可能是其他概率算法)。
假设第一天我当选了,那么第二天你的币龄就是 100*1=100,加上你本身有100保证金,两者相加就是200。而由于我第一天当选了负责人,规定当选负责人的后一天持币天数又从0开始记。所以第二天我的币龄还是 100*0=0。我只有200保证金,而你币龄加保证金也有200,故我俩当选为责任人的概率是一样的。
假如第二天还是我当了责任人,那么第三天,我就还是只有200保证金,而你两者加起来则有 100*2+100=300,显然,此时你当选责任人的概率就比我高了。
如此,就算你交的保证金不多,也是有机会成为责任人的
51%攻击
对于pow来说,只要你拥有了大于全网51%的算力(一半以上管理者联合起来一同作弊),你就可以完全控制该区块链。
对于pos来说,只要你拥有大于全网51%的保证金,你就有可能成功作弊,因为下一个负责人验证上一个负责人的工作,只要你能连续两次当上负责人,你就可以成功作弊了。但这需要你能有数额巨大巨大巨大的保证金,对于以太坊这样的链基本上不可能。
参考
https://www.youtube.com/watch?v=M3EFi_POhps
https://www.youtube.com/watch?v=YudpU58uYuM光棍节转正了?
刚看了下手机上的日历,发现11月11日被标记为了光棍节,随后又翻看了其他月份,节气显示倒也正常。
像什么感恩节、圣诞节被标记在日历里我倒是还能理解,毕竟人家也算是国外正经的节日。可为什么光棍节也能标在上面呢。印象中小时候没有所谓这个节日,记得其来源还是在高中时代,有些人本着好玩的心理,因为11.11号是四个1,代表单身,故将其戏称为光棍节,或者它本身就是淘宝当初做的一场营销,它本身就不是一个节日啊。
《无耻之徒》第四季劝退
目前看到第5季第2集,前面看着还好,到第4季的时候就越看越不舒服。
前三季虽然日子过得不怎么样,但是总让人觉得一家人在菲欧娜的照顾下还算温馨和谐,第四季就感觉突然大变样了,甚至有点让人觉得活该,特别是菲欧娜。也可能是编剧想表现孩子们都长大的叛逆心理,第四季反正就是各种吵架,各种不回家,所有人都天天在外面了,确实没有一家人的感觉了:菲奥娜入狱、lip上大学、伊恩从军队跑出来后去gay厅上班、黛比天天说自己不是小孩子了去外面混、卡尔一直让人觉得可怕,什么坏事都敢做(但貌似后面成了警察惩恶扬善了)第四季也是天天在外面干坏事。反正整个第四季看着非常不舒服。
尤其是菲欧娜,有男朋友的情况下还去勾引自己的老板,然后又突然和老板的弟弟搞上了,后来老板的弟弟毁了她和老板的关系并且还让她入狱了,她居然不是拿刀去砍他而是又继续找到他。尤其是我看到她已经判入狱之后,违反假释期规定跑到他家里去那一刻,我真觉得她过成那样就是活该。当然,整部剧都会出现很多毁三观的剧情,但我觉得其他毁三观的剧情只能算是为了制造矛盾而出现的剧情,这段剧情是真的让人感觉操蛋
我不打算继续看了,或许偶尔还会看上一两集。一个原因是第四季真让人太不舒服了,另一个原因是刚才无意间看到了剧透,每个人的去向现在也都知道了。
第四季真的让人感觉,剧中每个人悲惨的遭遇都是活该,不知道是不是刻意这样表现的还是怎么着
说来我也是看过不少欧美剧了,越狱、神探夏洛克、硅谷、绝命毒师、生活大爆炸、行尸走肉看了好几季,后面也看不下去了,反正看到貌似叫库屠的大反派杀了很多队员,后面卡尔也死了怎么着的,据说后面大反派还洗白了,因为觉得后面的剧情越来越刻意越来越像做任务,就没看了。老友记看了几集,还是觉得生活大爆炸有意思一些,绝命毒师看了两遍,第二遍就觉得他老婆太恶心了,或许也是看了一些网评的原因,整部剧还是挺好看的。
Double DQN
为什么需要DDQN
DQN使用QFunction拟合QTable,既然是拟合,就会出现和真实QValue不一致的情况。
QFunction迭代更新的方程是一个递归方程
$$ Q^{new}(s, a) = reward + λ\*max(Q^{old}(s', \*)) $$可以看到,更新 s 状态下 a 对应动作的qValue需要用到下一个状态 s’ 所有动作中的最大qValue。但 s’ 的最大qValue也是使用QFunction估计出来的,其估计值很可能偏大(因为你取的就是估计值中最大的值)。这就造成 Q(s, a) 计算出比实际情况更大的qValue,由于这是递归方程,其会使得后面的qValue越来越大,偏离实际情况。
DDQN
一个解决方法是将计算 Q(s, a) 的function与其依赖的 max(Q(s’, *)) 的function解耦,让它们使用不同的function计算,减少两者的相关程度。
打个高考填志愿的比方,如果让你自己估分填志愿(eval_net),你可能会由于主观因素高估或低估自己的分数,这会使得志愿填报的学校偏离实际。但你可以让你的老师给你估分(target_net),因为你的老师常年和你呆在一起,他的估分可能更加客观并且接近实际情况,此时再填志愿就靠谱很多。
所以DDQN的方程可以写为:
$$ Q^{new}(s, a) = reward + λ \* Q^{eval}(s', argmax(Q^{target}(s', \*))) $$可以看到,方程先是需要通过 target_net 找到 s’ 状态下qValue最大的action(此时也是拟合值),然后使用 eval_net 去计算 s’ 状态下,该action对应的qValue。这样做的好处是 找到 s’ 对应最大qValue值和需要更新的eval_net无关了,相当于定点打靶了
DQN中的一些问题
模型始终不收敛
这篇文章使用DQN网络训练agent平衡杆的游戏,代码可以正常运行
此时,若删除target_net,只保留eval_net,多次运行后发现,有时候模型一直都不会收敛(长时间训练后,agent仍然不能维持杆的平衡,表现仍和随机action一样)。
异常情况
正常情况
为什么DQN需要两个网络
通常在网上找到的DQN代码一般都有两个网络:eval_net 和 target_net,两个网络初始时同步参数,eval_net会在每次训练后都更新参数,target_net则仅会在多次训练后(例如10次)才会和eval_net同步一次权重参数。使用过程中,用eval_net计算当前qvalue,使用target_net计算期望qvalue。为什么要这样做?
如上个问题所述,即使去掉target_net,有时候模型也能正常训练。
- 若仅使用一个网络,由于贝尔曼方程是一个递归方程,其函数本身也用到了自身,如果函数本身一直在变,而你又依赖这个一直在变化的函数去企图收敛一个函数,就像打靶射击移动靶位一样困难
- 便于实现Double DQN。Double DQN
https://ai.stackexchange.com/questions/6982/why-does-dqn-require-two-different-networks
https://blog.csdn.net/weixin_46133643/article/details/121845874?spm=1001.2014.3001.5501
Pytorch官方DQN教程模型不收敛
我将pytorch官方DQN的教程代码复制下来运行一晚,貌似也没有收敛(平衡杆游戏,橙色的线代表一段时间游戏的平均时长,越高越好。官网说运行300个episode就会有效果)
同时测试删除里面的target_net,只保留eval_net同样是不收敛
pytorch中的gather方法
gather的本质是构建一个索引矩阵来获取数据
gather需要两个参数(dim, index),其中index为一个索引列表,里面元素为要修改为的索引。其形状和最终生成的结果形状一致,且与要修改矩阵的位置一一对应(如上图)。dim表示要修改哪一个维度的索引,例如,对于二维矩阵来说,dim=0则修改索引第一维,dim=1则修改第二维(如上图)
摄影中的对焦及虚化原理
为什么会出现虚化
凸透镜会将平行光汇聚在一点,但正常情况下,物体的每个点都会像各个方向反射光线,类似于点光源。
如图,有橙色和蓝色两个物体,他们离镜头距离不同,从它们顶端发出的点光源经过凸透镜分别汇聚与B、A两点,过这两点后光线会继续分散开来。
而镜头位置恰好在B焦点所在位置,而蓝色光线经过焦点A后继续发散,到镜头时已经分散成一个光斑了(称为弥散斑)。这就是为什么最终成像后,橙色物体成像清晰(光斑很小而已),而蓝色物体呈现虚化效果(光斑较大)
若要清晰拍摄蓝色物体,可移动镜头(或cmos)(当然还有其他方法,下面会介绍),使得A点正好到相机位置,这就是对焦过程
网上看到另外一张图,线比较清楚。一个意思
光圈大小影响背景虚化效果
在上图镜头前加上一块挡板,遮住上半部分的光线,可以看到最终成像中,除了颜色变暗之外(光线减少),橙色物体依然能清晰成像(相机处于其焦点上,使得光斑很小),而蓝色物体由于部分光线被遮住了,导致其光斑变小了。直观感觉就是物体显示更清晰了(背景虚化减弱),但画面整体亮度减少。
为什么点光源通过凸透镜会有焦点
- 平行光会穿过凸透镜焦点
- 过凸透镜中心的的光线不会发生折射
- 过凸透镜左焦点的光线会垂直透镜射出,反过来想比较简单,想象从成像焦点发出一条平行线
以上,它们就会汇聚在一点
长焦镜头
如果想拍远处的物体则需要用到长焦镜头,如下图,对于远处一个绿色的物体,使用长焦镜头拍摄的物体比使用短焦拍摄出来的更大,更清楚。(注:相机的cmos位置对不同镜头是不一样的,需处在不同镜头对焦位置)。但由于cmos就那么大,故长焦镜头拍摄出来的视野较小
关于对焦
就上图而言,若想拍摄出清晰的蓝色物体,有四种方法:
- 将镜头向后移动,直到A点到达相机的cmos(定焦镜头、变焦镜头)
- 向前移动相机cmos,直到A点(定焦镜头、变焦镜头)
- 向右(镜头方向)移动蓝色物体,直到其到达橙色物体附近
- 换个长焦镜头,或者改变当前镜头焦距(变焦镜头)
前三个方法很好实现,方法1和2也解释了定焦镜头对焦原理。方法4则比较困难,因为单个镜头的焦距一般都是固定不变的,故变焦镜头实际需要多个镜头组合完成变焦功能,相对来说成本更高。
手机镜头怎么对焦
手机摄影时自动对焦也是会移动镜头的。通过微型电机或微型电磁铁移动镜头位置
https://www.zhihu.com/question/21992503
相机镜头怎么对焦
因为镜头中有驱动电机,也能够改变镜头位置。
早期有些相机是通过机体内部电机来驱动镜头对焦,但对于长焦镜头来说(镜头本身也比较长),这种驱动方式很费劲,所以这些镜头就直接通过内置电机来驱动镜头,相机只负责发送对焦信号。或者镜头本身可以通过激光或超声波的方式测量物体距离,自动对焦
关于pytorch强化学习教程的一些注释
pytorch官网给出了一个使用DQN网络实现自平衡杆的demo:https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html,以下为一些注释:
初看这段话会有些懵,它说的是policy gradient里面的一个trick。
在执行完某个策略产生的一个action序列后(例如使用一个策略打游戏,则该策略会在一局游戏中使用多次产生action,他们组成一个序列),会将每次执行策略后得到的reward相加得到一个总的reward。
为了评估策略好坏,一个简单的做法是使用该总的reward作为该策略的评分。
但是有时虽然结果是坏的,但中间仍然会出现一些较好的action,我们不能因为最终结果不好就否定整个策略序列。一个基本想法是,一个策略产生的action只会影响其后续的env和action,所以为了评判这一步action的好坏,我只需要将从这一步开始到游戏结束期间产生的reward加起来,就能表示这一步action可能贡献的reward
上式中的 t=t0到正无穷即指的是从t0时刻的action到游戏结束产生的reward(即式中的r_t)加起来。
但是一般来说,某时刻产生的action或许对后面几个action产生较大影响,但时间越长,该action的影响也会减弱,故这里有一个γ参数(一般取0.9或0.99),随着时间增长(即式中的 t - t_0 越大),r_t的系数也就越小,这就表示其对t_0时刻的reward影响就越小
可能经常会看到其他地方说Q table的更新函数为:
事实上,这里式1只是将学习率α取为1了而已。
式2表示的是Q的预测值与当前策略下Q的真实值的一个误差。如何理解呢?我们知道DQN本质上只是将Q-learning中的Qtable替换成了Qfunction,在Qtable中,若表中各元素均满足式1中的关系,则其完成收敛。若希望Qfunction也达成同样的收敛条件,则其必须也满足相同的关系(某状态的输出与其他状态输出存在某种关系)。对于使用梯度下降作为优化函数的神经网络来说,我们需要给他一个loss函数,即上述式2
OpenAI的DALL·E2体验
DALL·E是OpenAI公司开发的一个可以根据语言描述创建图片的一个AI系统,前不久升级到了2代,并邀请人们体验。我也凑热闹申请了。
申请通过后它会给你发一个链接,要求填写姓名电话号码等信息,电话号码是用来接收验证短信的,故不能乱填,遗憾的是,其目前并不支持国内的电话号码注册。但可以使用在线接收短信的服务,比如我使用的就是这个:https://www.storytrain.info/verify,它会提供很多海外的电话号码用于帮助你接收短信。
OpenAI提供了很多借助于AI完成的有趣的功能,例如:
语法矫正:
多语言翻译:
对话:
等等功能,我数了一下,一共有49项
我迫不及待地想尝试一下文字描述转图片的功能,貌似这里没找到,去到其官网登录后才出现:https://openai.com/dall-e-2/
真的非常有趣
它甚至支持中文
《这条小鱼在乎》
在暴风雨后的一个早晨,一个男人来到海边散步。他看到沙滩的浅水洼里,有许多被海浪卷上岸来的小鱼。他们被困在浅水洼里,回不了大海了,虽然近在咫尺。被困的小鱼,也许有几百条,甚至几千条。用不了多久,浅水洼里的水就会被沙粒吸干,被太阳蒸干,这些小鱼都会干死的。
男人继续朝前走着。他突然看见前面有一个小男孩,走得很慢,而且不停地在每一个水洼旁弯下腰去——他在捡起水洼里的小鱼,用力把它们仍回大海。
终于,这个男人忍不住走过去:“孩子,这水洼里几百几千条小鱼,你救不过来的。”
“我知道。”小男孩头也不抬地回答。
“哦?那为什么还在扔?谁在乎呢?”
“这条小鱼在乎!”男孩儿一边回答,一边捡起一条鱼扔进大海。“这条在乎,这条也在乎!这一条、这一条、这一条……”
模型训练一段时间后意外终止了
我在同一台电脑上同时使用cpu训练两个神经网络模型(模型并不复杂),在运行大概23个小时之后,两个同时报错了:
# Program 1 error: ... RuntimeError: Caught RuntimeError in DataLoader worker process 0. ... RuntimeError: Couldn\'t open shared file mapping: <000001D70AFB4E12>, error code: <1455> # Program 2 error: ... RuntimeError: [enforce fail at ..\c10\core\CPUAllocator.cpp:75] data. DefaultCPUAllocator: not enough memory: you tried to allocate 1048576 bytes. Buy new RAM!两个模型都使用pytorch搭建,模型1设定dataloader的 num_worker=3,模型2设置为0
从网上搜索出来的结果看这两个问题都源于电脑性能不足
模型1的错误可以通过减少worker数量解决(但我已经设置很少了,我看别人都设置十几甚至几十,但我仅仅设置几个它就会占用大量磁盘,详见:https://blog.woyou.cool/post/3096)
模型2的错误说的很明显,内存不足,但是模型训练过程中,内存的占用不应该是稳定的吗?为啥在二十多个小时之后才出问题,不知道是不是发生了内存泄漏还是怎么着。
这俩问题我觉得都很诡异,不管是cpu性能还是内存不足,他们都不应该在训练这么长时间之后才出问题呀。
我突然想到,在模型训练的这二十多个小时里,我依旧是在一直使用这台电脑,或许恰是那个时间点,其他程序占用了太多资源导致模型训练资源不足。
但我上午的时候还用来编译了一些qt程序,我看模型训练过程也没受影响啊。依然觉得诡异。
另:貌似tensorboard也在同一时间挂掉了
对torch.cuda.stream的理解
cpu个gpu是两个独立的计算单元,也就是说他们可以做设备级别并行计算
而对cpu或gpu来说,他们可能有多个核,即他们本身也可以实现并行计算
一般来说,使用cpu将数据和计算方式传给gpu,由gpu做完计算再传回给cpu(因为gpu的计算能力更强)
不管是cpu还是gpu,其数据来源和计算结果都一定在自己的设备上(cpu是内存,gpu是显存)
所以在pytorch中,若想使用gpu做计算,需使用
tensor.to(gpu_device)方法将被计算数据显式地从内存复制到gpu的显存上,后续对该数据的计算也将在gpu上进行,计算结果也将保留在gpu的显存上(注:to函数也会放到Stream中)这也是为什么当打印或读取上述tensor时需加上
tensor.cpu(),用以将gpu上的数据读回cpu的内存,因为打印操作是cpu的操作gpu可以进行并行操作,即可以同时进行多个计算过程。这里的每个计算过程就是一个Stream
一个Stream可以理解为一个运算队列,例如以下代码(不安全代码):
import torch # 创建两个Stream s1 = torch.cuda.Stream() s2 = torch.cuda.Stream() t = torch.ones(1, device=torch.device('cuda')) with torch.cuda.stream(s1): for i in range(1000): t -= 1 with torch.cuda.stream(s2): for i in range(1000): t += 1 print(t)可以理解为:
s1和s2相当于两个操作队列,他们将并行操作变量t,理论上,这将是不安全的操作。
但,上述代码对cpu来说是串行的(先执行完第一个循环后再执行第二个循环)。由于加和减都是很快的操作,故上述代码实际上很难出现问题(第一个循环中,每次cpu让gpu执行“减”指令时,gpu都能立即完成,所以到第二个循环时,第一个循环中的减操作都已经完成了,即s1队列已经空了)
这是官网给出的另一个不安全的例子:
cuda = torch.device('cuda') s = torch.cuda.Stream() # Create a new stream. A = torch.empty((100, 100), device=cuda).normal_(0.0, 1.0) with torch.cuda.stream(s): # sum() may start execution before normal_() finishes! B = torch.sum(A)注:默认情况下,会有一个“default stream”,上面这段代码中实际有两个stream,除了显示声明的s外,A的normal_计算就发生在default stream中,而B=sum(A)则发生在s这个stream中。
Pytorch dataloader加载数据很慢
现象
写了个模型,训练速度很慢,发现大部分时间都花在了加载数据的过程中,训练时间反而不多
主机内存占用(已提交相当于总申请内存,其中包含交换分区的大小,其后面的数字为总可申请大小,其会根据申请情况动态扩容):
解决
num_workers
DataLoader中设置参数
num_workers=3效果:
主机内存占用:
测试过程中貌似有一次内存申请越来越多,进而导致磁盘被占满(交换分区)
该参数默认情况下为0
该参数用于指定加载数据使用的线程数
当其为0时,其顺序执行以下步骤:
dataloader获取本轮训练需要的数据索引
主线程拿到索引后再调用 torch.utils.data.Dataset 的 getitem 方法逐个获取数据
获取完数据后,开始执行模型训练
一轮训练结束之后,再次返回到步骤1获取数据,如此往复,完成训练
当其>0时,真实的过程我还是不清楚,以下是我做的一个测试结果:
dataloader会在初次迭代时根据 batch_sampler 获取多个batch的索引(具体为 prefetch_factor*num_workers 个),并将他们传给workers。每个worker都将单独加载一个batch(例如batch size为16,则每个worker会加载16条数据)到主机内存。
真正训练时,会去主机内存中找到所需的batch(如果用到GPU,则会再次从主机内存复制到显存)。与此同时,也会再次调用workers去加载一批新的数据
若没找到,则会再次调用workers去加载(这一句来源于网络)
实测结果显示,貌似只有在首次迭代dataloader时会一次加载多批数据,后续每次都是只用一个worker加载一批数据。我想这样应该也是合理的,如果每次都加载多批数据,消耗速度小于加载速度,最终内存会爆掉
经测试:
在我的某个模型中,每增加一个worker(默认prefetch_factor=2)内存消耗增加5.8G(绝大部分为交换分区,所以一旦worker多了之后就会大量占用磁盘空间,得注意)
可能是因为数据集较小(765M的纯文本数据),修改batchsize并不增加内存消耗,修改prefetch_factor对内存影响貌似也不是很大
以下为我某次测试数据(仅供参考,实际得依照具体模型和数据规模来看)
4worker 20次训练耗时16s 平均耗时0.8s
3…………………………………18s………………0.9s
2…………………………………28s………………1.4s
1…………………………………50s………………2.5s
0…………………………………50s………………2.5s参考:
https://pytorch.org/docs/master/data.html
看到一个简洁明了的:https://www.cnblogs.com/h694879357/p/16055835.html
加了该参数程序就不动了?
我在windows10下使用jupyter,加入该参数后程序就卡在那了。
解决方法,导出为python文件,并且:1. 将方法体放到 main 方法中, 2. 使用命令行或其他ide执行
原因是设置 num_workers>0 需要多线程支持,jupyter notebook在这方面有很大的问题,并且还需要在
if __name__ == '__main__'代码块中运行参考:https://github.com/pytorch/pytorch/issues/51344
pin_memory
dataloader参数,默认为false,该值设置为true的结果(貌似影响没那么大)
一种加快机器学习收敛速度的想法
机器学习的本质就是希望找到一个能基本拟合样本的函数
而这个函数的评判标准就是其loss要达到最小,那么问题就转换为了求 f_loss(w, b) 函数的最小值
如果数据量小的话,可以使用最小二乘法直接计算出最小值,但对于大样本数据就不是很好用了
传统的做法是使用梯度下降一点一点试,尝试寻找到函数的极值点,但这样很容易陷入局部极小值
我的想法是,能否使用一个更简单的函数来大致拟合这个loss函数,从而能更快地定位到全局最小值的大致范围,然后再利用梯度下降法去尝试找到该最小值
关于这个“更简单的函数”,我想是否可以通过类似傅里叶级数或一些其他展开式,舍去高阶的表达式后就可以得到一个大致轮廓相近图形的函数百度为什么不收录我的网站
我这个站已经建了好几个月了,文章也不少,且都是原创,为什么他就是不收录呢?
注:就在刚刚,我发现他好像有收录,之前一直都没有
收录了,但又没有收录
总之,相比之下,谷歌几乎在我建站没两天后就可以看到我的全部文章了。
而且我还经常给百度提交url,并且创建了百度站长的账号。
我不知道是不是跟我以前屏蔽过一些IP有关。建站初期,有一些IP一天来很多次,频率很高,我百度了下,有人说这些是盗资源的IP,于是我将他们封了
一段时间后,我又尝试将他们解封了,但是他们也没来过了。我甚至有点怀疑他们是不是百度的爬虫。
我自己也装了 YoastSEO 这个插件,但它总是说我文章需要修改
有些合理的我觉得修改下无所谓,但有些例如外链数啥的,这完全是为了SEO而SEO的,我就是想写写文章,记录下一些日常遇到的问题啥的,就懒得搞了。
事实上我已经放弃做SEO了,我想开了,这就是我的一个私人空间,为什么一定要SEO呢。但就是很好奇百度的收录规则是怎样的,说不定我后面会有需要。
《梦在竹溪》溯源
偶然间看到“梦在竹溪”这首歌的演唱者 张燕 是安徽省淮南市人,我原来一直以为是我们竹溪某地出来的一个歌手,并且一直以为是一个小歌手。我一度怀疑此张燕非彼张燕,但确实是同一个人。
关于这首歌能在网上找到的信息极少。但基于能找到的信息,我猜测,这首歌应该是2005年,北京太阳圣火广告公司给竹溪县政府做的官方宣传MV背景音乐,mv由战菁一主演,歌曲由云剑负责作词、戚建波作曲、再由张燕演唱。
以下为搜索过程:
从张燕的作品列表中找不到这首歌,说明这首歌艺术性质应该不大,更多的是任务属性。属于唱完就完事的那种,对歌手影响力不会有太大影响。
随后我又搜索这首歌名,调整检索时间,发现最早可以追溯到2005年2月的一个帖子
https://tieba.baidu.com/p/10704884?red_tag=1660514313
同年5月,知网上也有一篇相关文章被检索到
随后我去学校图书馆提供的知网数据库检索中找到了这篇文章,其实也不算是一篇文章,看起来也只是一张图片:
对,就只有这么一张图片,看起来像是某本书的某一页。
这里发现一个彩蛋,这首歌上面还有一首,没显示全,但搜索歌词能找到这首歌应该叫《月圆相思后》,但网上显示这首歌发行时间是2019年,且为原唱。上文中的 马牡斌,网上找不到其一点信息。
随后,我又去google做了同样的检索(貌似零几年的时候,google就已经在国内开展业务了,彼时百度还没出现),以下为其他找到的信息:
无聊图220721
素材来源于网络:
Pytorch使用tensorboard
基本使用
首先需要安装tensorboard
# -U 表示如果存在则升级 pip3 install -U tensorboard接着就可以直接在代码中使用
from torch.utils.tensorboard import SummaryWriter ... # 默认会在项目路径下创建 runs 文件夹 dashboard = SummaryWriter() ... dashboard.add_scalar('Loss/train', loss.item(), i) ... dashboard.close()查看图表
tensorboard --logdir=./runs
显示模型学习量变化
for idx, (x, y) in enumerate(test_data_loader): ... # 显示所有学习量变化 for name, parm in model.named_parameters(): dashboard.add_histogram('Weight/'+name, parm, i) # 仅显示指定学习量 dashboard.add_histogram('Weight/myweigth', model.fc.weight, i) ...Histogram
需要知道的是,上图中,虽然只是
gru.bias_hh_l1的取值变化,但这个bias并不只是代表一个值,而是一堆值(想象一个线性方程组中的参数),故它只是反应这一堆值的分布变化,而不是追踪其中一个值的变化事实上,并不能单纯地直接将横轴理解为学习量的取值,它仅表示一个范围。具体地,例如你不能直接从图中看出取值为0的学习量有多少(-0.0269同理),你只能通过计算 (-0.01, +0.01) 这个区间内的积分,大致估算出取值为0的有多少。
DISTRIBUTIONS
Distributions图和Histogram图是同源的,也就是说他俩是同一数据的不同展示形式。他们都展示的是某学习量的分布情况,相较而言,我认为Distributions更直观
初始化权重
def init_weight(m): if isinstance(m, torch.nn.GRU): m.weight_ih_l0.data.fill_(1) m.weight_hh_l0.data.fill_(1) m.bias_ih_l0.data.fill_(0) m.bias_hh_l0.data.fill_(0) ... model.apply(init_weight)在一个图中显示多条曲线
方法一(推荐):除了 add_scalar,tensorboard还提供了 add_scalars(tag, dict_data, step) 的方法
QQ音乐修改了我上传的音源
刚听歌单里的歌,听到
《可能否》——木小雅这首歌的时候,前奏感觉没听过。遂看了看歌词,又把进度条向后拉了拉,发现歌还是那个歌,但是不同版本
后面那朵小云代表这是我上传到微云音乐云盘上的歌,于是我又去音乐云盘的界面,找到这首歌,发现确实已经不是我喜欢的那首了。
ps:这是我非常喜欢的一首歌,我经常听,而且听了好几年了,所以不会错怪QQ音乐。
我是QQ音乐年费会员,之所以上传到音乐云盘,是因为这是之前用网易云时一些比较喜欢的歌,懒得在QQ音乐上一个个找了,就直接上传到云盘了
嗯。。。看来还是得把文件上传到私有云比较好
后记:
我发现这首歌就是上传不成功。
我删除了QQ音乐原来的音源,然后又从网易云上将它下载下来并上传到QQ音乐,它立即又将它替换成另一个版本了。。。
nlp学习
本文基于github教程:https://github.com/bentrevett/pytorch-seq2seq
环境搭建
本实验使用的环境为:pytorch=1.8.2 torchtext=0.9.2 Spacy=3.4.0
# 创建conda环境 conda create --name nlp python=3.8 conda activate nlp # 安装依赖 注意这里我一并安装了torchtext pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 torchtext==0.9.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111 # 使用Spacy对语料分词(一般使用conda做环境管理,pip做包管理。conda本身的包比较少且国内网络不太好) pip3 install -U pip setuptools wheel pip3 install -U 'spacy[cuda117]'# 注:有的时候上述安装过程很慢,只有几kb的速度,多尝试几次关闭窗口再重新开,有时候就能达到几mb的速度了
# 安装pytorch有些包死活安装不上(网络问题),替换源之后就好了(如下)。其中 -i 表示指定源,不写则默认是pypi.org,–extra-index-url 表示备用源
# pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio===0.8.2 torchtext==0.9.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/ –extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111torchtext版本需和pytorch版本对应,若安装不对应的torchtext,则它会强制重新安装对应的pytorch
https://github.com/pytorch/text
下载语料处理相关的库:
教程中使用
python -m spacy download en_core_web_sm的方式下载并安装数据集,但会出现网络的问题导致无法下载。事实上,每个语料库都会被当作一个单独的python包进行安装,所以只需手动下载这些包,然后进行本地安装即可。(其他安装方法参见:https://spacy.io/usage/models)
下载路径:https://github.com/explosion/spacy-models/releases
这里面可以找到各种语言的语料库,我这里选择中文和英文的进行下载
下载完成后进行本地安装
pip3 install C:\Users\HuntZou\Documents\Personal\Datasets\zh_core_web_sm-3.4.0-py3-none-any.whl pip3 install C:\Users\HuntZou\Documents\Personal\Datasets\en_core_web_sm-3.4.0-py3-none-any.whl测试
记录pytorch遇到的一些问题
Embedding层的num_embeddings设置过小
遇到了两个报错都是这个原因导致的:
报错一:
RuntimeError: CUDA error: device-side assert triggered报错二:
RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERRORnn.Embedding层的
num_embeddings参数用于指定需要被embed字典的最大容量(被embed那个数能取得的做大值,和具体能取哪些值无关),若传入的某个字典索引大于该容量,则会出现越界错误。例如我输入的vocab字典真实最大长度为3000,而Embedding层的
num_embeddings仅设置为2000,则可能报错PS:后边训练另一个Seq2Seq模型,也是随机报这两个错误,测试发现也是同样的问题引起的。
CSV/TSV中的双引号
csv vs tsv
csv和tsv的不同在于,csv使用逗号
,作为元素分隔符,tsv使用制表符\t作为分隔符Q&A
Q1:如果csv中某字符串中本身就包含逗号怎么办?
可以使用双引号将该字符串包起来
Q2:如果csv中某字符串中本身就包含双引号怎么办?
得分两种情况:
- 如果字符串没有被双引号包裹,则不需要任何处理
- 如果字符串被双引号包裹,则需要将句中的单个双引号都替换为双个双引号。即
"替换为""Example
例一:字符串中间包含双引号,没有逗号
直接写就可以了
例二:字符串中存在逗号和双引号,双引号不在开头
例如需要在某csv中加入以下信息:
id: 1 content: ooops, a double quotation " there正确写法:
错误写法1:
错误写法2:
例三:句子开头有双引号,句中没有逗号
这种情况其实和例2是一样的,都是被双引号包裹的字符串,故都需要将内容中的单个双引号转换为两个双引号
例如需要在某csv中加入以下信息:
id: 2 content: "look ahead正确写法:
错误写法1:
错误写法2:
CSV标准
其中 6-9 为双引号的使用
- 内容仅含有一般性字符
- 首行可以作为表头,也可以不作表头而直接写数据
- 每行数据都以”换行符“作为标识
- 字段(列)使用逗号进行分隔(tsv使用 \t)
- 每一行的列数相同
- 包含逗号的字段必须使用双引号包起来
- 包含”换行符“的字段必须使用双引号包起来
- 其他的字段(除了6、7)均不需要使用双引号包裹
- 字段中若出现两个连续的双引号,则仅代表两个连续的双引号(字面意思,无需转意)
参考:https://techterms.com/definition/csv
记一次模型训练时显存溢出的问题
出现的问题
写了一个Seq2Seq的中英翻译模型,使用Encoder-Decoder模式。训练时发现总是训练一段时间后就会报显存溢出的错误,训练终止。
根据报错信息可知,pytorch欲分配12.88G的显存,但我的显存只有4G,显然是不够的
寻找原因
从异常栈来看,报错问题出在我创建一个大小为
len(y) * batch_size * 30000的tensor上将 len(y) 和 batch_size 打印出来,发现异常处 len(y)=1579 ,正常情况下应该为35左右
pytorch为每个float类型数据分配
4字节内存,故上述tensor共需 1579 * 73 * 30000 *4 / (1024^3) = 12.88 G 的内存,这与错误信息相符。len(y) 表示的是英语句子的分词长度(即把一个句子拆分成单词数组的长度),故去语料数据集中找到该条数据
找到出问题的语料(一个句子)发现是双引号导致的问题,句子中包含一个双引号,处理是误认为是字符串开始的标识符。关于这一点参见
https://blog.woyou.cool/post/2826
问题解决
通过代码追踪发现,这个tsv文件是我自己生成的,生成过程中忽略了引号的转义,故重新生成并加上转义即可(删掉 quoting=csv.QUOTE_NONE 即可)
其他
如果是训练一段实际后才出现溢出问题,很有可能是代码或数据问题
如果是一开始就有问题,则可能是由于batch size过大导致
pytorch显存使用
- pytorch会根据代码需要向GPU申请显存空间
- 使用完该空间后pytorch并不会立即将其返还给GPU,而是继续保留
- 当代码继续向pytorch申请空间时,pytorch会先分配预留的空间,不够的话再向GPU申请
_故GPU显示的显存占用 = 代码的真实占用( torch.cuda.memory_allocated() ) + pytorch的预留空间( torch.cuda.memory_reserved() )_
这也是为什么训练过程已经结束,但代码并未退出时,查看显存占用依然很大的原因(用jupyter时很明显,不手动重启或终止内核它就会一直占用着)
python del
引用计数法
python使用的是“按引用计数”的方法作为垃圾回收的依据
即:若堆中某内存块不再被其他地方引用,则会对该区域进行垃圾回收
del的作用就是删除引用(拿java做比较就是:仅删除栈中的变量,但其指向的堆中的对象依然存在。通过计算该对象当前被引用次数判断其内存是否要被回收)
注:del只是删除引用,和c++中的free 以及java中的手动置null都不一样
import sys # getrefcount() 方法获取对象引用次数,id() 方法获取对象内存地址 # 为数字1开辟一块内存(地址为140703783919360),并创建一个num引用指向它 num = 1 sys.getrefcount(num) # 121 print(id(num)) # 140703783919360 # 因为python是按引用传递(传地址),故这里创建了一个num_r1引用并指向数字1所在的地址 num_r1 = num sys.getrefcount(num) # 122 print(id(num_r1)) # 140703783919360 # 删除一个引用后,数字1地址的引用减少1 del num_r1 sys.getrefcount(num) # 121 # 对数组来说,数组元素仅仅是元素对象的引用 arr = [1,2,3] sys.getrefcount(arr[0]) # 122 i0 = arr[0] sys.getrefcount(arr[0]) # 123 del arr[0] print(f'arr: {arr}, arr[0]: {arr[0]}') # arr: [2, 3], arr[0]: 2 sys.getrefcount(i0) # 122pytorch
在使用pytorch训练模型时,会发现随着训练时间的增加,使用GPU的显存也逐步增加,这有可能是因为显存没有及时被回收进而导致了内存泄漏,进一步会导致显存溢出进而训练终止。
深度学习GPU环境准备
CUDA和cuDNN
以前的显卡只能用作显示,后来nVidia为它的显卡开发了一套接口,叫CUDA,开发人员就能通过调用该接口实现使用GPU做计算
cuDNN是一个专门为深度学习开发的库。它里面包含了卷积计算、偏导计算等深度神经网络需要的计算库。它是以CUDA为基础的(注:为了更极致的优化,它可能使用更底层的接口)
可以这么理解:显卡就是一个计算器,CUDA就是上面 “+”、“-”、“*”、“/” 四个基本的运算按钮,cuDNN就是在计算器上又新增了 “^n”、“n!”、“ln” 等运算按钮。虽然它们是新增的,但它们本质上都是对加减乘除的组合运算
事实上,所谓的cuDNN的安装,也不过是将一些cuDNN相关的库文件复制到CUDA的安装目录下。很类似于在某个插件库中添加一个插件的过程。
CUDA、CUDA driver和CUDA Toolkit
CUDA一般其实指的是 CUDA runtime API(下文有介绍)
CUDA driver指的就是支持了CUDA指令集的显卡驱动(个人理解)。
类比java:CUDA相当于jre,cudaToolkit相当于jdk。cudaToolkit中包含了CUDA driver,同时也包含了其他一些东西,例如CUDA的编译器nvcc。cudaToolkit的版本和CUDA的版本一一对应(个人理解)
注:安装pytorch时也可能会安装一个cudatoolkit的包,它相当于nVidia提供的cuda toolkit的子集。它里面不包含CUDA driver。这也就意味着使用conda安装的cudatoolkit的版本需大于等于本地的CUDA driver的版本
这里有篇文章说的很详细:显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么?
加上这篇文章:CUDA环境详解
CUDA Liberaries、CUDA Runtime API、CUDA Driver API
三者是层层封装的关系,CUDA Driver API 是对GPU硬件的抽象,原则上可以直接使用该API进行开发,但实际操作较难,Runtime API则是对其的封装,使用该API开发相对简单,而Liberaries则是对Runtime API的进一步封装,使得开发更加容易,三者都有自己的版本。上层API的版本应不小于下层的版本
Driver API 是随着显卡驱动一起安装的,其中就包含了 nvidia-smi 命令,故只要安装了显卡驱动就能使用该命令
参考:https://cloud.tencent.com/developer/article/1496697
为什么没有安装CUDA还是能用pytorch调用GPU
Runtime API 是随着CUDA Toolkit一起安装的,虽然Runtime API基于Driver API,但它也是可以单独安装的。故即使你本地没有安装显卡驱动,也是可以安装CUDA Toolkit的(但有时显卡驱动也会随着该Toolkit一起安装)。该Toolkit中就包含CUDA的编译器nvcc
参考:https://www.zhihu.com/question/378419173/answer/2382489868
CUDA 是一种编程语言吗?
引自官网:https://www.nvidia.cn/geforce/technologies/cuda/faq/
“CUDA 是我们用于 GPU 计算的架构,能在 GPU 上运行标准 C 语言。为实现这一点,NVIDIA 定义了一套通用计算指令集 (PTX) 和一小部分C语言扩展集,从而让开发者充分利用我们 GPU 中强大的并行计算能力。Portland Group 为 NVIDIA CUDA 架构上的 Fortran 提供支持,而其它一些公司则为 Java、Python、.NET 等其它语言提供支持。
学校里的流浪猫
学校有很多流浪猫,很多学校都有。刚才去吃饭的路上就遇到一只。
让我惊讶与心疼的是,它非常的瘦,张着个嘴巴看着我,一脸警觉与惶恐。
我很抱歉没有随身带一根火腿肠或者其他什么能吃的,它太瘦了。
暑假后绝大部分学生都回家了,这些个猫也没人喂了。
我也不知道是不是这个原因导致这只猫这么瘦弱,事实上它看起来还是挺好看的那种。我记得之前也看到过学校的流浪猫,倒也都算正常。但这只却是有点让人不忍直视。
后面还有一两个月,这些动物若没人喂它们怎么撑过去。
无聊图220711
素材来源于网络
OpenCV 中的 Graph API 介绍
快速认知
例如 OpenCV 中的 cv::Canny(…),可以改用 G-API 写成 cv::gapi::Canny(…)
图
为了让图像处理过程更快,并且让代码有更好的可移植性,OpenCV引入了Graph API这个单独的模块。顾名思义,这是一种基于图的计算方式。这里图的概念类似于pytorch中图的概念。
例如,若一张图片的处理过程(pipeline)为:
resize -> 灰度化 -> 模糊处理 -> 边缘检测 -> 结果
没有图之前的做法是一步一步对某张图片进行处理,有了图之后就相当于将这些步骤单独封装成一个方法,需要处理的时候调用该方法即可得到最终结果。那么这和我直接将这些步骤封装成一个方法有什么区别呢?
直接封装成一个方法其本质还是对图像按整个过程一步一步处理
而将其封装成图之后,编译器会对整个pipeline做一系列优化,例如去除某些不必要的步骤或增加一些操作等等。
如何创建图?
# 注意这里引入的是gapi模块 #include <opencv2/highgui.hpp> #include <opencv2/gapi.hpp> #include <opencv2/gapi/core.hpp> #include <opencv2/gapi/imgproc.hpp> // 构建图,注意数据结构为 GMat cv::GMat in; cv::GMat vga = cv::gapi::resize(in, cv::Size(), 0.5, 0.5); cv::GMat gray = cv::gapi::BGR2Gray(vga); cv::GMat blurred = cv::gapi::blur(gray, cv::Size(5,5)); cv::GMat out = cv::gapi::Canny(blurred, 32, 128, 3); cv::GComputation ac(in, out); // 使用图,注意数据结构为 Mat cv::Mat output, input = cv::imread("pic-loction"); ac.apply(input, output); // 编译图并运行 cv::imshow("output", output);G-API架构
基础架构图:
无聊图220706
素材来源于网络
Windows下编译并测试OpenCV
注1:以下若不做说明默认将opencv下载编译到我本机 C:\Users\HuntZou\Downloads\ 目录下,您需根据您自己的情况做一些替换。
注2:以下若不做说明则都是我自己试过的方法
编译
1. 下载cmake
2. 下载opencv源码
3. 解压缩opencv源码并进入到解压后的目录
4. 在解压后的目录创建一个build目录,用于存放cmake的输出文件
注:这是为了后面在命令行中使用cmake,你也可以直接使用cmake的gui
5. 在build目录中打开cmd,并使用下载好的cmake创建makefile
这一步需要下载一些东西,由于东西在外网,导致在这里卡半天,最终会报错
解决办法:
5.1 简单方法(使用代理):如果电脑上装了clash代理软件的话,直接开启clash的tun模式即可,我自己实验一次就成功了。
貌似windows命令行默认不走代理,clash开启该选项后会虚拟出一块网卡,所有流量都会经过该网卡,这样即使不走代理的软件也会被迫走代理。
貌似也可以直接设置命令行走代理,不过我没试 https://blog.csdn.net/u014723479/article/details/103698296
5.2 复杂方法(cmake期间不用下载):
5.2.1. 自己在下载好该文件
停止cmake,然后找到build目录下的
CMakeDownloadLog.txt文件,在里面搜索关键字 ”https“ 可以找到文件的下载链接。
注:图示内容为可以正常下载情况下的截图,您该文件内容应该没这么完整,但也能找到一些url链接。
需要下载的文件一共有四个,共分为两类:
ffmpeg:opencv_videoio_ffmpeg.dll、opencv_videoio_ffmpeg_64.dll、ffmpeg_version.cmake
ippicv:ippicv_2020_win_intel64_20191018_general.zip
ippicv的链接直接下载即可
ffmpeg需要下载三个文件,但它们的url前缀都是一样的,将上述三个文件名替换一下下载即可
5.2.2. 将下载好的 ffmpeg 三个文件 放到 /3rdparty/ffmpeg/ 目录下
ippicv_2020_win_intel64_20191018_general.zip 放到 /3rdparty/ippicv/ 目录下
5.2.3. 打开opencv源码目录下的文件 /3rdparty/ippicv/ippicv.cmake 和 /3rdparty/ffmpeg/ffmpeg.cmake
注释掉以下部分:
重新开始cmake
6. cmake结束后会在build目录下生成一个opencv的vs工程,用vs打开即可,然后再用vs编译。
无聊图220701
素材来源于网络
输入输出对模型回传梯度的影响
TL;DR: 输入会影响梯度,输出基本上也都会有影响
输入
如果是线性网络的话,输入其实就是梯度,例如对于函数 y = kx+b 来说,forward时,输入x求y,backward时,求k的梯度,其实就是x。
而目前大部分的网络其最内部的函数就是线性函数(网络模型可以看作多层的嵌套函数)
输出
如果单从一个线性函数 y=kx+b 来说,求k的梯度确实没用到y,但是:
1. 目前的网络基本都是多层的,即上一个网络的输出就是下一个网络的输入。又由于链式求导法则,即从下一个网络开始,前面的网络梯度都会受到影响。
2. 对于一些激活函数来说,其梯度的计算本身就带有其输出值,例如对于sigmoid函数来说,它的公式为:
其导数为:
可以看到,它的导数中就包含它的函数值,所以如果使用了这类激活函数,输出也是会影响backward的梯度的。
梯度消失
由于链式求导法则的原因,一旦一个网络的梯度等于或接近0,因为其前面的网络计算梯度时都需要乘以这个梯度,故大概率也会接近0,这会引起梯度消失。
例如在一个嵌套网络中:A->B->C->D,表示前一个网络的输出是下一个网络的输入,假设这里网络C的输出为0,D网络只是一个线性输出层,则D网络的梯度很有可能为0,根据链式求导法则,A、B、C的网络梯度也是0,模型就更新不了了。
另外,如果C网络使用leru这种激活函数,如果它的输入小于0,那么它的梯度就等于0,其前面的网络梯度也就为0了,这之前的网络也就无法更新了。对于其他激活函数同理。
是不是要避免输出0?
那倒也不是,模型输出0可能表示这个特征对模型不重要或者不敏感,特征提取的本质也可以说是一个筛子,专门筛选有用的特征(例如自编码模型,仅通过提取的少量特征就能还原输入),或者说是一个特征压缩的过程
事实上,对于深度神经网络来说,其越到后面特征就越稀疏,这也体现了特征压缩的过程。
C++、Qt编译相关概念
问题描述
使用vs2022创建了一个静态库,欲在qt程序中使用,结果报
undefined reference to xxx错误,这里的xxx就是静态库中定义的方法。可以保证:
已经正确配置依赖并添加头文件
在vs中创建一个示例程序并引入该lib发现可以正常使用
由于对c++生态不太熟,做此记录
问题原因
vs使用的是msvc编译器,而qtcreator中使用的却是mingw编译器。两者并不兼容。
解决方案
qtcreator切换到msvc编译器,并且需要在电脑上正确安装与该msvc编译器对应的visual studio IDE。
概念区分
VC 和 VS
VC相关的概念在下面有详细说明,需要注意的是:除了下面说的它是一个C++编译器之外,在不同的语境下它也有可能是其他东西,例如一个名为VC++的IDE或者C语言等
可以简单理解为:vs(即Visual Studio IDE)是一个ide,对应java中的eclipse等。vc(即MSVC)是vindows下c++的编译环境,对应java中jdk的javac。
用vs开发时可以选择不同的vc版本
参考:https://zhuanlan.zhihu.com/p/497033106
MSVC、MSVC++、VC、VC++、Visual C++、Microsoft Visual C++
它们都是同一个东西
GNU、MinGW、GCC、gcc、g++(都带一个g)
GNU简单理解为一个开源软件集合,其中有很多开源软件,例如 GNU/Linux,GNU/GCC 等实际上GNU是一个单独的操作系统,拥有自己的内核
Hurd和一些列周边软件,但在生产环境中常常将其替换成更成熟的 linux内核。如此,这种替换了linux内核但同时拥有GNU周边软件的GNU系统就被称为GNU/Linux,它和linux其实是两个不同的系统,只不过很多时候直接将其简称为linux。
上面说的那个开源软件集合,其实指的就是GNU系统下的一些周边软件。
GCC全称 GNU Compiler Collection,顾名思义,它是GNU系统下编译器的集合,它下面有各种语言的编译器,例如java编译器、c/c++编译器(gcc和g++)、OC编译器等
gcc/g++全称 GNU C Compiler,就是上述GCC集合中的c/c++编译器。事实上,它们也并非真正的编译器,它们只是一个驱动,用于判断被编译文件类型或系统环境等,然后调用真正的c/c++编译器cc1或cc1plus。它们的区别是:g++不管遇到c或c++文件都当作c++文件,从而调用cc1plus编译器进行编译。而gcc则进行区分。再者g++在编译完成后会自动链接c++的标准库,gcc不会。有些文章说g++会调用gcc或反过来都是错误的。
而
MinGW全称 Minimalist GNU for Windows,它就是将GNU系统下的一些工具软件打包给windows用。其中就包含gcc。
详见:https://blog.csdn.net/lee_ham/article/details/81778581
MSVC 和 MinGW
可以简单认为两者都是c++的编译器(但上面说过MinGW是一个工具集,实际上编译器是gcc),区别在于:
MSVC是windows下独有的,全称:Microsoft Visual C++。它和VS是一一绑定的。可以简单认为,想用哪个版本的MSVC就需要下载安装对应版本的VS。
对C++引用库的理解
情景
创建两个静态库 libA 和 libB,libB依赖libA。创建一个程序App引用 libB
关系为:App -> libB -> libA
一般做法是:
创建完libA后编译生成静态库,创建libB时引用该静态库并将libA的头文件复制到libB项目中进行引用。
App对libB的引用也是导入它的静态库和头文件。
可不可以不用头文件?
可以,头文件只其申明作用,你完全可以自己写该声明。事实上,#include 只是在编译时起作用,它仅仅将include的文件全量复制到源文件中。故和你自己写是一样的。
头文件和源文件名称能否不同
可以,还是上面说的,include仅仅将内容原封不动复制进源文件,所以和头文件命名没有什么关系。
如何在App中使用libA中定义的类和方法
如果是java程序,那么你完全可以直接在App项目中声明和使用libA中的类和方法,我认为这也是符合直觉的。
但在c++中,貌似有一条不成文的规定就是任何东西都需要先声明再使用,所以,若想在App中调用libA中的方法,要么你include libA的头文件,要么你手动声明需要调用的方法,然后就可以直接调用,至于调用的方法体,c++程序会在链接步骤自动找到。
举例:
App.cpp(一个Qt的示例程序)
pch.h
libA.h
extern 关键字
我在libB中定义了一个变量,我想在App中使用它,如果你这个变量定义在libB的头文件中这样做是没问题的,但如果你将其定义在了cpp文件中,那你在App中仅引入libB的头文件还是访问不到该变量。
此时,你就可以在头文件中使用extern关键字再次声明定义在cpp中的变量,然后在App中就可以使用了。
例如:
# libB.h ... class MyClass{...} extern int num; extern MyClass mc; ...# libB.cpp ... int num = 1; MyClass mc = MyClass(); ...# App.cpp #include "libB.h" ... int main() { std::cout << num << ", " << mc.somproperties; } ...但是我测试了下,貌似不能作用与class
无聊图220627
素材来源于网络
Visual Studio 2022程序打包方法
从打包方式来看,分为
debug和release包(项目构建方式)从依赖方式来看,分为
静态链接和动态链接(处理项目依赖的方式)从程序用途来看,分为
exe、lib、dll(最终生成产物)它们之间互相交叉组合打包
Step 1:配置库依赖(若项目中有依赖第三方的库,NuGet的不需要)
Step 2:配置管理器中选择编译类型(默认是debug,打出来的就只有debug的包,性能较差)
Step 3:选择打包类型,默认是exe
Step 4:选择是编译成静态链接还是动态链接
Step 5:重新构建项目
Step 6:找到构建结果
静态编译:
动态编译:
注1:选择生成库文件(.lib或.dll文件)的话,还需要将代码中写的头文件给复制出来
注2:上述生成库文件我并没有尝试,后续做到这再验证,正确做法参见官网:https://docs.microsoft.com/zh-cn/cpp/build/walkthrough-creating-and-using-a-dynamic-link-library-cpp?view=msvc-170
我对程序员行业持悲观态度
我记得电影《大空头》中,主角一行人之所以能预测房市泡沫即将破裂,是因为他们发现当时的房贷很容易得到。由于当时房地产市场被炒得火热,他们调查发现,就算一个妓女手上也有很多房产。银行被房市冲昏了头,使得房贷极易获得。他们想去走访某个申请了房贷的用户,结果发现该用户只是某个人家中一条狗的名字——银行贷款条件宽松到根本不会做任何调查了。
我觉得目前程序员行业也有点类似了,因为门槛低且行业处于极度膨胀期,导致各行各业的人疯狂涌入。仿佛任何专业、任何学历,只要开始学习编程,就能飞黄腾达。
因此,我对该行业未来持悲观态度。我听说身边不少人转行做了开发,大多薪资也不错。但市场的需求真有这么大吗?
就我目前所看到的,目前市面上软件大多处于过剩状态。多少项目是为了互联网+而互联网+的(尤其是政府项目)。更多的项目都是开发人员风风火火不分昼夜地干,结果用户寥寥无几。我也见过不以用户为目的的,大多只是随便开发一个没什么用的东西圈钱(区块链项目几乎百分之百属于该类)。这些东西都是为了开发而开发。
现在随便打开一个软件,里面花花绿绿的功能,到底有几个是我们用得到的呢。
我遇到过不少人因为这个行业工资高而转行来的,我也遇到不少被劝退的,干两天觉得不爽就转行。我不喜欢这种行为,过于急功近利。我个人是喜欢计算机,打心底喜欢。不然我也不会放弃一个较好的薪资回来读研了。那些为了钱进场的人,他们只会把开发当作一个工作,他们只是为了完成任务而学习,这是一种亵渎。他们只是单纯的逐利。而且,他们的素质也是令人堪忧,高级计算机语言使得开发就像说话一样简单,但绝大多数人要么是结巴,要么五音不全,要么废话连篇,要么连基本表达都有问题。
以前看到过一个理论,说某个集合里的人越多,其平均素质就会下降。就像知乎、就像B站、就像短视频行业、就像程序员行业。
之前还看到一个言论说,现在的软件开发行业和以前的矿工一样,都是当时的高薪职业,都是苦力活(绝大多数开发岗,尤其是上述的那部分人,确实只是苦力活)。时机一到,万念俱灰。
最近一直在思考读完研之后的去路,我不想再继续从事开发岗,确实不想做些无谓的产出。我个人对金融也有很大兴趣,我想走个人量化交易这一块,但风险很大,国内经济环境确实越来越不景气了,未知因素太多,太迷茫了。
《在桥边》——伯尔
他们替我缝补了腿,给我一个可以坐着的差使:要我数在一座新桥上走过的人。他们以用数字来表明他们的精明能干为乐事,一些毫无意义的空洞的数目字使他们陶醉。整天,整天,我的不出声音的嘴象一台计时器那样动着,一个数字接着一个数字积起来,为了在晚上好送给他们一个数字的捷报,当我把我上班的结果报告他们时,他们的脸上放出光彩,数字愈大,他们愈加容光焕发。他们有理由心满意足地上床睡觉去了,因为每天有成千上万的人走过他们的新桥……
但是他们的统计是不准确的。我很抱歉,但它是不准确的,我是一个不可靠的人,虽然我懂得,怎样唤起人们对我有诚实的印象。
我以此暗自高兴,有时故意少数一个人;当我发起怜悯来时,就送给他们几个。他们的幸福掌握在我的手中。当我恼火时,当我没有烟抽时,我只给一个平均数;当我心情舒畅、精神愉快时,我就用五位数字来表示我的慷慨。他们多么高兴啊!每次他们郑重其事地在我手中把结果拿过去,眼睛闪闪发光,还拍拍我的肩膀。他们什么也没有料想到!然后,他们就开始乘呀,除呀,算百分比呀,以及其他我所不知道的事情。他们算出,今天每分钟有多少人过桥,十年后将有多少人过桥。他们喜欢这个未来完成式,未来完成式是他们的专长——可是,抱歉得很,这一切都是不准确的……
当我的心爱的姑娘过桥时——她一天走过两次——我的心简直就停止了跳动。我那不知疲倦的心跳简直就停止了突突的声音,直到她转入林荫道消失为止。所有在这个时间内走过的人,我一个也没有数。这两分钟是属于我的,完全属于我一个人的,我不让他们侵占去。当她晚上又从冷饮店里走回来时——这期间我打听到,她在一家冷饮店里工作——,当她在人行道的那一边,在我的不出声音、但又必须数的嘴前走过时,我的心又停止了跳动,当不再看见她时,我才又开始数起来。所有一切有幸在这几分钟内在我朦胧的眼睛前面一列列走过的人,都不会进入统计中去而永垂不朽了,他们全是些男男女女的幽灵,不存在的东西都不会在统计的未来完成式中一起过桥了。
这很清楚,我爱她。但是她什么也不知道,我也不愿意让她知道。她不该知道,她用何等可怕的方式把一切计算都推翻了,她应该无忧无虑地、天真无邪地带着她的长长的棕色头发和温柔的脚步走进冷饮店,她应该得到许多小费。我在爱她。这是很清楚的,我在爱她。
最近他们对我进行了检查。坐在人行道那一边数汽车的矿工及时地警告了我,我也就分外小心。我象发疯似地数着,一台自动记录公里行程的机器也不可能比我数得更好。那位主任统计员亲自站在人行道的那一边数,然后拿一小时的结果同我的统计数字相比较。我比他只少算了一个人。我心爱的姑娘走过来了,我一辈子也不会把这样漂亮的女孩子转换到未来完成式中去;我这个心爱的小姑娘不应该被乘、被除、变成空洞的百分比。我的心都碎了,因为我必须数,不能再目送她过去,我非常感激在对面数汽车的矿工。这直接关系到我的饭碗问题。
主任统计员拍着我的肩膀,说我是个好人,很忠实、很可靠。“一小时内只数错了一个人”,他说,“这没有多大关系。我们反正要追加一定的百分比的零头,我将提议,调您去数马车。”
数马车当然是美差。数马车是我从来没有碰到过的运气。马车一天最多只有二十五辆,每半小时在脑中记一次数字。这简直是交了鸿运!
数马车该多美!四点到八点时根本不准马车过桥,我可以去散散步或者到冷饮店去走走,可以长久地看她一番,说不定她回家的时候还可以送她一段路呢,我那心爱的,没有计算进去的小姑娘…….h/.cpp/.hpp/.c/.o/.obj/.lib/.dll/.a/.so/.exe傻傻分不清
这些都是c/c++编译运行时期所产生的文件,作为一个没用过这门语言的人很容易搞混。
简单分类
简单分三类,也就是三个过程需要的文件
.h/.cpp/.hpp/.c:代码源文件
.o/.obj/.lib/.a:编译过程需要的文件
.dll/.so/.exe:运行过程需要的文件源代码
cpp 与 c
.cpp和.c分别为c++和c的源代码文件。早期都只用.c文件,后来为了便于区分就为c++产生了.cpp文件。但这也只是约定俗成的,还有可能将c++源文件命名为其他后缀,例如.cxx等h(头文件)
假如
A.cpp需要引入B.cpp中的方法,则需要在A.cpp的头部引入#include "B.cpp"。其实这样就可以了。但更为常见的做法是将B.cpp中的所有方法声明都提取出来单独写到一个B.h文件中,需要用B.cpp中的方法时,只需要引入B.h即可。这很类似java中的接口模式,但不管是实践还是思想都是完全不同的为什么要这样做?
- 有的时候依赖包的源码并不是公开的,依赖提供者只会提供已经编译好的
.lib文件与其对应的.h文件,此时若需要调用lib中的方法就需要先引入该头文件。- 事实上
include关键字仅仅作用与编译期,即将include的文件原封不动地复制到本文件。所以假如被引用的头文件中声明了一些常量,你又在本地声明了一样的常量,这个问题就能在编译器就被发现。hpp
个人理解和
.cpp文件功能上一样,都是讲方法声明和实现写在一个文件中,但又在性能上有优化。注:hpp=header plus plus,意思是将实现写进头文件中,概念上还是属于头文件,但看起来像cpp文件。
每个
.cpp文件都会被单独编译成一个.o文件,然后再通过链接步骤将它们链接在一起。但hpp文件不会单独编译上面说 include 其实就是将代码原封不动复制过来,include的hpp文件会和源文件一起只生成一个
.o文件,减少了编译次数编译
.o 与 .obj
它们都是源文件编译后的产物,类似于java文件编译后产生的class文件
不同点在于
.obj是在windows下的编译产物,.o是linux下的。.lib 与 .a
每个cpp文件都会被单独编译成
.o文件。假如它们之间有依赖关系(例如A.cpp引用了B.cpp中的方法),那么它们怎么找到相应的方法实现呢(因为此时A.cpp只引用了B.h,该文件中只有方法声明,没有实现)?所以在编译结束后还需要一个链接操作,即将调用方法的符号引用替换成真实的方法地址。然后将它们一起打包成一个
.lib(windows下).a(linux下)文件,最终生成一个.exe文件。注:此时又有静态链接和动态链接的概念,见下文中“运行”部分
运行
静态链接
将整个项目所有的源码及依赖全都打包在一起,此时整个项目没有任何外部依赖,直接打开就能运行,这种打包方式称为静态链接
例如上述“编译”过程最后,将所有的文件都打包进一个
.lib文件中,运行过程中若需要找方法体,直接在该lib文件中就能找到。静态链接的好处是兼容性强,不受外部环境的干扰。因为所有的依赖它都已经自带了,可以自力更生了。
缺点是包比较大,同样是因为它携带的东西太对了。
动态链接
有的依赖确实不需要随身携带,例如
cout这种方法的依赖,一般系统下都有其实现并且不会轻易去更改。此时就可以使用动态链接。动态链接不打包方法体,只打包方法声明和调用地址。例如上述“编译”过程的最后,打包成的
.lib文件中仅仅包含被调用方法的声明,此时如果使用这些方法,程序就会在运行过程中动态地去系统中寻找依赖库文件,即.dll(windows下)或.so(linux下)文件。这也是为什么一些软件运行过程中会突然报却是某种dll的错误
动态链接的优点是打包的体积小,但缺点也很明显,对环境依赖高。一旦环境中没有所依赖的动态库软件就无法运行。
.dll 与 .exe
dll只是一个依赖包,就好比是一个工具箱。
exe就是在上述dll中加入了一个main方法,使得其可以直接执行。
总结
lib和dll总结
如果是静态链接,lib类似于自家的厨房,自己想吃什么就做什么,所有的材料也都是充沛的。此时lib就是所有方法的声明加实现。
如果是动态链接,lib就类似于餐厅的公共菜单,想吃什么直接点就行,不用去管怎么做。但不同的餐厅可能做法不同。且可能你点的菜某家餐厅没有,那就会报材料缺失的错误。此时lib相当于只是方法的一个索引了。
docker中的用户解惑
发生了什么?
普通用户(在docker用户组中)通过docker创建了一个文件,结果显示该文件的所有者却是root,且该普通用户已无权删除该文件:
接着,我又使用root用户在宿主机直接创建一个文件:
然后切换回普通用户,再使用docker去删除该文件:
再回头看该文件:
发现该文件已经被删除了。
是不是有种细思极恐的感觉:普通用户只要通过docker就能以root权限执行命令。
为什么会这样?
两个原因直接导致了这种情况的发生:
- 对linux内核来说,它没有用户的概念,它只认uid和gid
例如root用户的uid=0,普通用户的uid可能为其他一些数字。这意味着同一个uid可以对应多个用户名- docker容器默认就是使用root账户运行的
可以通过
cat /etc/passwd命令查看所有的用户:
例如这里显示 root 用户的uid为0,gid为0,hunt 用户的uid和gid均为1000。
那该怎么办?
最简单的想法自然是让docker不以root用户运行了。docker本身就支持
-u指令用来指定执行的用户。
可以看到使用 -u 命令指定了非root权限的uid后新创建的文件就不再是root用户的了。
所以,生产环境需要指定非root用户启动容器才比较安全。
关于指定的uid
但同时也能看到对于新启动的容器,它并不知道uid=1000到底是哪个用户。那为什么那个文件还是显示为hunt创建的呢?这是因为宿主机中恰好有个uid=1000的用户名为hunt,所以若我用另一个两边都没有的uid创建文件:
可以看到容器显示找不到该用户,宿主机也是直接使用uid来标识文件所有者。
已经使用root用户启动的容器怎么办?
已经启动的容器要想修改一些启动参数相对较为复杂,不过也不用过于担心,docker本身也考虑到这一点,所以它使用了
Linux Capabilities机制。使用docker执行命令的root用户和本机的root用户是同一个吗?
并不是,前面有提到,对内核来说它只认uid和gid,docker使用它的root用户(uid=0)创建了文件,在宿主机中因为uid=0的也是root用户,故在宿主机看来就像是同一个root用户创建的文件一样。
Linux Capabilities
linux中的进程分为特权进程(priviledged processes)和非特权进程(priviledged processes)。使用root权限启动的进程即为特权进程,这种进程拥有较多的权限。这里的root用户指的是uid=0的用户,其用户名不一定叫root。
事实上,linux对root用户的权限有进一步的细分,类似rbac权限管理模型。root用户的权限又细分为38个小权限,例如:CAP_CHOWN(修改文件所有者的权限)、CAP_SETGID(允许改变进程的 GID)、CAP_SYS_BOOT(允许重新启动系统)等。
上面说了,事实上docker容器的root用户和宿主机的root是不同的,不同点就在于它们拥有的这些小权限不同,docker容器的root只有其中的14项小权限。这也最大限度保证了宿主机系统的安全。
我就是想给容器超级权限,就是玩,该怎么办?
docker run --privileged=true ...总结
启动容器时记得指定用户
参考
https://www.cnblogs.com/woshimrf/p/understand-docker-uid.html
https://www.cnblogs.com/shoufu/p/14454793.html
无聊图220615
素材来源于网络
Windows下的Local、LocalLow、Roaming区别及Integrity level
windows下用户目录中有个
AppData目录,该目录下有三个子目录Local、LocalLow、Roaming
在C盘下还有一个
ProgramData的目录,另外还有Program Files、Program Files (x86)这三个目录
注:上述
AppData、ProgramData目录默认是隐藏的,可按以下设置查看
有时候安装程序会让你选一些目录,就会造成困惑,以下是我的一些了解:
为什么有这些目录
一般软件使用过程都分为三个阶段:安装——使用——卸载。这里讨论前两个阶段。
软件安装
Program Files和Program Files (x86)是安装目录。一般来说,所谓软件安装的过程其实就是压缩包解压的过程,程序员将某个软件打包成一个安装包文件,用户双击该文件就相当于解压这个文件(粗略认为)。解压的目录就是安装路径,解压完成即软件安装完成。
Program Files 和 Program Files (x86) 的区别
windows分为64位和32位的。
现在的家用机基本都是64位的,很少有32位的。但在64位出现之前,早期也都是32位的。所以很多软件都分32位版和64位版。一般来说64位的计算机会向下兼容32位的软件,所以64位机是可以安装32位的软件的。但为了做出一些区分,32位的软件就和64位的软件分两个目录安装了。64位的应安装在
Program Files下,32位的则应安装在 `Program Files (x86) 下。软件使用
上述步骤只是完成了软件的安装,软件运行又是另一回事。例如我在电脑上安装好了QQ,下一步就是双击打开并使用它。使用的过程必然伴随着一系列文件的产生,例如聊天记录、缓存文件、用户自定义配置等。从规范上来讲,这些运行过程中生成的文件或配置文件应该都存放在
ProgramData、AppData目录下。ProgramData 和 AppData 的区别
他们俩都是用来存放运行过程中产生的文件和配置,区别在于用户权限的不同。
ProgramData目录中存放的数据对所有用户共享(一台windows可以创建多个用户使用)。
AppData目录中存放的数据只对单个用户访问。例如对QQ而言,我对其外观进行了设置,因为这并不是什么隐私信息,所以可以将其配置存放在
ProgramData目录中,这样其他用户登录windows后也能看到修改外观的QQ。而对用户的聊天记录则存放在AppData目录,毕竟我也不想因为别人使用这台电脑就能看到我的聊天记录。(仅做理解,真实情况不一定是这样)Local、LocalLow、Roaming 的区别
这三个目录都在
AppData目录下,基本作用是一样的,就是上面说的为单个用户保存数据。但有一些小的区别:先说Local和Roaming两个的区别:
如果你的电脑只是你个人使用,那他俩没区别。如果你的电脑是有一个中心化的管理,例如学校的机房、公司的电脑等这种同一台电脑可能有多个用户登录的情况,才有一些区别。
visual studio如何使用第三方库
过程实际上很简单,就是两步
引入 .h 头文件告诉我第三方库提供了哪些方法(就好比是菜单)
引入 .lib 库文件告诉程序头文件的具体实现(就好比是具体的做菜过程)
至于 .dll 文件,你可以理解为它是对 lib 文件的补充,有的时候会没有
一般第三方库会提供三个文件 .h/.lib/.dll,有的时候也是两个 .h 和 .lib
在项目中,一般
.h文件会放到include文件夹中,.lib文件会放到lib文件夹中,.dll或可执行文件会放到bin文件夹中下文将介绍它们有什么用以及如何使用它们
1. 使用visual studio创建一个新的空项目
2. 创建一个 .cpp 文件(必须先于3执行)
在 Source Files 目录右键,选择添加新项目,并在弹出的对话框中选择 c++ 项目,然后输入一个文件名称
双击打开文件进行编辑,输入下面的代码并点击工具栏中的运行按钮看看能不能正常运行
#include <iostream>int main() { printf("bingo"); return 0;}3. 加载 .h 头文件
头文件就是 lib 文件中可用内容的声明,c++中,函数字段等都要先声明再使用,include头文件就是声明过程,你可以理解为它会把头文件的内容复制到你代码文件的顶部
项目上右键,选择属性
在弹出的页面中,下图所示位置添加 .h 文件所在目录
添加后,写c++代码时也会有相应的提示
4. 添加 .lib 依赖
traefik教程
使用traefik创建反向代理过程见:https://blog.woyou.cool/post/1908
本文来自官网文档的部分翻译并加以解释:https://doc.traefik.io/traefik/
由于本人不善描述,故请结合下述举例进行了解
简述
traefik是一个边际路由,它在服务中扮演着网关的角色。它拦截所有请求并进行一系列处理后再传递到具体的处理服务器。
其特点是可以进行自动的服务发现。例如,我希望在项目中添加一个新的服务,如果使用nginx的话就需要手动修改nginx配置文件,并创建路由规则。而traefik则会自动监听服务状态,新加的服务也会根据规则自动创建路由。这就使得它在初始配置时略微麻烦,但是后续使用的过程比较简单。
重要概念
traefik有几个较为重要的概念:
provider:之所以能自动进行服务发现,是因为要有人告诉它。告诉它的这个人就是provider,这个provider可以是docker socket、zookeeper、k8s、redis甚至file。traefik时刻监听它们里面的内容,并对其变化做出反应。
Router:路由规则,例如我希望对 “n1.domain.com” 的请求全部路由到n1服务器,而“n2.domain.com”的请求全部路由到n2服务器,这就是两条根据域名区分的路由规则
具体可以设定的参数参见:https://doc.traefik.io/traefik/routing/providers/docker/Service:处理具体请求的服务,例如上述的n1、n2服务器,但一个服务器上也可能有多个service,此时需要通过端口进行区分
Middleware:每个请求被traefik拦截后,都会经过一系列middleware才能到达service,用户可以指定需要哪些middleware,例如对url进行修改、对header进行修改等
具体有哪些middleware见:https://doc.traefik.io/traefik/middlewares/http/overview/ 和配置文件
traefik有两种非常重要的配置文件:静态配置和动态配置
静态配置就是一个 traefik.yml 的配置文件,这里面配置的是traefik的一些启动参数,例如其监听的端口、是否开始dashboard等
动态配置就是用来配置各种路由规则的。traefik一旦启动后就不需要再进行配置了,所有新加入的服务都应该在该服务启动时就指定路由规则,然后等待traefik自动发现。
例如:我启动了一个traefik,此时需要新加入一个web服务S,则我应该在启动S时给定一个启动参数“rule=my-router-rule”用于路由的配置(真实的配置不是这样,但也是kv的形式),这个参数就是一个动态配置。由于不同的provider中服务的启动方式不同,故动态配置都是不尽相同的。例如若使用docker作为provider,则启动新的docker容器时,就需要加上
--label rule=my-router-rule的参数。因为docker做provider时是使用容器的label作为动态配置的。(三个月后的后记:不得不说,这种配置方式,当时一时爽,后来火葬场。当我再次进入这个服务器看的时候,我发现我完全忘记了当时是怎么配置的,我完全不知道访问规则是什么,就算我找到了域名解析规则,但我依旧无法想起它到底是怎么访问的,为什么可以这样,我已经怀疑人生到不会组织语言了)
举例
开启一个traefik并使用docker作为provider
#traefik静态配置文件 traefik.yml # 使用docker作为provider providers: docker: {} # 使用安全模式并开启dashboard api: dashboard: true insecure: false启动traefik
docker run -d -p 8080:8080 -p 80:80 -p 443:443 --name traefik -v /var/run/docker.sock:/var/run/docker.sock -v /home/hunt/Templates/traefik.yml:/etc/traefik/traefik.yml --network net1 -l "traefik.http.routers.dashboard.rule=Host(\`traefik.huntzou.com\`) && (PathPrefix(\`/api\`) || PathPrefix(\`/dashboard\`))" -l "traefik.http.routers.dashboard.service=api@internal" traefik为了便于使用域名访问,我手动在host文件中添加了一些dns解析,其中192.168.190.128就是我的服务器ip
基于nextcloud搭建个人网盘
docker
使用docker搭建较为方便
docker run -d -p 80:80 --name nc nextcloud然后就可以在浏览器访问了
如果希望将文件目录挂载到宿主机,可以加上
-v your-local-dir:/var/www/html/data但是data目录并非只是文件存储的目录,其内容如下:
也就是说它其实会根据账户创建对应的文件目录,真正的文件是在该用户目录下的files目录下。但由于不确定后续会创建多少用户,故此处将整个data目录都挂载下来。
WebDAV
nextcloud支持WebDAV协议,该协议的一个好处就是可以将网盘像本地硬盘一样挂载到文件系统
先进入nextcloud的设置,找到WebDAV的url
在文件管理器中,鼠标右键点击此电脑——>映射网络驱动器
输入刚才复制的url,点击完成,稍等一会会弹出账号密码输入框,登录即可
然后就能看到该网盘,可以像在本地操作一样对其进行操作
注意事项
注1:需开启
webclient服务才能使用WebDAV协议,否则无法连接网盘
开启方法:
使用管理员权限打开命令提示符窗口,输入:net start webclient
注2:windows10默认不支持http协议的WebDAV,否则也会出现无法连接的情况。修改注册表即可
然后重启一下webclient,再次尝试连接即可
文件大小限制
使用webdav复制文件出现如下错误
解决方案:
修改注册表:计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\WebClient\Parameters
其默认值为:50000000
第三方客户端
在windows下,使用webdav传输文件是没有进度条的,而且每次重启系统它还不会自动登录,也不会记住账户名和密码,总之就是有很多问题,但第三方客户端可以解决,推荐使用 raidrive
反向代理获取真实ip
如果使用反向代理的话nextcloud就会一直认为是网关那台机器在操作,从nextcloud的反向代理文档来看,它支持de facto标准,即会自动识别
X-Forwarded-For请求头(注:但是很奇怪,好像我测试好像只有X-Real-IP头才会识别)。所以解决方法就是在反向代理转发流量的时候把这个头带上并指向真实的ip。在Caddy中的配置如下:xxx.woyou.cool { reverse_proxy { to http://nextcloud:80 header_up X-Real-IP {http.request.remote.host} # 关键:让nextcloud获取到实际的客户端ip。nextcloudh能自动获取该请求头以判断是否使用了反向代理 header_up X-Forwarded-For {http.request.header.X-Forwarded-For} header_up X-Forwarded-Port {http.request.port} header_up X-Forwarded-Proto {http.request.scheme} } # https://docs.nextcloud.com/server/28/admin_manual/configuration_server/reverse_proxy_configuration.html redir /.well-known/carddav /remote.php/dav 301 redir /.well-known/caldav /remote.php/dav 301}关于Caddy的反向代理配置:https://caddyserver.com/docs/caddyfile/directives/reverse_proxy
docker中使用traefik作反向代理
拉取traefik镜像
docker镜像地址:https://hub.docker.com/_/traefik
docker pull traefik创建traefik配置文件
traefik.yml
# Docker configuration backend providers: docker: defaultRule: "Host(`{{ trimPrefix `/` .Name }}.your-domain`)" # API and dashboard configuration api: insecure: false dashboard: true注:配置文件中的 your-domain 应替换成服务器的域名,前面那一串就是将被代理服务器名拼接成二级域名,当使用该二级域名访问时就会重定向到对应的服务器
启动traefik
docker run -d -p 8080:8080 -p 80:80 --name traefik -v /var/run/docker.sock:/var/run/docker.sock -v /home/hunt/Templates/traefik.yml:/etc/traefik/traefik.yml --network net1 -l "traefik.http.routers.dashboard.rule=Host(\`traefik.huntzou.com\`) && (PathPrefix(\`/api\`) || PathPrefix(\`/dashboard\`))" -l "traefik.http.routers.dashboard.service=api@internal" traefik注:
也可以不挂载traefik.yml文件,在运行traefik之后使用docker cp将其复制到挂载的位置
挂载 docker.sock 目的是监听docker容器的变化,当有新的容器被创建时traefik就能自动监测到并创建代理规则。sock=socket
需将traefik和被代理服务器放在同一个network下
8080端口用于traefik的控制面板,80和443将用作web服务端口
启动命令中的两个
-l参数是为了在安全模式下启动dashboard由于linux命令行中的反引号有特殊意义,故这里都需要转义
关于安全模式下的dashboard配置较为复杂,详见:https://doc.traefik.io/traefik/operations/dashboard/
启动web服务
我这里使用两个nginx当作被代理服务器
sudo docker run -d --name nginx1 --network net1 nginx sudo docker run -d --name nginx2 --network net1 nginx打开traefik控制台页面就能看到其自动检测出了nginx,并根据其配置文件生成了二级域名映射。
买了《日本蜡烛图技术》
刚随手翻看了几页,后面应该不会再看了。
网上看到有人推荐这本书,也没想着先去了解下内容,就下单买了。
开始我以为是一些原理性的东西,比如说通过对市场的分析,使用一些数学工具对二级市场进行一些分析和简单的预测等等,看了下目录发现完全不是这么回事。
目录给我的第一感觉就是玄学,这不就是那些老大爷口中所谓的一些技术吗。
随手翻看了几页,发现确实是这样。它就是告诉你k线呈现出某种状态可能意味着什么,并给这些个状态起一个很玄学的名字。至于原理那真是一点没涉及到。
我想,这和算命也没啥区别了。通过看手相获知命运也是一个道理。虽然手相在一定程度上能反应个人职业,但其变数还是太大了。整本书都是这样的tricks,毫无技术可言。
无聊图220606
素材来源于网络
经济学原理笔记17——货币
货币
货币(Money)是经济中人们经常性地用来从其他人那里购买物品与服务的一组资产(现金(M0)、饭卡、支付宝余额等)
货币的职能:
- 交换媒介
- 记账单位
- 价值储藏
使用货币交易后不立即使用该货币交换其他东西,则该货币就储藏了价值能满足以上三个职能的都可以称之为货币。
如何选择资产持有形式?
需考虑资产的 流动性 和 收益性
- 流动性:资产能够转换成经济中的交换媒介的容易程度(直接使用该资产进行交换)
- 收益性:赚钱的能力,例如房产可能会在几年内涨好多倍
货币的特征是流动性很强,收益性极差的资产
货币的存量
经济中流动的货币量称为货币存量
中央银行
职能:
- 监督银行体系
- 调节经济中的货币数量
银行在货币供给中的作用
银行可以影响经济中活期储蓄的数量和货币供给(改变货币形式或货币供给)
如果银行仅用作存款,则不影响货币供给(活期存款)
准备金:银行吸收但没有贷出的存款
货币创造
假设向银行存款100元,银行将其中百分之九十(90元)用于放贷。剩下10元作为准备金
贷款人拿到90元继续存入银行,银行又拿其中的百分之九十(81元)用于放贷。此时,银行中的货币总量就相当于是 100 + 90 = 190 元
贷款人又能继续将这81存入银行,如此往复,货币总量就会增大。
货币乘数
货币乘数 = 货币总量 / 准备金(中央银行发行的货币数量)
指银行系统中相对于每1美元所能创造的货币数量(中国目前货币乘数大约是5,则说明市场上货币总量约为实际的5倍)
控制货币供给
改变贴现率
银行可以向中央银行贷款,这样的贷款会使得货币总量上升。该贷款的利率即为贴现率
改变准备金率
改变准备金数
银行挤兑
由于部分储蓄被银行拿去贷款,故若短时间内有大量提现要求,就会发生银行挤兑
银行挤兑使货币创造的过程反方向起作用,从而减少了货币的供给
货币增长与通货膨胀
经济体中货币数量过多(货币贬值)就会引起通胀
货币的价值是由货币的供给(中央银行)和需求(普罗大众)决定的
货币需求:反映了人们愿意以流动的形式持有的财富数量(直接把钱拿手上)
例如:物价越高,货币需求越高。存款利率越高,货币需求越低
无聊图220604
素材来源于网络
经济学原理笔记16——失业
长期失业
在理想的竞争市场上,理论上由于供需平衡就不会出现长期失业。但会出现短期失业
周期性失业
- 周期性失业指的式失业围绕其自然失业率逐年波动。例如工厂订单减少造成失业,但也会因为订单增多而产生就业
- 它和经济周期的短期上升和下降相关联
什么是失业者?
一个人暂时没工作,
且正在寻找工作失业率计算方式:
失业率 = 失业者/劳动力(劳动力:失业者+就业者)
失业原因
因为经济一直在变动,所以寻找工作过程中的失业是不可避免的
需求的行业和地区结构的变动
劳动力供给的数量超出了需求数量,即工资高于了均衡工资。这就会带来长期性失业
计量经济学入门_黄少敏
内容来源于网络,仅供学习
https://files.woyou.cool/s/fHnrxdJ5jy4A9iB
无聊图220602
素材来源于网络
经济学原理笔记11——收入差别与歧视
造成收入差距的原因
劳动力的供给和需求
劳动力的需求反映了劳动力的边际生产率
在均衡状态下,每个工人得到的是他对整个经济的物品与服务生产边际贡献的价值
理论上讲,最终工人的工资是趋近一致的,但由于工人和工作的不同特点引起劳动需求、供给与均衡工资的不同
补偿性差别
由于工作的非货币特征引起的工资差别
例如煤矿工人比较危险,企业需支付更高的工资
人力资本
对人的投资的累计,例如教育、锻炼
为了提高未来的生产力而对教育进行投资
能力、努力和机遇
因人而异
对教育的另一种观点:信号
企业把教育状况作为区分高能量工人与低能力工人的一种方法。例如某人学习了数学并不能说他比没学数学的人要聪明。但一种假设认为,他就是因为比较聪明,能力比较大,所以才会学数学,而另外一些人因为能力不足,所以就没学。这就是将教育水平看作是一种能力的信号。
超级明星现象
两个人有一定差别,但差别不大。
由于人总是追求最好的享受,所以即使两人差别不大,人们还是都愿意雇佣生产力更高的那个人
歧视经济学
根本原因
对不同的人支付不同的工资
从上述分析可得,即使在一个没有歧视的劳动力市场,不同人的工资也是不同的
人们拥有的人力资源数量以及能够并愿意从事工作的种类是不同的。例如男人相比女人更愿意从事体力劳动
由于不同群体之间平均工资的差别部分反映了人力资本和工作特性的差别,这些差别本身并没有说明劳动力市场上有多大歧视。例如黑人的工资平均比白人低,但不能直接说歧视黑人,有可能是因为黑人平均受教育水平较低导致的。
歧视出现的直接原因
- 雇主的歧视。
- 顾客和政府的歧视。例如消费者更喜欢好看的前台,则逼迫企业用工歧视
收入分布(分配)
社会收入的不同是否是公平、平等或合意的呢?
基尼系数
将所有人收入按低到高排序,计算每个收入区间的占比得到一条曲线。该曲线与斜率为1的直线围成的面积就是基尼系数
可以想象,如果收入绝对平等,则该曲线应该等于斜率为1的直线,基尼系数越大,收入越不平等。
贫困率
家庭收入低于贫困线的绝对水平人口百分比。这是一个绝对指标,并不关注其与富人的相对差距。例如美国制定的贫困线为 能吃饱饭的收入*3
本质上还是政治问题,因为贫困线都是国家自己制定的,无法做横向对比
经济学原理笔记12——一国收入的衡量
宏观经济学
微观经济学研究个人、家庭、企业、行业如何做出决策,以及它们如何在市场上相互作用
宏观经济学研究一个整体的经济,一个省市、国家。其目标在于解释同时影响许多家庭企业和市场的因素
宏观经济学考虑加总的经济变量(统计量),但不是简单的加和,例如一些加权和等。
主要包括:
- 总产出(或收入)
- 通货膨胀
- 失业
如果影响因素包含上述三个之一,则基本上都是宏观经济学的问题。
例如:
为什么某些国家平均收入高于另一国家?
为什么有时候物价在一段时间涨势迅速,其他时间较为平缓?
衡量方法
GDP
国内生产总值:在一段时期、一国范围内生产的所有
最终物品和服务的市场总价值。即将所有商品价格和总量相乘再求和注:
- 它记录最终物品而非中间物品的价值(用小麦生产面粉,再用面粉生产面包,则只计算面包的价值而不算小麦和面粉的价值)
也可以用所有生产者之间的增加值之和来计算。(用面粉和小麦价值的差值加上面包和面粉价值的差值)- 它包括当期生产的物品和服务,而不是对过去生产物品的交易(去年买了一辆车就不能算在今年的GDP中)
- 它衡量的是一个国家范围内的总价值
哪些可以被计入GDP
GDP包括在经济中生产,并在市场上合法销售的各项物品或服务
排除了大多数在家里生产和消费、因而从未进入市场的项目。例如:父母帮忙看孩子不计入GDP,但是雇保姆看孩子就计入
排除了违法生产和销售的项目。例如毒品
经济的收入与支出
除了产出之外,GDP也是衡量收入和支出的一种方法
收入:经济中每个人获得的收入(工资、地租、利润等),通常由企业支付
支出:家庭在经济所产出的物品与服务上的总花费
原因:
可以想象一张循环流向图:企业的支出——>员工的收入——>员工用该收入购买企业的产品——>企业的收入——>企业用该收入支付员工工资——>企业的支出——>…
GDP计算的是流通物品的总价值,在上述循环图中,流通物品的总价值=企业生产的产品=员工的支出=企业的收入=员工的收入=企业的支出。所以基本可以使用GDP衡量收入和支出(排除税收、国际贸易等因素)
所以,就一个经济体来说,收入恒等于支出,二者都等于产出
注:到底哪些交易能被算到GDP呢?
本质上要看交易的商品或服务是不是这段时间内企业的产出。例如我买一辆新车,因为车是今年生产的,所以要计入GDP,我买一辆几年前生产的旧车就不算
解释:假如一个企业今年生产并销售了3辆车,但市场今年一共交易了5辆车,其中两辆是去年的二手车。可以根据家庭总支出或企业总收入计算今年GDP
根据家庭总支出计算:GDP为5辆车的总价值
根据企业总收入计算:GDP为3辆车的总价值
这就矛盾了,因为这两个数字应该相等且等于GDP的。按照定义,应该以3辆车的总价值为GDP
衍生概念
- GNP:国民生产总值
一国居民的收入(或支出或总价值),与GDP的区别是:加上了本国公民在国外的收入,减去了外国人在本国的收入。- NNP:国民生产净值
GNP减去折旧的损耗。例如机器用多了会有损耗- 个人收入
NNP中减去企业的收入,加上来自政府的利息收入和转移支付- 个人可支配收入
个人收入减去税收GDP的组成部分(从支出方面考虑)
支出意味着需求。当然也可以从收入方面考虑(收入主要指企业的收入,其反应的是供给)
从需求方面考虑,GDP为下面各项之和:
- 消费(C)
- 投资(I)
- 政府购买(G)
- 净出口(NX)
GDP和经济福利
GDP是最好的社会经济福利
单一衡量指标人均GDP告诉我们经济中每个人的平均收入和支出
更高的人均GDP表明更高的生活水平
HDI
人类发展指标(也是单一指标)
包括:人均寿命、教育水平、人均GDP
经济学原理笔记13——生活成本的衡量
通货膨胀描述经济的价格总水平上升情况
通货膨胀率是从上一个时期以来价格水平的百分比变化
消费者价格指数(CPI)的百分比变化衡量了通货膨胀率其他价格指数:生产者价格(PPI)
CPI
衡量一个普通消费者购买物品和服务的总费用
它用来监测物价水平的变动
如何计算
确定固定篮子:确定哪些物品的价格对消费者而言是极为重要的。(食品、房租)
寻找价格:找到篮子中所有商品的价格
整个篮子的总价/基准年篮子总价 = cpi
(今年cpi-去年cpi)/去年cpi = 通胀率
缺陷
替代偏差:固定篮子中某些商品被其他商品部分替代
新物品的引入:出现了对消费者而言极为重要的新的东西(例如智能手机)
无法衡量的质量变动:同样的商品同样的价格但是质量却发生了变化,例如几年前买一台五千快钱的电脑和现在买一台五千块钱的电脑,同样的五千块钱,但其代表的价值却上升了
经济学原理笔记14——生产与增长
微观经济学更关注静态理论——均衡状态
宏观更多关注动态——长期或短期的波动
如何解释各国经济增长差异?如何加快增长?
复利计算指增长率在一段时间上的累计
年度增长率看起来微小,逐年增长复利计算起来就非常大
如果年利率为7%,按复利计算十年翻一番
生产率
单个工人在单位时间能够生产的物品和服务的数量
生产要素直接决定生产率
生产要素
物质资本
机器、工具、建筑等人力资本
通过教育、培训等获得的知识自然资源
技术知识
人类掌握的生产的最佳方法生产函数
描述总投入和总产出的关系
产出量(Y) = 技术水平A*f(劳动量L,物质资本量K,人力资本量H,自然资源量N)
函数 f 需满足
规模报酬不变:L、K、H、N增加x倍,Y也呈x倍增长。注:没有A,我们认为技术可以无限复制而没有损耗。若x为 1/工人数量 ,则结果表示人均量例如:原本只有一个工厂,再新建一个工厂,则其总产出应该是原来的两倍
影响增长的因素
- 鼓励储蓄和投资
但一谓地增加投资会出现边际报酬递减效应- 鼓励来自国外的投资
- 促进健康
- 促进教育
- 建立产权保障和制度稳定
- 允许自由贸易
- 控制人口增长
总量增加,但人均减少。但另一方面来说,人口增多,A有可能变大- 鼓励技术研发
经济学原理笔记15——储蓄、投资与金融体系
储蓄与投资是GDP与生活水平长期增长的重要决定因素
金融体系
金融机构的总称,它促使一个人的储蓄与另一个人的投资相匹配(下面 储蓄与投资 有证明)。本质都是将经济中的稀缺资源从储蓄者转移到借用者(储蓄的过程就是把钱存进银行,银行再把钱贷给其他人)
金融机构分为金融市场和金融中介机构
金融市场:储蓄者直接向借用者提供资金的机构:股票市场、债券市场等
金融中介:银行、基金等
股票市场市盈率
价格——收益比,简称 P/E 值,是过去一年公司的股票价格除以每股收益额(包括股息和未分配利润)
市盈率倒数即 E/P 相当于购买股票的利息率
市盈率越高,则说明利息越低(也说明企业闲置资金过多,即股票的价格不能有效创造收益)
有效市场假说:股价反应了企业的真实价值。即假如某企业发布了一款受欢迎的产品,引起了股价的上涨,那么已经上涨的股价就包含了这一利好消息。所以
通过k线去预测股市是不现实的储蓄与投资
储蓄(可贷资金)=投资
推导:
总收入 = 消费 + 投资 + 政府支出 + 进出口 ≈ 消费 + 投资 + 政府支出(进出口较小)
总收入 - 消费 - 政府支出 = 投资
(总收入 - 消费 - 税收) + (税收 - 政府支出) = 投资
总收入 - 消费 - 税收 = 私人储蓄
税收 - 政府支出 = 公有储蓄
私人储蓄 + 公有储蓄 = 投资 ——> 总储蓄 = 投资
无聊图220531
素材来源于网络
无聊图220601
素材来源于网络
经济学原理笔记10——生产要素市场
生产要素:用于生产物品与服务的投入
劳动需求
劳动作为一种特殊的商品也有其需求和供给曲线
由于边际产量递减,企业在追求利润最大化时,需将雇佣的工人数设置在边际产量值等于工资的那一点(边际产量:每增加一单位劳动力引起的产量的增加量。边际产量值:边际产量*产品价格)
什么引起劳动需求曲线的移动
- 产出价格
- 技术变革
- 其他要素的供给
技术变革
就一个具体行业而言,技术变革可能会增加或减少劳动需求
不过,技术进步总体上趋向于增加劳动而不是节约劳动。
原因:技术进步相当于是生产可能性边界外移。其造成的影响是所有物品生产总量增加。进而提高消费者福利,假设这些福利体现在各个方面,其中就包含劳动福利,则,考虑劳动需求与供给曲线,劳动供给不变,工资上涨(劳动福利提高导致),则说明劳动需求曲线右移,进而说明劳动需求量增大。
注:
- 生产可能性边界外移:所谓生产可能性边界指的是我用一公斤棉花既可以单独制造10张被子,也可以单独制造100件衣服,那么我就可以使用一条曲线表示用这些棉花同时制造被子和衣服能造多少。例如同时造3张被子或150件衣服。生产边界可能性外移指的是由于技术进步,导致原本只能制造10张被子的棉花现在可以制造20张了。可以想象,原来的那条曲线就向外移动了。
- 假如由于技术进步使得不需要那么多人耕地,如何解释技术进步增加劳动力需求?
技术进步使得某行业劳动力需求下降,但可能会引起另一行业劳动力需求上升,并且上升的数量大于原行业下降的数量。例如农业进步使得不需要那么多人耕地,所以工厂的劳动需求大大增加,原来的农民都去进厂了。
引起劳动供给曲线移动因素
- 嗜好变动
- 可供选择的机会改变(改革开放可以出国打工)
- 移民
无聊图220530
素材来源于网络
经济学原理笔记4——征税的代价(应用)
向买者征税和向卖者征税是无关的。当征税时,买者支付的价格上升,而卖者得到的价格下降。
注:经济学只关心总的市场效率。例如对于税收,虽然说买者和卖者有一定亏损,但政府却有一定收获,所以税收就没有社会成本。
税收如何影响市场参与者的福利?
乍看起来征税确实是没有损失(仅有转移支付),但分析表明,税收对于买卖双方的成本超过了政府的税收收入(效率损失或无谓损失)
无谓损失
征税相当于增加了买者的支出并降低了卖者的收入,进而使得部分买者和卖者退出市场。
而退出市场的这些人原本能带来一些消费者剩余或生产者剩余的,现在就被损失掉了。
原本的消费者剩余:A+B+D,生产者剩余:C+E+F
由于税收使得交易的商品数量减少,买卖双方负担增大,部分买卖者脱离市场,进而导致:
现在的消费者剩余:A,生产者剩余:F,政府拿走了 B+C(交易数量*税率)
也就是说 D+E(即无谓损失) 的部分被浪费掉了。即市场总福利减少
无谓损失的决定因素
- 税收的大小
税收越小,无谓损失越小- 供给和需求弹性
弹性越小,无谓损失越小。因为弹性反应的是市场对价格变动的敏感度(可以从供给需求曲线很容易看出)从税率图上也能得到:
一、随着税率的增大,无谓损失呈平方级增大(三角形面积与底边边长的平方成正比)
所以征很多小的税比征一个很大的税要好
二、税收收入不会随着税率的增大而增大
经济学原理笔记5——国际贸易(应用)
注:讨论的是国际贸易对国内市场的作用,而不是国家和国家之间的市场。
什么决定一个国家进口还是出口某个物品?
基本原则:国内价格高于世界价格就会进口,反之则进口
国际贸易如何影响社会福利?
出口
总的来看,社会总福利增加,但卖者受益,买者损失
分析:
原本消费者剩余为:A+B+C,原本生产者剩余为:D+E
由于国际价格高于国内均衡价格,就会导致更多厂商进入市场并,且由于价格提高,导致更多消费者离场。进而:
现在消费者剩余为:A,现在生产者剩余为:B+C+F+D+E
从总体来看,社会总剩余(总福利)增加了一个F,从卖者来看,其侵占了原来部分消费者剩余(B+C),并产生了新的剩余 F
进口
同出口分析,结果相反
关税
对进口物品征税
使得国内的交易价格增加,出售价格 = min(国际价格+关税,国内均衡价格)
进口限额
限制进口数量
经济学原理笔记6——外部性
有些情况下市场并不会达到社会福利最大化,导致市场失灵
原因一:外部性
原因二:市场势力
外部性
买卖者之间的交易产生了副作用影响了除市场以外的地方,这种副作用就是外部性
外部性引起了市场的无效率,因此不能使得总剩余最大化
根本原因:交易影响了市场以外的一些东西,但却没有人为这些影响买单
负外部性:对市场以外的影响是不利的,例如环境污染、抽烟
正外部性:产生的影响有利也可能导致市场失灵(市场失灵只是说均衡价格不是最优价格),例如注射疫苗、研究新技术、开源软件
社会成本 = 生产成本 + 影响成本(比如造成了环境污染就需要花钱处理该污染)
负外部性存在的情况下,社会成本大于生产成本,供给曲线应该左移,均衡价格也应该上移。但由于企业没有考虑外部性的影响,还是只使用生产成本考虑价格,会导致均衡价格不是最优价格,原因是企业生产过多了。
社会成本曲线和需求曲线的交点才是最优价格
正外部性也是同样分析
解决方法
政府介入方法:
方法一:将外部性内在化,例如征税(负外部性)、补贴(正外部性)
方法二:政策直接调控,例如生产多了就让他少生产
私人解决方法:
科斯定理:假如产权得到明确界定,如果当事各方能够无成本地就资源配置进行谈判协商,那么私人市场总能解决外部性问题,并有效率地配置资源
即:在两个条件下,外部性问题能自动被解决:
- 产权有明确界定
- 交易成本为0(现实很难达到)
私人方法并不是总是有效的,有时似然解决方法失灵是因为交易成本过高以至于不可能达到私人协议
科斯定理
交易成本是在交易各方在协议及遵守协议过程中发生的成本。例如制定协议过程可能需要协商或争论,这也是成本科斯定理提供了一个基准(类似物理中无摩擦状态讨论运动),其核心是一个谈判过程:买卖双方的自由谈判或讨价还价可以使得双方都受益,因此可以提高效率
没有科斯定理之前,人们往往根据问题的表象,即外部性或权利的分配,给出错误结论。科斯定理告诉人们,科斯谈判是不可忽略的因素,
因为理性的个人总有谈判的动因科斯定理指导我们寻找出正确的原因,即造成科斯谈判失败的原因。
举例:
宿舍有两个人:吸烟者和不吸烟者
规定一:吸烟者有吸烟的权利,即吸烟者可以不通过另一个人的同意就吸烟
规定二:不吸烟者有呼吸新鲜空气的权利,即吸烟者必须征得同意才能吸烟
注:这两个规定就是两个不同的产权界定
问一:是不是第一种规定下比第二种规定下更有可能发生吸烟?
答:不是,可能性一样
解释:
关键核心是能够自由谈判
假设吸烟给吸烟者带来的收益是100,给不吸烟者带来的损失是50
在规定一的情况下,吸烟带来的总收益是50,所以吸烟者还是会吸烟
在规定二的情况下,吸烟者可以通过谈判给不吸烟者51,自己则还有49的收益,两人都有收益,则还是会吸烟
假设吸烟给吸烟者带来的收益还是100,但给不吸烟者带来的损失是200
在规定一的情况下,不吸烟者可以给吸烟者101让他不吸烟
在规定二的情况下,不吸烟者可以不让他吸烟
问二:学校规定,吸烟者罚款。这与前两各规定相比,是增加了效率还是减少?
答:减少效率,因为产生了两种扭曲:
- 管不住,即吸烟不该发生却发生了
例如罚款的数量小于吸烟得到的收益,则吸烟者情愿接受罚款- 不该管,即吸烟该发生却未发生
例如本来吸烟可以增加总收益,却没有发生公共物品与共有资源(外部性应用)
物体的不同类型:
排他性:排他的(例如水杯)和不排他的(例如放烟花,你没办法禁止其他人看)
竞争性:某人对该物品的使用减少其他人对该物品的使用(例如高速公路)
一般物品都有排他性和竞争性。例如私人物品是排他的且非竞争的
公共物品具有排他性和竞争性。
共有资源不具有排他性但有竞争性。例如公海捕鱼,会被过渡捕捞产生负的外部性
产权界定很重要
产权就是对某种权力的分配,例如上述吸烟的权利,或者国家发展核武器的权利等,只有产权有明确界定后,科斯定理才有可能生效,综合效率才能够提升。
经济学原理笔记7——生产成本
企业的目标
企业的经济目标就是追求利润最大化。利润 = 总收益 - 总成本
一个企业的生产成本包括其生产物品与服务的所有机会成本(企业有一块布料,可以选择生产衣服或裤子,如果生产了衣服,则没生产裤子的损失就称为了机会成本)
机会成本又分为显性(直接的资金支持,例如购买布料)和隐形成本(例如没生产裤子的损失)
企业的会计衡量的是会计利润,即只有显性成本
边际产量递减
边际产量:每增加一个投入,产生的总收益差值,即 ( 边际产量 = \frac {总收益差值}{新投入数量}\ )
投入和收益并不总成正比,比如一台机器只需要一个人操作,此时增加一个人就会让这两个人的边际产量小于一个人的边际产量
总成本曲线
企业成本一般都分为固定成本(厂房设施)和可变成本(人工成本)
从边际产量加上固定成本容易得出生产函数曲线,进而得到总成本曲线。
边际成本
MC衡量企业增加一单位产量时总成本的增加量。
例如,一顿酒席对每个人的平均成本很高,每个人都要分担买菜做饭的成本。但对新增加的人来说,也就是一双筷子而已,这双筷子就是边际成本。
由边际产量递减可得边际成本递增(一个从投入看,一个从产出看)
边际成本和平均成本的关系
边际成本小于平均成本时,增加产量会使得平均成本降低。边际成本大于平均成本则相反。原因很容易想到,因为在计算平均成本时,是要将边际成本平均掉的,如果边际成本比原本平均成本高,则平均下来就会比原来的平均成本更高
由于一开始会有固定成本,所以在前期,一定是产量增大,平均成本降低。但是由于边际成本的增加,会使得到某个产量后,平均成本开始升高,形成一条U形曲线
综上也很容易想到,边际成本曲线是会穿过平均成本曲线的最低点的
经济学原理笔记8——竞争市场中的企业
企业作为卖者也是价格的接受者
企业收益 = 销售价格 * 销售数量
对竞争企业来说,
边际收益等于物品出售价格,因为每卖出一个商品,得到的收益就是出售价格利润最大化
边际收益和边际成本正好相等时,该产量下的利润达到最大化(注:考虑边际成本递增)
解释:边际收益 = 出售价格 = 平均成本 + 平均利润
即边际收益可以看成是平均成本的偏置,若平均利润为0,则边际收益就是平均成本,由于边际成本穿过平均成本最低点可以推出以上结论(市场的平均利润总是趋近于0,因为一旦有正利润,就会有新的企业进来)
边际成本曲线其实就是卖者的供给曲线
解释:边际成本曲线上的点表示生产到该数量产品后,多生产一个产品所需要的成本。按照上述结论,给定一个价格,企业就只愿意对应到该价格所对应边际成本的产品的数量,多了或者少了都会增加平均成本。
企业短期停业决策
停业期间仍需要支付固定成本,但这已经是沉没成本
如果生产得到的收益小于生产的可变成本,企业就应该停业
经济学原理笔记9——垄断
竞争企业是
价格接受者,而垄断企业是价格制定者如果一个企业是某个产品的唯一卖者,其就可以被认为是垄断者
产生垄断的根本原因是
进入障碍进入障碍的三个主要来源:
- 关键资源由一家企业独有
- 政府给予一个企业生产某种产品的特权
- 生产成本比其他生产者更有效率(自然垄断)
垄断者的边际收益
垄断者的边际收益总是小于其物品的价格
因为需求曲线是向左下方倾斜的,这意味着垄断企业想多卖产品就需要降低价格。例如:某企业想卖 n 个产品就定价在 p 元,若想卖 n+1 个产品就需要定价在 p-x 元,则此时物品的价格为 p-x,边际收益为 p-x-x,这里面第二个 -x 表示:第n个产品本来可以卖p元,但你现在只能以p-x元卖出,则第n个产品收益也减少了x元。
垄断者的利润最大化
垄断企业要追求利益最大化就需要达到产量最大化,但由于边际成本递增使得产量不能无限大,故找到企业最大化(利润最大化)的产量对应的消费者需求曲线上的价格,就能达到利润最大化
垄断的福利代价
由于垄断者收取高于边际成本的价格,它就在消费者的支付意愿和生产者的成本之间形成一个价格差,进而导致销售量小于社会最优量,于是便出现了无谓损失(和税收相似)
对垄断的公共政策
政府对垄断企业可以做出以下反应:
- 努力使得垄断行业更具竞争性
- 管制垄断者的行为
- 把一些私人垄断转换为公有企业
- 什么也不做
价格歧视
将同一个物品以不同的价格卖给不同的消费者
当一个物品在竞争市场出售时,价格歧视是不可能的。企业能够实行价格歧视,则它一定具有某种
市场势力某些市场力量会阻止企业实行价格歧视,例如
套利的力量。它指在一个市场上以低价购买,而在另一个市场上以高价出售,赚取差价(因为价格歧视一定有一个高价和一个低价)价格歧视的两个重要效果:
- 它可以增加垄断者的利润
- 它可以减少无谓损失
例如:机票价格,它能够根据订票时间与起飞时间差值进行歧视,使得用户自愿接受该歧视。例如,对于有些人计划旅游,他就能提前一个月买到便宜票,但有些人公务出差就必须接受最近的贵的票
再如数量折扣,量大优惠也是价格歧视
不完全竞争
企业面临竞争,但竞争没有激烈到使企业称为价格接受者
垄断竞争
许多企业出售
类似但不相同的产品举例:书籍、电影、歌星等
市场上企业的数目要一直调整到经济利润为0为止。(差异越来越小,直到接近完全竞争)
企业仍然面临一条向右下方倾斜的曲线
完全竞争市场中,在长期中没有生产能力过剩,垄断竞争中会,原因是完全竞争中,企业面临的需求曲线是一条水平线(弹性趋近于0)
虽然垄断竞争会产生生产能力过剩,但这并不是市场无效率的来源
对垄断竞争企业来说,价格高于边际成本
。。。。。。。。。。。。。。
寡头
只有少数卖者,每一个都提供类似的或者相同的产品
例如联通移动电信
市场上的任何一个卖者的行为都对其他卖者的利润产生巨大影响
寡头市场的关键特征是合作(科斯谈判)与利己的冲突
最好的选择是合作,成为一个联合企业,像垄断那样生产少量产品把价格定在高于边际成本的地方
但由于每个寡头只关心自己的利润,所以有强大的激励使企业集团难以维持垄断的结果
博弈论
双头是只有两个企业的寡头情况
双头同意垄断的结果:形成一个联合体(称为卡特尔)。但由于政策或者出于自身利益考虑,很难达成合作
假设合作是不可能的,双方
独立选择自己的产量,以使得自己的利润最大化,每个寡头考虑选择时都需要将其他企业的选择考虑在内纳什均衡
相互作用中的每一个经纪人,在其他方所选择的策略为既定时(假设其他人的选择已经确定了),选择了自己的最优策略
注:纳什均衡不是指一个人的策略,而是所有人的策略组合所表示的策略,即该策略对A来说是最优的,同时对B来说也是最优的
囚徒困境:。。。
无聊图220529
素材来源于网络
院里的一个网站没通过安全检查
院里想部署一个网站,但若需要使用学校域名访问则需要通过一些安全检查。最近网站部署上去了,但是由于没通过检查还是无法访问。今天他们找我看看怎么改,看了看检测报告,有感而发。
第一个大的问题就是说启用了不安全的HTTP方法
我觉得很奇怪,OPTIONS怎么就不安全了
查了下是说,该方法会暴露一些服务器或中间件信息等
我没记错的话,这应该就是这个方法的初衷吧。
好比是有这么一家医院,它有很多的科室,皮肤科、脑科、眼科等,一开始,如果有人要来看病,这个人就必须熟悉这个医院有哪些科室,每个科室在什么地方。现在我为了方便病人,加入了一个前台,病人只需要询问前台即可知道该去哪里挂号。这时候医院领导却说,这样搞不行,万一来的人是竞争对手或恶意人员就暴露的医院的信息。所以就不让建立这个前台,很神奇吧。
这让我想起来我之前待过的一家公司,刚进去的时候,让我写了一些接口,因为是前后端分离的项目,用的是restful api,写完后将文档发给前端,后来他找我说接口调不通。检查后发现,我文档明明写的是PUT、DELETE方法,他却用POST方法调用,我让他改改,他说他们为了省事都不用这些方法。这家公司我没待太久。
互联网技术发展太快了,稍微有点惰性就跟不上时代了。
老的技术仍在固步自封,新的技术却在飞速发展,当两者相遇,就会产生很强的割裂感。
无聊图220528
素材均来源于网络,仅供学习
经济学原理笔记3——市场效率
消费者剩余
买者的支付意愿(我愿意花3元买一瓶矿泉水) - 实际支付金额(实际支付了2元) = 买者剩余(1元)。
衡量了消费者购买一种物品感觉到的收益。
价格降低会带来两个效果:
- 使得原来已经在市场中的人受益。(已经在市场中的人可以以更低的价格买到商品,就产生了消费者剩余)
- 使得原来没有在市场中的人进入市场。(一些消费意愿较低的人因为价格下降会进入市场)
降低价格会增加消费者剩余
生产者剩余
卖者得到的量(一瓶矿泉水卖2元) - 卖者实际成本(成本1元) = 生产者剩余(1元)(类似利润,但不完全是)
市场效率
消费者剩余 + 生产者剩余 = 市场效率
由于卖者得到的量等于买者支付的金额(不用交税的情况下),该等式也可写成:
买者的支付意愿 - 卖者的实际成本 = 市场效率
注意:该公式中已经不包含出售价格了。这就说明在市场效率与实际价格无关。价格只是
一双看不见的手用来配置资源(有些人买,有些人不买,有些人生产,有些人不生产)。例如:在计划经济中就没有价格,所有的商品都直接由政府分配。当资源配置使得总剩余(市场效率)最大化时,称为 达到市场效率。
证明:均衡价格使得市场效率最大化
前提假设:
- 市场是完全竞争的,例如没有垄断
- 市场结果只与卖者和买者相关,没有外部性,例如污染问题
左边竖线的调控使得部分原本应处于市场的买者和卖者离开市场,使得市场效率减小。(类似税收)
右边竖线的调控意味着迫使企业以低于成本的价格售卖,这会产生负的市场效率,进而导致总的市场效率减小
综上:只有在均衡价格时,市场效率最高
证明结果其实能说明一个经济学中非常重要(也可能是最重要)的现象:价格虽然在市场福利或市场效率中没有出现,但它却对资源配置起到了至关重要的作用。对于一个物品,市场给出了它的均衡价格后,就将消费者和生产者都分成了愿意进入市场和不愿意进入市场的两类人,无形中就调节了市场,并使得市场效率做大化。
这是违反直觉的:因为想象中,不管是消费者还是生产者都只会关注自己的利益,进而会导致市场毫无规律进而崩溃。但实际上,因为有价格这双无形的手调控着,使得过分关注自己利益的人离开了市场,市场也就稳定了下来且符合双方的利益。
这也是为何我国在执行计划经济后又提出“发展市场经济使其发挥资源配置的基础作用”
为什么市场效率模型重要
市场效率模型引入了两个基本假设,尽管这两个假设与现实社会有一定差距,但市场效率模型依然很重要
很多情况下这两个基本假设是大致符合现实社会的
即使在现实中这些假设不完全成立,它仍然为我们分析问题提供了一个
基准或标尺或参照系例如:学习物理中物体运动的时候需要先学习无摩擦下的运动
有了这些基准或标尺,我们对显示的进一步分析就有了力量。例如:分析垄断问题时,需考虑无垄断的情况下是什么样子。
微信公众平台添加历史文章菜单
好像是从前两年开始微信就没有添加历史文章的功能了,所以只能通过其他方法。
我找到一个有历史文章菜单的公众号,点进其历史文章,然后复制该页面的url
得到如下字符串:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzI4NjAxxxxxx==#wechat_redirect其中有个参数
__biz=MzI4NjAxxxxxx==我一瞅,这貌似是base64编码,使用解码器查看,发现是一串数字,我猜测这个数字可能和该公众号的id有关于是便有两个思路:
- 找到公众号id后进行base64编码
- 直接能找到自己公众号的biz
事实上,找biz异常顺利,随便打开自己的一篇公众号文章,就能从链接中看到biz
直接将之前得到的历史文章url中的biz替换掉就可以了
经济学原理笔记1——供给和需求
现代微观经济学研究供给、需求和市场均衡
一个单一的市场是由某种商品或服务的买卖双方构成的群体,不关心其市场形式(网络或现实等)
买方决定需求,卖方决定供给。他们共同决定市场结果(价格和数量)
若单独考虑每个买者(卖者)的意愿考虑市场结果很困难,所以一个市场的需求和供给考虑的是他们的总和(但不是所有的市场都适用,例如拍卖,该方式仅适用于竞争市场)
竞争市场:买者卖者很多、单个人的影响很有限。
完全竞争:物品完全相同(相同的物品才会有竞争)、买卖者众多以至于个人的意愿对价格影响不大、买者卖者都是价格接受者(买的人希望降价,卖的人希望涨价,结果导致两人都无法决定价格,都只能接受最终的价格)除了竞争市场还有:垄断(只有一个卖者,它就能控制价格)、寡头(只有少数几个卖者,例如百事和可口可乐)
垄断竞争:有很多卖者(有竞争)、商品存在微小差别(百事和可口可乐)、每个卖者可以给自己的商品卖不同的价格(但不能偏离太大,因为毕竟还是有竞争的)竞争市场
需求模型
需求量是买者
愿意且能够购买的商品数量,例如价格升高,需求量就会下降影响需求量的因素:
- 市场价格
- 消费者收入
- 商品价格
- 个人偏好(天气变热,冰激凌需求增加)
- 预期(对未来价格的判断,例如如果你判断房价会上涨,你就会买房)
市场价格:
需求定律:其他条件不变,价格上升导致需求量下降(一般性而言,也有反例)
需求的变化和需求量的变化:需求量的变化单指价格变化导致的变化,需求的变化指价格之外的因素导致的变化
消费者收入:
随着收入的增加,对*正常品* 的需求会增加,但对*劣等品*的需求会减少(例如:有钱了就不爱坐公交反而经常打车了)
相关商品的价格:
替代品:例如麦当劳价格下跌,肯德基的需求就会降低
互补品:例如住房价格下跌,装修的需求量就会上升
需求曲线(汽车价格与汽车需求量之间的关系):
但是也不能单纯只考虑这两个因素,例如:近些年房价在上涨,房屋的需求量也在上涨。若按上述分析,房价上涨应该引起需求量下降才对。但实际上,由于人们对未来房价的期望以及一些非理性因素,就导致了这种情况的发生。
供给模型
供给量:买者原因且能够出售的数量
影响因素:
- 市场价格
- 成本
- 技术
- 预期
- 生产商的数量
供给定律:其他条件不变,价格上升导致供给量增加(没有例外)
供给量变化和供给变化:同需求量
其他同需求量
供给曲线(汽车出售价格与供给量之间的关系):
供求均衡模型
供求定律:在竞争市场上,价格的调整使得供给量和需求量平衡
价格的调节最终会达到一个均衡:达到供求量相对的状况,在供求曲线相交的点
市场条件最终会将市场推向价格均衡点。例如:过剩供给(商品过多)会降低价格,超额需求(商品短缺)会抬高价格
市场不是一定会达到均衡点的:例如外界因素不断不变化、或人的非理性因素影响等
市场价格的变动应当至少考虑两个因素:是供给变化导致的还是需求变化导致的,亦或者是同时的变动
市场价格均衡点:
市场价格变动举例:
例如,原来当一辆车价格是3万时,市场的需求量为3,但现在由于疫情,很多人选择在家办公,进而导致汽车的需求量降低。汽车的价格还是3万时,现在市场的需求量减少到了2。这就导致需求曲线左移。
值得注意的是,此时仅仅是需求曲线发生变化,而供给曲线没变,这意味着疫情这个条件是不影响卖者的,卖者价格的变动仅仅是因为市场价格发生了变动,这也说明卖者也是价格接受者
或者,由于发现了新的大铁矿,使得汽车生产成本降低,原来2万的时候卖家只愿意卖两台汽车,现在愿意卖4台。这就导致供给曲线右移。同样发现大铁矿并没有影响需求曲线,买家甚至可能不知道这个事,价格的降低只是市场调节的影响,买家也只是价格的接受者
上述两种情况都导致了汽车价格的降低,但原因却截然不同。
弹性
是对供需关系分析的补充,使得其分析更加精确
衡量了买者和卖者对市场环境(例如价格)变化做出的反应程度的大小(可以理解为供需曲线在某点的斜率绝对值)
需求的价格弹性
当价格变动了百分之一,需求量的变化的程度
决定因素:
- 必需品还是奢侈品(必需品的价格弹性相对较小)
- 替代品的可获得性(替代品越多,则其价格弹性较大)
- 考察时间的范围(汽油价格在短期内的变化对需求量影响不大,时间越长,弹性越大)
弹性的计量
需求量对价格的变化不强烈:记作弹性小于1(缺乏弹性),即价格变动的比例大于需求量变动的比例
需求量对价格的变化强烈:记作弹性大于1(富于弹性),即价格变动的比例小于需求量变动的比例
弹性与总收益的关系
总收益即买者支付的总金额,也即卖者得到的总收入
经济学原理笔记2——市场和政治政策
在自由的、无管制的市场中,市场的力量建立均衡价格,决定交换商品的数量(即需求曲线与供给曲线的交点)
虽然均衡的状态是有效率的,但并不会使得每个人都满意。
价格控制
实行价格控制的原因是政府认为当前市场价格对买方或卖方不公平。但常常引发意想不到的效果。
控制方式:制定价格上限或价格下限
价格上限
可能出现两种结果:
- 如果价格上限高于均衡价格,则无效果
- 如果上限低于均衡价格,则有约束效果,会出现商品短缺(买方的需求量大于卖方的供给量)。
但由于周边环境的不断变化,会导致两种结果的交叉出现
调控举例:规定房价上限,防止过度涨幅
价格下限
价格下限也同样会产生两个结果:
- 如果下限低于均衡价格,则无影响
- 如果高于均衡价格,则会出现供给过剩,供给大于需求(如果是劳动力市场,就意味着失业)
调控举例:规定最低工资、农产品价格保护
税收
税收改变了原来市场的均衡
不管向谁征税,税收总是使得买者付出更多而卖者得到更少
税收抑制市场活动。
解释:通过供需曲线可以看到,当向买者征税后,买者的需求曲线左移,均衡点也相对左移,则市场的销售量随之减小。同样若向卖者征税,则税收相当于增加了成本,相当于供给曲线左移,也将导致销售量减少。
这进一步说明一个反直觉的现象:不管是由谁交税,结果是一样的
税收负担
买者和卖者是按什么比例交税的?或者既然谁交税都一样,那这个税对谁的影响更大?
答案就取决于需求弹性和供给弹性,税收负担更多地落在缺乏弹性的一方。
因为谁交税都一样,所以图中只显示出现了税收后会出现的情况。出现了税收后,相对于均衡位置,买方多付了钱,而卖方少收了钱,但是他们的负担是不同的
解释:弹性是当条件变得不利时,买方或卖方离开市场的意愿。当征税时,不能轻易地离开市场的一方更多地承担负担。
不均匀光照下的图像二值化处理方案
问题发现
被拍摄的物体由于不均匀光照可能对二值化结果产生较大影响,例如我希望通过二值化方法提取滤芯中间的图形:
因为光照的不均匀,导致图片左下角明显比右上角更亮,加上不合理的二值化阈值,导致中间图形未封闭。进而影响轮廓检测。
解决方案
分块二值化
思路:将整个图形切分为多个部分,对每个部分选取不同的阈值进行二值化,最后组合在一起。
提升对比度
有三种方式:提高高亮度区域、降低低亮度区域、两着同时进行
这里仅以提高高亮度区域举例:
思路:对每个像素点的灰度值使用某种非线性变换,该变换应具有以下特征:
- 低亮度区域值基本不变
- 高亮度区域值趋于统一
经测试,以下方程比较符合要求(详见 Photoshop中曝光度的三个参数原理):
( Y = -((-X + 1)^{\frac {1}{2.2}} - 0.1)^{\frac {1}{2.2}} + 1\ )
其中 X 为原始灰度,Y 为调整后的值。图形如下:
# 提高高光区域亮度 pic = (-np.clip((-pic_crop/255 + 1) ** 2.2 - 0.1, 0, 1) ** (1/2.2) + 1)*255处理后的结果如下第一张图:
可以看到,仅外边高亮轮廓灰度被统一,内部图形阴影几乎没变。经过处理后的轮廓提取更准确了。
伽马变换其实也是这个原理,只不过换了另外一个函数,使得暗的地方更暗,或亮的地方更亮。
直方图均衡化
这也是一种常见的增强对比度方法,图像的直方图反应的是图像中各个灰度值分布数据。例如在某个图中,灰度值为1的像素有多少个,灰度值为2的像素又有多少个等等。
直方图均衡化就好比劫富济贫,把某些数量很多的灰度值向其两边扩散。例如,若一个黑底的图片上有一个白色的圆。经过直方图均衡化之后就会得到一个从中心向四周灰度径向变换的圆。中心的亮度比原来更白,而周边的亮度比原来更暗,这就增强了对比度。
举例:
这是正常的图片以及其直方图
这是经过直方图均衡化之后的
由于对比度的提高,使得暗处的更暗,进而可以完整地提取出整个中间的图形
equalize_hist_pic = cv.equalizeHist(pic)使用梯度计算边缘
有时候光线照射角度实在刁钻:
Photoshop中曝光度的三个参数原理
photoshop中对曝光度有三个可以设置的参数,他们分别是曝光度(Exposure),位移(Offset),灰度系数校正(Gamma)
灰度图
本文以灰度图举例,灰度图是一种单通道图,相比rgb三通道图更简单,更容易理解。
rgb是一种三原色,任何颜色都能由这三种颜色依不同比例混合而成,所以对彩色图片上任意一个像素点都是一个代表这三个颜色强度的长度为3的数组,例如,一张1944×2592大小的图片真实数据量为1944×2592×3
而灰度图只表示明暗关系,其每个像素只有一个数值即灰度。灰度值越大,则说明该点越亮。下文将灰度定为 [ 0, 1 ] ,其中0表示全黑,1表示全白
曝光度(Exposure)
对传统的相机底片来说,成像亮度与光照时间成正相关。即光照越久,被照区域亮度越高,但也不是无限高,到达某个阈值就不会再提高了。
所以,提高该值或减小该值相应的图片会整体变亮或变暗
其计算公式为:
( Y = min(X * 2^{\frac {E}{2.2}}, 1)\ )
- 其中 X 为像素点原始灰度值,E 为曝光度参数值,Y 为最终输出显示值
- 为什么用min函数
如上文所说,亮度最高值为1,我们不能让亮度值比1还大。min函数用来限制最大值- 式子中 2.2 什么含义
见下文中的 灰度系数校正 有解释位移(Offset)
一般来说,位移的作用在于保持高亮区域不变,只提升或降低阴影和低亮度区域。为什么会这样呢?
先看一个对比图,左边是拉小曝光度中的位移产生的结果,右边是整体拉低曲线值,但值较小的灰度被拉低的幅度更大。两者产生了相似的图形。
右边的图形就类似下面这个灰色的方程曲线
由此,可以解释修改该值的作用了。
式子中的 0.4 就是待调整的位移值,修改该值将得到不同的曲线
但基本上,越往右上角看(高光区域),其值越稳定。左下角(低光区域)值的波动更大,意味着修改位移值可以认为只是对低光或阴影部分的调节。
其公式为:
( Y = max(min(X^{2.2} + O, 1) , 0)\ )
- 其中 O 为设置的位移值
灰度系数校正(Gamma)
首先要说明的是,Gamma值在ps中默认显示的是1,但其真实的值应该是2.2,显示为1我认为是方便用户操作。接下来简单解释一些Gamma值,这里用亮度单位做一个说明:
众所周知,手机屏幕亮度单位是nit,现在手机经常能看到上千nit亮度,动不动就有新手机突破记录。
又众所周知,灰度值一般都是一个固定的范围。将不同的亮度对应到一个固定的范围就需要一个映射函数。
我不想用微信
发生了什么
今天偶然看到手机上流量使用统计,很可怕。
因为平时除了吃饭外几乎一直都是待在实验室的,一般也都是连着wifi,去吃饭的时候会关掉wifi,回到实验室就会打开。手动关掉的原因是外面偶尔也会自动连上wifi,但信号极差,几乎是不可用的,为了避免自动连接就会在出门的时候关掉wifi。
不过即使是就吃饭那一会时间,每天仍然会产生几百M的流量,在此之前我并没有太在意,因为我用的是腾讯大王卡,每天固定1G,所以无所谓。
刚才发现,这几百M的流量大部分都是微信产生的,我不明白,我平时并没有什么人联系,也就偶尔用小程序刷刷知乎热榜,这一天大几百M流量是怎么产生的。
昨天的流量统计
刚又去看了下月流量数据统计,真的恐怖,上个月用了我6G流量
与这6个G的流量数据相比,wifi反而只用了4个G。我想,他们是瞅准了你用流量的时候才更新或下载东西的吗?我用的很多软件,当需要消耗大量流量时都会提醒我应该切换到wifi。微信的产品是在用脚趾头想问题的吗?
我又去看了看占用存储空间的排行,果不其然微信排在第一个
我听说别人的微信动不动就能占到十几个G,我不懂,但我大受震惊。我的能这么小可能跟我上个月才重置系统有关吧。
怎么用起微信的
我记得那时候微信在我眼中还是很负面的印象,和陌陌一样。但是随着周边越来越多人用微信,QQ上也看不到什么动态了,加之当时是可以直接通过QQ登录微信并复制好友的,我也就开始用了。我相信大多数人也都是跟我一个情况,用微信基本都是被逼的。微信也算是吸QQ的血才长大的。当然这里面肯定也跟腾讯的发展战略有关。
如何看待
要说起来,我认为telegram、slack确实很不错。但他们功能确实也有点让人目不暇接。微信用起来也确实简单干脆。但除了最基础的聊天算得上好用,其他的功能基本上可以说是反人类。
有理由相信腾讯可能正用微信下一盘大棋,面对指责,他可能只会觉得民众愚钝,目光短浅。
我想到了贪心算法,局部最优也能达成全局最优解。
我是真心希望能不用微信,但又不得不用。
无聊图220523
素材均来源于网络,仅供学习。
用了一年的oppowatch2
入手
去年本来是入手了一块佳明的手表,很好看,使用的是反射屏,我很喜欢。
但恰巧当时oppo发售了oppowatch2,听说使用的是修改后的android系统,并且支持esim。心中那颗diy的心又燃起来了,果断将佳明的表给退掉换了这个。
现在已经戴了一年多了,说说我的感受。简单概括来说就是很失望。
显示
开始的时候没有屏幕常亮功能,我喜欢佳明那个表的很大的一个原因就是我可以任何时间,任何地点以任何角度,任何姿势看时间。这个表不行,必须得动一下手腕或者点一下,很不喜欢,但为了那颗勇于diy的心,还是能接受的。
现在的系统已经具备屏幕常亮的功能了,但是为了省电,常亮的那一块很小,笔画很细,并且我猜测是为了防止烧屏,显示时间的位置会不停地跳来跳去。
室外的不太容易看清,并且由于其光线传感器反应迟钝,即使是点进去看时间,一开始也是看不清的,得过一两秒亮度才会上来。所以之前有段时间我没有开启自动亮度,一直让它顶着最大亮度。但处于省电,还是放弃了。
软件
软件问题是最令我糟心的,我原本想着oppo也算是一个大厂,不会想着捞一笔快钱就跑吧,事实证明我错了。到目前为止,除了手表刚发售时的那几款软件,后面几乎再没有什么诚意的更新了,偶尔上架一两个软件也给人感觉很敷衍。
更敷衍的还有表盘,发售之后,表盘的更新频率越来越低。几个月看不到更新。我刚买它的时候,还想着能不能自己开发一些我自己喜欢的表盘,发现不行,也可能因为我没深入研究,但至少官方没有提供方法。
传感器
跑步的时候GPS冷启动要很久,不过问题不大,我正好热身。但有一次我记得我都围着操场转了两圈了,还没搜索到GPS。另一个很大的槽点,手表上的悦跑圈不能用,对,它有这个软件,但是不能用。我以前跑步都是用手机上的悦跑圈,刚买这个表时,想着用手表上的软件,不行,完全记录不了GPS轨迹,但是它自带的运动app就可以,应该是对第三方软件的限制用以防止电量消耗。
睡眠监测很搞笑,我是一个半夜经常醒的人,有时候我半夜明明醒了好几次,甚至还拿起手机看直播,第二天看手表的睡眠统计依然是睡眠状态。开始我还以为是我老糊涂记错了。后来好几次半夜醒了,我都特地看下时间,但手表没有一次记录正确。没有一次。很搞笑的是,我手表设置了每天早上6点的闹钟,所以我几乎每天6点一定会醒来关闹钟,但会不会继续睡另说。这个手表的睡眠检测中仿佛有根据闹钟时间硬编码,它一定会记录我6点钟会处于清醒状态。以至于有好几次我睡得太死没关闹钟,它也显示我是清醒状态。
系统
系统也是常年看不到更新,之前有一次大的更新,加入了屏幕常亮还算有点价值,再就没有了。
前段时间发现系统更新后出现了一个检测睡眠自动暂停音乐的功能,我是欣喜若狂。我一般都是听书睡觉的,一般也会设置一个定时关闭,但是睡着时听到哪就得每次手动去找,我还想着有了这个功能就可以每次接着听就行了,发现我还是年轻了。这个功能有几个月了,貌似就只有两三次看到看到过它提示说检测到我睡着了,自动把音乐关了。至于真的关没关,我不知道,因为我每天还是得手动去找播放位置。
AI
鱼唇,真的鱼唇。
总结
不得不说,国内这些厂东西做的不怎么地,营销确实还可以,特别是oppo这一类,一有新品发布,b站、b乎、微博啥平台上一堆水军开吹,制造出一副欣欣向荣的景象。我开始也是被蒙蔽了,我再不会相信新品发布后那两个月内的相关推荐了。
其实在买它之前我已经听说了oppowatch1用户的遭遇,但是我还是选择相信他。渣男就是渣男,本性难移。
总的来说,oppowatch2也只是oppo挣快钱的一波操作,什么火就往什么上倘,反正就是告诉别人,我有这个东西,至于使用体验如何,有不就够了。
我是不会再买oppo的任何东西了。
听完了《三体》
前言
今天中午午休听完了三体,要说起来我还是前年考研的时候就开始听这本书的。
我是那种很难入睡的人,只要眼睛一闭上,大脑立刻就会浮现出各种各样的事情,开始胡思乱想起来。偶然可能快要睡着了,突然又一个什么想法从大脑的不知什么地方蹦出来,然后又开始乱想,好多年了。
后来养成了睡觉看游戏直播的习惯,就是把手机开着直播放在床上靠着墙,看着看着就睡着了,方法很有效,偶尔也会越看越精神,但起码不会因为胡思乱想而睡不着觉了。一度发展到甚至我不看直播就睡不着了。
但是看直播睡觉还是有缺陷的。如果开声音会吵到别人,所以我看直播都是静音看的,因为是游戏直播,所以开不开声音问题不大。最大的缺点就是,我的大脑可能还处于叛逆期,每次检测到我困了眼睛即将闭上时,就立刻又精神起来。所以有时候甚至看到凌晨三四点。我想睡,但就是睡不着。
考研期间,看直播已经不行了,虽然它的效果还是比直接睡觉更好,但还是不行。催眠过程还是太长,一般来说,从躺下看直播入睡到睡着,得花上一个小时左右。有时候可能更久。之所以能得出这个结论是因为,每次看之前我都会给直播设定一个定时关闭,开始设置半个小时,后来发现不行,设置一个小时也还是经常会看着它结束,不得不又重置定时。考研期间经常是睡得比较晚起的比较早,如果每天都需要一两个小时催眠的话肯定不行,况且中午就一两个小时休息时间,更不可能都用来催眠。
于是我开始了听相声。郭德纲的相声反反复复我都不知道听了多少遍了,因为他的每一场表演也就是那几个段子的排列组合,甚至连字都不会改。可以想象,听他说出来每句话都是很自然的,甚至感觉像是随意的临场发挥,但其实每次讲这个段子都是这样,每个字,每个语气都不差,可见他是讲了很多遍了,可见他是有多熟练了。
听相声的优点远远大于看直播,我甚至因为听相声睡觉而戒掉了不看直播睡不了觉的怪癖。主要原因我觉得还是,听相声的时候眼睛是闭着的,整个人都处于睡眠该有的状态,于是很容易睡着。当然也有很多时候一听就是几个小时,愣是睡不着的那种。有时实在太晚了我就会直接丢掉耳机,强行让自己睡。有时也会又打开直播看。但总的来说,听的催眠效果还是好于看的。
相声总有听腻的一天,倒也不是听腻,而是翻来覆去就那几个段子。段子听多了我都会背了。导致有时候听到重复的,大脑就不自觉不听了,又转而胡思乱想——这才是我最讨厌的。于是我又转而听其他的。
郭德纲的单口相声,或者说是讲故事的能力确实不错,特别是讲鬼故事,或者一些仙鬼神妖的故事,非常的引人入胜,有时候模仿别人的口音也是非常有趣。他的故事中一般都会有一个讲湖南话的主,非常搞笑。济公传我听了两遍,但是很遗憾,有头没尾。按他的说法,这个故事可以讲很久很久,他也就摘其中一点去讲。其他的一些故事也都非常生动活泼。太多了,短篇的中篇的,我都记不清名字了,但要说有些情节,我感觉就像是我亲眼看见过一般,活灵活现。
我也听过明朝那些事,可能到了我这个年纪,对这种刻意的搞笑已经没那么喜欢了,但那个书讲的还是不错的。这本书我没有听完,因为我的目的也不是听书,就是当作睡前故事。每次也都是定时一个小时,睡着就睡着了,没睡着再续一个小时,第二天睡觉的时候也不管昨天听到哪睡着的,继续他定时退出的地方听就完了。所以对于明朝这本书,和另外其他一些故事,我是听了,也是没听。
开始听三体的时候也是这样,也不是因为我懒得去找睡着的时间点,而是,我确实不在乎我听到哪了,我听的是什么。再者因为是在考研期间,我也不会讲精力放在这些故事上。即使是听,也是干听——单纯的听,不去思考里面的逻辑,不去记里面的东西。这也是我睡觉听书的根本目的——放空大脑,不再胡思乱想。
考研结束后,我有时间和精力去理解故事内容,去体会故事的跌宕起伏。这时我应该是已经囫囵吞枣的快听完第一季了。此时恰又听人说第二季第三季是越来越精彩,所以我决定好好听一下,以后出去也有跟人讨论的资本。
总观
听的过程中很多时候我总是会惊叹刘慈欣科学方面的理解,我这里并不是说“了解”,而说的是“理解”,这是不一样的。可能在我的潜意识里,搞文学的就是应该对科学一窍不通,就像现在的那些流水线职场偶像剧对真正的职场一窍不通一样,不懂装懂只会引起我的反感。但他这个确实不一样,或许是因为对于科学来说我也是局外人。或许对于真正搞科学甚至只是了解一些专业知识的人来说也很可笑呢。但单从我的角度来说,确实已经很大的超乎我的想象了。就如,我可能听说过弦理论,但我也仅仅停留在概念上,而他能让这个东西在他小说的世界里出现很多的应用,并且让人觉得可靠,这就像当我刚听说了冯诺依曼体系后,他已经想象出电脑是什么样子的区别。再如,我知道了光速是很快且不可超越的,而他却由此联想到,光为什么是这么快,有没有可能他只是暂时这么快?——早期宇宙光速无限(文中的一种想象),如果减慢光速会怎么样?甚至能将光速与第三宇宙速度发生联系。甚至由肥皂想到曲率飞船(在此之前我也只是听说曲率飞船,不知道它还和空间扭曲有关系)。给我的感觉就像,你给他了一堆积木,他却能用这堆积木搭建出各种出其不意的东西出来,让你感叹:原理积木还能这么玩。
再者我也很羡慕刘慈欣的表达叙述及描绘能力。我相信我们任何人都有很强大的想象力,我们能想象出各种天马行空的东西,如果单从自己的角度看,我认为我们大部分人能想象的东西绝对比这本书中所描写的更奇幻瑰丽。但一旦我们给别人讲或者写下这些东西的时候,就会发现这完全就是两个东西了。我知道四维空间一定不是书中描绘的那样,我也一直坚信人是不可能想象得出四维空间的。但天马行空的想象总是可以的,我可以想,但我一定描绘不出我想象中的场景。他却能写出来。再者,我是一个表达能力很差的人,我很羡慕他,我到现在对罗辑威胁三体的那段场景记忆尤新,仿佛是亲眼看到的一般。写出来的竟然能有这么强的画面感。
个人认为文章也很受现代科技的局限性。很典型的,即使人类发展了很多年,太空移民已经稀疏平常,甚至造出了光速飞船,更甚都已经过了几百几千亿年,更更甚把地球人当虫子的三体人,更更更甚把三体人都不放在眼里的歌者,这么高超的文明都逃不过我们现在最常见的——操作对话框。虽然对话框已经不再是实体屏幕了,但它还是对话框,即便有了AI加持,很多操作依然是需要用手点击拖拽的,没记错的话,歌者毁灭地球时也是在一个操作窗口完成的,甚至程心和关一帆所在的小宇宙里,作者还特地介绍说,在这里的任何地方都能调出一个对话框,很奇怪,很出戏。我们现在不都已经有脑机接口问世了吗。
另一个感觉很出戏的是对所有飞船推进器的描写,当然这个就很主观。文中所描写的飞船都离不开大喷口设定,这就像工业时代的人们想象中的二十一世纪离不开大齿轮一样。光速飞船另说,难道世界发展了千亿年还是摆脱不掉使用动量守恒推进吗?
内容
读到思想钢印那部分我就希望自己能有一个这玩意,这样我是不是就能统治世界了。我其实一直不太能理解宗教。对我来说,我实在无法想象回族人不吃猪肉。猪肉可是主要肉类来源之一,我之前待的小山村都是养猪吃猪肉的,它们怎么能控制住自己,怎么就能不染朱墨呢。如果不是身边实实在在真有这样的人,我是实在无法想象的。作为从小接收科学教育的我来说,同样无法理解对各种天神的信奉。我无法理解他们能为了一个看不见摸不着的东西还每个月进行斋戒,我更无法想象他们需要每天进行好多次的祷告——毕竟我连一天吃三顿饭的事都觉得烦。我想这应该就是思想钢印吧。我们应该也是被加了一种名为科学的思想钢印,所以对他们再正常不过的行为无法理解。
思想钢印是给人灌输的一种强大信念,例如文中提到,若给人加上“水是有毒的”这种思想钢印,这个人就会坚信水是有毒的,并由此开始惧怕并远离任何有水的东西,进而开始怀疑自己——毕竟人体大部分构成也是水。文中主要用这东西给军队灌输外星战争一定赢的信念,避免消极情绪蔓延。
什么是“思想钢印”
读到罗辑当选面壁者那一块,我也曾想过如果我能当选会是怎样。但我很快打消了这个念头,一是我还是知道我有几斤几两的,凭我大脑里的那点知识和想象力,可行性为零。二是以我对自己的了解,我一定会在纸醉金迷中迷失自我。但如果真给我了这个身份,按照书中的设定,这也是摆脱不掉的。毕竟,罗辑最开始也以为自己只是一个普通人。
面壁计划是人类对抗外星人入侵的计划之一,外星人监视着地球人的一举一动,唯有思想无法被监控。所以人类在行为上不能做出任何有效抵御外星入侵的方法。联合国指派的四个人,让他们终其一生想出对抗外星人的方法,想到了就开始冬眠,等外星人来的时候唤醒他们。想对抗计划的过程中,他们可以动用联合国的任何资源,想做什么都可以,并且不需要解释原因。罗辑也是用这个特权让国家给他找梦中情人。
破壁人是三体外星人对抗面壁计划的方法。在地球上分别找四个人,他们潜伏在四个面壁人身边,使用各种方法得知面壁者的真实计划,然后告诉三体人。
印象比较深的,有个面壁人一直隐藏的很深,即使是他的老婆也是什么都不知道。他们非常恩爱,后来要宣告面壁计划失败时,他老婆才站出来说她就是他的破壁人,并且说自己这些年是怎么怎么监控他的,反正监控过程异常艰辛。他也是秘密保守的特别好,几乎就成功了——几乎。
什么是“面壁人”、“破壁人”
面壁者的身份还是很具有吸引力的,执剑人也具有相似的权力,但终其一生都只能生活在一个小房间里。即使这样也有很多人为其争斗。我想如果面壁者是公开竞标的话,全世界人怕是都会参与进去。
话说回来,我读到这一块的时候有点读爽文的感觉。毕竟这么一个设定,很符合现在的一些霸道总裁、世界主宰的设定。想要什么有什么而不要担心受到惩罚之类的。
对于智子的描写我觉得也是过于受到现实的局限了。听书的时候我一直以为名字是“质子”,而后才知道是”智子“。单就我个人的理解,如果真的存在三维向二维展开的话,即使再小的三维物体,在二维展开也是无限的。文中对此的描写我认为更像是拍扁,即把三维的东西拍的很扁,但本身仍是三维的。很典型的就是智子,文中最开始描述的智子甚至都摆脱不了电路板的设计,它就是将一个质子拍扁一个很大很大的电路板,并在上面雕刻出很复杂的电路——原文好像就是这么描写的。
智子是三体外星人的一种高科技设备,只有质子大小,但可以被精准控制,且其本身移速接近光速。三体人发射了几颗智子到地球上,它有三大作用:
一是为了阻止人类科学的进步,防止在外星舰队来地球之前人类科技水平超过三体人。例如,当人类做原子核撞击实验时,智子就跑到里面干扰实验结果。
二是通信。按照设定,三体事件距离地球好几光年,无法与地球建立直接即时通信。但智子可以,它不受空间限制,可以在任意远的地方与三体人实时互动。这就意味着三体人可以用它与地球人实时通信。
三是监控,按照设定,智子运行速度极快,且装备有各种各样的传感器(传感器。。。)。所以人类的一切活动都能通过智子实时传输给三体人。
什么是“智子”
我无法评价程心,她总让人感觉有些妇人之仁,但又可以理解的那种。我很理解她阻止韦德的那个做法,即使把我放在那个位置,我可能也会那样做。但我还是无法理解她第一次作为执剑人的做法,三体人都攻来了,地球都要被抢走了,你这个时候却心软了。但我毕竟不在那个位置,感受不到那种压力,况且,这也只是小说,换句话说,这只是作者自己的意愿。
再说程心,我觉得云天明挺惨的,他送了程心一颗星星(真正的),程心却希望他死,虽然是无意的,并且此时她也不知道这个星星是云天明送的,但我还是能够感受到云天明当时躺在病床上的绝望。程心一开始并不喜欢他,也不是不喜欢,甚至是没怎么注意过他,所以也谈不上喜不喜欢。但当她知道是他送的星星后,对他的感情立刻发生变化,感觉她仅仅是喜欢送她星星的那个人,至于这个人是谁,无所谓。从后面剧情看,云天明的大脑被三体人复活后,他并没有因为绝望情绪而心生憎恨,一如既往喜欢她。程心后面的表现也并没有让人觉得厌恶,她一直喜欢着云天明。即使是她们到蓝星后的故事中,她不得不和另一个男的共度余生,我也觉得非常可以理解。我在想,或许这才是正常的感情应该有的剧情呢?两个人因为某件事产生了感情,并一直将这份感情延续了下去。所以,针对网上的一些说程心婊的言论,我是不屑的。
一般网上批程心的都是因为她一次毁灭了地球,一次毁灭了太阳系,(还有最后在小宇宙留下小鱼缸,有可能导致宇宙的毁灭),自己乘坐唯一的光速飞船逃离灾难还为自己开脱,加之对云天明感情的变化。她的做法确实又有很大问题,造成了巨大影响。即使文中不断强调,地球与银河系的毁灭的注定的,不可能由她一个人的意愿就决定的。但她还是占很大一部分原因。从我个人理性角度分析其感性性格,我还是认为她的很多行为是可以理解的,这也是我无法评价她的原因。
第一次是作为执剑人的时候。所谓执剑人,就是一个拥有特殊权利,可以打开某个装置,该装置可以同时毁灭地球和三体星球,进而威胁到三体人的地球人,故对三体人有一定的震慑作用,用于阻止他们进攻地球。在三体人眼中,程心并不会对他们造成威胁,当三体人知道她继承了罗辑取得执剑人位置之后,立刻就对地球发动进攻。而程心此时却心软没有打开威慑装置——这也是三体人预料之中的。后面就是三体武器进攻了地球,把地球人都赶到一小片地方,造成数以亿计的死亡。
第二次是知道太阳系即将要被毁灭的时候,韦德想制造光速飞船使人们逃离太阳系(后文中提到,在众多的方法中,这是唯一可以摆脱被彻底毁灭的方法)。但有绝对决定权的程心却阻止了该做法,因为该做法有可能会伤害一些居民和军队。(需要说明的是,当时并不知道这是唯一可行的方法,当时还有很多其他防御计划在进行中)。后来歌者向太阳系丢出了二向箔,毁灭了太阳系。程心却误打误撞得到了唯一的光速飞船跑掉了,成为太阳系仅存的两个人,她还为自己开脱,说如果此时自己也死了,那太阳系的人就少了一半。
第三次并不是明确提到的,而是众多网民的臆想。宇宙因为少了一些物质即将毁灭,少的这些物质正是程心他们所在的小宇宙挖走的(为了让程心在宇宙中活下来,云天明又送了她一个适宜生活的小宇宙,当然,这样的小宇宙还有很多个)。所以要将这些物质返还给大宇宙才行。她们决定放弃小宇宙,但在临走前,程心又在小宇宙中留了一缸鱼,说是要给人类文明留下印记。按照另一个人的设想,宇宙所需要的物质可能要精确到原子。文中并没有交代后续。很多网友按照之前的尿性,就开始推测宇宙可能由此走向毁灭。
程心带来的三次“毁灭”
后记
我并不喜欢看小说,印象中上次完整看完一个小说还是在初中,当时同学有一本讲的网游的小说,我看完了。这么细想下来我好像没看完,我记得当时那本书分三册,我好像之看了第一册。问题不大,反正我不喜欢看,那也是我第一次看的。我觉得很无聊。或者说我是讨厌文字类叙述的东西,一大片一大片的文字看着就烦。听三体也是睡眠需要。两年才听完也足以说明我个人其实仍无所谓这些东西,即使是听到一半让我不听了,我也不会有太大的遗憾感。
至于值不值得看,仁者见仁吧,我已经在找下个听物了,可以肯定的是,它一定不可能是爽文小说。
说起爽文小说,我想起来了,我初中还真完整看过一部小说,那是当时一个同学送我的。是一部霸道总裁文,如果现在让我看,我是一个字都不可能看下去。当时看完还是因为是同学送的,并且当时也并没有现在这样那么极度厌恶这种价值观。这好像才是唯一看完过的一部小说了。
我有考虑听一些英语短文,比如一些英语演讲或者像TED这种,但那种需要集中精神,并且很多时候还听不懂,会使得我更难以入眠,思绪万千。也不能听那些过于高深的名著,会因为内容过于乏味而让我进入胡思乱想状态,无法吸引我的注意力。
所以我还是希望能找到一些有价值,又有趣味的读物听听。比如一些经济学小故事、名著小说例如骆驼祥子等等。
无聊图220521
素材来源于网络,仅供学习。
班级成员
无聊图220516
素材来源于网络
wordpress 后台登录一直是被锁定状态
情景
一直提示过多的错误登录,即使是自己没有输错过密码,即使是过了限制时间再次登录也会被重置限制时间等等,反正就是一直提示尝试次数过多而被限制。
原因
由于安装了
Limit Login Attempts Reloaded插件,该插件会限制同一个ip错误登录的次数,但是又由于开启了nginx的反向代理(并且还是多层代理),导致不管是谁登录后台,都会被认为是同一个ip(nginx服务器的ip)登录的。所以若别人尝试登录达到限制,其他客户端的任何登录都会被限制。临时解决
进入wordpress后台服务器,删除该插件的目录
root@a5665d258313:/var/www/html/wp-content/plugins# pwd /var/www/html/wp-content/plugins root@a5665d258313:/var/www/html/wp-content/plugins# ls xxx xxx xxxx limit-login-attempts-reloaded xxx xxx xxx root@a5665d258313:/var/www/html/wp-content/plugins# rm -rf limit-login-attempts-reloaded永久解决
这种反向代理的场景很常见,那该插件肯定也是有解决的。
配置nginx
在代理的请求头中加上真实IP的信息
插件设置
进入该插件的设置页面最下面就有,在
Trusted IP Origins的头部加上HTTP_X_REAL_IP
为什么默认的 REMOTE_ADDR 获取不到真实IP
因为我使用了多层代理,导致其在nginx内部进行了多次重定向,remote_addr 记录的是最后一次跳转的客户端的地址,即仍然是nginx的ip
这里好像理解的不对,我找找资料先
算法书中的代码不好懂
我总是很难看懂算法书中的某段程序,今天在看某段程序时发现,我总要不住得往前文看这个变量代表什么意思。原因是算法书中的变量都喜欢以一个单字母来命名:
我认为这是非常糟糕做法,它总是追求极致的简介而忽略了可读性,而恰巧这些东西是给不懂这些东西的人阅读的。
我觉得应该尽量避免这种既缺少注释、又随心所欲给变量命名并且本身还是用于描述一件很绕的事情的做法。
Nginx反向代理wordpress开启HTTPS
网站创建过程详见:个人网站搭建过程
申请SSL证书
首先申请一个SSL证书,我在腾讯云上申请的
https://buy.cloud.tencent.com/ssl?fromSource=ssl
注:23年3月20号以后页面进行了改版,现在在证书购买页面看不到免费证书了,需要去 SSL证书管理控制台/我的证书/免费证书 里面才能看到购买免费证书的入口,现在全网域名可配置20个免费证书,腾讯云域名还能额外配置30个免费证书
使用dns验证需手动添加一条域名解析记录
使用文件验证需在web根目录创建指定文件
以下为使用dns验证的方式
根据提示,去域名服务商添加一条解析记录
点击查看域名验证状态,等待几分钟即可,都是自动验证签发的
签发通过后点击下载,会得到一个压缩包,里面有证书以及私钥
修改wordpress地址设置
将原来的http修改为https,关于这两个地址的作用:关于wordpress中WordPress Address和Site Address的理解
给nginx配置SSL证书
将上述证书和私钥复制到nginx服务器上,例如我这里就把它们放在了nginx容器中的 /opt/bitnami/nginx/conf/cert/blog 目录(解压后一共有四个文件,但只需要这两个就够了)
修改nginx配置文件
# 用作将http跳转到https server { listen 80; server_name woyou.cool; rewrite ^/(.*) https://blog.woyou.cool/$1 permanent; } server { listen 443 ssl; server_name blog.woyou.cool; access_log /opt/bitnami/nginx/logs/huntzou_website.log; error_log /opt/bitnami/nginx/logs/huntzou_website_error.log; #证书文件名称 ssl_certificate /opt/bitnami/nginx/conf/cert/blog/blog.woyou.cool_bundle.crt; #私钥文件名称 ssl_certificate_key /opt/bitnami/nginx/conf/cert/blog/blog.woyou.cool.key; ssl_session_timeout 5m; ssl_protocols TLSv1.2 TLSv1.3; ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE; ssl_prefer_server_ciphers on; location / { proxy_set_header X-Real-IP $remote_addr; proxy_set_header HOST $http_host; proxy_set_header X-NginX-Proxy true; # 注意这个配置,一定要有,下文说明 proxy_set_header X-Forwarded-Proto https; proxy_pass http://wp-web:80; proxy_redirect off; } }将配置文件保存后重启nginx
git删除误提交文件
问题描述
今天向github提交代码时提示有大于100M的文件,无法完成push(github规定单文件大于100M无法提交)
错误信息指出,项目中存在一个 xxx.psd 的文件是127.33M,大于100M了。该文件是不应该放在项目中的,于是我删除了该文件,再次push还是不行,原因是该文件已经加入到了版本库中,单纯从工作区中删除是不行的。
解决方法
删除 .git 文件,基于现有代码重新创建版本库
该方法比较简单,适用于不会有任何历史包袱的项目。
rm -rf .git git init使用 git filter-banch 重写版本历史
简单介绍
该命令允许你修改git的提交历史,你可以删除已经提交而又不想提交的文件(例如误提交的,或者私钥等信息),也可以运行 perl 脚本进行历史提交信息的修改。修改后的历史版本将不再和之前的版本兼容,这意味着你只能强行push(-f 参数),若同时别人也在远程分支的基上进行开发,就会造成严重冲突。慎用
官方文档:https://git-scm.com/docs/git-filter-branch
官方不建议使用该命令,因为它可能会带来一些不可预知的问题,更建议使用 git filter-repo
删除误提交部分
git filter-branch --tree-filter 'git rm -f --ignore-unmatch {filename}' HEAD
若某些版本中不包含要删除的文件,则应该使用 -f 和 –ignore-unmatch 参数,否则会报错
最后需强制push
git push origin main -fgit rebase修改提交历史
rebase命令有很多功能,常用的就是通过变基合并代码,即让某个版本中的commit插入其他版本的commit。
使用
git rebase -i {v}可以使用交互模式修改历史提交,例如在某次提交中,我错误地提交了某个大文件
可以看到该commit是倒数第二次提交,所以我可以如下方法删除该次提交
# HEAD~3 指的是最近三次提交 git rebase -i HEAD~3输入该命令后就会进入一个交互页面,一般是一个vim编辑器页面
其上方非注释部分就是我近3次提交的内容,根据下面的注释,我可以选择对历史提交进行各种操作,在此,我选择删除第二次提交,将其 pick 修改为 d 即可,然后保存退出
开启clash代理git访问github还是很慢
如何开启
可能是因为git没有走代理,可做如下设置
# 若希望只对单个项目生效则不要 --global git config --global http.proxy "socks5://127.0.0.1:7890" git config --global https.proxy "socks5://127.0.0.1:7890"取消代理
git config --global --unset http.proxy git config --global --unset https.proxy其中
7890是clash设置的代理端口
或者只针对github单独配置(因为也可能使用其他的git远程仓库,如gitee)
# 添加代理 git config --global http.https://github.com.proxy socks5://127.0.0.1:7890 # 取消代理 git config --global --unset http.https://github.com.proxy如果想对单个项目使用代理,则去除上述命令中的
--global即可如何验证
关闭clash,再进行提交或拉取代码,若设置了代理则会提示拒绝连接
开启clash后再次提交发现没问题了就说明代理设置成功了
还是没效果?
不知道你们什么情况,我根据上述方法测试后发现,即使确定使用了代理也经常会遇到dns解析或超时等问题,新的解决方案是使用
socks5h代理,这里的 h 即 host,表示域名解析也走该代理(socks5a也是一样),否则就是使用本地配置的dns进行解析。git config --global http.proxy socks5h://127.0.0.1:7890 git config --global https.proxy socks5h://127.0.0.1:7890或
git config --global http.https://github.com.proxy socks5h://127.0.0.1:7890CMD怎么配置
在需要设置代理的cmd窗口输入命令
WebAssembly的简单理解
什么是WebAssembly
WebAssembly是一种字节码指令,类比java字节码。它现在已经成为了浏览器的第四大标准语言:html、css、JavaScript、WebAssembly
若想让不同的计算机语言写的程序能够跨平台运行,则需要一个针对不同语言的编译器将它们翻译成一种统一的字节码,在java体系中,编译器能将各种jvm-base的语言(java、groovy、scala等)统一翻译成java字节码文件供执行引擎调用。同样,若想让浏览器也能运行各种语言(c、c++、rust等),则需要使用编译器将各种语言编译成一种统一的语言文件,这个转换后的文件就是WebAssembly指令集文件,通常以.swam为后缀
flutter web 中使用的wasm
为什么要这么做
个人认为有两个主要原因:
- 性能更高
使用wasm技术直接将原本的c文件转换为字节码文件比让浏览器引擎解析js文件要快得多- 减少成本
可以直接将已经用其他语言写好的项目直接转换为web端,大大减少了开发成本比较有名的例如AutoCAD web端,它就是将其原本使用c语言编写的客户端软件编译成了wasm使得用户可以在浏览器上使用、Figma、
flutter web端也使用了该技术
flutter
浏览器访问flutter web项目时,需要先加载一个 canvaskit.wasm 文件,该文件就是将Skia编译成的webassembly文件,这也是flutter能在浏览器中渲染图形的核心文件
Skia
Skia是一套2d渲染库,canvas就使用该库进行渲染
skia是个2D向量图形处理函数库,包含字型、坐标转换,以及点阵图都有高效能且简洁的表现。不仅用于Google Chrome浏览器,新兴的Android开放手机平台也采用skia作为绘图处理,搭配OpenGL/ES与特定的硬件特征,强化显示的效果。
百度百科
为什么不直接使用Skia
既然Chrome已经用了skia,为什么还需要再加载一个wasm格式的Canvaskit文件?
1. Canvaskit 能够缓存绘制中间对象,使得多次渲染性能更高
2. 避免了 gpu 内存和 cpu 内存交换
3. 更可靠的path boolean operations 布尔运算
4. 文字排版功能更好用
skia根据硬件不同有很多后端实现,例如对cpu和gpu的不同实现,canvaskit编译使用的是cpu版本,这就导致canvaskit的性能普遍较低。但canvaskit可以用在部分不支持skia的浏览器上。
如果浏览器不支持wasm怎么办
浏览器会再次将wasm翻译回js执行,这种技术叫做 polyfill
跨平台
当然,其能将多种语言统一成一种语言便具有了跨平台的优势,自然可以不仅仅局限于浏览器了,比如nodejs端。所以后面就出现了越来越多的WebAssembly技术用于跨平台处理
台式机插入耳机底噪很大解决
我是用的是技嘉(Gigabyte)Z590 UD 的主板,最近买了一个解析力较高的耳机,发现连上电脑后耳机电流声很大。网上找了很多方法无效,最终是修改排线位置解决的。
打开机箱发现机箱上端的音频线和其他的各种线材捆绑在了一起
这么杂的线缠绕在一起很难没有底噪
于是我单独将音频线剥离出来单独走线,底噪就消失了
Zernike矩
这两篇文章讲的挺好
https://www.cnblogs.com/ronny/p/3985810.html
https://zhuanlan.zhihu.com/p/392294958?ivk_sa=1024320u
我的理解:
正交多项式可以理解为一组基,类比空间中的一组正交基,你可以通过给该正交基加权的方式得到空间中任意一个点,同理,对正交多项式加权就能得到任意一个n维多项式。
比如泰勒展开,任何函数f(x)都能通过幂级数展开的方式得到一个统一的形式,如展开成 \( f(x) = Ax + Bx^2 +Cx^3+Dx^4...\\),或使用麦克劳林展开、泰勒展开、傅里叶展开,就可以将\((x, x^2,x^3,x^4…)\ )理解为一组基,在它们前面加上不同的权值就能拟合不同的函数,如果将这些不同的权值都取出来作为一个有序集合,那么我就可以认为这个几何就能表示在某种展开方式下的其原函数
若将一个图像看作是一个函数f(x,y),其中x,y表示像素点坐标,则该函数也能通过某种展开方式得到一组权值乘以一组基的形式。zernike就想到了一种方法用以展开单位圆内的图像函数,展开之后的这个权值就是zernike矩(前面说了用这个权值其实就可以确定一个f(x,y)),这组基就是zernike正交多项式。理论上,由于在zernike多项式对单位圆内图形的处理,图形旋转之后其图形本质上是没有变化的,即表示图形的函数f(x,y)没变,则其zernike矩就基本不会变。
Docker常用工具
docker engine
平常说的docker一般就是值docker engine,是由cli及守护程序等组成的一整个docker应用程序,简单类比为电脑上装的QQ、浏览器等软件
docker machine
用于管理多台安装有docker engine的主机,比如我有十台电脑,我就可以通过docker machine同时配置和管理这十台电脑上的docker。或者也可以用它创建虚拟机(在虚拟机软件上创建,例如VirtualBox)然后进行管理
docker compose
用于组织和编排单台主机上的docker容器,比如我希望创建一个服务,该服务包含一个nginx的docker容器,一个service的docker容器和一个mysql的docker容器。
- 不用docker compose时的做法:
- 创建网络
- 编写service端dockerfile、创建镜像、配置网络。。。
- 拉取nginx、mysql镜像、修改配置、暴露端口。。。
- 运行容器
- 使用docker compose的做法
编写docker-compose.yml
# 不代表真实配置形式,仅便于理解 ... network:... services: nginx:... service:... mysql... ...运行
docker-compose up -d命令即可docker swarm
将多台装有docker的主机组合成一个docker集群,并将该集群抽象成单个docker主机,所有对该抽象主机的操作都将同步到集群中各个主机上,且会对该集群的主机进行集群管理,例如容灾处理等 并且通过创建overlay网络使得集群中各主机间能正常通信
- overlay网络 不同于bridge只能单主机间容器的通信,它是一种逻辑网络,即在各主机的docker容器之间建立一种虚拟网络实现通信。
与docker machine的区别
可以简单理解为docker machine是对主机上的docker engine进行管理,docker swarm则是对docker中运行的服务进行管理。类比于一个网吧,网吧老板负责机器的采购升级等,而网管则负责将这些电脑连成一个网络并维护该网络
组合使用案例
- 使用docker-machine给多台机器安装和配置docker engine
- 使用docker-swarm将这些机器汇聚在一起,形成一个虚拟的单一的docker节点
- 使用docker-compose编排好你项目所需要的服务,并通过docker-swarm部署到虚拟节点上即可
UWB技术介绍
UWB(超宽带技术)是什么
uwb(超宽带技术)是一种全新的、与传统通信技术有极大差异的通信新技术。它不需要使用传统通信体制中的载波,而是通过发送和接收具有纳秒或纳秒级以下的极窄
脉冲来传输数据,从而具有GHz量级的带宽。UWB的特点
- 超宽频,其频率覆盖从 3G
5G,6G10G 共 7G 的频段,单信道带宽超过 500MHz- 功率低,按 FCC 等法规,其输出功率被限制在-41dBm/MHz,按单个信道 500MHz计算,其信道功率为-14.3dBm
- 超宽带系统与传统的窄带系统相比,具有穿透力强、功耗低、抗多径效果好、安全性高、系统复杂度低、能提供精确定位精度等优点
优点
- 功耗更低
- 抗干扰能力更强
- 传输效率更高
- 抗多径能力更强
- 防窃听
影响UWB信号质量因素
- 多径效应影响 超宽带UWB信号在传播过程中,会受到周围环境如墙壁、玻璃和桌面等室内物品的反射和折射的影响,产生多路径效应。信号在延迟、幅值和相位等方面的变化,从而产生能量衰减,信噪比下降,导致首达信号并非直达信号,引起测距误差,UWB定位精度也随之下降。
- 多址效应影响 在多个用户环境下,其他用户的UWB信号会干扰目标信号,从而降低了估计的准确性。减小这种干扰的一种方法就是把来自不同用户的信号从时间上分开,也即对不同节点使用不同的时隙进行传输。
- NLOS(非视距信号传播)的影响 视距传播(LOS)是保证信号测量结果准确的首要、必要的前提条件,当移动定位目标和UWB基站之间不能满足条件时,UWB信号的传播只能在折射和衍射等非视距条件下完成,达到接收终端。此时第一个到达的脉冲的时间并不代表TOA的真实值,首达脉冲的方向也不是AOA的真实值,这样就会造成一定的定位误差。
- UWB穿透遮挡物信号减弱对UWB定位精度的影响 UWB信号穿透普通的砖墙时,信号值会减弱将近一半左右。因穿透墙体引起的信号传输时间的变化也会影响定位精度。 各类遮挡物对UWB信号穿透的影响程度如下所示:
- 实体墙:一堵实体墙的这种遮挡将使得UWB信号衰减60-70%,定位精度误差上升30厘米左右,两堵或者两堵以上的实体墙遮挡,将使得UWB无法定位。
- 钢板:钢铁对UWB脉冲信号吸收很严重,将使得UWB无法定位。
- 玻璃:玻璃遮挡对UWB定位精度没太大影响。
- 木板或纸板:一般厚度10厘米左右的木板或纸板对UWB定位精度没太大影响。
- 电线杆或树木:线杆或者树木遮挡时,需要考虑它们之间距离UWB基站或者标签的距离。比如,UWB基站和定位标电签间距50米,电线杆或者树木正好在两者中间,25米处,这种遮挡就无大的影响,如离UWB基站或标签距离很近,比如小于1米,影响就很大。
- 无线干扰对UWB设备精度的影响 由于UWB信号的脉冲持续时间很短,可以认为接受的信号与干扰脉冲是不相关的,因此,经相关处理后,它们的影响可以忽略不计
UWB的应用
测距
UWB测距主要采用双向测距(Two-way Ranging)方法,以下所有的方法都包括两个节点:设备A和设备B,默认设备A是测距的发起者,设备B是响应者;双向测距主要分为以下两种方法(1和2):
- 单边双向测距(Single-sided Two-way Ranging)
- 双边双向测距(Double-sided Two-way Ranging)
单边双向测距(Single-sided Two-way Ranging)
单边双向测距(Single-sided Two-way Ranging),单侧双向测距(SS-TWR)是对单个往返消息时间上的简单测量,设备A主动发送数据到设备B,设备B返回数据响应设备A。
测距流程
设备A(Device A)主动发送(TX)数据,同时记录发送时间戳,设备B(Device B)接收到之后记录接收时间戳;延时Treply之后,设备B发送数据,同时记录发送时间戳,设备A接收数据,同时记录接收时间戳。 所以可以拿到两个时间差数据,设备A的时间差Tround和设备B的时间差Treply,最终得到无线信号的飞行时间Tprop如下:
两个差值时间都是基于本地的时钟计算得到的,本地时钟误差可以抵消,但是不同设备之间会存在微小的时钟偏移,假设设备A和B的时钟偏移分别为eA和eB,因此得到的飞行时间会随着Treply的增加而增加,测距误差的方程如下:
Treply越小,测距越准确。另外Treply不仅仅是设备B接收到发送的时间,也包括装载数据和发送数据耗费的时间(UWB除了支持定位之外,也可以传输数据,标准可以装载128字节,扩展模式可以装载1024字节数据) 随着Treply和时钟偏移的增加,会增加飞行时间的误差,从而使得测距不准确。 因此单边双向测距(SS-TWR)并不常用,但对于特定的应用,如果对于精度要求不是很高,但是需要更短的测距时间可以采用。
双边双向测距(Double-sided Two-way Ranging)
双边双向测距(Double-sided Two-way Ranging)是单边双向测距的一种扩展测距方法,记录了两个往返的时间戳,最后得到飞行时间,虽然增加了响应的时间,但会降低测距误差。双边双向测距根据发送消息个数不同,分为两种方法:
- 4消息方式(4 messages)
- 3消息方式(3 messages)
双边双向测距4消息方式
分为两次测距,设备A主动发起第一次测距消息,设备B响应,得到4个时间戳;然后过了一段时间,设备B主动发起测距,设备A响应,同样得到4个不同的时间戳。最终可以得到如下四个时间差:
VMware中桥接、仅主机、NAT三个模式的简单理解
在VMware菜单栏中,依次选择 编辑 > 虚拟网络编辑器 > 更改设置(需管理员权限)可以看到VMware中存在的一些网络,其中分为三大类:桥接、仅主机、NAT
桥接模式
最常用的模式,VMware虚拟出一个交换机,将所有处于该网络下的虚拟机都通过该交换机连接到宿主机所在的网络中,此时,所有的虚拟机与宿主机在外部真实路由器网络层面是相等的。
仅主机模式
使用虚拟路由器创建出一个隔离的虚拟网络,所有处于该网络的设备之间可以通信,但不能同外界通信(宿主机除外,可以理解为它装了两块网卡,一块连接虚拟网络,一块连接外部路由器,所以两边都能通信),所有的虚拟机与宿主机在内部虚拟路由器网络层面是相等的。相当于国家的一些军用网络(很多军用网络都是独立组网,不与任何外界相连的)
NAT模式
在仅主机模式的基础上,将虚拟路由器同外部网络进行连接,形成一个NAT网络,此时虚拟机就可以同外部网络进行通信,相当于校园内部的局域网通过路由器连接到公网上了
关于wordpress中WordPress Address和Site Address的理解
wordpress的 设置=>基本设置 中存在这样两个让人困惑的配置
WordPress Address
即wordpress资源文件在服务器中存放的位置,例如,加载wordpress网页时需要加载的各种js、css等资源文件
若错误地设置了该地址,则wordpress网页就会显示不正常(毕竟css等资源文件找不到了),但数据依然可以正常获取
错误修复
若不慎错误地修改了该地址导致页面不正常,可通过以下方式恢复
找到wordpress主题文件夹所在位置,并在其中的 functions.php 文件最下面加入:
update_option('siteurl','http://127.0.0.1(即修改前地址)'); update_option('home','http://127.0.0.1(即修改前地址)');强制刷新wordpress网页即可
页面正常后再删除这两行代码
Site Address
即网站访问地址,访问该地址将进入你的默认首页。相当于给首页增加了一个别名。该地址可随意修改
例如将该地址原本为 http://127.0.0.1,此时访问 http://127.0.0.1:anotherpage 将显示404。
若将该地址修改为 http://127.0.0.1:anotherpage,此时就能同时使用 http://127.0.0.1 和 http://127.0.0.1:anotherpage 进行访问
总结
不管是 WordPress Address 还是 Site Address 都不会修改wordpress原本的访问路径,其原本访问路径在apache启动时就已经确定了。修改Site Address基本不会影响访问,修改WordPress Address也只不过是在网页加载时告诉网页,我将资源文件放在哪了。但实际放没放,那就是另一回事了。
浏览器渲染数学公式
使用
MathJax可以在主流浏览器渲染Latex格式的数学公式,wordpress上也可以用。github:https://github.com/mathjax/MathJax
使用方式
直接引用CDN
在页面header中加入以下代码即可:
<script src="https://polyfill.io/v3/polyfill.min.js?features=es6"></script> <script id="MathJax-script" async src="https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js"></script>
- 其中
polyfill库是用来提升兼容性的,可以不要下载到本地使用
方式一:使用npm下载
npm install mathjax@3 mv node_modules/mathjax/es5 你的存放地址/mathjax方式二:直接下载源码文件
git clone https://github.com/mathjax/MathJax.git mj-tmp mv mj-tmp/es5 你的存放地址/mathjax然后在项目中引用即可
<script id="MathJax-script" async src="你的存放地址/mathjax/tex-chtml.js"></script>在nodejs项目中使用
- 安装包
npm install mathjax@3- 在项目中引用
require('mathjax').init({ loader: {load: ['input/tex', 'output/svg']} // 定义MathJax 配置 }).then((MathJax) => { const svg = MathJax.tex2svg('\\frac{1}{x^2-1}', {display: true}); // 这两行将在 MathJax 加载完成之后执行 console.log(MathJax.startup.adaptor.outerHTML(svg)); }).catch((err) => console.log(err.message));注意事项
MathJax 默认不支持使用单个
$作为内联公式,因为美元符号经常会被用在展示价格,容易引起冲突。应使用( ... )代替$...$loss总是收敛到0.69左右
这种情况一般是在使用了交叉熵的二分类问题上容易出现,同样的,也可能出现loss收敛到1.0986、1.386等等,其实他们就是log(1/2)、log(1/3)、log(1/4)。。。
问题概述
根本原因:交叉熵
若q=0.5则对于01分布来说,H=log(0.5)=0.69,同理对于n分类问题来说,loss可能会收敛到log(1/n),这都是因为各个类别拟合概率相近导致的,再看看为什么会导致各类别拟合概率相似
常见原因之一:Sigmoid
使用交叉熵之前通常会使用sigmoid作为激活函数,sigmoid公式及图像为:
由此可知,有两种情况会使得sigmoid的输出都是相近的
1. 自变量x都是相近的,导致函数值也相近
2. 当自变量x大于或小于某个数之后(例如5和-5),其值基本就等于1或-1。那么如果上层神经元的输出都是一个较大或较小的数,则经过sigmoid之后得到数组元素就都是1或-1,则针对每个分类的概率就是相同的,这样的数据得到的交叉熵就是log(0.5)或者log(1/3)或者log(1/4)…
对于第一种情况,我们看看为什么自变量x会都相近。一般来说,线性函数的结果输入到sigmoid中,其公式为:wX=Y
由此可知,若要使得y中的元素相同,又有两种方式:
1. w中每一行都相同或相近
2. X趋近于0,则此时Y也会都趋近于0
再分析逐个分析
出现第一种情况一般来说可能是权重的初始值设置不合理,例如使用pytorch中的fill_函数使得所有的权重都相同,且后续训练也没有有效地更新权重导致的(为什么没更新权重后面会说),则可以选择一些更随机的初始化方法。
为什么权重没有更新:可能是学习率设置的过小或初始权重过大或情况二,一般来说,如果是学习率设置过小或初始权重过大,则在足够多的迭代次数之后,loss就会恢复正常
出现第二种情况则是数据源的问题(若全连接前还有其他层,则其他层的输出就已经很小了),此时可以通过normalize的方法对batch的数据进行处理或放大之后再输送到全连接层
对于第二种情况,较好的做法是在将数据送到sigmoid之前先进行normalize以上只是两种特殊情况,下面将列举我目前能想到的五种情况
出现问题原因及解决方法
当输入与输出确实不相关时
解释:这个很好理解,因为你的数据本身就不能拟合,所以不管是让人做分类还是让机器做分类都只能得到50%的正确率
解决办法:数据源上找原因
当模型初始权重相同且较大,且学习率较小时
解释:权重相同则意味着模型预测每个分类的概率输出是一样的,学习率较小意味着权重更新幅度太小,导致即使经过了长时间的训练权重依然几乎相同——同初始值一样。
解决办法:理论上,出现这种情况,只要迭代的次数足够多,模型还是可以收敛的。也可以使用pytorch的norm_方法初始化权重,并增大学习率
当模型的输入本身就很小,或者模型初始化权重很小时
解释:两个原因,1. 由于预测输入是通过线性函数 w*x + b=y 得出的,如果此时x或w趋近于0,则得出的y也都是趋近于0或偏置b的,最终导致模型对各个类的概率相同。2. 同下方的将输入整体放大的情况
解决办法:对输入做normalization处理,合理初始化权重,比如使用N(0,0.001)分布初始化权重
特征不明显,导致长时间训练不拟合
解释:emmmm
解决办法:做一些特征工程,多迭代迭代应该也能跑出来,增加模型复杂度或许也有用
使用sigmoid或tanh这类函数时,将输入特征整体放大后使得收敛更困难
解释:从pytorch文档中可以看出,lstm使用了很多sigmoid和tanh激活函数
这两个函数都有一个特征,就是他们的导数在大于或小于某个范围时几乎等于0,这就导致backward时梯度越来越小,进而导致权重无法更新或极慢,如下图
所以如果输入lstm的值都比较大或比较小,从官网给出的公式不难看出,其输出就容易只在0、1、-1三个数附近徘徊(如下图中的第二个图)
解决办法:解决办法很多,这里写三种
想要解决这个问题就得在lstm的输入端做一些处理,比如,我这里使用sin函数将值域固定在某个范围内,起到了一定的效果
或者,直接使用pytorch提供的layerNorm
或者,当我不进行norm只使用batch输入的时候,批量化处理会排除个别元素干扰,对整个batch求均值能提高收敛速度减小训练时间
wordpress WP Statistics插件无法开启GeoIP国家和城市统计功能
现象
勾选
GeoIP收集和GeoIP城市点击保存无效
问题原因
这两个选项需从github上下载ip地址和物理地址映射的数据文件,但国内访问github存在问题
解决方案
直接下载该映射数据文件放到指定目录
具体方法
- 下载国家和城市与ip的映射数据文件(GeoLite2数据库,下文有介绍)
https://raw.githubusercontent.com/wp-statistics/GeoLite2-Country/master/GeoLite2-Country.mmdb.gz
https://raw.githubusercontent.com/wp-statistics/GeoLite2-City/master/GeoLite2-City.mmdb.gz- 解压gz文件(网上很多教程没有这一步,如果你直接将上面下载的文件放在目标文件夹后还是没用,可以试试先解压,我就遇到了这个问题)
- 将解压后的文件放到
html/wp-content/uploads/wp-statistics/目录下,再次尝试开启即可
确认开启了还是没用?
ip显示为一个内网IP,城市都显示的是unknown
你是不是使用了反向代理功能?我也是这种情况,所以你还需要设置WP Statistics使用请求头中的真实ip地址:
Nginx配置中需要有这个
GeoLite2数据库
GeoLite2数据库是一个免费的
ip-物理地址映射数据库,每周二更新一次https://dev.maxmind.com/geoip/geolite2-free-geolocation-data?lang=en
该数据库由MixMind提供,但现在从官网下载较为麻烦,需要申请一个licese key,然后使用该key下载。下载链接:
详见:https://dev.maxmind.com/geoip/updating-databases
也可以从其他渠道下载,例如:
https://github.com/P3TERX/GeoLite.mmdb
https://github.com/wp-statistics/GeoLite2-City
个人网站搭建过程
网站架构
wordpress是一个用于快速搭建博客平台的php软件,运行在apache下
wekan是一个开源看板,类似trello,可用于项目管理和计划安排
搭建步骤
环境准备
1. 安装docker
2. 拉取wordpress、mysql、wekan、mongo的docker镜像
docker pull wordpress docker pull mysql docker pull mongo:4.4-rc-focal docker pull wekanteam/wekan:v5.35 # 作者反馈最新版的镜像有bug,不建议拉取最新的。不过我看他说目前已经修复了。docker创建网络用于容器间通信
docker network create huntzou_website启动容器
1. 启动mysql
docker run --name db-mysql --restart=always -v /etc/localtime:/etc/localtime -e MYSQL_ROOT_PASSWORD=<your pwd> -d --network huntzou_website f2ad92. 进入到mysql容器中创建数据库
docker exec -it <containerID> bash mysql -u<your db user> -p CREATE DATABASE <your db name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;3. 启动wordpress
docker run --name wp-web --restart=always -v /etc/localtime:/etc/localtime --network huntzou_website -d -e WORDPRESS_DB_HOST=db-mysql -e WORDPRESS_DB_USER=<your db user> -e WORDPRESS_DB_PASSWORD=<your db pwd> -e WORDPRESS_DB_NAME=<your db name> -e WORDPRESS_TABLE_PREFIX=wp b44d4. 启动mongodb
交叉熵
信息量
用于描述事件包含的信息。一件事发生的概率越小,则其信息量越大。如
事件A:“Hunt当选了国家杰出青年称号”
事件B:“Hunt当选了学生会主席”
两个事件都有可能发生,但他们所蕴含的信息是有差别的,比如,若要发生事件A,则Hunt至少满足四个条件:Hunt年龄小于四十五岁、Hunt具有博士学位、Hunt有较好的科研成果、Hunt曾在高校或科研所工作。但若只是事件B发生了,我们能知道的仅仅是:Hunt是一名学生。显然,事件A的信息量大于事件B,且事件A发生的概率P(A)要小于事件B发生的概率P(B)
则某个事件发生的概率越小,其信息量越大。
信息量与发生概率负相关,且当某件事x的发生概率为1时,其信息量应该是0,若发生概率无线小,则其信息量应该无限大,log函数能较好匹配这个条件,由此可以得出信息量的公式:
熵
一个系统是一系列事件的集合,比如我们生活中无时无刻不在发生着各种各样的事件。熵则表示这整个系统中所有可能发生事件的信息量期望。若一个系统所有可能出现的事件总和为n,每个事件xi发生的概率为P(xi),则熵的公式为:
若将抛掷一枚硬币单独看成一个系统,则该系统由两个事件组成:抛正面(概率为p)和抛反面(概率为 1-p),则上式可写成:
相对熵(KL散度)
假设现在我让你去猜某个系统中所有事件发生的概率,对于有n的事件的系统,第i个事件真实发生的概率为 P(xi),而你的猜测是Q(xi),如何衡量你猜的是否准确呢?最简单的办法就是使用Q(xi) - P(xi),其绝对值越小,则说明猜的越准。对于整个系统来说,我可以将简单的概率猜测差值转换为系统熵的差值,则公式为:
交叉熵
相对熵描述的是对同一个随机变量两种不同分布的差异大小,在机器学习中,我们需要制定一个损失函数并设法将其值减小以使得机器学习的拟合度更高,则相对熵较好匹配了这个要求。相对熵越小,则说明我们猜测的概率Q越接近真实概率P。
从相对熵的公式可以看出,若要最小化相对熵,由于真实熵是一个常数(设为M),根据吉布斯不等式可知,KL散度一定是大于0的,所以只用减小猜测的熵值即可,则将真实熵移到等号左侧。剩下的就是我们猜测的Q所产生的熵又被称作交叉熵,这和直接使用相对熵是等价的
吉布斯不等式
来源:https://blog.csdn.net/m0_37805255/article/details/95587461
使用numpy实现梯度计算
pytorch官方示例程序,使用numpy实现梯度计算
https://pytorch.org/tutorials/beginner/pytorch_with_examples.html
修改docker中wordpress文件上传大小限制
默认情况下,只能向媒体库中上传2M大小的文件,该限制是php的限制而非wordpress。
解决方法:
进入docker容器
docker exec -it 6bab bash其中 6bab 是 docker container id
找到php安装路径
whereis php
进入到其安装目录
cd /usr/local/etc/php ls
默认情况下是没有
php.ini文件的,需要创建一个。直接复制一个php.ini-production重命名为php.ini即可。编辑
php.ini文件,默认情况下docker容器中没有安装vim,可以选择安装或者将文件拷贝出来修改后再拷贝回去。演示后一种方法将
php.ini复制到宿主机docker cp 6bab:/usr/local/etc/php/ php.ini修改该文件中的这几个配置:
upload_max_filesize = 512M #文件大小限制 post_max_size = 512M #post大小限制 memory_limit = 256M #内存占用限制再将该文件复制回docker容器
docker cp php.ini 6bab:/usr/local/etc/php/重启容器即可
docker restart 6bab图像的Hu矩
我们希望能用很少的几个特征代表一个图形,这些特征不因图形在图像中所在的位置、旋转角度、缩放比例的改变而改变,也不应受光照、噪点等影响。经过计算机视觉多年的发展,已经发现了很多这样的特征,
不变矩就是其中一个。统计学中的矩
图像的几何矩
将图像的像素坐标看作是二维随机变量,像素的灰度值看作是概率,就可以套用统计学中的矩作为图像的几何矩。
原点矩:( M_{ij}=\sum_x \sum_y x^iy^jI(x,y)\ )
中心矩:( \mu_{ij}=\sum_x \sum_y (x-\hat x)^i(y-\hat y)^jI(x,y) \text ,其中(\hat x, \hat y)为图形的质心(重心)\ )
- 零阶矩 ( M_{00}=\sum_x \sum_y I(x, y) \text {,其中I(x,y)表示在(x,y)处的像素灰度值}\ ) 零阶矩计算的是所有像素灰度的总和,类比统计学中的概率总和
- 一阶矩 \( \\begin{cases} M\_{10}=\\sum\_x \\sum\_y xI(x, y) \\\\ M{01}=\\sum\_x \\sum\_y yI(x, y) \\end{cases}\\) 一阶矩计算出图像横纵坐标的加权和,权值即为该坐标像素。若想将权值归一化到(0,1)的区间,则可以将每个像素灰度值除以灰度总和,这样一阶矩就类似统计学中的数学期望了,该期望值是横纵坐标轴的加权平均值。该坐标点即为图形的质心(重心)坐标: \(\begin{cases} xc=M{10} / M_{00} \\ yc=M{01} / M_{00} \end{cases}\ )
- 二阶矩 ( \begin{cases} M_{20}=\sum_x \sum_y x^2I(x, y) \\ M{02}=\sum_x \sum_y y^2I(x, y) \\ M11=\sum_x \sum_y xyI(x,y) \end{cases}\ ) 类比上述统计学中的k阶原点矩
- 二阶中心矩 ( \begin{cases} \mu_{20}=\sum_x \sum_y (x-xc)^2I(x, y) \\ \mu{02}=\sum_x \sum_y (y-y_c)^2I(x, y) \end{cases}\ ) 即方差
Hu矩
中心距仅保证了平移不变性,若想要保证缩放不变性,则对中心矩归一化:
手机刷机相关知识
recovery/bootloader/fastboot关系
recovery和android一样,是手机上的两个独立系统(理解为电脑装了双系统)。手机启动时是可以选择启动哪一个的,默认是android
类比于电脑的PE系统,可以对android系统进行刷机、升级、备份等操作
例如,你可以提前在手机上下载好新的android系统,通过进入recovery模式安装该新系统,即卡刷
因为Google官方的recovery系统不好用,所以有人开发出第三方的twrp recovery
bootloader是连接系统和硬件的桥梁,类似bios,主板上电之后,首先bl会启动先初始化硬件并做映射,然后才会启动系统。相当于android或recovery的爸爸
现在的很多手机为了防止刷其他的系统,就会在bootloader上加锁,所以刷系统前需要解锁bootloader。
fastboot可以理解为手机的一个运行模式或一个接口,通过它你就可以直接向bootloader发出指令,例如,当你的手机运行于fastboot模式下,将手机连接电脑,并在电脑上下载android或者recovery的镜像,然后通过命令让bl安装该镜像,即线刷
OTA:空中升级,即直接通过无线网下载镜像进行升级,而不用线刷或卡刷
OEM:bootloader的开关,只有打开这个开关才能解锁bootloader
bootloader/BIOS/UEFI/Legacy
计算机的硬件千差万别,甚至于你可以自己动手组装一部手机或者一台电脑。为了让操作系统能够兼容各种机器,操作系统只能使用虚拟硬件(类似于java内存模型)。在x86架构中,这种用于抽象出虚拟硬件的东西叫做BIOS,在arm架构中就叫做bootloader。
UEFI和Legacy就是两种不同的BIOS(都是指x86下的),可以说,UEFI是新一代的BIOS,传统BIOS统称Legacy。事实上,UEFI只是一个规范,具体的实现得看厂商(类似于jvm规范)。
可以简单理解为:Legacy需要根据不同的硬件进行汇编开发,而UEFI则使用统一的c语言接口,通用性更强。类比于在原生操作系统上开发和在java虚拟机上做开发的区别。
更直观的来看就是:Legacy相当于直接在硬件上烧录一个程序,这个程序的功能就是加载一个系统。而UEFI(说的是UEFI的具体实现)则可以直接看作一个系统,它可以运行各种程序或驱动,甚至可以安装文本编辑器,浏览器等,而操作系统就是安装在其里面的一个程序
现在很多基于arm的手机或者平板都开始支持UEFI(但仍然叫bootloader),使得能在上面安装windows、Ubuntu等电脑操作系统
刷机步骤:
注:这是以前的方法,如果过程中提示 recovery_ab 找不到partition 之类的错误,应该是手机使用了 boot_a/b 逻辑分区的方式,这种情况的刷机方式在本文下面有写
下载小米官方解锁工具解锁,手机关机后按住音量下加电源键进入fastboot模式。此时可能解锁工具提示找不到设备,有可能是usb口的问题,换个插口试试
解锁后会清空设备并重启
将下载好的系统镜像解压缩,并将 .img 文件传输到手机
电脑上下载 platform-tool工具(ADB工具)压缩包,解压缩,cmd进入该目录
进入fastboot模式:
cmd输入
./fastboot devices命令查看是否已经进入fastboot模式
./fastboot flash boot XXXXX_XXXXX.img刷入系统镜像Fastboot flash boot xxx.img是刷入主系统镜像,若要刷入recovery(例如twrp)则使用 fastboot flash recovery xxx.img,若什么镜像都不想安装,则直接使用 fastboot boot xxx.img命令
提示完成后输入
./fastboot reboot重启手机刷magisk:
magisk通过修改替换boot.img文件的形式获取root权限。
什么是boot.img?
通过解压miui的卡刷包可以看到里面有各种各样的xxx.img,其中boot.img即为android内核文件,一般来说,不管你是什么系统,只要是基于android的,并且android版本一样,那么这个boot.img就可以互换,不管是miui还是其他什么ui,指的就是该内核的ui
下载官方卡刷包(需和手机现在系统的版本一致,实在没有android大版本一直应该也可以),解压,提取payload.bin文件(如果解压后就有boot.img则省略下一步)
下载payloadbin提取软件,可以提取其中的各种 xxx.img
复制上一步提取的boot.img到手机,并使用手机上的magisk manage软件修改boot.img,形成一个新的 Magisk_xxx.img
将上一步的magisk_xxx.img复制回电脑,手机连接电脑并进入fastboot模式,执行fastboot flash boot Magisk_xxx.img即可刷入修改后的内核镜像,(可选,因为貌似不这样做也没问题:可以同时也将提取出来的vbmeta.img也复制到adb工具目录下,刷入bootimg时也将该img文件刷入。刷入完成后执行 ‘fastboot.exe –disable-verity –disable-verification flash vbmeta vbmeta.img’命令关闭AVB校验,avb校验img文件的完整性),接着重启手机即可
逐步理解RNN
量化指标
MA均线
n天内的平均股价,周期越短的均线对单次股价波动越敏感
EMA均线
是在MA均线的基础上对时间加权,使得它对最近的价格波动更为敏感
MACD
分为三大要素:DIF、DEA、红绿柱
因为EMA本质也是一种均线,所以可以理解为当前的股价是否大于平时的股价,若DIF大于0,则表明最近股价大于以前股价。
但是,同样,因为EMA本质是均线,也可能出现股价在上涨,但是DIF却在下跌的情况,若短期内股票上涨的增量较小,而12天前有较大的跌幅,涨幅不足以抵消跌幅,则EMA(12)反而会减小,从而导致DIF的减小
- 即:DEA是DIF的9日均线,前面说DIF描述的是短期股价与长期股价的背离情况,则DEA就是平均背离情况。即若 DIF>DEA 则说明当前股票行情比平时更好(涨的时候涨的多,跌的时候跌的少),反之亦然
- 红柱为正,绿柱为负。前面说了,若 DIF>DEA 即 DIF-DEA 大于0,即红柱,则当前行情好于平时行情。柱子高度也体现出上涨或下跌的力度
RSI
当前股市是在买方市场还是卖方市场。例如:有100个人在进行交易,若此时大部分人都在买,则股价上涨。而若大部分人都要卖,则股价下跌
- 若将n天平均上涨点数(An)理解为100个人当中要买股票的人数,n天平均下跌点数(Dn)为100个人中要卖股票的人数,则该式可理解为:100个人中,有多少人是想买股票的。即:若该值大于50,则说明股价为卖方市场,股价正在上涨,过大则可能处于超买状态。
MOMENTUM(MOM)
股价动量,计算方式较为简单,使用上一个收盘价减去其n天前的收盘价
- 该指标反应了当前股价涨跌的速度,例如,在一个匀速上涨的股价中,其任意n天时间段的增量差值应该为0,类比加速度:(V - Vt)/t 即(C - Cn)/n
KDJ
- kdj一般用于判断超买超卖,计算kdj的前提是计算n日的RSV,C、L、H分别表示第n日收盘价、前n日最低价及最高价,该式表示的是当日收盘价在前n日最高价和最低价区间中所处的位置
- 可以理解为前n日RSV均值,即平均价格,类比MACD中的EMA
- 理解为前n日K的均值,类比MACD中的DEA,因为是K的均值,所以K更容易受短期价格影响
- 放大RSV波动,价格变动时波动最大
霍夫变换-线圆检测
假设笛卡尔坐标系中有n个点,每个点坐标为 ( (x_i, y_i)\ ),且这些点大致拟合成一条直线,问:如何找到这条直线?
霍夫空间
对于每个点 \( (x\_i, y\_i)\\) 都有无数条直线 \(y_i=kx_i+b\) 过该点。由k和b唯一确定该条直线,若将 \((k,b)\ ) 看作一个坐标,则该坐标点即为霍夫空间下的坐标。霍夫空间可以看作是原函数的
参数空间。同理,对于过某一点的圆的方程 \( (x\_i-a)^2+(y\_i-b)^2=r^2\\) 其参数构成的点 \((a,b,r)\ ) 就是霍夫空间下的坐标。
有时,为了便于计算,会将笛卡尔坐标系转换为极坐标系进而得到极坐标系下的参数空间。
直线检测
在霍夫空间中 \( (k,b)\\) 方程可以表示为 \(b=-x_ik+y_i\) 也是一条直线。将所有n个点代入即可得到霍夫空间中的n条直线,若其中有m条直线相交于一点 \((k_m, b_m)\ ),对于这m条霍夫空间下的直线所对应的笛卡尔坐标下的m个点来说,它们有共同的k和b,即它们在同一条直线上,即检测出一条直线。对霍夫空间中所有直线的交点进行遍历就检测出所有的直线。进一步可以使用一些淘汰算法进行筛选及合并,减少多余的直线
圆检测
同直线检测,只不过将二维坐标系转换为三维。对于任意a、b,总能找到一个r,使得这三个参数构成的圆的方程过点 \( (x\_i,y\_i)\\)。\((a,b,r)\ ) 在霍夫空间中的图形如下:
三个锥面相交即确定一个参数坐标点,进而得出经过这三点的圆的方程。
对 HoughCircles 方法中参数dp的理解
该参数可以理解为拟合精度,或者去除多余圆的程度。
简单理解为将霍夫空间的一个面(或一个空间等)划分为多个小格子,处于同一个格子的点视为一个点。dp即为每个小格子的宽度。dp=1 代表每个小格子仅代表一像素,即不进行合并。
例如,在霍夫空间下,有3个锥形,其中两个相交,第三个并没有过这个相交线,但该线与第三个锥面的最近距离小于2。此时,如果设置 dp=1 就检测不出圆形,因为并没有相交点。但如果设置 dp=2 则意味着所有小于2的距离将视为同一个点,此时就能检测出一个圆。
图像傅里叶变换
一维函数 f(x) 的傅里叶变换:
任何周期函数都可以通过多个正弦波的叠加表示
图像(二维函数)的傅里叶变换有两种理解方式:
- 任何图像 f(x,y) 也都可以由无数个正弦波平面叠加而成,他们具有不同的 频率、相位、振幅、方向 四个属性
- 对图像的每一行每一列做一维傅里叶变换
图像的傅里叶图谱:
- 可以根据傅里叶图谱还原图像
- 傅里叶图谱只能表示频率、方向、振幅三个属性。图谱中的每个点相对于中心点的位置就对应正弦波平面的方向,每个点的灰度值代表的就是振幅。为什么没有相位信息也能还原?
- 傅里叶函数具有中心对称性,所以傅里叶图谱左上和右下、右上和左下的图像是中心对称的
- 傅里叶图谱中每个点代表的是一个正弦波平面的函数,即一个M_N的图片可以转换为M_N个正弦函数叠加
- 傅里叶图谱中每个点所代表的正弦波频率从左到右增大,但由于中心对称性的缘故,图谱中越靠近中心点所代表的频率越高,边缘代表的频率较低。为了方便观看,一般通过 ffshift() 函数将频率低的点和频率高的点调换位置,即傅里叶图谱中越靠近中间的点的频率越低
- 可以将正弦波频率理解为图像梯度,频率越高,图像的变化越剧烈。所以高频往往代表了图像中的噪音和边缘
参考:
https://zhuanlan.zhihu.com/p/99605178?utm_source=qq
https://blog.csdn.net/weixin_46233323/article/details/105355133
https://www.zhihu.com/question/355013340
https://homepages.inf.ed.ac.uk/rbf/HIPR2/fourier.htm
P2P原理
关键字
stun协议\P2P\UDP打洞\NAT
常用方法
中继
使用中继服务器连接两台内网设备,受限于中继节点性能。
逆向连接
当客户端A、B之一有公网地址时可以使用该方法。
UDP打洞
最常见的方法
利用锥形NAT(下文将介绍NAT分类)会将 内网ip+端口 绑定一个 外网ip+端口 的特性实现。理论上来说,利用该特性就可以实现任意主机间的通信,但往往NAT会做很多限制,导致这种直接通信无法完成。下面以限制最多的
Restricted-Port NAT为例说明:网络拓扑图
Client A和B仅具有内网地址,有Restricted-Port NAT功能的router A和B将他们的内网地址及端口和外网地址及端口进行绑定,Server S具有外网地址。
限制前提
Restricted-Port NAT 会直接丢弃其他主机
主动发送过来的报文,只有它向另一台主机发送一个报文后,它才会接收该主机发送过来的一个报文。所以即使A和B映射了公网地址也不能直接通信。打洞过程
- Client A和B分别向S发送一条报文,S会记录下A和B的出口地址及端口(即:1.1.1.1:7777和2.2.2.2:8888)
- S分别向A和B返回对方的出口地址及端口
- A和B分别向对方的出口地址发送一个报文,由于Restricted-Port NAT的限制,该报文均会被丢弃。但同时,由于都向对方发送了报文,后面就能接收对方发送的报文。此时A和B就可以P2P通信了
NAT分类
基础NAT
只有主机本身就具有公网IP的情况下才能使用,此时基础NAT中会记录一张内网ip和公网ip的映射表
内网地址 外网地址 192.168.1.111 1.1.1.1 192.168.1.222 2.2.2.2 192.168.1.333 3.3.3.3 NAPT
允许多个内网主机公用一个公网IP,通过端口区分,此时NAT中会记录如下映射(有时间限制,超时删除)
内网地址 外网地址 192.168.1.111:1111 1.1.1.1:1111 192.168.1.222:1111 1.1.1.1:2222 192.168.1.333:5555 1.1.1.1:3333 完全锥型
内网地址+端口 和 外网地址+端口 一一绑定,不因访问资源地址变化而变化
出口地址可自由接收 任意外部主机的任意端口 发送来的报文
受限锥型
内网地址+端口 和 外网地址+端口 一一绑定,不因访问资源地址变化而变化
损失函数中正则项的作用
防止过拟合
深度学习模型实际上是在拟合一个函数 f(x1, x2, x3…),可以想象,特征x的系数越小,函数整体就越平滑,即模型对特征x越不敏感,这就是防止过拟合的基本原理。
已知损失函数f(x),求在使得w越小的条件下,f(x)的极小值,这就是约束条件下的极值问题,可以使用拉格朗日乘子法。
要使w小,即让其接近0,则可以设g(w)=|w|→0(L1正则) 或者 g(w)=w^2→0(L2正则),则求f(x)在约束条件g(w)下的极值就是求 ( f(x) + λg(w) \ ) 的极值。
上面说的就是L1正则和L2正则的基本思想,但实际上它们的效果还是有些不一样的。其实还有L0正则,它就是直接统计权重矩阵中0的个数,然后让0尽量多。
事实上,模型中常用的dropout也是正则化的一种,它等价于L2正则
防止梯度爆炸
梯度爆炸的根本原因还是梯度太大了,然后一层一层累积,梯度大就会引起权重大,而正则项可以让权重减小,从而减缓梯度爆炸的问题。
L1正则
L1正则侧重于让某些权重w变为0,这样相当于减少多项式的项数。也就是让模型只关注那些重要的特征
为什么L1正则让权重矩阵更稀疏?
所谓稀疏矩阵就是矩阵中有很多元素都是0的矩阵,也就是让一些w变为0,也就是在w取0时,损失函数取得极小值,怎么做呢?
加上L1正则后的损失函数为 ( f(x) + λ|w| \ ) (这里只是针对w矩阵中的一个w),其在w=0的左边导数为 f’(x)-λ,右边导数为 f’(x)+λ,故,如果λ比f’(x)大,就能让它在w=0处左右导数一个为正一个为负,即取得极小值。这样一来,就让这个w取为0了。不难看出,λ越大,权重矩阵中的0就越多,矩阵就越稀疏。
L2正则
L2正则更侧重于让所有的权重更小,即让整个激活函数更平滑,相当于权力的稀释。它的基本原理就是让权重在每一次迭代中都乘以一个小于1的数,然后再做梯度更新,以下为解释:
参考
https://blog.csdn.net/jinping_shi/article/details/52433975
https://www.zhihu.com/question/37096933/answer/70426653
https://zhuanlan.zhihu.com/p/306672638
https://www.zhihu.com/question/20700829
模型怎么知道哪些特征是重要的?
一个模型的输入可能很大,每个数都可以看作是一个特征,那么神经网络在训练时怎么知道哪些特征重要哪些不重要呢?
这就好比是我为了考试而复习,我怎么知道哪些知识点重要哪些不重要呢?
事实上也很简单,考试前我确实不知道哪些重要(forward),但考试后我一定是知道的(backward)。第一次考试前我啥都不知道,所以第一次考试时我就记录下考察的知识点,下来就专门针对这些知识点进行学习,第二次考试时我也记录下考察的知识点,然后针对性复习。经过多次考试后,由于每次我都会针对上次考察的知识点进行复习,那么那些常考的知识点我就可以掌握得很牢,但每次考试中都可能出现一些冷门的考点,这些考点由于之前出现得少甚至没出现过,所以我没怎么复习过,也就是总有一些题是不会做的。每次考试后我的分数都会提高一点点(常考的知识点复习次数变多,冷门知识点涉及广度更广),最终会稳定在一个成绩区间(总有些冷门考点)
神经网络也是一样,比如一个最简单的线性模型 y = k1x1 + k2x2,它的输入是一个数组,例如(x1 = -3,x2 = 5),里面有正有负,它在第一次forward也是随机初始化参数(第一次考试瞎填,即k1和k2是两个随机数),假如我们的目标是最大化y(提升考试成绩,深度神经网络一般最小化loss,原理一样),那么很明显,我应该在第一次更新权重时增加正数前面的k,而减小负数前面的k(这个例子中增加k2,减小k1)。如此一来,下一次迭代时y就会大一点点,经过不断迭代,这里的y就能不停增大。实际上深度学习模型远比这个复杂,且一般都不是线性网络,所以y不一定能无限增大(或减小)。
那么思考一个问题,假如上面的x1或x2等于0怎么办?很显然,如果x等于0,那么它前面的k是不会更新的。也可以说k的梯度为0,对于多层的深度学习模型来说,如果中间层输出为0,意味着下一层的输入为0,进而可能导致下一层模型的梯度为0,由于链式求导原则,其前面所i有的模型梯度都会为0,其前面的模型在这一轮迭代中就不会更新了。进一步的,如果每一层都输出一个很小的值(远小于0),梯度叠乘的情况下,很容易引发梯度消失,反之如果每层输出一个较大的数(大于1),则又很容易引发梯度爆炸。
所以,为了缓解梯度消失或梯度爆炸,可以在中间各层网络输出加上normalize层,让这个输出不会太大也不会太小。
前面说,深度学习模型一般不会是线性网络,这就是通过激活函数体现的,激活函数一般都是一个非线性函数(模型本质上就是一个函数),例如sigmoid函数,当x很小时它的值趋近于0,当x很大时,它的值趋近于1,其实想一想,它其实就实现了计算机语言中的if else功能,如此一想,一个深度神经网络是不是就是一颗决策树了,它不停地判断if else。
什么是容器
之前一直把容器理解成虚拟机,容器内的用户是独立的,与宿主机无关的,容器内的进程也是完全和宿主机隔离的。今天才知道这基本上是错误的,这是被vmware这类虚拟机形成思维定势了。
使用vmware创建一个虚拟机就好像在现实世界中,使用计算机完全模拟出来一个虚拟世界,这个虚拟世界的环境和真实世界一模一样,只不过它是用计算机模拟的。这个虚拟世界中出现任何问题都不会对现实世界造成影响,虚拟世界的人口膨胀到人挤人了,现实世界该咋样还咋样。
但是容器不同,容器使用的是命名空间的技术,就是贴标签,所有的人都是真实存在的,他们共享同一片土地。但是给他们穿上了不同的衣服,红色衣服的人只能看到穿红色衣服的人,绿色的只能看到绿色衣服的人,总之就是只能看到同标签的人。那么,如果哪天穿红色衣服的人发生了人口膨胀,那势必穿绿色衣服人的生存空间也会受到影响——即使他们互相看不到对方。
这就意味着,你在容器中运行一个MySQL进程,实际上在宿主机是真的有一个MySQL进程在运行的
可以这样理解,当你创建一个容器后,它会先创建一堆文件,例如/usr、/opt等等,这些文件也是真的在宿主机存在的,只不过它们会分配一个命名空间(标签),例如实际创建的/usr目录可能是 xxx:/usr,而所有带有xxx的文件或者进程,也都只能看到带有xxx的文件或进程。
但是从宿主机的角度来看,不管带有什么标签,一个进程就是一个进程,文件就是文件。这就是为什么明明是在虚拟机中运行的MySQL,却能在宿主机上通过top看到(可能pid显示不同)。也就是说,如果你在容器中启动了两个进程,你在宿主机中kill掉其中一个,那另一个进程仍然是在容器中正常运行的。
另一个非常重要的概念就是用户映射了,既然容器中的进程和文件都是实实在在在宿主机上的,那么如果我在容器中创建了一个文件或者启动一个进程,那这个文件或进程是属于哪个用户的呢?
实际上容器中的用户和宿主机的某个用户本质上是同一个用户,它们之间通过用户映射关系进行绑定。例如在宿主机下我有一个用户hunt,当我用该用户创建了一个容器时,容器运行时(docker、containerd等)会在容器中创建创建一个用户(比如root),并将root映射到宿主机上的hunt,它们其实本质上就是同一个用户在不同的命名空间下的映射,不同命名空间下拥有的权限也不同。所以此时我在容器中以root身份启动了一个MySQL服务,而在宿主机中看到的其实是hunt启动的一个MySQL服务。那如果我手动在容器中创建一个用户,然后用这个用户启动一个进程,宿主机看到的是什么呢?这就得看容器运行时的具体实现了,可能使用启动容器运行时的账户,可能使用一个匿名账户等等。
获取linux实时网速
linux中的/proc是一个虚拟目录,里面都是系统在运行过程中的各种状态,例如内存使用情况,网络情况,各个进程的运行情况等等。它是一个虚拟目录,只有在系统运行起来后才有而且仅存在于内存中。有点类似于MySQL的视图。
查看当前内存的使用情况:
查看网络的使用情况:
由此可知,如果想要计算当前的网络流速,则只需要在间隔1秒前后分别得到bytes列的数据,然后相减即可。以下为一个shell脚本:
#!/bin/bashwhile truedo init_state=$(cat /proc/net/dev | grep wlp2s0) sleep 1 end_state=$(cat /proc/net/dev | grep wlp2s0) rx1=$(echo $init_state | awk '{print $2}') rx2=$(echo $end_state | awk '{print $2}') rx_speed=$(((rx2 - rx1) / 1024)) tx1=$(echo $init_state | awk '{print $10}') tx2=$(echo $end_state | awk '{print $10}') tx_speed=$(((tx2 - tx1) / 1024)) #printf "RX: $rx_speed kbps, tx: $tx_speed kbps\r" # 打印很长的空行是为了覆盖掉前面一次的打印结果。否则如果前一次打印出很长的东西,下一次又没那么长,则下一次打印的后面会有上一次打印更长的部分 # \r控制光标返回行首,echo命令会自动在文本后面加上\n换行,-n命令就是让它不加换行符,-e命令就是让它把\r之类的特殊符号作为控制符处理 echo -ne " \r" echo -ne "RX: $rx_speed kbps, tx: $tx_speed kbps\r"done然后使用
chmod +x test.sh再执行./test.sh即可transformer简单理解
transformer论文:https://arxiv.org/pdf/1706.03762.pdf
简述
transformer是一个encoder-decoder结构,也就是说,它需要先将所有的输入序列(例如一句话)都输入到encoder中,得到一个context向量,该向量包含了原始输入序列的全部信息并进行编码后的结果,然后再使用decoder将其解码成另一种信息,例如机器翻译就是将一门语言翻译成另一种语言。
在此之前,人们将rnn用在encoder-decoder中,也就是两个网络,第一个rnn网络将原始信息生成context,第二个rnn对context进行解码。但transformer则将编码器和解码器都替换成“自注意力网络”的堆叠(当然还有其他组成结构)
注意力机制
注意力机制可以让你一次关注到全局信息,它包含三个参数:q(query)、k(key)、v(value)。其中,q是你要查询的东西,k-v是一个键值对。你需要拿q去和多个k做相似的计算,再使用该相似度与其对应的v进行加权和。
例如对于一个由三个词组成的一句话“今天/天气/晴朗”,首先将每个词映射成一个k-v键值对,这一步一般由模型训练自己得到结果,然后再将每个词作为q去进行查询,例如当“晴朗”作为q时,它会发现三个词中,除了其本身与本身的相似度(q和k的相似度也是模型自己训练出来的)较高之外,它还与“天气”这个词的相似度也很高,而与“今天”的k的相似度就相对较低,那么可以认为“晴朗”这两个字是用来描述“天气”的。
transformer使用的注意力机制
transformer就是利用注意力机制对输入序列进行编码的,不同点在于:
transformer使用了自注意力机制(下图红色箭头),即qkv都是这个词向量本身,可以想到,对任何一个词来说,最相关的那个k一定也是它本身,但由于词向量本身就经过了模型训练的学习过程,故它也能和序列中的其他词向量计算出相似度
从横向来看,transformer的encoder和decoder都同时并行使用多个注意力机制来计算不同维度的相似度,就好比使用多个不同的卷积核提取图像不同的特征一样。这就是“多头注意力机制”,每个注意力模型得到的结果再使用MLP进行合并,组成一个新的输出向量
从纵向来看,transformer的encoder和decoder都使用多个layer进行堆叠,每个layer都是2中所述结构
注意到decoder的自注意力模型上加了个“masked”修饰,这是因为其处理的是时间序列的数据,例如,对于一句话来说,一般都是后出现的词会依赖之前的词,而不会反过来,故在生成第n个词时,可以将原语义中与该词相关的后面的词都给一个0权重,屏蔽掉。
注意力机制与RNN
本质上他们的功能是一样的,都是输入一个时间序列,输出另一个时间序列
只不过注意力机制更能顾全全局信息(毕竟是通过对全局信息加权和得到的),而RNN则对很久之前的word不敏感。这也是transformer选择注意力机制的原因
位置编码
注意力机制只有加权和,而没有时序信息,故还需要根据每个词出现的先后顺序进行位置编码(上图中的Positional encoding)。也就是根据顺序给每个词创建一个向量,然后和原输入词向量相加即可
注意力机制实现
主要是QKV三个向量,它们的维度如图
相同字母表示该维度相同,可以使用卷积或MLP先将不符合维度要求的QKV转换为符合要求的,attention计算过程为:
\[ result = (Q @ K^T) @ V \ ]
直观上,Q就是你要预测的序列,V就是潜在特征序列,K用来计算Q到每个V的分数
在NLP自注意力机制中,就是使用三个独立的MLP将同一个输入转换为QKV,其中,m为要处理的字符串长度,e为每个字符embeding的长度,L为整个字符串的长度(计算字符串中所有字符对其中某个字符的注意力分数),n可以设置为1。一般情况下 m = L
python classmethod staticmethod
有两点不同
1. class method 会自动将当前class作为参数传入,但我觉得这并不能让它和 static method 产生差异,因为你完全可以这样写:
class F(): @staticmethod def sm(cls): print(cls) @classmethod def cm(cls): print(cls)F.sm(S) # <class '__main__.F'>F.cm() # <class '__main__.F'>一般这里会说classmethod可以防止硬编码,我觉得比较牵强,因为你调用的时候实际上已经需要指定调用class了,这里无非是多传了一个参数,看起来不太优雅,不过也可以通过其他方式解决,这样一来,classmethod在某些场景下确实能一定程度使得代码更美观简洁
2. 继承的差别才是我觉得classmethod的优势所在
class F(): @staticmethod def sm(): print(F()) @classmethod def cm(cls): print(cls())class S(F): ...S.sm() # <__main__.F object at 0x00000290C6935120>S.cm() # <__main__.S object at 0x00000290C6935120>注意到,static method 创建的是父类对象,而class method 创建的是子类对象,所以classmethod的一个典型的应用场景就是创建当前类的对象
class MyClass: @classmethod def create_instance(cls, *args, **kwargs): # do some check before instance be created return cls(*args, **kwargs)如此一来,不管该类如何继承,都可以直接通过 XXX.create_instance() 来创建对应的对象
api VS spi
api 和 spi 的区别:api 就是别人写好一些函数,然后规定一个调用这些函数的声明集合,spi 简单理解就是回调函数的集合,例如在android或web等需要响应交互情况下,会有很多回调函数,例如 on_key_down() 用于监听键盘按下事件,on_mouse_move() 用于监听鼠标移动事件,这些函数都有一个特点,就是只会在特定的情况下自动触发执行,而不能直接运行。作为服务提供方,我就可以选择将这些回调函数封装成一个类,在适当的时候调用这些函数,消费方使用时,让开发人员实现这个类并传给我
简单概括就是:api是由服务消费方选择调用时机,spi由服务提供方选择调用时机另一种说法是api由服务提供方制定规范,而spi由服务消费方制定规范,我认为是不恰当的,反而我觉得两者都是服务提供方制定的规范,不同点仅在于谁决定服务的调用时机
python multiprocessing Pipe Queue
两者功能类似,甚至可以说是相同,都是用于多进程通信。两者可以认为是Hibernate和JPA的关系,即Queue可以看作是对Pipe的进一步封装
Pipe的基本形式为:
pipe1, pipe2 = multiprocessing.Pipe()task1(p1, p2): p1.send("bingo") # 进程1向pipe1发送一条数据task2(p1, p2): p2.recv() # 进程2接收pipe中的数据,如果没有数据则会阻塞multiprocessing.Process(target=task1, args=(pipe1, pipe2)).start()multiprocessing.Process(target=task2, args=(pipe1, pipe2)).start()上面代码为 Pipe 的默认用法,需要注意的是:
就像非对称加密中的公钥和私钥一样,使用公钥加密的数据必须用私钥才能解密,使用私钥加密的数据必须用公钥解密
这里也一样,pipe1 和 pipe2 互为一对,任意一个用来发送数据,就必须用另一个才能接收。
另外,你可以向pipe中send多个数据,但每次调用recv时只会获取一条数据
与Pipe类似的还有 Queue,不同点在于它只是一个实例
queue = multiprocessing.Queue()事实上,可以认为Queue是对Pipe的封装,这种封装带来了两个好处:1)全双工通信,即一个Queue对象既可以发,也可以收。2)实际上Pipe是有send 限制的,即如果一直send数据但不recv,当占用一定大小内存后,send也会发生阻塞,而Queue就不会。但是,当设置
Pipe(duplex=True)时,得到的两个pipe就都是全双工通信的了,相当于得到了两个Queue但也正因为如此,Queue的效率往往更低
另一个不同在于:从设计思想上,Pipe应该被用于两个进程间通信,而Queue则可以应用于多进程间通信。但从实际使用上看,即使将Pipe用于多进程间通信也是没问题的。
参考:https://superfastpython.com/multiprocessing-pipe-in-python
matplotlib.pyplot 一些基本概念
默认的figure和axes
首先明确概念,figure可以看作整个窗口,而axes只是其中的一个chart组件,figure中除了axes外,还有标题、按钮等组件
如果直接使用
plt.plot([1,2,3]),则会自动创建一个 figure,并且自动向该figure中添加一个 axes,画图就是在该axes中画plt.plot([1,2,3]) # 直接调用plt.plot()会先自动创建一个figure和axesplt.plot()会自动在最后一个激活的figure和最后一个激活的axes中画图,所以上述代码和下面的代码等价:
fig = plt.figure()plt.plot([1,2,3]) # 如果已经有figure,则会自动在最后一个figure中画图上面这个代码其实和下面这个代码是一样的:
fig = plt.figure()fig.gca().plot([1,2,3]) # figure.gca() 即获取当前的(最后一个) axes,如果没有则自动创建一个# 也等价于plt.gcf().gca().plot([1,2,3]) # plt.gcf() 即获取当前的(最后一个)figure同理也等价于下面代码:
fig, (ax1, ax2) = plt.subplots(1,2)ax2.plot([1,2,3]) # 是自动在最后一个figure中最后一个axes中画figure.canvas.draw()
需要注意的是,上述代码,不管是调用 plot() 还是调用 scatter() 等,并没有真正在axes上画图,它只是相当于一个蓝图,真正的渲染得靠
fig.canvas.draw()方法,在调用 plt.show() 时会自动调用该方法:fig, ax = plt.subplots()ax.plot([1,2,3])plt.show() # 内部会先自动调用 fig.canvas.draw() 方法plt.cla、plt.clf
plt.cla()方法用于clean最后一个axesfig, (ax1, ax2) = plt.subplots(1,2)ax1.plot([1,2])ax2.plot([2,1])plt.cla() # 只会清理最后一个axes(即ax2)plt.show()
同理,
plt.clf()则会将最后一个figure整个清理掉如果不清理多次调用 ax.plot() 会怎样呢?
如前文所说,ax.plot() 并非真正渲染,只是创建一个蓝图,则多次调用 ax.plot() 方法会在同一个ax中添加多个折线或散点等,最后调用 draw() 方法一起在同一个ax上渲染
x = [1,2,3]y1 = [4,2,6]y2 = [8,3,5]plt.plot(x, y1)plt.plot(x, y2)plt.show()
U盘应该用什么文件系统
概览
fat32:古老的windows文件系统,兼容性最好,最大单文件限制在4GB。支持windows/mac/linux,uefi也能识别并加载引导文件
exFat/fat64:微软专为闪存设计,支持大文件传输。支持windows/mac/linux。
ntfs:先进的windows文件系统,原本为机械盘设计,支持大文件。支持windows,mac默认只可读,linux需要安装相应驱动
ext4:linux下的文件系统
xfs:centos为服务器大文件系统设置
U盘应该格式化为哪种?
一般U盘默认为fat32,兼容性好,对U盘损耗低,但这样就不能传输大文件了,所以还是建议使用exFat格式
exFat容易丢失文件?
文件的写入是一个“事务”,它包含多个步骤(写入文件数据、修改matadata…)所以需要保证一致性。其他文件系统通过日志的方式可以解决该问题。但exFat没有日志系统,故当写入事务执行一部分时拔出U盘会造成数据丢失(数据可能已经写入了,但没有更新matadata,也还是读不出来,可以通过fsck命令修复,它会将找出来但没有记录的文件放到 /lost+found 文件夹下,由于该文件没有元信息,故需自行打开二进制文件查看文件的真实类别,windows下也有相应的修复工具)
所以,使用exFat格式的U盘需要先手动“弹出”,再拔出,最好不要直接拔(即使提示文件传输完成也有可能数据还在缓存中,没有刷入U盘)
总结
现在U盘我觉得还是不要用fat32了,毕竟现在文件动辄以G计,如果用这种格式有时候就很麻烦,比如我已经存放了一些东西,现在需要用这个U盘临时转移一个大文件,却发现拷贝不进去。
用exFat或者ntfs更好吧,但ntfs是为机械盘设计的,为了保证数据写入的一致性,会频繁记录日志,但闪存颗粒的读写次数是有限的,故会在一定程度上影响闪存寿命
还是建议使用exFat格式,兼容性更好。网上都说容易丢失数据,但我觉得和上面说ntfs影响U盘使用寿命一样,还是听风就是雨的人多一些,毕竟技术发展了这么多年,各大平台都支持的东西,用的人那么多的东西,怎么可能说出问题就出问题
python多继承的问题
__new__考虑以下代码的输出结果:
class A: print("AAAAA") def __init__(self): print("a init") ... def __new__(cls, *args, **kwargs): print("a new") return super(A, cls).__new__(cls) a = A()结果为:
__new__是object的一个静态方法,用于创建对象实例,__init__用于初始化对象。而上面的 “AAAAA” 则是在加载类的过程中就执行了多继承下的实例化过程
考虑以下代码输出:
class A: print("AAAAA") a_attr = "a" def __init__(self): print("a init") super(A, self).__init__() # 这里的super指的是谁? ... def __new__(cls, *args, **kwargs): print("a new") return super(A, cls).__new__(cls) class B: print("BBBBB") def __init__(self): print("b init") super(B, self).__init__() # 这里的super指的是谁? ... def __new__(cls, *args, **kwargs): print("b new") return super(B, cls).__new__(cls) def bm(self): print("bbb") class C(A, B): print('CCCCC') def __init__(self): print('c init') super(C, self).__init__() # 这里的super指的是谁? def __new__(cls, *args, **kwargs): print("c new") return super(C, cls).__new__(cls) ... c = C() print(C.mro())
forward和backward
深度学习的本质是,在已知变量x的情况下,求出 ( y = f(w|x) \ ) 的最优解,绝大部分情况下,都是求f(w|x)的极值。问题就在于,这里所说的极值,是针对哪个自变量的极值。因为前馈神经网络训练过程中分为两步:forward和backward,这两个步骤中的自变量是不一样的。在forward过程中,自变量是x,但在backward过程中,自变量变为了w和b。十几年的方程学习导致我们过拟合了,看到x就觉得它应该是自变量,而w则应该是固定不变的,这是理解该问题最大的障碍。
backward
举个例子,求 ( y=w*x\ ) 的极小值。我们当然知道该函数是一个无极值的函数
计算机不知道,它只能顺着曲线不断向下找,看能不能找到一个极值点,这就是SGD,随机梯度下降法。
我们知道SGD权重更新公式为:( w_{new} = w_{old} - μ\frac {\partial f(x)}{\partial w} \ ),它是怎么来的?表达了什么意思?
SGD是backward的一个过程,那么和上面那个图就不一样了
注意看,此时横轴自变量已经是w了,它和上面那个图本质上是两个图形,只不过因为函数的特殊性,导致长得相似而已。而我们真正要求的极值,实际上是这个函数的极值(即:x作为斜率固定不变,w作为自变量)。
SGD会尝试寻找该函数的极小值:每次将w减小一点,这样得到的y也就小一点,不断尝试,直到w到负无穷也是找不到极值点的。这就有两个问题:
SGD如何知道w是应该增大还是应该减小?
SGD如何知道每轮迭代下,w的变化量是多大?
解决这两个问题很简单,对第一个问题来说,若权重x为正,则应该减小w(如上图),反之则增加。而变化量你可以设定一个定值,更好的方式则是让其在每轮迭代过程中动态变化。而w在某个点上的导数则可以很好得解决这两个问题。
( \frac {\partial y} {\partial w} \ )正好等于x,而其值的绝对值大小也正好对应着斜率的大小——主观上来说,某点的斜率越大,则其离极值点的距离可能就越远。所以就有了SGD的权重更新公式
forward
写代码时,我总是担心对模型的输入x做处理会影响模型训练过程,实际上这种担心是完全多余的,因为单纯对x做函数映射处理对上述backward过程来说是完全透明的——模型的输入对该模型的backward过程来说,只是函数的一些参数,它在模型图建立起来之后就是固定不变的,我们要做的只是调整模型的参数即函数的自变量。
激活函数
但要注意的是上面说的只是单纯对模型输入做处理,像激活函数这种则不是,激活函数的输入本身就是一个模型的输出,也就是(x, w),这么一个元组。它就不止包含模型输入x了,同时还有模型参数w。故在backward链式求导过程中,就要求激活函数可导。
但对于leru这类激活函数来说,它本身在0点就不可导,这也就意味着当模型在backward到w=0时,会不知所措——我到底是该减小权重,还是该保持该权重不变?实际上,该点导数约定俗成就是0
总结
backward过程中,我们总是在针对某个特定的输入x,来不断调整w,是的函数因变量y不断逼近一个期望值。需要注意的是,我们每次都是针对这一个固定的x做调整,即在该输入x下,使得模型拟合的函数接近期望的函数。
应该能想到,每一个x都对应一个函数,我们的目的就是让这所有的函数都能在同一个w下近似拟合期望的函数。为什么可以这样,因为这些x都来自同一个已观测到的样本,他们本身就是服从同一个分布。它就类似于贝叶斯理论中的后验概率了。
例如对于函数 ( y=wx\ ),假设实际情况是,x只能为正值,而观测的x样本也都是正值,只不过它们的取值不同。则可画出以下backward图形
可见,虽然在某w下,对不同的输入x,对w的更新量不同,但总体方向都是一样的,都是负的,所以模型仍然会继续学习。当对不同输入x时,w出现了反复振荡,则模型可能找到了极值点
linux定时任务
linux下可以使用 crontab 创建定时任务
怎么用
如果是最小化安装的ubuntu可能没有该服务,可以使用
sudo apt install cron进行安装,安装后就可以使用cron或crontabcrontab的使用方式很简单,输入
crontab -e命令,就会弹出一个vim框,然后你就可以在里面输入 crontab 格式的指令,保存退出即可。# 每年 6 月 12 号 晚上 23 点 59 秒输出一个bingo 59 23 12 6 * echo "bingo"注:系统会定时执行后面的命令,且以创建者的身份执行
可以使用
crontab -l查看创建的定时任务另一种方式是直接将定时任务添加到
/etc/crontab文件,cron服务会每分钟读取一次该文件看看是否有需要执行的命令,只不过和上面的格式稍有不同,你需要添加一个执行命令的用户名# 注意,该命令会以hunt的身份执行,为什么可以指定执行的用户呢?因为修改该文件需要使用root权限 59 23 12 6 * hunt echo "bingo"语法
几分 几点 几号 几月 周几 执行什么任务从上面看并没有设置年份,所以你的任务最起码是以年为循环执行的
那如果我要设置两个时间,但它们只有一点不同,例如分别是 3 分钟 和 5 分钟的时候执行,那该怎么办呢?
有两种方法:
写两个定时任务
使用
,分隔符,例如3,5 * * * * tasklinux的用户和组
UID和GID
linux中每个用户都有一个UID和GID,且linux只认UID,用户名只是方便用户记忆而已,用户名和UID的关系有点像域名和ip的关系。
每个用户创建后默认会创建一个与用户名同名的组,并分配一个GID。
用户的UID和GID可以在
/etc/passwd文件中查看到:
需要注意的是,密码拦全部为 X,这是历史遗留,早期密码确实存在这里,但由于对密码安全性的要求以及密码本身添加了很多属性,所以将实际密码放到了
/etc/shadow注1:前面说,linux只认UID,也就是说,如果此时你将 /etc/passwd 中某用户的UID改掉时,他仍然可以通过用户名登录到系统(linux只认UID说的是文件,linux是一个以文件为基础的系统),但是他之前所有的文件,仍然是绑定到他之前那个UID上的,所以他无法再访问这些文件了
注2:可以看到,除了我们自己创建的用户外,还有很多其他的用户,这些用户都是系统自己用的,勿动
group的相关信息保存在
etc/group文件中
所以,要想让某个用户加入一个组,最简单的方法就是直接改 etc/group 这个文件,将该用户名添加到某个组第4列中
用户可以通过 groups 或 id 命令查看自己的组:
另:既然加入了一个组就能操作该组的文件,那么如果加入了多个组,我创建的文件是属于哪个组呢?
组也有默认组的概念,即通过groups命令得到的第一个组就是你创建文件所属的组。可以通过newgrp命令修改默认组
作用
需要注意的是,即使你将某个用户放到 adm 或 root 组下面,他仍然不能执行sudo命令,因为,所谓用户或组,指的只是对文件的 rwx 权限,只能说他现在可以操作 adm 或 root 组的文件,即文件权限符号的中间三个字符:
-rwxr-xr-x // 文件所有者权限,组成员权限,其他人权限忘记密码?
如果是普通用户忘记密码,可以让root用户通过 passwd 命令直接修改密码而不需要输入原来的密码
如果是root忘记密码,则也有解决办法,前文说到,密码都保存在 /etc/shadow 文件中,此时只需要想办法进入该文件并将密码清空即可。进入该文件的方法有:1)使用linux本身提供的恢复模式等。2)使用类似windows的PE系统的做法,将linux的系统盘挂载到其他系统下进行读取和修改内部文件
ACL
一个文件或文件夹只能设定针对ower、一个group和其他人的权限,假如我有一个文件,我希望有些人/组可以读写,而另一些人/组只能读,那该怎么办呢?
linux提供了一套更为精细化的权限管理系统ACL,它可以针对某文件或文件夹单独对某个用户/组设置权限,用法为:
setfacl -m d:u:user_name:rwx file(其中的 d 指递归权限,即用户进入该目录内部创建的文件或目录也具有该ACL权限)和getfacl file
sudo
前文说,用户组只是对文件访问权限的控制,而真正要想使用sudo需要专门对
/etc/sudoers文件进行修改
此时,zh这个用户就能使用sudo权限了
注1:要想使用户具有sudo权限,只需要修改这个文件即可,不需要将用户添加到特定的组
linux下目录的rwx权限
linux下的文件有rwx权限好理解,但目录的rwx权限如何理解呢?
你可以这样理解,目录也是一个文件,文件的内容就是目录中所有的文件名
当一个目录具有r权限时,你就可以ls该目录,查看该目录下有哪些文件,效果等同于cat查看一个文件的具体内容。
当一个目录具有w权限时,你就可以在该目录下创建新的文件或删除里面的文件
当一个目录具有x权限时,你就可以进入到该目录,这一点有些不好理解,当我具有r或w权限时,还不能进入目录吗?
不行的,见下方实验
甚至于此时,我就算有w权限,也无法新建或删除目录下的文件,这一点貌似有点疑惑,难道w权限必须配合x权限使用?
双系统应先安装windows再安装linux
MBR
MBR(Master Boot Record)是一种用于处理开机管理程序(bootloader)和分区表的一种方式,它规定磁盘的第一个扇区存放两个东西:bootloader和分区表
bootloader用于作为系统启动的引导程序,它会认识磁盘内的文件系统格式,因此可以读取系统的核心文件并执行。而分区表则用于指定磁盘分区如何划分的
MBR有很多缺点,例如第一个扇区损坏会导致磁盘无法读取(MBR没有备份),第一个扇区大小有效,导致分区表最多只能设置4个分区(可以通过其他方式设置子分区)等,GPT就是用于取代MBR的,由于磁盘的发展,一个扇区的大小可能不一样,为了统一,它规定了逻辑区块,称为LBA,一个LBA可以是一个或多个扇区的集合。
GPT使用磁盘的前34个LBA来记录分区信息(可以分更多的区),同时将磁盘最后33个LBA用于备份。bootloader同MBR一样,存储在LBA0区域,为了表述简单,下文中统一使用MBR代表磁盘一开始存放的bootloader的区域。
Bootloader
bootloader也是一段程序,它的主要作用是找到并执行系统的核心文件,但在此之前,它还可以:
多系统环境下提供一个启动选项,用户可以选择启动哪一个系统
如果用户选择了启动其他系统,则bootloader会去执行其他系统的bootloader
也就是说,每个系统在安装时都会安装一个bootloader,linux常用的bootloader是grub
但前文不是说bootloader安装在MBR吗?MBR不是只有一个吗?
MBR确实只有一个,bootloader却可以安装在每个分区的首个扇区。
BIOS
BIOS是一段固定在主板上的程序,是主机启动的第一个程序,用于硬件检查,并引导执行bootloader
BIOS比较老,它并不能识别GPT磁盘,UEFI是BIOS的升级版,使用C语言编写,提供比BIOS更强大的功能,有些UEFI提供非常好看的界面,它甚至可以提供网络连接,有些甚至自带有浏览器,使得你都不用进入系统就能上网。
所以你可以认为操作系统只不过是BIOS或UEFI的一个软件,而bootloader则是该软件的启动器
文件系统
MBR和GPT只是负责将一块物理磁盘分成多个逻辑分区,这一块由BIOS或者UEFI负责识别,而分区后还需要对分区格式化文件系统,例如windows的ntfs,U盘的fat32,centos的xfs,linux的ext4等,所以文件系统是操作系统负责识别的
windows和linux
首先要知道,将一个系统安装到一个分区上,它一定会将自己的bl安装到该分区的启动扇区(首个扇区)上,区别在于是否会覆盖磁盘的MBR区域
linux安装bl时,可以选择将bl仅安装到分区的启动扇区,或者选择同时安装到MBR区域
windows安装bl时,会强制安装到分区的首个扇区并覆盖MBR区域,主要还是windows的bl不支持多重引导(即它会直接启动windows而不会让你选择是否重定向到其他bl)
所以,如果先安装linux再安装windows,则windows会将MBR覆盖为windows的bl,启动时会直接进入windows
而先安装windows后再安装linux,就可以将linux的bl(一般是grub2)安装到MBR,而linux的bl支持选择启动bl,所以启动时它会有选项是否启动linux还是重定向到windows的bl(启动windows)
这个就是grub提供的启动选单
当然,即使是先装了linux也没关系,linux在安装时,你不仅可以选择安装linux,同时也提供一个troubleshoot的选项,这里面就有修复MBR的功能,所以你要做的就是重新进入linux安装界面,但选择troubleshoot选项
参考
《鸟哥的Linux私房菜-基础篇》第四版 P93
linux自动重试出错命令
例如国内使用默认channel安装pytorch比较困难,很容易网络连接超时,所以需要写一个脚本不断重试,记录一下刚写的一个简单脚本
#!/bin/bash while true;do python -m pip install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111 if [[ $? -eq 0 ]];then break fi done也可以不适用shell脚本,一行命令搞定
bash -c "while true; do command && break; done"对shell脚本的逐行批注:
#!/bin/bash用于指定执行的shell,否则将使用默认shell执行(sh、bash等),出现不可控的情况
while true;do有的时候会看到没有分号的写法,但do在下一行,两种写法都可以,这里的分号起断句的作用
python -m pip install也能看到直接写pip install的,区别在于用 python -m 执行的话会使用与python环境对应的pip,而直接使用pip install的话就使用的是环境变量中的pip,但有的时候和python环境还不是对应的
if [[ command ]];then也能看到只用单个中括号的[],一般来说两者都行,但单括号的兼容性更好,而双括号的只支持部分常用的shell,还要注意command两边的空格
$? -eq 0$用于获取变量,$? 可以获取上一条指令执行的结果,如果执行成功则返回0,否则为其他数值。-eq 就是 ==,其他的还有 -ne 表示 不等于,-gt 表示大于,-lt 表示小于等等python:global vs nonlocal
这两者都只有在修改外部作用域变量时才需要,如果只是读取就不用
首先需要区分python中的全局变量和局部变量
全局变量是在函数外定义的变量,即所有定义在
def中的变量都不是全局变量,即使是嵌套函数外层函数中定义的变量相反,定义在函数内部的变量即为局部变量,即使闭包嵌套再多层,也都是局部变量。
如果要在函数中 修改 全局变量(即将原本的引用指向一个新的引用地址,最下面有举例说明),则需要先用
global声明。count = 0 def increment(): global count # 修改全局变量前应先声明这里的count是全局变量,否则下一行语句会报错 count += 1 print(count) increment() # 输出1 increment() # 输出2如果想要在闭包中修改上层函数中的变量,则需要使用
nonlocal关键字先声明,它的作用和global类似,但是它只能关联嵌套函数中上层函数中的变量。def outer(): count = 0 def increment(): nonlocal count # 使用nonlocal声明这里的count是上层函数中的count count += 1 print(count) increment() # 输出1 increment() # 输出2 outer()注意:即使上层函数中没有引用的变量,但是上上层有,或者更上层有,也是可以的:
def outer(): count = 0 def inner(): def increment(): nonlocal count # 使用nonlocal声明这里的count是上上层函数中的count count += 1 print(count) increment() # 输出1 increment() # 输出2 inner() outer()但是nonlocal引用的变量必须是局部变量(定义在函数内部),如果将上述
count=0定义在最上层(outer()函数外面),则报错。tcp连接
连接状态
tcp本身就是长连接+全双工的,什么意思呢?就是tcp连接一旦建立,就会一直维持连接状态,这个状态下,服务端和客户端是可以同时发送和接收数据的。注意是同时,也就是说发送的同时也能接收,它们是两块独立的缓冲区。下面是python代码,服务端和客户端建立连接后,就启用两个线程,一个用于读数据,一个用于发数据。
# server.pyimport socket,timeimport threadinghost = '127.0.0.1'port = 12345def read(c): while True: data = c.recv(1024) print(f"server recv: {data.decode('utf-8')}")def write(c): while True: v = input() c.sendall(v.encode('utf-8'))s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)s.bind((host, port))s.listen()print("server start...")conn, addr = s.accept()print(f"client connect, {addr}")threading.Thread(target=read, args=(conn,)).start()threading.Thread(target=write, args=(conn,)).start()time.sleep(9999)conn.close()s.close()# client.pyimport socketimport threadingimport timehost = '127.0.0.1'port = 12345s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)s.connect((host, port))threading.Thread(target=read, args=(s,)).start() # 同server的read()方法threading.Thread(target=write, args=(s,)).start()time.sleep(9999)s.close()几个点需要注意:
1. 在连接没有断开之前(代码中的sleep(9999)作用就是阻止调用close()),两端可以任意发送和接收数据,发送多少次都可以,这也是目前长连接或者websocket的实现基础。
2. 默认情况下,recv()函数在连接建立的状态下是阻塞的,也就是说,如果对方没有向写recv缓冲区放数据的话,该方法会一直阻塞
3. 连接断开的情况下,recv()函数就会立刻返回空字符串。这里又有三点需要注意:
连接断开,指的是对方不管正常还是异常退出。
立即返回空字符串,即“”,而不是None
连接断开后,数据接收方的recv()是会一直接收一个空串的,此时已经不阻塞了,如果recv()在循环体内,则会一直循环
下图展示了客户端正常退出后,两者的tcp状态。tcp规定发起退出的一方会在最后进入CLOSE_WAIT状态,以等待该连接彻底失效。而此时,由于我上面的代码并没有判断正常退出的流程,所以理论上它们两者的状态会一直维持现状。
解释一下这两个状态产生的过程:客户端要关闭连接了,给服务端发送了一个关闭tcp连接的报文(FIN),此时客户端会进入FIN_WAIT1状态等待服务端确认,服务端收到报文后会自动回复一个ACK,此时服务端进入CLOSE_WAIT状态,而客户端收到该ACK后就进入FIN_WAIT2状态,这两个状态是相辅相成的,其本质是等待服务端将剩下的数据传输完成,注意这些步骤都是tcp完成的,而不是我们代码实现。实际上tcp并不可能知道到底什么时候服务端会将数据传输完成,所以它会一直等待业务逻辑代码执行完,直到调用close()方法,而我上述代码中,它会sleep很久,所以这个状态会一直保持。理论上tcp协议会将这个状态保持到系统关机,实际上系统也会设定一个超时时间。
所以正常情况下,当调用recv()返回空字符串时,你就应该意识到对方已经关闭了,所以你这边也应该调用close()方法了。
那么如果我就是给对方发送了一个空字符串呢?这是不被允许的,空字符串是发不出去的,必须有内容。
当然,也可以设置recv()不阻塞,
s.setblocking(False),这种情况下,无论如何recv()都会立即返回,但是如果没有数据的话,就会报异常“BlockingIOError: [ Errno 11 ] Resource temporarily unavailable”。此时可以使用try对其封装,或者使用select模块,这就是非阻塞io或NIO的实现方式了。kubernetes 基本使用
当容器较少的时候,可以使用docker进行手动管理,但是如果容器很多,每个容器为了容灾还有很多副本以集群方式运行,并且各个容器集群之间有错综复杂的通信连接,那么此时就能使用k8s进行管理了。
它可以根据你的配置,自动维护集群和系统的稳定,例如当集群中的一个容器副本下线后,它会根据配置立即重新创建一个容器顶上。它可以将一个集群统一暴露成一个ip,再由内部的负载均衡算法进行流量调度,可以认为,springcloud的那些核心功能它都有,但springcloud仅适用于java
安装
minikube
注:我用这种方式安装总是出现各种各样的问题,所以使用的是k3s,下面记录的是安装和使用minikube时遇到的一些问题:
https://minikube.sigs.k8s.io/docs/start
执行
minikube start失败sudo minikube start --image-mirror-country='cn' --registry-mirror=https://registry.docker-cn.com --forceminikube start会下载k8s,其中,–image-mirror-country=‘cn’表示使用国内镜像下载,–force 表示强制使用有root权限的docker(k8s不建议docker使用root运行)
如果sudo执行命令遇到
permission denied这类问题,可以尝试使用下面命令解决:sudo rm -rf /tmp/minikube_* /tmp/juju-mk*文档上说设置别名
kubectl='minikube kubectl --',但这样一来,sudo kubectl是用不了的,因为使用sudo执行命令会重新创建一个只有root环境变量的shell执行命令,所以当前shell下的环境变量和别名用不了,可以通过下面的方式解决:# 将sudo设置为别名,注意后面多了一个空格。官方解释是当别名后面是空格时,它会继续检查下一个字符是否也是别名alias sudo='sudo '# 如此一来 sudo kubectl xxx 就能使用了另一种方式是执行
sudo -i(登录式交互shell,会执行 /etc/profile)或sudo -s(非登录式交互shell),它会以root身份开启一个交互式shell,进去后再执行source .bashrc,即可将当前用户的环境变量复制过来。k3s
去掉了k8s中的一些不常用和过时的功能,保留最核心的功能,并且可以单机部署
https://docs.rancher.cn/docs/k3s/installation/install-options/_index
国内的话使用下面的命令安装更快
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn sh -安装完就能直接使用了,可以使用
systemctl stop/start k3s进行关闭和开启k3s服务。需要注意的是,这只是能停止k3s服务,但k3s管理的那些容器等仍然是在运行的,官方提供了完全停止的脚本:bash /usr/local/bin/k3s-killall.sh# 卸载脚本bash /usr/local/bin/k3s-uninstall.sh基本概念
node: 表示一台主机,可以是物理机或虚拟机
git rebase VS merge
代码从commit init处分为了两个分支,branch1和branch2,它们上面分别有各自的commit,c1、c2 和 c3、c4
此时切换到 branch1 处,并执行
git rebase branch2就会这样:
大概就是:将要rebase分支上的提交作为当前分支的基,然后将当前分支上的提交都生成一个新的提交建立在新的基上。所以rebase被称为 变基,改变了当前分支所有commit的基础代码
而merge则是
看到并没有创建新的commit(即 commit ID 是对应一样的),并且是基于当前分支的commit所做的修改
试想一下,生产环境中的main分支应该使用merge还是rebase来合并bugfix分支上的代码呢?
个人感觉应该使用merge,因为它更符合人的直观感觉,它是一种线性的、追加形式的。代码出了问题或者有新的功能添加,它应该就是以追加的形式添加代码的
至于说能不能用rebase,当然也是可以的,merge和rabase都是代码合并的手段,其最终效果还是一样的
rebase不仅可以用来合并代码,还能加上 -i 参数可视化修改提交,是一个功能非常强大的命令
git回滚操作
图来源:https://blog.osteele.com/2008/05/my-git-workflow/
git中有一棵树、两个区、两类指针
一棵树:版本树,它将代码的每个版本打包串起来,某些版本可能会有分支,他们就共同构成一棵树
两个区:工作区和暂存区
工作区:就是你当前项目目录
暂存区:版本树是一个大仓库,但我并不希望每次代码改动都做成一个版本提交到版本树中,而是希望按照实现的功能将多次改动共同作为一个版本提交,这个暂存区就是用来存储你的多次改动的地方
两类指针:HEAD指针和branch指针。他们分别指向版本树中的某个版本
HEAD指针:你对代码的所有操作总是依赖于版本树中的一个版本的,而HEAD指针指的就是你当前工作的那个版本
branch指针:你的代码有多个分支,每个分支总会有一个版本状态,branch指针就是说当前版本树的哪个节点表示这个分支
注:一般也会将暂存区和工作区也比作两棵树,我更乐意把他们看作两个代码缓冲区,因为他们没有版本的概念。就像两个大水池,你往里面放什么它就装什么,你往里面放哪个版本的代码,他就算是哪个版本。
例如:当你在暂存区存放了一些改动文件后,没有commit而切换到其他分支(git checkout branch),此时暂存区和工作区都会保持不变,只有HEAD指针会移动到新分支的branch指针所指向的版本上,你再commit的话就是将暂存区的代码提交到新分支上了
reset
git reset VERSION
用于同时修改HEAD指针和branch指针指向代码树中的版本(只要树中有的版本都可以指),你可以使用参数设置它是否要级联修改暂存区和工作区的代码
--soft:只修改HEAD和branch指针。
此时暂存区和工作区保持不变。就是回滚到add之后,commit之前的状态
注:暂存区在commit之后并不会清空,而是保留commit时的代码快照--mix(默认):修改HEAD&branch指针和暂存区代码。
即将暂存区的代码修改为HEAD新指向的版本代码。即回滚到add之前的状态--hard:修改HEAD&branch指针和两个区的代码
使用该命令要注意,因为它会修改工作区的代码git reset VERSION files
你可以选择只回滚部分文件到某个版本,但如此一来一个项目中的文件就可能属于不同版本了,而一个HEAD指针显然不可能指向多个版本
故当你只回滚部分文件时,HEAD指针并不会改变
除了HEAD指针不变外,其他还是一样的(即暂存区和工作区的级联改变)
git revert
git revert commitid
reset是将HEAD指针和branch指针重新指回之前的某个commit,而在该commit之后的commit都不要了
revert是指定回滚某一个commit,它只会回滚这一个commit中的代码,并且提交一个新的commit到版本库
reset的指针是往后走的,而revert的指针是往前走的
如果你要revert的某个commit与其后面的一些commit修改了相同的文件则会产生冲突,此时执行revert命令后,这些有冲突的文件就会有两个版本的代码,需要你手动进行处理,你可以使用 git revert –abort来撤销revert
checkout
git checkout 有两个作用,一是切换分支(checkout [ version|branch ]),二是恢复工作区文件状态(checkout files)
注:由于checkout功能比较混乱,后面又开发出
switch和restore两个命令分别用来切换分支和恢复文件状态git checkout VERSION 和 git reset –hard VERSION 命令很像,他们都会移动HEAD指针,修改暂存区和工作区,但它们又有很大不同
- 它只移动了HEAD指针而没有移动branch指针(若checkout的是某个版本而不是分支,则会出现branch指针和HEAD指针指向两个不同的版本,这就是指针分离)。你可以在指针分离的情况下修改代码创建新的branch,防止污染了原来的branch
git checkout VERSION file也和 git reset –hard VERSION file相似,只不过也是不移动HEAD指针,暂存区和工作区还是会变的(不管暂存区和工作区是否有未提交的代码)python的闭包简介
LEGB法则
python变量的作用域遵从LEGB法则,即:
Local(L):定义在方法或类内部的变量,如 def 或 lambda 函数内部
Enclosed(E):闭包内部变量(仅限闭包)
Global(G):全局变量
Built-in(B):python内置的关键字
对任意一个变量,python会按照上述顺序依次查找
这意味着python中有且仅有这四个作用域,最小作用域范围就是方法,而没有其他语言中的块作用域,例如下述代码:
def func(): if True: v = 'bingo' print(v)这段代码如果在java中执行就会无法编译,因为v的作用域局限在if的代码块中。而在python中就不会,因为python的最小作用域是func。同样,对于for、while这些代码块也是没有作用域的
闭包
英文名为 enclosing function,我更喜欢称之为“嵌套函数”,因为其本身就是“函数内部定义的函数”
def outlier(): def inner(): # 这个函数就是闭包 ... ... # 你可以在outlier函数内部直接调用inner函数,也可以直接将inner函数作为返回值这样做的目的是什么呢?我觉得就是创建出一个作用域。如果不看python内置变量的话,在没有闭包的情况下,python仅仅只有两个作用域,对于一个变量,要么在func内部找,要么去全局里面找。这样做的话,对于func内部变量还好说,因为变量已经被func根据不同的功能隔离开了,但对于全局变量的管理就比较混乱了,各种不同功能的全局变量一股脑都在全局环境中。但引入闭包就不同了,它又将func视作一个全局变量环境(仅针对闭包来说),一层一层嵌套,就能更好地管理“全局变量”(并非真的全局变量,仅仅对闭包而言)
这就好比是:在以前,村民有什么问题都去找酋长。现在这种责任关系通过进一步的细分,村民有问题找村长,村长解决不了找县长,县长解决不了找市长。。。
一个综合一点的题目
为什么输出结果是这样?
arr = [] for i in range(3): def inner(num): return num * i arr.append(inner) for func in arr: print(func(2)) # 输出结果:4 4 4分析:
从作用域来说,由于for是没有作用域的,故代码其实等价于:
arr = [] i = 0 # 由于for没有定义域,故for内部定义的变量i等价于在外部定义 def inner(num): # 由于for没有定义域,故for内部定义的函数inner等价于在外部定义 return num * i for counter in range(3): # for会先给外部变量i赋值,再将函数添加到arr中 i = counter arr.append(inner) for func in arr: print(func(2))看到没,对于函数inner来说,i就是全局变量,而对于main来说,它是局部变量。这个作用域太大了,而我们仅仅是希望将其限制在for和inner之间。所以,一个解决方法是使用闭包:
Golang基础知识
优势
简单的部署方式
可直接编译成机器码
不依赖其他库
直接运行即可部署
静态类型语言
- 编译的时候检查出大多数的问题
语言层面的并发
强大的标准库
runtime系统调度机制
高效的GC垃圾回收
丰富的标准库
简单易学
25个关键字
c语言支持
面向对象
跨平台
成就
Docker
Kubernetes
缺点
包管理,大部分都托管在github上
无泛化类型
所有的Exception都用Error来处理
对C的降级处理并非无缝,没有C降级到asm(汇编)那么完美
杂记
分号可加可不加
左花括号一定和方法名在同一行(同java,但强制)
变量
声明变量的四种方式
var a int // 默认值为0
var a int = 100 // 初始化值
var c = 100 //不显示声明类型
c := 100 // 最常用,省去var
注:声明全局变量,以上方法1、2、3都可以,
:=只能使用在函数体中
- 多变量声明
- 方式一
var v1, v2 = 100, "name"
- 方式二
var ( v1 int = 100 v2 bool = true )常量
将变量中的var修改为const即可
使用Go module创建项目
项目实例
最终目录结构
创建项目目录
创建一个目录作为项目根目录(目录名随意,我这里使用 go_practice ),在在其下面创建一个子目录(sub_pkg)用于演示package的引用方式
初始化GOMODULE
在 go_practice 目录下执行命令
go mod init hunt/practice其中
hunt/practice是该 module 名,其他 module 需要引入该 module 时就使用该名称引入,该名称可设置为任何合法字符串 “mypractice”、“dir1/dir2/dir3”、“github.com/some/dependency” 等。命令执行完成之后会在该目录下生成一个
go.mod文件,该文件维护该module的依赖(初始化项目没有依赖,所有是空的)
创建go文件
首先在
sub_pkg下创建一个say_hi.go,用于演示调用本地package的情况// 包名建议和目录名相同,此处为了演示效果设置一个不同的名称 package hi import ( "fmt" ) // 方法名开头大写可被其他package调用,否则视为private只能同包使用 func Say() { fmt.Println("hi") }再在
sub_pkg下创建一个thirdpart.go,用于演示调用第三方库的情况// 注意,同一个目录下的go文件同属于同一个package,故设置package名相同(若设置不同名称会编译报错) package hi import ( "fmt" "rsc.io/quote" ) func Third_say() { fmt.Println("third part pkg say: " + quote.Go()) }然后在根目录 go_practice 下创建一个 my_main.go
《Redis开发与运维》笔记
为什么单线程还能那么快
- 纯内存访问,Redis将所有数据放在内存中,内存的响应时长大 约为100纳秒,这是Redis达到每秒万级别访问的重要基础。
- 非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上 Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不 在网络I/O上浪费过多的时间。
对于字符串类型键,执行set命令会去掉过期时间,这个问题很容易 在开发中被忽视。
设置过期时间为负值,则会立刻删除key。使用persist指令移除过期时间
可以使用migrate指令将源redis中的key迁移到目标redis(两个redis实例)。其本质是 dump(源redis执行)、restore(目标redis执行)、del(源redis执行)三个命令的组合,不过是原子操作
scan命令
scan命令用于增量遍历keys,类似于keys命令,但是scan命令可以指定分页以达到增量遍历的目的,时间复杂度为O1 但是如果在scan过程中key数量发生了变化,则获取的结果将和实际有偏差
- flushdb/flushall指令用于清空数据库,flushall会清空所有1-16个数据库。可以使用rename指令将其重命名为一个随机字符串避免滥用
除了五种数据结构的存储,redis还提供了其他的功能
慢查询分析、pipeline、事务于Lua、Bitmaps、HyperLoglog、发布订阅、GEO
慢查询
每次执行命令分4步:
- 客户端向redis服务端发送命令
- 命令排队
- 执行命令
- 返回结果 其中,慢查询分析只到前3步
慢查询阈值 在配置文件中加入以下配置
slowlog-log-slower-than=1000000 // 记录大于1秒的命令,如果设为0,则记录所有命令 slowlog-max-len=1000 // 最多记录多少条记录
慢查询记录放在哪 慢查询日志是存放在内存中的,可以通过命令进行查询
slowlog get 3 // 获取3条慢查询记录,先进先出队列
Pipeline
批处理命令(如mget、mset)有效地节约了多命令执行时间,但大部分命令不支持批量操作,pipeline就是将多条命令打包一起发送,然后一起返回,降低了命令执行时间
- 原生批处理命令与pipeline对比
- 原生批处理是原子的,pipeline不是
- 原生批处理命令是一个命令对应多个key,pipeline支持多个不同命令
- 原生批命令是redis服务端支持实现的,而pipeline需服务端和客户端共同实现
事务
redis提供了简单的事务功能,将多个命令放在 multi 和 exec 之间即可,事务过程中的命令并没有真正执行
注:
- redis中事务不支持回滚,如果事务中某个命令出错,其前面的命令仍会执行。
- 如果在事务中某个事务中用到的key被其他客户端修改了,则不会执行该事务,类似于乐观锁 但是这些问题可以使用Lua脚本解决,即使用一段脚本来控制redis,且是原子操作
Bitmaps
Bitmaps可以实现对位操作 其本质就是一个字符串,例如 a 的二进制为1001,虽然Bitmaps存储的是 a,但可以对其二进制进行操作
setbit key 20 1 // 设置key的第20位的值为1(只能是01) getbit key 20 // 获取key的第20位的值
ArrayList扩容
向
ArrayList中添加元素时,若数组容量小于添加元素后长度,则创建一个新的数组,数组长度为原长度的 3/2 倍,然后将旧的数组内容复制到新的数组// 注释:>> 1 的意思是除2,<< 1的意思是乘2,位计算效率会更高 //参见JDK1.8.0_121 ArrayList.java:255 int newCapacity = oldCapacity + (oldCapacity >> 1); ... elementData = Arrays.copyOf(elementData,newCapacity);DNS与CDN相关联系与实现
背景:
- Client 1 与 business server 3 及DNS A在地理位置上相较于其他更近。
- dns缓存均未命中。
- Local DNS 默认实现了 edns 协议。(路由查询会携带源client的ip地址)
- a.com 域名配置为了 NS 记录方式。
过程解析:
- Client 1 向local dns(即本机设置的dns服务器,本例中为 8.8.8.8)发送域名 mail.a.com 的解析请求。
- 通过 anycall 技术可以实现一个 8.8.8.8 地址被多个域名解析服务器使用,通过 bgp 协议找到距离 client 1 最近的dns server(本例中为:DNS A) 3.1 DNS A如果未开启转发模式,则会请求根域名服务器,根域名服务器返回域名服务器ip地址(本例中为 com dns server),DNS A请求com dns server,其返回 a.com dns server ip地址【批注1】。DNS A携带client A的源ip(edge协议)访问 a.com dns server,该dns依据 edns 协议,由 client A的ip地址匹配与其地理位置最近的mail.a.com CDN服务器的ip(本例中为 business server A 3.3.3.3)。DNS A将3.3.3.3返回给客户机,客户机再访问该server A。 3.2 DNS A如果开启转发模式,则会根据其配置的转发规则进行转发,具体可参考:https://www.cnblogs.com/qingdaofu/p/7399670.html
【批注1】:我们注册域名后,可以选择将域名解析为 NS 记录(类比 A记录或CNAME记录),其会将该域名授权为 dns 域名解析服务器的域名,我们可以自己实现路由规则。
git拉取远程分支基本过程
Step 1: 首先查看当前分支
git branchStep 2: 拉取远程分支代码到本地的一个临时分支
git fetch origin main:tmp注:
git中的 origin 只是远程仓库地址的别名,也可替换为其真正的地址。使用 git remote -v 查看。
一般来说 对于不会用的命令,在其后面加上 –help 即可打开文档,翻到文档最下面一般有详细示例。
Step 3: 查看不同
git diff --stat tmp # --stat 参数只显示不同文件名,否则会将修改的代码都显示出来
git diff默认显示工作区和暂存区的不同
git diff --staged显示暂存区和HEAD的不同
git diff commit1 commit2显示commit2相对与commit1的变动,也能将commitID替换成branch
git diff commitID显示当前工作区对比指定版本的变动,也能指定分支Step 4: 合并代码
git merge tmp此时如果有冲突会有提示,执行
git merge --abort即可回退合并,该命令只有在合并完成之前有效,即如果没有冲突,则直接自动合并完成。Step 5: 删除临时分支
git branch -d tmp # -d参数即为删除例:
hashmap的数据结构
存储结构
hashmap在jdk1.8之前采用数组加链表的方式存储,根据key的hash计算存储在数组中的位置,因为hash可能重复,当hash值重复时,则在该数组元素下卦一个链表,jdk1.8以后,默认当链表长度大于8时,会在该链表下挂一个红黑树。
如何计算hash 使用数据的hash值与数组长度进行
按位与运行hash(data) & table.length
效果相当于取模,得到的值不会大于数组长度(redis中的slot也是这样的算法)
效率
所以对于_没有链表数组元素_的操作,比如CRUD都很快,只需_一次_寻址即可,如果定位到有链表的数组元素,对于添加操作其时间复杂度依然位O(1),因为最新的Entry会插入链表的头部,只需要简单的改变引用链即可,但是对于查找来说,就需要遍历整个_链表_,通过key的equals方法逐一对比。
容量问题
解释1:创建hashmap和hashtable时,若不指定初始容量值,hashtable默认的初始值为
11,之后每次扩充,容量变为原来的==2n+1==。hashmap默认初始大小为16,之后每次扩容,容量变为原来的==2倍==。如果创建时制定了大小,hashtable会直接使用给定大小,但hashmap会将其扩充到==2的幂次方==大小。也就是说hashmap总是使用2的幂次方作为hash表的大小。原因:为了能让hashmap存取高效,尽量减少碰撞,也就是说要尽量把数据分配均匀,每个链表/红黑树长度大致相同,首先会想到取余操作实现,但是,取余(%)中如果除数是2的幂次则等价于与其除数减一的与(&)操作,即 hash%length==hash&(length-1),前提是length是2的n次方,并且二进制操作&相对于%能提高效率,这就解释了hashmap的长度为什么是2的幂次方。解释2: 根据上面计算元素在数组中的角标算法(按位与),则table的长度的二进制必须得是 000011111的形式(后面必须全是连续的1),否则进行按位与时就有的值取不到,例如,如果表长为 0110(十进制为6),则任何数据与其进行按位与时都无法取到 xxx1,因为按位与必须两个数据对应位置全是1结果才是1。这样就浪费了一个空间
i++的java底层原理
i++问题
int i = 0; i = i++; print(i) // 0解释: i++中有两个临时变量,所以上式编译之后会成为
int i = 0; byte temp1 = i; int temp2 = i + 1; i = temp1; print(i)但是其真正的字节码中只有i一个变量,使用栈完成上述结果(复习栈帧的内容)
js中的async/await
async 起什么作用
这个问题的关键在于,async 函数是怎么处理它的返回值的!
我们当然希望它能直接通过 return 语句返回我们想要的值,但是如果真是这样,似乎就没 await 什么事了。所以,写段代码来试试,看它到底会返回什么:
async function testAsync() { return "hello async"; } const result = testAsync(); console.log(result);输出为一个Promise对象
c:\var\test> node –harmony_async_await . Promise { ‘hello async’ }
所以,async 函数返回的是一个 Promise 对象。从文档中也可以得到这个信息。async 函数(包含函数语句、函数表达式、Lambda表达式)会返回一个 Promise 对象,如果在函数中 return 一个直接量,async 会把这个直接量通过 Promise.resolve() 封装成 Promise 对象。 async 函数返回的是一个 Promise 对象,所以在最外层不能用 await 获取其返回值的情况下,我们当然应该用原来的方式:then() 链来处理这个 Promise 对象,就像这样
testAsync().then(v => { console.log(v); // 输出 hello async });现在回过头来想下,如果 async 函数没有返回值,又该如何?很容易想到,它会返回 Promise.resolve(undefined)。
联想一下 Promise 的特点——无等待,所以在没有 await 的情况下执行 async 函数,它会立即执行,返回一个 Promise 对象,并且,绝不会阻塞后面的语句。这和普通返回 Promise 对象的函数并无二致。
JUC学习笔记
volatile
- 关于上述程序的说明: main方法中开启了两个线程,一个共享数据flag。myThread线程在100毫秒后将flag修改为true,主线程循环读取flag,如果为true则打印一句话。 但是执行结果发现,即使myThread将flag修改为true,主线程仍然没有打印任何值。
- 解释: 每个线程都会有自己的工作线程,且他们共享一块主内存。myThread线程从主内存读取数据后,在工作内存中修改数据并同步进主内存,但由于 while(true) 执行效率非常快,main线程从主内存获取数据之后根本来不及重新从主内存中读取数据,所以一直读取的是旧数据。解决方案:死循环中加入延时/加入同步锁/使用volatile修饰变量
volatile
使用内存栅栏技术(防止指令重排序),使得线程每次获取数据都是从主存中获取 相较于synchronized是一种更轻量级的同步策略
缺点
- 不具备互斥性,可以多线程同时读写
- 不保证操作原子性
原子变量
使用volatile能保证可见性,但是无法保证对变量修改的原子性(例如 i++ 问题),此时可以使用 java.util.concurrent.atomic 包下提供的常用原子变量
- 这些原子变量内部都使用了volatile保证可见先
- 对这些变量的修改都使用了 CAS 保证数据的原子性
private AtomicInteger num = new AtomicInteger(); num.getAndIncreasment(); // 自增CAS
包含了三个操作数 内存值V,预估值A,更新值B。当且仅当 V== A 时,才会将B赋给V。这三步是同步的 会出现ABA问题
synchronized
synchronized 默认使用当前对象作为锁,如果是静态方法则使用当前class对象作为锁。 在某时刻内,只能有一个线程能够获取锁
ConcurrentHashMap/CountDownLatch
线程安全的Hash表
- HashMap 和 HashTable HashMap线程不安全 HashTable线程安全,但效率低,每个方法都使用同步锁,并且复合操作(例:如果存在即修改)也是线程不安全
ConcurrentHashMap 锁分段机制
并发级别(concurrentLevel)
默认分为16段(segment),每个段中又有一个16单位长度的数组,数组的每个元素下又挂着一个链表 这样的话每个段都有一个独立的锁,所以可以多线程同时访问多个不同的段 jdk1.8之后每个段也修改为使用cas操作
- 此包下还提供了很多其他的集合,例如 CopyOnWriteArrayList,该类也是一个集合,用法同 List,但是每次向其中添加元素时,它都会重新复制一个新的List并指向原集合。所以对集合有很多的添加操作时效率较低,开销大。通常可以用于多线程使用迭代器遍历,并在遍历过程中添加元素(注:普通的list即使在迭代器遍历过程中添加元素也会报错)
CountDownLatch 闭锁
在进行某些运算时,只有其他所有线程的运算全部完成,当前运算才继续执行
// 这里的 2 代表这个闭锁可以监控2个线程是否结束,内部维护一个整型变量=2,每次子线程结束就-1,直到为0 CountDownLatch latch = new CountDownLatch(2) new Thread(new MyThread(latch)).start(); new Thread(new MyThread(latch)).start(); latch.wait(); // 会一直等到闭锁值为0 class MyThread implements Runable{ private CountDownLatch latch; public void run() { // do something this.latch.countDown(); // 子线程结束后,需手动将闭锁减一 } }Callable接口
创建线程的方式有四种
jvm学习笔记
基于栈和基于寄存器的指令集架构
Jvm前端编译器架构=都是=
基于栈的指令集架构,与之对应的还有基于寄存器的指令集架构。### 基于栈的指令集架构* 跨平台性好、指令集小、指令多、性能相较于寄存器更差 * 例:
基于寄存器的指令集架构
* 直接使用cpu的指令集,故执行幸能更好,但是移植性较差Hotspot/JRocket/J9
JRocket:号称最快的虚拟机,专注于服务端,牺牲程序启动速度,因此其内部不包含解析器的实现,全部代码都即时编译器编译后执行
J9:运行IBM自己的软件时速度较快,J9最厉害的地方是它高度模块化,不但可以部署在桌面或服务器上,还可以部署到嵌入式环境中,例如CLDC级别的环境;这些环境用的是同一个J9核心VM,搭配上适用于具体环境的GC和JIT编译器。
hotspot:运用最广泛的虚拟机
类加载子系统
graph LR 加载 ---> 验证 subgraph 链接 验证 ---> 准备 ---> 解析 end 解析 ---> 初始化类的加载过程
- 加载 加载二进制流并产生对应的Class对象。
- 链接 2.1 验证
- 确保class文件的字节流满足当前虚拟机的要求,保证被加载类的正确性
- 主要包含四种验证:文件格式验证(例如是否以魔数开头),元数据验证,字节码验证,符号引用验证 2.2 准备
- 为类变量分配内存并且设置该类变量(static修饰的变量)的默认初始值,即零值。如 int i = 3,则在此阶段将i赋值为0。
- 注:这里不包含被final修饰的类变量,它在编译的时候就已经赋零值了,在准备阶段会显示初始化,即 i 赋值为3。
- 准备阶段不会为实例变量初始化,类变量会分配到方法区中,而示例变量则会随着对象一起分配到java堆中。 2.3 解析
- 将常量池内的符号引用转换为直接引用的过程。
- 初始化
- 初始化阶段就是执行类构造器方法()的过程。
- 该方法不需要定义,由javac编译器自动生成(如果没有类变量或静态代码块就不会生成该方法)。不同于类的构造器,即()
- 构造器方法中的指令语句按照源文件出现的顺序执行。
- 若该类有父类,则一定要保证父类的()已经执行完毕了
- 虚拟机必须保证一个类的()方法在多线程下被同步加锁。
类加载器
虚拟机规范中规定类加载器只有两种,启动类加载器(bootstrap class loader)和用户自定义类加载器(凡是直接或间接继承自ClassLoader类的均为用户自定义类加载器)
Bootstrap class loader使用的是c/c++编写,其他类加载器使用java编写。
macos查看局域网所有的ip地址 arp命令
apr -a用于查看高速缓存中的所有项目。-a和-g参数的结果是一样的,多年来-g一直是UNIX平台上用来显示ARP高速缓存中所有项目的选项,而Windows用的是arp -a(-a可被视为all,即全部的意思),但它也可以接受比较传统的-g选项。
ARP常用命令选项
arp -a IP如果我们有多个网卡,那么使用arp -a加上接口的IP地址,就可以只显示与该接口相关的ARP缓存项目。
arp -s IP 物理地址我们可以向ARP高速缓存中人工输入一个静态项目。该项目在计算机引导过程中将保持有效状态,或者在出现错误时,人工配置的物理地址将自动更新该项目。
arp -d IP使用本命令能够人工删除一个静态项目。
例如我们在命令提示符下,我们使用过 Ping 命令测试并验证从这台计算机到 IP 地址为 10.0.0.99 的主机的连通性,然后再键入 Arp -a,则 ARP 缓存显示以下项: Interface:10.0.0.1 on interface — 0x1 Internet Address Physical Address Type 10.0.0.99 00-e0-98-00-7c-dc dynamic
在此例中,缓存项指出位于 10.0.0.99 的远程主机解析成 00-e0-98-00-7c-dc 的媒体访问控制地址,它是在远程计算机的网卡硬件中分配的。媒体访问控制地址是计算机用于与网络上远程 TCP/IP 主机物理通讯的地址。
MySQL学习笔记
概述
索引的数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
- 每个索引都可以选择不同的数据结构
使用红黑树保存索引数据,仍然会因为树的高度增加带来的查询效率的衰减,解决方案是每个节点多放几个索引数据,即B树,为了更高的查询效率,在B树的基础上衍生出B+树
B和B+树的区别
- 非叶子节点不保存数据,只保存树索引
- 叶子节点使用指针链接
B+树每个节点默认是16kb,每个索引14字节,所以一个节点可以存1170个索引元素
myISAM 和 InnoDB是形容表的,不是形容库的,所以每个表都能有不同的存储引擎
MyISAM中B+树索引的叶子节点的data元素保存的是数据库某一行的索引(在文件系统中索引和数据分两个文件存储),而InnoDB叶子节点中的data保存的就是某一行的数据(索引和文件保存在同一个文件中,即
聚集索引)InnoDB表必须要有主键,并且推荐使用整型自增 每个节点中保存了很多的索引数据,如果没有使用UUID作为主键则需要先转换成为acsii进行比较。并且整型更节约空间 使用自增的原因是因为查找可能是范围查找,就可以直接遍历叶子节点 方便插入和删除(树的插入和删除复习)
联合索引 按照联合索引顺序将多个索引统一保存在B+树的每一个节点中,查找时,如果节点中的第一个元素相同,则比较下一个,以此类推
每次查询的时候,文件系统最少会向内存中加载一页的数据(即一个节点16kb,类比操作系统的
局部性原理)表中的每一行都会有一种行格式,比如COMPACT、Dynamic、Compress等。每一种行格式所记录的每一行的数据格式不尽相同,例如COMPACT格式记录的一行数据为: 变长字段长度列表+NULL标志位+记录头信息+列1数据+列2数据。。。
- 变长字段长度列表: 按可变长字段顺序保存该字段长度,例如 name varchar(20) 是该列第3个元素,则在该变长字段长度列表的第三个位置保存实际存储的name的实际长度 注:innoDB每一行元素占用总内存不得超过65535字节,blobs类型字段除外。但是一页只有16k的数据,
故超过一页大小的数据就需要分页,不同的数据库引擎分页方式不同,例如InnoDB中,分页数据的第一页不存储数据,只存储下一页的地址,方便索引- NULL标志位 表中的某些字段允许为空,则该字段中按照允许为空的字段顺序存储01,其中0代表该值为空,1代表不为空,例如00101
存储结构/索引
InnoDB
- InnoDB查询出来的数据会自动根据主键进行排序,原因是其主键默认也是索引。MySIAM查询出来的顺序是插入时的顺序
InnoDB数据存储格式
表中的数据以数据页为单位在磁盘中进行存储,每一页有16KB,每一页数据都会携带除用户数据以外的数据,例如下一页的数据,和该页的分组数据。例如:如果表中每一行元素只需要存很少数据,则一页数据就可以存很多行数据,所有的行数据形成一个链表,如果一页数据量过大,则查询效率会减小。 此时就会将这一页的数据分成n个组,例如(1-4)(5-9)…,每个组保存最小数据的指针,保存在页的头信息中,即
分组数据。 这样的话,如果查询某一个数据则会先去分组数据里面找,然后直接在命中的分组中进行查找。
目录页 一张表中的数据会存储在多个页中,那么查找数据时如何知道在第几页? 在这些页之上又抽象出一种目录页的结果(即B+树中的非叶子节点),目录页中存储了每一页的最小索引的位置
如果建表时既没有定义主键,也没有定义唯一列,则InnoDB会自动创建一个名为 rowID的自增字段
MySql在创建表时会自动创建一个空页,当向表中存数据时就会向该页存,当该页存满时,
会复制当前页到新的一页,然后再创建一个新页存储新的数据,并将第一页数据清空,升级为这两个新页的目录页,这样做的好处是保持查找开始内存位置不变,将第一页常驻内存,加快查找速度创建多个字段联合索引 会将这些字段拼接起来进行排序(建立索引的本质就是排序),
并在该索引的B+树的叶子节点只保存数据行的主键(即每创建一个索引都会创建一个B+树,但是除主键索引外,其他的都不保存行数据),然后根据该主键再去主键索引查找行数据 如果建立的索引列的数据都相似或者相同,则创建出的索引意义不大,Mysql会自动在这种索引中加上主键索引,保证索引唯一可以使用 explain SQL 查看是否使用索引
注:
- mysql中的utf8格式其实只是真正的utf8的子集,它认为你不会存一些非常少见的字符,真正的utf8应该是utf8mb4
- 定义字段时也可以指定排序规则,比如对于字符串的比较,可以将其转换为ascii比较,也可以转换为二进制比较,使用以下方式设置
例如,以_bin结尾的就是转换为二进制比较
事务
使用begin/commit/rollback开启/提交/回滚事务,可以开启或关闭Mysql的自动提交(默认开启使用begin/commit/rollback开启/提交/回滚事务,可以开启或关闭Mysql的自动提交(默开)
隐式提交 使用ddl时会自动隐式提交数据
保存点 创建事务后,提交前,可以创建多个保存点。当需要回滚时可以指定回滚到某个保存点
四种事务隔离
- 读未提交(Read Uncommitted) 事务即使没有提交,其他地方也能读到该未提交的数据 会出现脏读
读已提交(Read Committed) 必须提交之后其他地方才能读到数据,但是其他地方的事务中,即使没有提交,但是表发生了变动,同一个事务中也会查出不同的结构 会出现幻读和不可重复读(两者本质相同)
netty学习笔记
预备
什么是Netty? 异步的、基于事件驱动的网络应用框架,用于快速开发高性能、高可靠的网络IO程序 主要针对TCP协议下,面向Clients端的高并发应用 本指是一个基于TCP的NIO框架,只是对原生的NIO做了一个封装。
应用场景 高性能RPC框架必不可少,例如Dubbo 游戏行业中,处理大并发
I/O模型
Java共支持3中网络编程模型I/O模式:BIO、NIO、AIO
BIO(同步阻塞) 服务器实现模式为一个连接一个线程
NIO(同步非阻塞) 一个线程处理多个请求,即客户端发送的连接请求都会注册到多路复用器上(selector),多路复用器轮询到连接有IO请求就进行处理,适合于连接数目多连接比较短的架构,例如聊天服务器弹幕系统等
AIO(异步非阻塞) AIO引入异步通道的概念,采用了Proactor模式,简化了程序的编写,有效的请求才启动线程,特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用
NIO
NIO相关的类都放在java.nio包及其子包下
NIO三大核心:Channel、Buffer、Selector
NIO是面向缓冲区或面向块编程的,数据读取到一个缓冲区,需要时可在缓冲区前后移动
三大组件的关系
graph Thread ---> Selector Selector ---> Channel1 Selector ---> Channel2 Selector ---> Channel3Channel1 —> Buffer1 Channel2 —> Buffer2 Channel3 —> Buffer3
Buffer1 —> Client1 Buffer2 —> Client2 Buffer3 —> Client3
1. 每一个Channel都会对应一个Buffer 2. Selector对应一个线程,一个线程对应多个Channel(连接) 3. 该图反映了三个Channel注册到该Selector 4. 程序切换到哪个Channel是由事件(Event)决定的 5. Selector会根据不同的事件在各个Channel上切换 6. Buffer本质是一个数组 7. 数据的读取和写入都是要通过Buffer,通过flip方法切换 ##### Buffer 本质是一个可以读写的数据块,可以理解成一个容器对象(包含了一个数组),该对象提供了一组方法可以轻松的使用内存块。缓冲区对象内置了一些机制,能够追踪和记录缓冲区的状态变化情况,JDK提供了除了boolean之外的其他七种基本类型的Buffer ```java public static void main(String[] args) { IntBuffer buffer = IntBuffer.allocate(3); for (int i = 0; i < buffer.capacity(); i++) { buffer.put(i); } // 读写转换(重要) buffer.flip(); // 是否还存在值 while (buffer.hasRemaining()) { // get方法内部存在一个游标 System.out.println(buffer.get()); } }
- Buffer类(所有Buffer父类)定义了所有缓冲区都具有的四个属性
- Capacity:容量,创建时指定,不能改变
- Limit:缓冲区的当前终点,不能对超过该值的位置进行读写操作
- Position:游标,每次读写数据都会改变
- Mark:标记,很少主动修改
Channel
类似于流,但可以双向读写(实际上channel是Stream中的一个属性) Channel在Java中是一个接口,常用的实现类:FileChannel、ServerSocketChannel、SocketChannel等 使用transferFrom/transterTo方法实现文件的快速拷贝 提供了MappedByteBuffer支持直接在堆外内存中修改文件,而不用操作系统多拷贝一次
Unicode汉字、英文字母、数字的unicode范围
汉字:[
0x4e00,0x9fa5](或十进制[19968,40869])共20901个数字:[
0x30,0x39](或十进制[48,57])共10个小写字母:[
0x61,0x7a](或十进制[97,122])共26个大写字母:[
0x41,0x5a](或十进制[65,90])共26个例如:编码
\u4e00表示汉字一,编码\u0061表示小写字母awin10系统重置之后鼠标右键一直转圈
显卡驱动的问题,进入 设备管理器 ,右键显示适配器,更新驱动程序就好
Zookeeper 学习笔记
什么是Zookeeper Zookeeper分为服务端和客户端 一个服务端可以理解为多个节点容器,节点被成为ZNode,一个节点类似于一个文件,用于保存数据,例如字符串。同时,一个节点也可以理解为一个目录,即可以在一个节点下新建其他节点。 一个Zookeeper集群可以有多个服务端,每个服务端在启动时就已经在配置文件中配置了其他服务端的信息,例如ip和通信端口等。 在集群中,任意修改某个服务端中的节点数据都会实时同步到其他服务端。即集群中的服务端节点数据始终保持一致 客户端可以连接任意服务端增加、删除、修改、监听任意节点的变化。可以直接使用客户端的Shell,也可以在项目中引入Zookeeper的依赖,创建一个客户端,类似于JDBC或者Jedis等。
特点
- Zookeeper有一个Leader和多个Follower
- 集群中只要有
半数以上节点存活,Zookeeper季军就能正常服务- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接哪个Server,数据都是一致的
- 更新请求顺序执行,来自同一个Client的更新请求按照其发送顺序依次执行
- 数据更新的原子性,一次数据更新要么成功要么失败
- 实时性,在一定时间范围内,Client能读到最新的数据
数据结构及存储方式 Zookeeper数据模型的结构与Unix文件系统类似,整体上可以看作是一棵树,每个节点称作为一个ZNode,每个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标志
graph n --/znode1--> n1 n --/znode2--> n2 n1 --/znode1/leaf1--> n3 n1 --/znode1/leaf2--> n4 n2 --/znode2/leaf1--> n5应用场景
- 统一命名服务 在分布式环境下,经常需要对应用或者服务器进行统一命名,便于标识。类似域名和IP
- 统一配置服务 在分布式环境下,配置文件同步非常常见。将配置信息写入Zookeeper上的一个ZNode,每个客户端监听该ZNode,一旦该节点配置发生变化,leader将通知其他节点进行更新
- 统一集群管理 分布式环境中,实时掌握每个节点的状态是必要的。Zookeeper可以实时监控节点状态的变化,可以将节点信息写入Zookeeper上的一个Znode,然后监听这个node获取它实时状态变化
- 服务器节点动态上下线 客户端需要实时洞察服务器的上下线状态
- 软负载均衡 在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器取处理最新的请求
选举机制
- 半数机制:集群中半数以上的机器存活,集群可用。所以Zookeeper更适合安装奇数台服务器。
- Zookeeper索然在配置文件中没有指定Master和Slave。但是Zookeeper工作时还是有一个节点为Leader,其他则为Follower,Leader是通过内部选举机制产生的。
- 举例说明选举过程: 假设一个Zookeeper集群有五台服务器,他们的ID从1-5,同时他们都是最新启动的,也就是没有历史数据。假设这些服务器依次启动,则每台服务器启动后先选自己,如果没有成为Leader则选择ID号最大的,一旦某台服务器票数超过一半(在服务器启动时,已经在配置文件中配置了所有服务器的信息,故启动时是直到服务器总数的),就确认当选。例如3号服务器启动之后,即当选为Leader,由于票数已经超过了半数,故当4、5号机启动时不在进行选举。
节点类型
- 持久型(Perisitent):客户端和服务器端节点断开连接,创建的节点不删除(默认) 持久型的又分为两类:1)持久化目录节点。2)持久化顺序编号目录节点,即创建znode时设置顺序标识,znode名称后面会加上一个单调增的id。在分布式系统中,顺序号可以被用于所有事件的全局排序,这样客户端可以通过顺序号推断事件的顺序
- 短暂型(Ephemeral):客户端和服务器端节点断开连接后,创建的节点自己删除 同持久型,分两类。该类型一般用于判断服务器上下线。例如将某台应用服务器与某个短暂型节点绑定,一旦该服务器掉线,则该节点也被删除,监听该节点的客户端就能知道该服务器不可用了。
监听器原理
- 首先要有一个main()线程
- 在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个赋值网络通信(connect),一个负责监听(listener)
- 通过connect线程将注册的监听事件发送给Zookeeper(通过getChildren("/", rue)方法)
- 在Zookeeper的注册监听器列表中将之策的监听事件添加到列表中
- Zookeeper监听到由数据或路径变化,就会将该消息发送到listener线程
- listener线程内部调用process(方法)
写数据流程
- Client向Zookeeper上的Server1写数据,发送一个写请求
- 如果Server1不是Leader,那么Server1就会把接收到的请求进一步转发给Leader,因为每个Zookeeper的Server里面就会有一个时Leader,该Lieader就会将写请求广播给各个Server,各个Server写成功后就会通知Leader
- 当Leader收到大多数Server数据写成功了没那么说明数据写成功了。之后Leader会告知Server1数据写成功了。
字符集编码
将每个字符都使用一个数字表示,显示的时候自动将该数字替换为对应的字符,这就是现代的字符编码的意思
一开始,电脑只有西方在用,所以它们将26个英文字母和一些常用字符使用0-127这些数字表示,即一个字符只占一个字节,这就是最初的ASCII码表
后来越来越多非拉丁字符的地区需要使用电脑,于是各个地区或国家都创建了对应自己国家文字的编码表,比如中国大陆就创建了 GB2312、台湾地区的big5、德国的 IA5等,它们都是将自己的文字使用一个数字一一对应上,但总的来说前128位编码都还是拉丁文那一套。这些不同地区的编码同城为 ANSI 编码(即国内说的ANSI可能指的是GB2312,到台湾地区可能又指的是big5等)
问题来了,同一个数字在不同的地区可能表示不同的字符,所以查看一个文档,就需要计算机中装有该文档对应的字符集编码。
所以,有人就创建了 Unicode 字符集编码,它将全世界所有的字符全都收集起来,组成一个大的编码集。如此一来,理论上全世界都只用这一个编码即可。这里需要注意的一点是,这里所说的Unicode指的是编码表,即哪个数字对应哪个字符,但是没有规定如何在磁盘进行存储
问题来了,由于Unicode需要囊括所有的字符集,单单一个字节以及不足以存储一个字符所表示的数字了,所以可能每个字符都需要两个字节甚至四个字节来表示,例如原来字母a使用数字 96 表示,现在需要使用 0096 甚至 000096 来表示(每个字符都固定长度,用于对齐填充)。这样一来使用拉丁文的国家就不干了,因为原本只占用一倍的存储空间现在变成了两倍甚至四倍。
所以,在 Unicode 的基础上,有人就发明了 utf-8、utf-16等,它们能够自动识别当前字符是什么类型的字符,如果是拉丁字符,则存储时仍然只占用一个字节,如果是中文字符,则占用两个字节等等。不必纠结它如何实现这个功能的,但必须要明确的一点是,utf-8只是Unicode的一种存储方式,它本质上仍然使用的是Unicode编码表。也就是说,utf-8会将两个字节的 0096(表示Unicode中的a) 仍然以 96 这种单字节的方式存储在磁盘,相对应的,那种直接将 0096 存储到磁盘的方式就叫 UCS-2
以上就是它们的基本关系,另外还有一些编码,例如 iso8859,它是对ASCII的扩充,但仍然只支持拉丁文,GBK是对GB2312的扩充等。
最容易搞混的一点就是Unicode了,因为它有的时候表示的是Unicode字符集(字符到数字的映射),有的时候又表示字符的存储方式(UCS-2),网上有一张图
这里的Unicode就是指的 UCS-2。ANSI指的是该系统所用的编码。
敏捷开发中的一些概念
PO:产品负责人(Product Owner):主要负责确定产品的功能和达到要求的标准,指定软件的发布日期和交付的内容,同时有权力接受或拒绝开发团队的工作成果。 SM:流程管理员(Scrum Master):主要负责整个Scrum流程在项目中的顺利实施和进行,以及清除挡在客户和开发工作之间的沟通障碍,使得客户可以直接驱动开发。 ST:开发团队(Scrum Team):主要负责软件产品在Scrum规定流程下进行开发工作,人数控制在5~10人左右,每个成员可能负责不同的技术方面,但要求每成员必须要有很强的自我管理能力,同时具有一定的表达能力;成员可以采用任何工作方式,只要能达到Sprint的目标。
Sprint:是短距离赛跑的意思,这里面指的是一次迭代,而一次迭代的周期是1个月时间(即4个星期),也就是我们要把一次迭代的开发内容以最快的速度完成它,这个过程我们称它为 Sprint
敏捷开发分两种实践方式
Scrum和XP,Scrum 偏重于过程,XP 则偏重于实践,但是实际中,两者是结合一起应用的。 Scrum: 英文意思是橄榄球运动的一个专业术语,表示“争球”的动作;把一个开发流程的名字取名为Scrum,我想你一定能想象出你的开发团队在开发一个项目时, 大家像打橄榄球一样迅速、富有战斗激情、人人你争我抢地完成它,你一定会感到非常兴奋的。而Scrum就是这样的一个开发流程,运用该流程,你就能看到你团队高效的工作。 XP:极限编程(Extreme Programming),“开车”就是一个XP的范例,即使看上去进行得很顺利,也不要把视线从公路上移开,因为路况的变化,将使得你必须随时做出一些这样那样的调整。而在软件项目中,客户就是司机,他们也没有办法确切地知道软件应该做什么,因此程序员就需要向客户提供方向盘,并且告知我们现在的位置。详情参考Scrum开发流程
1.首先我们需要确认一个 PB ( Product Backlog , 即按优先顺序排列的一个产品需求列表) ,这是由 PO(Product Owner) 负责的
2.ST(Scrum Team) 会根据 PB 列表,进行工作量的预估和安排
3.有了 PB 列表,我们需要通过 Sprint Planning Meeting( Sprint 计划会议)来从中挑选出一个 Story 作为本次迭代完成的目标,这个目标的时间周期是1~4个星期,然后把这个Story进行细化,形成一个Sprint Backlog
4.Sprint Backlog 是由 ST 去完成的,每个成员根据Sprint Backlog再细化成更小的任务(细到每个任务的工作量在2天内能完成)
5.在Scrum Team完成计划会议上选出的Sprint Backlog过程中,需要进行 Daily Scrum Meeting(每日站立会议),每次会议控制在15分钟左右,每个人都必须发言,并且要向所有成员当面汇报你昨天完成了什么,并且向所有成员承诺你今天要完成什么,同时遇到不能解决的问题也可以提出,每个人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃尽图)
6.做到每日集成,也就是每天都要有一个可以成功编译、并且可以演示的版本;很多人可能还没有用过自动化的每日集成,其实TFS就有这个功能,它可以支持每次有成员进行签入操作的时候,在服务器上自动获取最新版本,然后在服务器中编译,如果通过则马上再执行单元测试代码,如果也全部通过,则将该版本发布,这时一次正式的签入操作才保存到TFS中,中间有任何失败,都会用邮件通知项目管理人员
7.当一个Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,这时,我们要进行 Srpint Review Meeting(演示会议),也称为评审会议,产品负责人和客户都要参加(最好本公司老板也参加),每一个Scrum Team的成员都要向他们演示自己完成的软件产品(这个会议非常重要,一定不能取消)
8.最后就是 Sprint Retrospective Meeting(回顾会议),也称为总结会议,以轮流发言方式进行,每个人都要发言,总结并讨论改进的地方,放入下一轮Sprint的产品需求中
正则匹配a,b之间的内容
比如我想匹配
<a>bingo</a>中的bingo可以使用正则(?<=<a>).*(?=<\a>)其中的(?<=X)为正后发断言,(?=X)为正先行断言,断言只是条件,帮助你找到需要的字符串,本身不会被匹配到结果中
规则 描述 (?=X) 零宽度先行断言,匹配右侧有表达式X (?!X) 零宽度负先行断言,匹配右侧没有表达式X (?<=X) 零宽度正后发断言,匹配左侧有表达式X (?<!X) 零宽度正后发断言,匹配左侧没有有表达式X 线程安全与锁优化
多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调用和交替执行,也不需要额外的同步,或者在调用方进行任何协调操作,都能获得正确的结果,那么这个对象是线程安全的
可以将java语言中的各种操作共享数据分为5类
- 不可变:Immutable对象、String或被finnal修饰的基本数据类型。对引用类型,只要其地址不变,且其不会暴露出影响其状态的方法,也是不变的。例如String,其本身内部使用final修饰,且其所有的方法都不会改变该值,而是新建一个String对象,所以String是不可变的
- 绝对线程安全:条件相当严苛,即在任何情况下都线程安全
- 相对线程安全:对象单独的操作是线程安全的。例如 Vector(所有的方法都被同步修饰)、HashTable
- 线程兼容:对象本身不是线程安全的,但是通过使用同步手段可以达到该目的,例如使用锁或者同步机制。如ArrayList和HashMap
- 线程对立:无论是否使用同步手段,都无法保证线程安全。Thread类的suspend()和resume()方法,如果一个线程执行了suspend()但逻辑上又需要执行resume()则就发生了死锁
线程安全的实现方法
互斥同步(阻塞同步)
同步是指在多线程并发访问共享数据时,保证同一时刻只能被一个线程使用
互斥是实现同步的一种手段
实现方式
在java中,最基本的同步手段就是使用
synchronized关键字。其经过编译后,会在同步块的前后分别形成monitorenter和monitorexit这两个字节码指令,这两个字节码都需要一个 reference 类型的参数来指明要锁定和解锁的对象。还可以使用JUC下的重入锁(ReentrantLock)实现同步,基本用法上其与synchronized很相似,他们都具备一样的线程重入特征(一个线程锁定一个资源后,自己还可以再次进入该锁定区域,不至于将自己锁死) 相较于 synchronized,其还有三个优势:
- 等待可中断:当持有锁的线程长期不释放锁时,正在等待的线程可以选择放弃等待,改为处理其他事情
- 公平锁:指多个线程在等待同一个锁时,必须按照先来后到的顺序获取锁
- 锁绑定多个条件:一个 ReentrantLock对象可以同时绑定多个 Condition 对象,每个Condition对象又可以理解为一把锁
非阻塞同步
互斥同步最主要的问题是进行线程阻塞和唤醒所带来的性能问题。互斥同步署于一种悲观的并发策略。而非阻塞同步则是:先进行操作,如果没有其他线程争用共享数据,那操作就是成功了,如果有冲突,则再采取其他补偿措施(最藏剑的就是不断重试,直到成功,即CAS)。因为其不需要将线程挂起,所以是非阻塞的。
无同步方案
要保证线程安全,并不一定要使用同步。同步只是保证共享数据争用时的正确性手段。如果一个方法本来就不涉及共享数据,那他天然就是线程安全的。
锁优化
自旋锁与自适应自旋
互斥同步对性能影响最大的时阻塞的实现(线程的阻塞和唤醒需要用户态和内核态的切换),且由于共享数据的锁定状态只会维持很短一段时间,所以可以让等待的线程不放弃处理器执行时间而执行一个忙循环(自旋) 因为不会放弃cpu执行时间,所以对于长时间的等待自然是一种浪费,如果自旋超过了一定次数仍没有获得锁,就是使用传统的方式挂起线程了。自旋次数默认为10次,可以通过 -XX:PreBlockSpin 参数修改 JDK1.6引入了自适应自旋锁,如果之前能很快自旋成功,那么下次自旋将会允许更长的时间,反之则会更快升级为挂起
锁消除
指虚拟机即使编译器在运行时,对一些要求同步的代码进行分析,检测到其不可能存在共享数据竞争的关系,则会对锁进行消除。 锁消除的主要判定依据来源于
逃逸分析的数据支持。锁粗化
如果虚拟机探测到有一串零碎的操作都对同一个对象加锁,则虚拟机会将锁扩展到整个操作序列以外,内部的锁就会被消除
轻量级锁
轻量级锁不能代替重量级锁,其本意时在
没有多线程的竞争前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗 HotSpot虚拟机的对象头分为两个部分。第一部分(Mark Word)用于存储对象自身的运行数据,如hashCode、GC分代年龄等,它是实现轻量级锁和偏向锁的关键。另一部分用于存储指向方法区对象类型的指针数据,如果是数组对象的化,还会有一个额外的部分用于存储数组长度 在Mark Word中,使用2bit记录锁状态
- 加锁过程
- 代码进入同步块时,如果此同步对象没有被锁定(锁标志为“01”状态),虚拟机将首先在当前线程的栈帧中建立一个名为锁记录的空间,用于存储锁对象目前的Mark Word的拷贝(即Displaced Mark Word)
- 虚拟机将使用CAS尝试将该对象的MarkWord更新为指向栈中锁记录的指针。如果该操作成功了,那么这个线程就拥有了该对象的锁,并且对象的MarkWord锁标志位转变位“00”,表示此时对象处于轻量级锁定状态。如果该操作失败了,虚拟机首先坚持对象的markword是否指向当前线程栈帧,如果是,则说明当前线程已经拥有了这个对象的锁,就可以直接进入同步代码块。否则说明这个锁队形已经被其他线程抢占了。
- 如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀位重量级锁,锁标志状态值变为“10”,MarkWord中存储的就是指向重量级锁(互斥量)的指针,后面等待的线程也要进入阻塞状态
- 解锁过程也是通过CAS进行的
轻量级锁的缺点:如果存在竞争,则处理互斥量(加重量级锁)的开销外,还额外发生了CAS
偏向锁
如果说轻量级锁是在无竞争情况下使用CAS去消除同步使用的互斥量,那偏向锁就是在无竞争情况下把整个同步都消除掉,连CAS都不做了 偏向锁会偏向第一个获取它的线程,如果接下来执行过程中,该锁没有被其他线程获取,则持有偏向锁的线程永远不需要同步
- 加锁过程
- 当锁队形第一次被线程获取时,虚拟机会把对象头中的标志位设置位“01”,即偏向模式
- 同时使用CAS操作把获取到这个锁的线程ID记录在对象的MarkWord中
- 如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都不再进行任何同步操作
- 当另外一个线程去尝试获取这个锁时,偏向模式就宣告结束。根据锁对象目前是否处于被锁定状态,撤销偏向后恢复到未锁定状态,标志位设置为“01”或轻量级锁定状态,标记位设置为“00”,后续的同步操作就是轻量级锁的操作
视频直播相关
视频直播技术以及 h264 解析
软件版本Alpha、Beta、RC、GA、Release解惑
- Alpha(α内测版):Alpha是内部测试版,一般不向外部发布,会有很多Bug.除非你也是测试人员,否则不建议使用.是希腊字母的第一位,表示最初级的版本。alpha 就是α,beta 就是β,alpha 版就是比beta还早的测试版,一般都是内部测试的版本。
- Beta(β公测版):该版本相对于α版已有了很大的改进,消除了严重的错误,但还是存在着一缺陷,需要经过多次测试来进一步消除。这个阶段的版本会一直加入新的功能。
- RC(候选发行版):Release Candidate,Candidate是候选人的意思,用在软件上就是候选版本。Release.Candidate.就是发行候选版本。和Beta版最大的差别在于Beta阶段会一直加入新的功能,但是到了RC版本,几乎就不会加入新的功能了,而主要着重于除错! RC版本是最终发放给用户的最接近正式版的版本,发行后改正bug就是正式版了,就是正式版之前的最后一个测试版。
- GA(首个稳定版本):general availability,比如:Apache Struts 2 GA这是Apache Struts 2首次发行稳定的版本,GA意味着General Availability,也就是官方开始推荐广泛使用了。
- Release(标准版):该版本意味“最终版本”,在前面版本的一系列测试版之后,终归会有一个正式版本,是最终交付用户使用的一个版本。该版本有时也称为标准版。一般情况下,Release不会以单词形式出现在软件封面上,取而代之的是符号(R)。
- LTS:long term support,长期支持版本
Lambda表达式相关的Consumer、Function、Predicate与Supplier的区别
区别总览
名称 参数 返回值 实例 Consumer 有 无 Iterable上的forEach方法 Function 有 有 Optional的map方法 Predicate 有 有(bool) Optional的filter方法 Supplier 无 有 懒加载、惰性求值、Stream的generate(静态) 详细解释
Supplier
- 解释
在开发中,我们经常会遇到一些需要延迟计算的情形,比如某些运算非常消耗资源,如果提前算出来却没有用到,会得不偿失。在计算机科学中,有个专门的术语形容它:惰性求值。惰性求值是一种求值策略,也就是把求值延迟到真正需要的时候。在Java里,我们有一个专门的设计模式几乎就是为了处理这种情形而生的:Proxy。不过,现在我们有了新的选择:Supplier。
非常简单的一个定义,简而言之,得到一个对象。但它有什么用呢?我们可以把耗资源运算放到get方法里,在程序里,我们传递的是Supplier对象,直到调用get方法时,运算才会执行。这就是所谓的惰性求值。
- 举例
static void randomZero(Integer[] coins, Supplier<Integer> randomSupplier) { coins[randomSupplier.get()] = 0; } Integer[] coins = {10, 10, 10, 10, 10, 10, 10, 10, 10, 10}; randomZero(coins, () -> (int) (Math.random() * 10));
- 扩展
但是,通常实现 Proxy 模式,我们只会计算一次,反复计算是没有必要的。Guava给我们提供了一个函数:
memorizedUltimateAnswerSupplier = Suppliers.memoize(ultimateAnswerSupplier);memoize() 函数帮我打点了前面所说的那些事情:第一次 get() 的时候,它会调用真正Supplier,得到结果并保存下来,下次再访问就返回这个保存下来的值。
(git) origin main VS origin/main
首先要知道的是,本地实际上有两个版本库,一个是你本地正在使用的版本库,另一个是远程版本库的副本(默认使用origin作为远程仓库的别名,可以使用
git remote -v查看)所以
git fetch的作用就是同步远程版本库,否则,即使远程版本库修改了,你不主动fetch的话,本地远程版本库的副本还是原来的样子而本地的远程版本库副本的分支名就是
origin/main(如果远程分支中有一个分支名为main)所以,对于合并远程代码的操作可以是:
# 更新本地的远程版本库副本 git fetch origin main # 合并副本中的main分支(此时还是本地的两个版本库进行合并) git merge origin/main所以,总的来说,如果是对远程仓库的操作,例如 push pull fetch 等就是用 origin main,如果是对远程仓库分支的操作,例如 merge rebase 等就是用 origin/main
python -m
长话短说
简单来说,
-m参数的作用有两个:
简化运行方式,你可以直接运行在
sys.path下的模块而不需要指定具体路径(如果直接用python pkgpath则要指明具体路径)它会将当前执行的目录也加入到
sys.path,这样即使在代码中使用相对或绝对路径import package_path也是可以运行的(否则就只能引用sys.path中的package了)具体的
模块
python中的模块分两种:
一般的python文件,例如
xxx.py,这个称之为“代码模块”一个包含其他模块的目录,这个称之为“包模块”,其目录下的模块既可以是代码模块,也可以是包模块。一般情况下,其目录下会存在一个名为__init__.py的文件
最初
-m参数提出来就是为了简化模块的运行方式,例如对于SimpleHTTPServer(python3中是http.server),在没有该参数出来之前你需要指定该包的具体路径才能运行python xxx/xxx/xxx.py在此之后,因为该包在
sys.path中,你只需要直接运行包名即可(注:包名不包含.py后缀)python -m xxx事实上,这两种方式运行的效果是一样的,使用-m参数后python解释器会自动帮你找到模块的绝对路径,这和直接在代码中 import module 本质上是一样的
如果某目录(模块)下存在“__main__.py”文件,则你可以直接运行该模块,例如你在 “testmodule” 目录下有两个文件
你可以运行
# 均在上述Tmp目录下 python .\testmodule\ # 或 python -m testmodule
注1:如果是以模块方式运行,则其模块下的“__init__.py”会先运行
注2:import module时也会执行module下的“__init__.py”,如果module就是一个py文件时,它会先将该文件执行一遍
sys.path
sys.path是一个目录数组,你在import module时,python解释器就会遍历这些目录去寻找相应的module,如果没找到就报找不到module的错误,当在命令行中使用-m参数运行module时,它会自动将当前目录加入到sys.path中去,否则就不会,可以在代码中打印出来看看
添加
可以直接使用
sys.path.append(dir)进行添加,这里需要注意的是,如果使用如下代码进行添加则可能会出问题:# 以下为错误做法:这里实际上指的不是当前文件所在目录,而是你运行py文件时所在的目录 module_dir = os.path.abspath('./') # 以下为正确做法,要获取文件所在位置,然后再根据该位置进行调整 module_dir = os.path.abspath(os.path.join(os.path.abspath(__file__), "..")) sys.path.append(module_dir)
if __name__ == “__main__”:
__name__是个魔法属性,当你执行某module时,该module的 __name__就会等于"__main__",如果是import的module,则该module的__name__就等于该module的名称
import 代码模块时,python解释器会先从头到尾执行一遍该代码模块的代码,有些代码你不想这个时候运行,例如一些测试该模块的代码。此时你就可以将这部分代码放在“if __name__==“main””中,只有你主动执行该模块时,这段代码才会执行
参考
https://stackoverflow.com/questions/7610001/what-is-the-purpose-of-the-m-switch
linux的du和df命令
du查看文件或文件夹磁盘占用情况,类似于windows下文件属性
df查看分区占用情况,类似于查看“我的电脑”du
-a表示统计所有文件和文件夹,否则只统计文件夹
-d num表示统计文件夹最大深度,不指定则递归统计所有文件夹及其子文件夹。df
df是查看分区使用情况,不指定目录就返回所有分区,指定目录则返回该目录所在分区情况
python中的yield
使用方式
def counter(): print('counter start...') for i in range(): a = yield i print(f'a is {a}') counter() # <generator object counter at 0x000001E7DA8B09E0> counter() # <generator object counter at 0x000001E7DA8B09E1> f = counter() print(next(f)) # counter start... # 0 print(next(f)) # a is None # 1 print(next(f)) # a is None # 2yield关键字可以看作是return,代码执行到这里就会停止执行并返回其后面的值。下次调用的时候就会接着其后面继续执行
使用yield返回值的方法 **每次** 调用时会产生一个迭代器对象,如上述代码中 counter() 生成一个 generator object,将该迭代器赋值给一个变量(上述代码中的 f ),就可以对该变量使用迭代操作了。
自动计数器
记录步数的时候好用,例如使用tensorboard追踪神经网络参数时需要填写一个step参数
方法一:
import itertools c = itertools.count() next(c) # 0 next(c) # 1 next(c) # 2方法二(使用yield,有点脱裤子放屁):
《高性能MySQL第四版》笔记
MySQL的事务是由存储引擎实现的
事务的四种特性:Atomicity、Consistency、Isolation、Durability:
原子性:要么全部成功要么全部失败,不能切割
一致性:数据库的数据从一个一致性状态转移到另一个一致性状态,可以理解为是原子性的一个结果,即执行一个事务后,数据库的数据要么是保持事务执行之前的状态,要么是事务完整执行之后的状态,而不能是事务执行过程中中间的状态
隔离性:下述的四种隔离级别
持久性:一旦事务提交,数据就永久保存在数据库中,不会因为数据库崩溃而导致数据丢失
事务的隔离级别:读未提交、读已提交、可重复读、可串行化
读未提交:事务中可以查看其他事务中还没提交的修改,这个过程称为脏读
读已提交:大多数据库默认的隔离级别(MySQL不是),只能读取到已经提交的事务修改。但可能存在同一个事务中读取到两个不一样的值(两次读取过程中,其他事务提交了修改)
可重复读:MySQL默认级别,保证了一个事务中读取的同一个数据是一致的,但如果是读取一个范围内的数据,仍然不能保证一致,例如两次读取一个范围内数据过程中,其他事务向该范围内增加或修改了数据,这一过程称为幻读
可串行化:读取数据时,在每一行都加上锁,解决幻读问题。但锁的开销巨大
多版本并发控制
使用MVCC用于提高并发性能,Oracle、PostgreSQL也使用了MVCC,但实现方式有区别
MVCC可以认为是行级锁的一个变种,但它很多情况下避免了加锁操作
Performance Schema
提供了数据库优化的一些性能指标
什么是程序插桩?
程序插桩是在mysql代码中插入检测代码,以获取想了解的信息,例如,想要收集关于元数据锁的使用情况,需要启用 wait/lock/meta-data/sql/mdl 这个插桩
什么是消费者表?
用于存储程序插桩获得的记录结果,例如我们为查询模块添加插桩,则相应的消费者表中将记录诸如执行总数、未使用索引的次数、花费的时间等信息
docker 容器迁移
import导入的镜像无法运行?
import 导入的镜像需在run命令最后手动指定镜像内的运行指令,该指令可在原宿主机上使用以下命令查看:
docker ps --no-trunc
在run命令的末尾加上这些命令(以上图第一个容器举例):
docker run -d --name xxx IMAGE_ID java -jar /webfont.jar迁移后没有数据?
使用 export/import 或者 save/load 持久化容器并运行在新的服务器上,发现原本的数据没有了,但原来的镜像在运行的时候并没有手动挂载卷。
出现这种问题的原因是:虽然你没有手动挂载卷,但不代表镜像制作者当初没有在dockerfile中挂载卷。
dockerfile中有个
VOLUME指令,可用于指定匿名挂载卷。其形式为:VOLUME [/some-container-dir]只需要指定一个镜像内的地址,而不需要指定将其挂载到宿主机的什么位置。docker会自动在docker安装目录下生成一个挂载点。这样做的目的主要是为了数据安全考虑,倘若有一个非常重要的数据库容器,运行时没有指定挂载数据点,假如不小心将该容器删除了,那数据就再找不回来了。故一般数据库镜像都会自动将数据文件夹挂载到宿主机。(注:手动指定的挂载点会覆盖自动挂载点)
例如 wordpress 的dockerfile中就有:
启动容器后(不手动挂载卷)使用以下命令查看容器详情:
docker inspect my-wordpress
可以看到虽然没有手动指定,它还是自动将 /var/www/html 目录挂载到了宿主机的某个目录上。
所以正确的做法是,将容器迁移后还需要将这些挂载点也复制过去。
匿名挂载卷如何处理?
挂载时没有指明具体宿主机目录就是匿名挂载卷(通过docker inspect中的 Mount 部分可以看到)
在清除docker-compose容器时,使用命令:
docker-compose down -v其中,-v 参数即删除匿名卷
或者在启动时使用命令
docker-compose up -V -d其中 -V 表示重新生成匿名卷(注:这种方式我试了一下好像还是不行)
java中的内部类
从编译后的class文件来看,不管是普通内部类还是内部静态类都是一个独立的class文件
multiprocessing.Manager().Queue() 的一个问题
import multiprocessing import time def task(q: multiprocessing.Queue, name): while True: v = q.get() print(f"subprocess {name=} get {v=}") if __name__ == "__main__": q = multiprocessing.Manager().Queue() p1 = multiprocessing.Process(target=task, args=(q, "sub1",)) # 创建第一个进程用于接收 queue 中的数据 p1.start() q.put(1) # 向 queue 中发送两条数据 time.sleep(1) q.put(2) time.sleep(1) p1.terminate() # 销毁第一个进程 p1.join() p1.close() p2 = multiprocessing.Process(target=task, args=(q, "sub2", )) # 创建第二个进程用于接收 queue 中的数据 p2.start() q.put(3) # 向 queue 中发送两条数据 time.sleep(1) q.put(4) time.sleep(999)运行结果基本为:
值得注意的是,我试了很多次,结果都是这样的,3 那个元素消失了
在这个过程中,我还发现,如果将上面的 multiprocessing.Manager().Queue() 修改为 multiprocessing.Queue(),则可能会出现即使向queue中put数据成功了,get() 都会一直阻塞,我猜测可能存在锁释放的问题。
记一次wordpress docker迁移过程
1. 查看镜像的挂载点
docker inspect wp-web | grep Mounts -A 50 docker inspect wp-web | grep Mounts -A 50
2. 将挂载文件目录打包
tar -cvf wp-data.tar /var/lib/docker/volumes/32fe7e4a8fc55bf030f3eac666a40c6c52b3d6aa61faa0f0919a44bed1c4632d/_data tar -cvf mysql-data.tar /var/lib/docker/volumes/6902018c3680a510af9d445d9a48da407bc1242694c9ccb5b9b6a23f728701ec/_data3. 将容器commit成镜像
docker commit -p wp-web wp-web:migratev1 docker commit -p db-mysql db-mysql:migratev1
4. save命令持久化镜像
docker save -o wp-web.tar wp-web:migratev1 docker save -o db-mysql.tar db-mysql:migratev1注:save 命令后应接镜像名而不是镜像id(例如:应该是 wp-web:migratev1 而不是 8f5b),否则用load加载的镜像名称和tag都是none,就需要手动重命名:
docker tag [镜像id] [新镜像名称]:[新镜像标签]
5. 将所有的打包文件复制到新服务器
# 旧服务器上 tar -cvf wp-migrate.tar db-mysql.tar mysql-data.tar wp-data.tar wp-web.tar # 新服务器上 scp [email protected]:/root/wp-migrate.tar ./Desktop/wp-migrate/6. 新服务器上解压